Hierarchical Clustering
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Arsenal Holdings Plc Financial Highlights Directors, Officers and Advisers
CONTENTS FINANCIAL HIGHLIGHTS page 3 DIRECTORS, OFFICERS & ADVISERS page 4 CHAIRMAN’S REPORT page 5 EMIRATES STADIUM page 14 REVIEW OF THE 2004/2005 SEASON page 15 CHARITY OF THE SEASON page 20 ARSENAL IN THE COMMUNITY page 21 DIRECTORS’ REPORT page 22 FINANCIAL STATEMENTS Corporate Governance page 24 Remuneration Report page 25 Independent Auditors’ Report page 26 Consolidated Profit and Loss Account page 27 Balance Sheets page 28 Consolidated Cash Flow Statement page 29 Notes to the Accounts page 30 FIVE YEAR SUMMARY page 49 NOTICE OF ANNUAL GENERAL MEETING page 50 AGM VOTING FORM page 51 FINANCIAL HIGHLIGHTS 2005 2004 Group turnover £m 138.4 156.9 Group operating profit before player trading and exceptional costs £m 32.6 36.2 Profit before taxation £m 19.3 10.6 Earnings per share £ 138.91 138.29 Group Turnover Group operating profit before player trading and exceptionals £m £m £m 180 40 160 35 140 30 120 25 100 20 80 15 60 10 40 5 2001 2002 2003 2004 2005 2001 2002 2003 2004 2005 Wage Cost as % of Group turnover Investment in fixed assets per annum %£m 70 120 65 100 60 80 55 60 50 40 45 20 40 0 2001 2002 2003 2004 2005 2001 2002 2003 2004 2005 3 ARSENAL HOLDINGS PLC FINANCIAL HIGHLIGHTS DIRECTORS, OFFICERS AND ADVISERS LIFE VICE PRESIDENT BANKERS C E B L Carr Royal Bank of Scotland plc 62/63 Threadneedle Street DIRECTORS London P D Hill-Wood EC2R 8LA Lady Nina Bracewell-Smith R C L Carr Barclays Bank plc D B Dein Holloway & Kingsland K G Edelman Business Centre D D Fiszman London K J Friar OBE E8 2JX Sir Roger Gibbs REGISTRARS MANAGER Capita IRG plc A Wenger OBE The Registry 34 Beckenham Road SECRETARY Beckenham D Miles Kent BR3 4TU GROUP CHIEF ACCOUNTANT S W Wisely ACA REGISTERED OFFICE Arsenal Stadium AUDITORS Avenell Road Deloitte & Touche LLP Highbury Chartered Accountants London London N5 1BU SOLICITORS COMPANY REG. -

Ma Vie, Mon Oeuvre, Mon Cul (Philoumiha)
Ma Vie, Mon Oeuvre, Mon Cul (philoumiha) Ceci est une fiction. Toute ressemblance avec des personnes de la vie réelle ou avec des faits historiques avérés serait complètement involontaire de ma part. Mardi 17 juin 2008, abords du Stade de Suisse, Berne. - C'est vraiment dommage, on fait un gros match. Je suis vraiment fier de mes joueurs. On a pas eu beaucoup de réussite mais y'avait quand même des choses interessantes. - Mais quand même, perdre 6-1 face à la Pologne alors qu'on attendait une réaction d'orgueil de la part de l'équipe, ca fait beaucoup. - Libre à vous de voir les choses comme ca. De toute facon, c'est facile de critiquer. Mais je maintiens que je suis content de la performance des garcons. On a pas eu de chance. Y'a qu'à voir les stats du match. 1 tir pour nous, 1 but. 27 tirs pour eux, 6 buts. Ca nous fait du 100%, pas eux. Les mathématiques et les astres ne mentent jamais. - Vous avez des regrets sur ce match? - Non, on a fait ce qu'il fallait. Faut dire aussi que l'arbitre a pas été très loyal. Regardez à 10 minutes de la fin, Machinski fait une faute qui mérite un jaune. Et l'arbitre sort pas le carton. Dans ces conditions, pas facile de gagner. - Votre avenir, c'est quoi? - En ce moment, je pense juste à me marier. D'ailleurs Estelle, ma mie, ma douce, ma bitch, veux-tu m'epousailler? T.Roland: Hé Hé Hé Ho (son rire à la con). -

