[Cs.CR] 19 Nov 2019 Attention Due to Their Use in Spectre [26] and Meltdown [31]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Amd Athlon Ii X2 270 Manual
Amd Athlon Ii X2 270 Manual Specifications. Please visit AMD Athlon II X2 215 (rev. C3) and AMD Athlon II X2 270 pages for more detailed specifications. Review, Differences, Benchmarks, Specifications, Comments Athlon II X2 270. CPUBoss recommends the AMD Athlon II X2 270 based on its. See full details. Specifications. Please visit AMD Athlon II X2 270 and AMD Athlon II X2 280 pages for more detailed specifications of both. Far Cry 4 on AMD Athlon x2 340(Dual Core) 4GB RAM HD 6570 PC Specifications. Specifications. Please visit AMD Athlon II X2 270 and AMD FX-6300 pages for more detailed specifications of both. AMD Athlon II x2 260 (3.2GHz) Although the specifications of this cpu list 74C as the max temp, i prefer to stick to the old "65C max" rule-of-thumb for amd cpus. Amd Athlon Ii X2 270 Manual Read/Download AMD Athlon II X2 270u. 2 GHz, Dual core. Front view of AMD Athlon II X2 270u. 5.9 Out of 10. VS Review, Differences, Benchmarks, Specifications, Comments. Photos of the AMD Athlon II X2 270 Black Edition from the KitGuru Price Comparison Engine. Specifications. Please visit AMD Athlon II X2 270 and AMD FX-4300 pages for more detailed specifications of both. SPECIFICATIONS : Model : AMD Athlon II X2 270. CPU Clock Speed : 3.4 GHz. Core : 2. Total L2 Cache : 2 MB Sockets : Socket AM2+,Socket AM3 Supported. up vote -5 down vote favorite. These are my specifications: AMD Athlon II x2 270 CPU, AMD 760g GPU, 4GB RAM. grand-theft-auto-5. -

AMD FX Cpus Now Faster Than Ever—Unlocked Performance with Maximum Cores
How to Sell the New AMD FX CPUs Now Faster than Ever—Unlocked Performance with Maximum Cores Who’s it for? Gamers and Enthusiasts who want the most out of their PC. Sell it in 5 seconds. More Cores. More Speed. Unlocked1 More Cores > Up to 8 Cores > Only 8 Core Desktop Processor—2 cores more than Intel1 Maximum Speed > Up to 4.2GHz Turbo Clock Speed > Latest Technology and Worlds Highest Frequencies2 Unlocked & Overclockable > Get the Maximum Tunable Performance > Go up to 5.0 GHz with aggressive cooling solutions from AMD3 Sell it in 60 seconds. Unlocked Performance for Less Money1,4 Performance Ferocious power right out of the box. > The groundbreaking AMD FX 8-Core Processor Black Edition comes unlocked. No premium to pay. No code to input.Just unrestrained, overclocked power right away.4 > Groundbreaking technology. Epic performance. > This next-generation architecture takes 8-core processing to a new level. Test the limits to play harder and get more done. Speed The need for speed. AMD FX Processors—Unlocked and overclocked.4 > Incredible speed out of the box and more in the tank; AMD Turbo CORE Technology automatically kicks in, boosting performance to a user’s varied workload. > The sky’s the limit with this processor’s massive headroom. Go up to 5.0 GHz with aggressive cooling solutions from AMD.5 Price Price and performance that keeps getting better and more bang for your buck. Unlocked technology.4 Unbelievable pricing. > With more speed than ever and more aggressive price points – New AMD FX Processors raise the bar for 8-core computing. -