The Gooner Survey Results 2013
THE GOONER SURVEY RESULTS 2013 PART 1 – SEASON 2012-13 Arsenal Player of the Season 2012/13 Best Arsenal Goal 2012/13 1st Choice 2nd Choice 1. Podolski v Montpellier (H) 1. Santi Cazorla 63% 26% 2. Walcott’s 3rd v Newcastle (H) 2. Laurent Koscielny 22% 39% 3. Cazorla v West Ham (A) 3. Theo Walcott 5% 19% 4. Gibbs v Swansea (A - FA Cup) 4. Jack Wilshere 2% 5% 5. Mertesacker v Spurs (H) Other 8% 11% 6. Podolski v West Ham (H) Most Disappointing Arsenal Player 2012/13 1st Choice 2nd Choice 1. Thomas Vermaelen 60% 25% 2. Bacary Sagna 20% 38% 3. Wojciech Szczesny 4% 15% Other 16% 22% Most Improved Arsenal Player in last 12 months 1. Ramsey 46% 2. Laurent Koscielny 30% 3. Theo Walcott 13% Whilst recognising that the summer transfer Other 11% dealings will play a large part in how we fare next season, at this point in time how optimistic are you about our prospects of competing for the Best Team Performance 2012/13 Premier League title in 2013-14? Extremely Optimistic 6% 1. 2-0 v Bayern Munich (A) 44% Quite Optimistic 35% 2. 5-2 v Spurs (H) 24% Unsure 25% 3. 2-0 v Liverpool (A) 17% Quite pessimistic 21% 4. 7-3 v Newcastle (H) 4% Extremely pessimistic 13% Other 11% Whilst accepting the two are not mutually Worst Team Performace exclusive, which of the following achievements do you regard as being most important? 1. 0-1 v Blackburn (H) 32% 2. 1-1 v Bradford (A) 31% Qualifying for the Champions League 59% 3. -

P20 Layout 1
Serena, Sharapova Windies rout again on Miami Bangladesh collision course WEDNESDAY, MARCH 26, 201417 18 Brazil beckons Pakistan’s street kid footballers Page 19 OLD TRAFFORD: Manchester City’s Argentinian defender Pablo Zabaleta (left) and Manchester United’s English forward Danny Welbeck lie injured after clashing during the English Premier League football match.— AFP Dzeko’s brace give City derby spoils Dzeko claimed his second goal early in the Hertha Berlin to secure the Bundesliga title in invited City to attack them. to deny Dzeko-but they did not heed them second half before Yaya Toure added a late record time. Jones had to slide in to block from Silva after and in the 56th minute it was 2-0. Nasri Man United 0 third to leave Manuel Pellegrini’s side three “We didn’t start the game well,” admitted Carrick lost the ball, while United goalkeeper shaped a corner towards the near post from points behind leaders Chelsea, with two games Moyes.”I think we have played a very good David de Gea produced a superb one-handed the right-hand side and Dzeko left Rio in hand, ahead of Saturday’s trip to Arsenal. side, playing at the sort of level we are aspir- save to thwart Dzeko and atone for a loose kick Ferdinand in his wake to steer a right-foot vol- “We scored three goals and had three or ing to. We need to come up a couple of lev- of his own. ley into the top-right corner. Man City 3 four more good chances to score,” City manager els ourselves because at the moment we are Gradually the hosts began to make inroads, With victory secure, City’s fans delved into Manuel Pellegrini told Sky Sports. -