AMD's Early Processor Lines, up to the Hammer Family (Families K8
AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) Dezső Sima October 2018 (Ver. 1.1) Sima Dezső, 2018 AMD’s early processor lines, up to the Hammer Family (Families K8 - K10.5h) • 1. Introduction to AMD’s processor families • 2. AMD’s 32-bit x86 families • 3. Migration of 32-bit ISAs and microarchitectures to 64-bit • 4. Overview of AMD’s K8 – K10.5 (Hammer-based) families • 5. The K8 (Hammer) family • 6. The K10 Barcelona family • 7. The K10.5 Shanghai family • 8. The K10.5 Istambul family • 9. The K10.5-based Magny-Course/Lisbon family • 10. References 1. Introduction to AMD’s processor families 1. Introduction to AMD’s processor families (1) 1. Introduction to AMD’s processor families AMD’s early x86 processor history [1] AMD’s own processors Second sourced processors 1. Introduction to AMD’s processor families (2) Evolution of AMD’s early processors [2] 1. Introduction to AMD’s processor families (3) Historical remarks 1) Beyond x86 processors AMD also designed and marketed two embedded processor families; • the 2900 family of bipolar, 4-bit slice microprocessors (1975-?) used in a number of processors, such as particular DEC 11 family models, and • the 29000 family (29K family) of CMOS, 32-bit embedded microcontrollers (1987-95). In late 1995 AMD cancelled their 29K family development and transferred the related design team to the firm’s K5 effort, in order to focus on x86 processors [3]. 2) Initially, AMD designed the Am386/486 processors that were clones of Intel’s processors. -

AMD Raven Ridge
DELIVERING A NEW LEVEL OF VISUAL PERFORMANCE IN AN SOC AMD “RAVEN RIDGE” APU Dan Bouvier, Jim Gibney, Alex Branover, Sonu Arora Presented by: Dan Bouvier Corporate VP, Client Products Chief Architect AMD CONFIDENTIAL RAISING THE BAR FOR THE APU VISUAL EXPERIENCE Up to MOBILE APU GENERATIONAL 200% MORE CPU PERFORMANCE PERFORMANCE GAINS Up to 128% MORE GPU PERFORMANCE Up to 58% LESS POWER FIRST “Zen”-based APU CPU Performance GPU Performance Power HIGH-PERFORMANCE AMD Ryzen™ 7 2700U 7th Gen AMD A-Series APU On-die “Vega”-based graphics Scaled GPU Managed Improved Upgraded Increased LONG BATTERY LIFE and CPU up to power delivery memory display package Premium form factors reach target and thermal bandwidth experience performance frame rate dissipation efficiency density 2 | AMD Ryzen™ Processors with Radeon™ Vega Graphics - Hot Chips 30 | * See footnotes for details. “RAVEN RIDGE” APU AMD “ZEN” x86 CPU CORES CPU 0 “ZEN” CPU CPU 1 (4 CORE | 8 THREAD) USB 3.1 NVMe PCIe FULL PCIe GPP ----------- ----------- Discrete SYSTEM 4MB USB 2.0 SATA GFX CONNECTIVITY CPU 2 CPU 3 L3 Cache X64 DDR4 HIGH BANDWIDTH SOC FABRIC System Infinity Fabric & MEMORY Management SYSTEM Unit ACCELERATED Platform Multimedia Security MULTIMEDIA Processor Engines AMD GFX+ 1MB L2 EXPERIENCE X64 DDR4 (11 COMPUTE UNITS) Cache Video Audio Sensor INTEGRATED CU CU CU CU CU CU Display Codec ACP Fusion Controller Next SENSOR Next Hub FUSION HUB CU CU CU CU CU AMD “VEGA” GPU UPGRADED DISPLAY ENGINE 3 | AMD Ryzen™ Processors with Radeon™ Vega Graphics - Hot Chips 30 | SIGNIFICANT DENSITY INCREASE “Raven Ridge” die BGA Package: 25 x 35 x 1.38mm Technology: GLOBALFOUNDRIES 14nm – 11 layer metal Transistor count: 4.94B 59% 16% Die Size: 209.78mm2 more transistors smaller die than prior generation “Bristol Ridge” APU 4 | AMD Ryzen™ Processors with Radeon™ Vega Graphics - Hot Chips 30 | * See footnotes for details. -