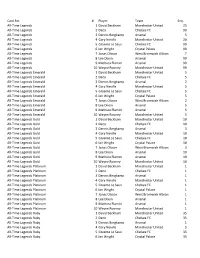
Card Set # Player Team Seq. All-Time Legends 1 David Beckham
Card Set # Player Team Seq. All-Time Legends 1 David Beckham Manchester United 25 All-Time Legends 2 Deco Chelsea FC 99 All-Time Legends 3 Dennis Bergkamp Arsenal 5 All-Time Legends 4 Gary Neville Manchester United 20 All-Time Legends 5 Graeme Le Saux Chelsea FC 99 All-Time Legends 6 Ian Wright Crystal Palace 99 All-Time Legends 7 Jonas Olsson West Bromwich Albion 7 All-Time Legends 8 Lee Dixon Arsenal 99 All-Time Legends 9 Mathieu Flamini Arsenal 99 All-Time Legends 10 Wayne Rooney Manchester United 99 All-Time Legends Emerald 1 David Beckham Manchester United 5 All-Time Legends Emerald 2 Deco Chelsea FC 5 All-Time Legends Emerald 3 Dennis Bergkamp Arsenal 2 All-Time Legends Emerald 4 Gary Neville Manchester United 5 All-Time Legends Emerald 5 Graeme Le Saux Chelsea FC 5 All-Time Legends Emerald 6 Ian Wright Crystal Palace 5 All-Time Legends Emerald 7 Jonas Olsson West Bromwich Albion 2 All-Time Legends Emerald 8 Lee Dixon Arsenal 5 All-Time Legends Emerald 9 Mathieu Flamini Arsenal 5 All-Time Legends Emerald 10 Wayne Rooney Manchester United 5 All-Time Legends Gold 1 David Beckham Manchester United 10 All-Time Legends Gold 2 Deco Chelsea FC 10 All-Time Legends Gold 3 Dennis Bergkamp Arsenal 3 All-Time Legends Gold 4 Gary Neville Manchester United 10 All-Time Legends Gold 5 Graeme Le Saux Chelsea FC 10 All-Time Legends Gold 6 Ian Wright Crystal Palace 10 All-Time Legends Gold 7 Jonas Olsson West Bromwich Albion 3 All-Time Legends Gold 8 Lee Dixon Arsenal 10 All-Time Legends Gold 9 Mathieu Flamini Arsenal 10 All-Time Legends Gold 10 Wayne -
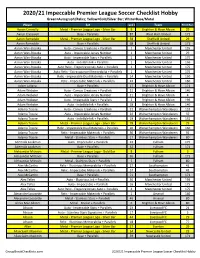
2020-21 Panini Impeccable Hobby Soccer Checklist
2020/21 Impeccable Premier League Soccer Checklist Hobby Green=Autograph/Relics; Yellow=Gold/Silver Bar; White=Base/Metal Player Set Card # Team Print Run Aaron Connolly Metal - Premier League Logo - Silver Bar 9 Brighton & Hove Albion 29 Aaron Cresswell Base + Parallels 87 West Ham United 171 Aaron Ramsdale Metal - Premier League Logo - Silver Bar 58 Sheffield United 29 Aaron Ramsdale Base + Parallels 68 Sheffield United 171 Aaron Wan-Bissaka Auto - Canvas Creations + Parallels 1 Manchester United 135 Aaron Wan-Bissaka Auto - Impeccable Jersey Number 1 Manchester United 29 Aaron Wan-Bissaka Auto - Impeccable Stars + Parallels 1 Manchester United 175 Aaron Wan-Bissaka Auto - Indelible Ink + Parallels 1 Manchester United 136 Aaron Wan-Bissaka Auto Relic - Elegance Jersey Auto + Parallels 1 Manchester United 175 Aaron Wan-Bissaka Auto Relic - Extravagance Memorabilia + Parallels 1 Manchester United 175 Aaron Wan-Bissaka Relic - Impeccable Dual Materials + Parallels 14 Manchester United 160 Aaron Wan-Bissaka Relic - Impeccable Materials + Parallels 24 Manchester United 160 Adam Lallana Base + Parallels 17 Brighton & Hove Albion 171 Adam Webster Auto - Canvas Creations + Parallels 21 Brighton & Hove Albion 140 Adam Webster Auto - Impeccable Jersey Number 21 Brighton & Hove Albion 4 Adam Webster Auto - Impeccable Stars + Parallels 2 Brighton & Hove Albion 199 Adam Webster Auto - Indelible Ink + Parallels 18 Brighton & Hove Albion 140 Adama Traore Auto - Canvas Creations + Parallels 22 Wolverhampton Wanderers 131 Adama Traore Auto - Impeccable -

Big-5 Weekly Post
Issue n°79 - 02/09/2014 Big-5 Weekly Post Transfers follow-up - Summer 2014 Most over-paid players Most under-paid players + 30.0 Ángel Di María -16.0 Mario Balotelli million € Real Madrid CF Manchester United FC million € Milan AC Liverpool FC + 29.0 David Luiz -11.8 Luis Suárez million € Chelsea FC Paris St-Germain FC million € Liverpool FC FC Barcelona + 25.0 m James Rodríguez -10.0 Diego Costa million € AS Monaco Real Madrid CF million € Club Atlético de Madrid Chelsea FC Transfers worth more than 10 million € Over-paid Ángel Jérémy Shane Dejan Luís Gyl Di María Mathieu Long Lovren Filipe Sigurdsson David Calum Claudio Adam Vincent Juan Manuel Luiz Chambers Bravo Lallana Aboubakar Iturbe James Thomas Luke Jack Keylor Alberto Rodríguez Vermaelen Shaw Rodwell Navas Moreno Ander Alexis Medhi Ivan Divock Herrera Sánchez Benatia Rakitić Origi Right price Demba Ben Federico Jake Álvaro Ba Davies Fernández Livermore Morata Juan Mathieu Javi Adrián Shkodran Bernat Debuchy García López Musta Hakan Federico Toni Romelu Marc-André Çalhanoğlu Fazio Kroos Lukaku ter Stegen Emre Leroy Pierre-Michel Mario Danny Can Fer Lasogga Mandžukić Welbeck Under-paid Mario Matthias Steven Antoine Balotelli Ginter Caulker Griezmann Luis Juan Ciro Suárez Cuadrado Immobile Diego Rémy Alessio Costa Cabella Cerci Antonio Loïc Francesc Candreva Rémy Fàbregas Editors: Raffaele Poli, Roger Besson and Loïc Ravenel Issue n°80 - 09/09/2014 Big-5 Weekly Post page 1/5 Rank estimated 1st 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20th Chelsea FC Manchester City -

3. All-Time Records 1955-2021
UEFA CHAMPIONS LEAGUE STATISTICS HANDBOOK 2021/22 3. ALL-TIME RECORDS 1955-2021 PAGE 1 EUROPEAN CHAMPION CLUBS’ CUP/UEFA CHAMPIONS LEAGUE ALL-TIME CLUB RANKING 5 EUROPEAN CHAMPION CLUBS’ CUP/UEFA CHAMPIONS LEAGUE ALL-TIME TOP PLAYER APPEARANCES 9 EUROPEAN CHAMPION CLUBS’ CUP/UEFA CHAMPIONS LEAGUE ALL-TIME TOP GOALSCORERS NB All statistics in this chapter include qualifying and play-off matches. Pos Club Country Part Titles Pld W D L F A Pts GD ALL-TIME CLUB RANKING 58 Sporting Clube de Portugal POR 22 0 93 26 20 47 119 157 72 -38 59 Sevilla FC ESP 9 0 61 28 15 18 100 87 71 13 60 FC Zenit RUS 11 0 71 29 13 29 88 87 71 1 Pos Club Country Part Titles Pld W D L F A Pts GD 61 HJK Helsinki FIN 21 0 76 28 13 35 101 117 69 -16 1 Real Madrid CF ESP 52 13 452 269 79 104 993 494 617 499 62 SV Werder Bremen GER 9 0 66 27 14 25 109 107 68 2 2 FC Bayern München GER 38 6 363 215 73 75 754 360 503 394 63 RC Deportivo La Coruña ESP 5 0 62 25 17 20 78 79 67 3 FC Barcelona ESP 32 5 328 193 74 61 653 325 460 328 64 FK Austria Wien AUT 19 0 73 25 16 32 100 110 66 -10 4 Manchester United ENG 30 3 286 157 66 63 522 276 380 246 65 SS Lazio ITA 7 0 60 24 16 20 93 77 64 16 5 Juventus ITA 36 2 288 148 69 71 462 278 365 184 66 Ferencvárosi TC HUN 14 0 63 24 16 23 99 109 64 -10 6 AC Milan ITA 29 7 250 125 64 61 418 234 314 184 67 VfL Borussia Mönchengladbach GER 9 0 55 22 16 17 110 74 60 36 7 Liverpool FC ENG 26 6 228 128 49 51 426 204 305 222 68 Tottenham Hotspur ENG 6 0 55 25 10 20 108 83 60 25 8 SL Benfica POR 41 2 264 117 61 86 423 302 295 121 69 R. -

“Bosman”: Are Competition Exemptions Admissible for Football?