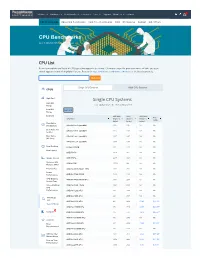
CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android Ios / Iphone
Software Hardware Benchmarks Services Store Support About Us Forums 0 CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android iOS / iPhone CPU Benchmarks Over 1,000,000 CPUs Benchmarked CPU List Below is an alphabetical list of all CPU types that appear in the charts. Clicking on a specific processor name will take you to the chart it appears in and will highlight it for you. Results for Single CPU Systems and Multiple CPU Systems are listed separately. Find CPU Single CPU Systems Multi CPU Systems CPUS High End Single CPU Systems High Mid Range Last updated on the 28th of May 2021 Low Mid Column Range Low End CPU Mark Rank CPU Value Price CPU Name (higher is (lower is (higher is (USD) better) better) better) Best Value (On Market) AArch64 rev 0 (aarch64) 2,335 1605 NA NA Best Value XY AArch64 rev 1 (aarch64) 2,325 1606 NA NA Scatter Best Value AArch64 rev 2 (aarch64) 1,937 1807 NA NA (All time) AArch64 rev 4 (aarch64) 1,676 1968 NA NA New Desktop AC8257V/WAB 693 2730 NA NA New Laptop AMD 3015e 2,678 1472 NA NA Single Thread AMD 3020e 2,637 1481 NA NA Systems with AMD 4700S 17,756 222 NA NA Multiple CPUs Overclocked AMD A4 Micro-6400T APU 1,004 2445 NA NA Power Performance AMD A4 PRO-3340B 1,706 1938 NA NA CPU Mark by AMD A4 PRO-7300B APU 1,481 2097 NA NA Socket Type Cross-Platform AMD A4 PRO-7350B 1,024 2428 NA NA CPU Performance AMD A4-1200 APU 445 2969 NA NA AMD A4-1250 APU 428 2987 NA NA CPU Mega List AMD A4-3300 APU 961 2494 53.40 $18.00* Search Model AMD A4-3300M APU 686 2740 22.86 $29.99* 0 Compare AMD -

AMD FX-9000 Series Installation Guide
5. Carefully place the motherboard 6. Install the graphics card into the 8. The POST screen should now 10. Install your Operating System. 13. Congratulations, you have into the chassis, such that its rear x16 PCI Express slot and ensure appear. (See image at right) Press successfully set up your AMD I/O ports line up with the cutouts the appropriate power connectors and hold down the DEL key on 11. Download the latest chipset, optimized AMD-powered system. FX-9000 in the I/O shield. Secure the are used. the keyboard until the BIOS network and audio drivers at motherboard with the supplied screen appears. Verify that the the motherboard manufacturer Series screws. The holes should line 7. Turn system on. motherboard model, CPU type website. up directly with the standoffs and total memory are correctly Installation underneath. Ensure all system shown. For those not using a 12. Download the latest graphics Guide power cables are connected. recommended motherboard, drivers and hotfixes at: please enter the system BIOS www.support.amd.com or www.microsoft.com setup screen as documented by For Windows 7 users, please motherboard manufacturer install updates specific to FX processors. 9. Enable A.M.P. Memory Profiles to set Memory Frequencies. For those http://support.microsoft.com/ without AMD Radeon™ Memory, kb/2645594/en-us enable XMP in the BIOS (See image http://support.microsoft.com/ at right) to ensure maximum kb/2646060/en-us © 2013 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, AMD Athlon, AMD CrossFire, AMD memory settings. -