Crisis at Football Market After the “Bosman”: Are Competition Exemptions Admissible for Football? Cengiz Kağan ŞAHİN Promoter: Prof. Frank HOFFMEISTER Readers: Prof. Frank HOFFMEISTER, Prof. Marc MARESCEAU, Prof. Dirk ARTS Academic Year: 2007-2008 Crisis at Football Market After the “Bosman”: Are Competition Exemptions Admissible for Football? / ŞAHİN 1. Introduction Sports has been a prominent issue in European Union agenda and within this field football has been the most interesting and attractive branch of sports. This study will examine the legal conformity of making competition exemption to enhance competition in the field of football. Following such a context; firstly the applicability of EU Law to the field of sport will be elaborated. Within this issue, the evolving relationship between sport and European Union, the sports connection to the community law is essential. The Helsinki report constitutes a basic document in which general problems linking the sport and the Com- petition Policy were deliberated. Thus, it will be presented before the related articles of the EC Treaty. Then, the actors of football and their legal positions will be introduced. The various markets will be distinguished in order to reveal the affects of restrictions on an upstream market on the downstream markets. After that; the main actors of football market including the footballers, the FIFA and the UEFA will be explained. The changing situation of footballers and transfer system will be elaborated. The conditions for competition exemption in the area of football will be expressed in addition to the expectations of the EU from the market. Mentioning this issue, the paper will deal with relevant legislations about the competition exemptions. -

Uefa Champions League
UEFA CHAMPIONS LEAGUE - 2013/14 SEASON MATCH PRESS KITS Arsenal Stadium - London Tuesday 1 October 2013 20.45CET (19.45 local time) Arsenal FC Group F - Matchday 2 SSC Napoli Last updated 01/10/2013 09:45CET UEFA CHAMPIONS LEAGUE OFFICIAL SPONSORS Previous meetings 2 Match background 5 Match facts 7 Squad list 8 Head coach 11 Match officials 12 Fixtures and results 13 Match-by-match lineups 17 Group Standings 19 Competition facts 21 Team facts 22 Legend 24 1 Arsenal FC - SSC Napoli Tuesday 1 October 2013 - 20.45CET, (19.45 local time) Match press kit Arsenal Stadium, London Previous meetings Head to Head No UEFA competition matches have been played between these two teams Arsenal FC - Record versus clubs from opponents' country UEFA Champions League Date Stage Match Result Venue Goalscorers 3-0 Koscielny 7, Rosický 06/03/2012 R16 Arsenal FC - AC Milan London agg: 3-4 26, Van Persie 43(P) Boateng 15, Robinho 15/02/2012 R16 AC Milan - Arsenal FC 4-0 Milan 38, 49, Ibrahimović 79(P) 1-2 Di Natale 39; Van 24/08/2011 PO Udinese Calcio - Arsenal FC Udine agg: 1-3 Persie 55, Walcott 69 16/08/2011 PO Arsenal FC - Udinese Calcio 1-0 London Walcott 4 UEFA Champions League Date Stage Match Result Venue Goalscorers 1-0 11/03/2009 R16 AS Roma - Arsenal FC agg: 1-1 (aet, 6- Rome Juan 9 7pens) 24/02/2009 R16 Arsenal FC - AS Roma 1-0 London Van Persie 37(P) UEFA Champions League Date Stage Match Result Venue Goalscorers 0-2 Fàbregas 84, 04/03/2008 R16 AC Milan - Arsenal FC Milan agg: 0-2 Adebayor 90+2 20/02/2008 R16 Arsenal FC - AC Milan 0-0 London UEFA -
Football, Immigrations Et Outre-Mer En Équipe De France (1918-2018)
FOOTBALL, IMMIGRATIONS ET OUTRE-MER EN ÉQUIPE DE FRANCE (1918-2018) L’histoire du football en équipe de France ne peut se concevoir sans l’apport multiple des outre-mer (Antilles, Guyane, Océanie et océan Indien) et d’une immigration venue des quatre coins d’Europe, du Maghreb, d’Afrique noire et de l’Amérique du Sud. Chaque grande vague d’immigration et de présence se retrouve au niveau de l’équipe nationale, et l’intégration des représentants les plus brillants des communautés étrangères illustre la notion de « creuset français ». Près de 350 joueurs de l’équipe nationale, soit plus d’un tiers, ont un parent ou un grand-parent d’origine étrangère ou ultramarine, ou ont eux-mêmes été naturalisés après avoir migré en France. Ces internationaux ont arboré le maillot des Bleus de la première Coupe du monde en 1930 en Uruguay à celle de 2018 en Russie. Également présents en championnat de France, des joueurs belges et luxembourgeois s’illustrent dès la première Coupe de France en 1917-1918 et inaugurent un long récit d’un siècle dans les compétitions sportives en France. Le Onze de France est désormais l’histoire de joueurs et joueuses de toutes origines et aux destins emblématiques : les Algériens Zinédine Zidane et Rachid Mekhloufi, le Sénégalo-Guyanais Raoul Diagne, le Néo-Calédonien Christian Karembeu, le Polonais Raymond Kopaszewski, l’Autrichien Rodolphe Hiden ainsi que la Martiniquaise Wendie Renard et l’Ivoirienne Marie-Laure Delie. Écrivant les plus belles heures du football français, ils et elles conduisent par deux fois à la victoire en Europe (1984 et 2000), une fois à la conquête du titre mondial (1998), une fois à la finale (2006) et une fois à celle du titre olympique (1984). -

P19:Layout 1
TUESDAY, OCTOBER 22, 2013 SPORTS Wenger’s Arsenal harvest finally bears fruit LONDON: After eight fallow years with- Arsenal’s play with his vision and deft- together and their association already Although much of the media’s atten- however, may have been his decision to out silverware, Arsenal manager Arsene ness of touch, and his artistry appears to promises much, but no-one symbolises tion has focused on the signing of Ozil, bring French holding midfielder Wenger has seen his side reap a spec- have rubbed off on the players around the Arsenal revival more strongly than Giroud believes it was also vitally impor- Mathieu Flamini back to the club on a tacular harvest in the first month of the him. Aaron Ramsey. tant that Arsenal did not lose any of free transfer after a four-year exile at AC English autumn. Jack Wilshere was initially exiled to The Welsh midfielder’s career their major players during the close sea- Milan. His return was decried by some Saturday’s stylish 4-1 win over the left wing following Ozil’s arrival from seemed to be stuck in second gear after son. “We kept our best players and it’s fans as a sign of a lack of ambition, but Norwich City sent the north London Real Madrid, but he demonstrated his he sustained a double leg break in a something that Arsenal hadn’t done for his tigerish attitude and dogged deter- club two points clear at the Premier worth in a central role by breaking the challenge by Stoke City’s Ryan a few years because they lost four or five mination have given Arsenal a bite in League summit and extended their deadlock against Norwich with a Shawcross in February 2010, but he is of their best players,” the France striker central midfield that they have not had unbeaten run to 12 games in all compe- breath-taking goal that Wenger now playing with arresting self-assur- told AFP.