TA960 Motherboard TA960 Specifcation
TA960 Motherboard • Socket AM3+ • Supports AMD FX Series/Phenom II Series/Athlon II Series Processors • Hyper Transport Technology up to 4.4G • Supports AMD Cool'n'Quiet Technology • Supports BIO-Remote 2 Technology • Supports Charger Booster Technology TA960 Specifcation CPU SUPPORT AMD FX™ Processor AMD Phenom™ II X6 Processor AMD Phenom™ II X4 Processor AMD Phenom™ II X3 Processor AMD Phenom™ II X2 Processor AMD Athlon™ II X4 Processor AMD Athlon™ II X3 Processor AMD Athlon™ II X2 Processor AMD Sempron™ Processor Maximum CPU TDP (Thermal Design Power) : 125Watt HT Support HT 4.4G MEMORY Support Dual Channel DDR3 800/1066/1333/1600/1866 MHz 2 x DDR3 DIMM Memory Slot Max. Supports up to 16GB Memory BIOSTAR※DDR3-1866 for AM3+ CPU only INTEGRATED VIDEO ATI Radeon™ HD3000 Graphics, On Board Graphic Max. Memory Share Up to 1024 MB STORAGE 6 x SATA II Connector 1 x IDE Connector Support SATA RAID: 0,1,10 LAN Realtek RTL8111F - 10/100/1000 Controller AUDIO CODEC Realtek ALC662 6-Channel HD Audio USB 4 x USB 2.0 Port 2 x USB 2.0 Header EXPANSION SLOT 1 x PCI-E 2.0 x16 Slot 2 x PCI-E 2.0 x1 Slot 3 x PCI Slot REAR I/O 1 x PS/2 Mouse 1 x PS/2 Keyboard 4 x USB 2.0 Port 1 x DVI Connector 1 x VGA Port 1 x LAN Port 3 x Audio Jacks INTERNAL I/O 2 x USB 2.0 Header 6 x SATA II Connector (3Gb/s ) 1 x IDE Connector 1 x Front Audio Header 1 x Front Panel Header 1 x CPU Fan Connector 2 x System Fan Connector 1 x COM Port Header 1 x Printer Port Header H/W MONITORING CPU / System Temperature Monitoring CPU / System Fan Monitoring Smart / Manual CPU Fan Control -

CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android Ios / Iphone
CPU Benchmarks Video Card Benchmarks Hard Drive Benchmarks RAM PC Systems Android iOS / iPhone CPU Benchmarks Over 1,000,000 CPUs benchmarked This chart comparing high end CPUs is made using thousands of PerformanceTest benchmark results and is updated daily. These are the high end AMD and Intel CPUs are typically those found in newer computers. The chart below compares the performance of Intel Xeon CPUs, Intel Core i7/i9 CPUs, AMD Ryzen/Threadripper CPUs and AMD Epyc with multiple cores. Intel processors vs AMD chips - find out which CPUs performance is best for your new gaming rig or server! CPU Mark Price Performance CPUS PassMark - CPU Mark High End High End CPUs High Mid Updated 17th of May 2020 Range Low Mid Range AMD Ryzen Threadripper 3990X 81,371 $3,699.99 Low End AMD EPYC 7702 71,362 $6,305.38 AMD EPYC 7742 66,679 $7,423.97 Best Value (On Market) AMD EPYC 7702P 63,910 $4,749.95 Best Value XY AMD Ryzen Threadripper 3970X 62,513 $1,899.99 Scatter AMD Ryzen Threadripper 3960X 56,017 $1,349.99 Best Value AMD EPYC 7452 53,075 $2,198.99 (All time) AMD EPYC 7502P 48,724 $2,582.02 AMD Ryzen 9 3950X 39,357 $719.99 New Desktop AMD EPYC 7402P 39,249 $1,366.53 New Laptop Intel Xeon W-3275M @ 2.50GHz 38,961 $7,453.00* AMD EPYC 7302P 38,825 $903.62 Single Thread Intel Core i9-10980XE @ 3.00GHz 34,643 $979.00* Systems with Multiple CPUs Intel Xeon W-3265 @ 2.70GHz 33,503 $4,551.37* Overclocked Intel Xeon Platinum 8268 @ 2.90GHz 33,501 $6,005.98* Power Intel Xeon W-3175X @ 3.10GHz 33,351 $3,103.99 Performance AMD Ryzen 9 3900X 32,856 $409.99 -
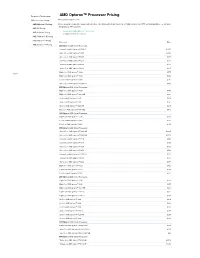
AMD Opteron\231 Processor Pricing
Products & Technologies AMD Opteron™ Processor Pricing AMD Processor Pricing Effective December 4, 2012 AMD Opteron™ Pricing Prices below are subject to change without notice. This listing reflects pricing for direct AMD customers in 1000-unit tray quantities, except when designated as PIB quantities. AMD FX Pricing Shop for all AMD Opteron™ Processors AMD A-Series Pricing Compare Server Processors AMD Phenom™ II Pricing AMD Athlon™ II Pricing Processor Price AMD Sempron™ Pricing AMD Opteron 6300 Series Processors Sixteen-Core AMD Opteron™ 6386 SE $1,392 Sixteen-Core AMD Opteron™ 6380 $1,088 Sixteen-Core AMD Opteron™ 6378 $867 Sixteen-Core AMD Opteron™ 6376 $703 Twelve-Core AMD Opteron™ 6348 $575 Twelve-Core AMD Opteron™ 6344 $415 Eight-Core AMD Opteron™ 6328 $575 Share Eight-Core AMD Opteron™ 6320 $293 Four-Core AMD Opteron™ 6308 $501 Sixteen-Core AMD Opteron™ 6366 HE $575 AMD Opteron 4300 Series Processors Eight-Core AMD Opteron™ 4386 $348 Eight-Core AMD Opteron™ 4376 HE $501 Six-Core AMD Opteron™ 4340 $348 Six-Core AMD Opteron™ 4334 $191 Six-Core AMD Opteron™ 4332 HE $415 Four-Core AMD Opteron™ 4310 EE $415 AMD Opteron 3300 Series Processors Eight-Core AMD Opteron™ 3380 $229 Four-Core AMD Opteron™ 3350 $125 Four-Core AMD Opteron™ 3320 $174 AMD Opteron 6200 Series Processors Sixteen-Core AMD Opteron™ 6284 SE $1265 Sixteen-Core AMD Opteron™ 6282 SE $1,019 Sixteen-Core AMD Opteron™ 6278 $989 Sixteen-Core AMD Opteron™ 6276 $788 Sixteen-Core AMD Opteron™ 6274 $639 Sixteen-Core AMD Opteron™ 6272 $523 Sixteen-Core AMD Opteron™ 6262 HE $523 -

Passmark - CPU Benchmarks - List of Benchmarked Cpus
PassMark - CPU Benchmarks - List of Benchmarked CPUs https://www.cpubenchmark.net/cpu_list.php CPU Mark Rank CPU Name CPU Benchmarks (higher is better) (lower is better) CPU Benchmarks Over 1,000,000 CPUs Benchmarked CPU List Below is an alphabetical list of all CPU types that appear in the charts. Clicking on a specific processor name will take you to the chart it appears in and will highlight it for you. Results for Single CPU Systems and Multiple CPU Systems are listed separately. Find CPU Single CPU Systems Multi CPU Systems Single CPU Systems Last updated on the 11th of June 2021 Column CPU Mark Rank CPU Value Price CPU Name (higher is better) (lower is better) (higher is better) (USD) AMD EPYC 7763 87,767 1 NA NA AMD Ryzen Threadripper PRO 3995WX 86,096 2 15.69 $5,486.99 AMD EPYC 7713 85,887 3 NA NA AMD Ryzen Threadripper 3990X 81,290 4 13.30 $6,110.99 AMD EPYC 7643 77,101 5 NA NA AMD EPYC 7702 71,686 6 8.43 $8,499.00 AMD Ryzen Threadripper 3970X 64,139 7 26.28 $2,440.51 AMD EPYC 7742 64,071 8 8.01 $7,995.94* AMD Ryzen Threadripper PRO 3975WX 61,259 9 22.70 $2,698.99 AMD EPYC 7702P 60,273 10 12.96 $4,650.00* AMD EPYC 7443P 58,896 11 44.05 $1,337.00* AMD EPYC 7R32 58,556 12 NA NA AMD EPYC 7542 56,809 13 13.53 $4,198.95* AMD Ryzen Threadripper 3960X 55,004 14 39.29 $1,399.99 1 z 112 11.06.2021, 11:17 PassMark - CPU Benchmarks - List of Benchmarked CPUs https://www.cpubenchmark.net/cpu_list.php CPU Mark Rank CPU Value Price CPU Name (higher is better) (lower is better) (higher is better) (USD) CPU Mark Rank CPU Name CPU Benchmarks (higher -

AMD FX Processor Quick Reference Guide
AMD FX Processor Quick Reference Guide Experience responsive game play and mega-tasking performance with AMD FX Processors. Get AMD FX in your system. AMD FX 8-Core Processor Black Edition PRODUCT FEATURES AMD FX 6-Core Processor Black Edition > World’s first native 8-core desktop processor. > Overclocking capabilities — Unlocked for a big boost in performance and speed.1 > “Bulldozer” architecture — Designed to increase core communication for unparalleled multitasking and pure core performance; also available with 6- and 4-core processors. > AMD Turbo CORE Technology — A burst of speed for the task at hand. Delivers dynamic core performance boosts depending on users’ workload at frequencies of up to 900MHz faster. > AMD OverDrive™ software — Tuning controls to push performance to the limits and monitors system stability when overclocking.1 > 32nm die shrink — Stable and smooth performance with impressive energy efficiency. > Advanced Instruction Support — accelerates a new generation of applications: Maximum Performance SSE3, SSE4.1/4.2, AVX, AES, XOP, FMA4 > More cores, the power you crave, at virtually every price point > Larger Caches — increase everyday performance with support up to 8MB L2 Cache - The industry’s only competitively priced 8-core consumer processor and 8MB L3 Cache - Designed for more speed and overall performance - Maximum power available from virtually every core configuration Operating System Compatibility - Maximum multitasking The AMD FX Processors are designed to be compatible with Windows® 7, Windows Vista® - Aggressive performance for intensive applications like video editing Home Basic, Windows Vista® Business, Windows Vista® Enterprise, Windows Professional, and 3D modeling Microsoft® Windows® XP Home Edition, Windows® XP Media Center Edition, Linux®, and other PC operating systems. -

Amd A10-4600M Apu 330,70% Amd A10-4655M Apu 320,90
AMD A10-4600M APU 330,70% AMD A10-4655M APU 320,90% AMD A10-5700 APU 511,70% AMD A10-5800K APU 530,40% AMD A4-3300 APU 168,40% AMD A4-3300M APU 151,90% AMD A4-3400 APU 146,90% AMD A4-3420 APU 175,50% AMD A6-3400M APU 203,00% AMD A6-3410MX APU 227,20% AMD A6-3420M APU 209,90% AMD A6-3430MX APU 247,60% AMD A6-3500 APU 212,90% AMD A6-3600 APU 345,00% AMD A6-3620 APU 325,40% AMD A6-3650 APU 344,00% AMD A6-3670 APU 362,00% AMD A6-4400M APU 208,50% AMD A6-5400K APU 243,00% AMD A8-3500M APU 193,00% AMD A8-3510MX APU 280,70% AMD A8-3520M APU 233,60% AMD A8-3530MX APU 257,50% AMD A8-3550MX APU 272,60% AMD A8-3800 APU 371,40% AMD A8-3820 APU 355,50% AMD A8-3850 APU 376,80% AMD A8-3870K APU 371,20% AMD A8-4500M APU 286,30% AMD A8-4555M APU 363,20% AMD A8-5500 APU 641,70% AMD A8-5600K APU 549,40% AMD Athlon 5200 Dual-Core 151,70% AMD Athlon 64 FX-62 Dual Core 161,60% AMD Athlon 64 FX-72 179,40% AMD Athlon 64 FX-74 184,10% AMD Athlon 64 X2 Dual Core 5000+ 146,00% AMD Athlon 64 X2 Dual Core 5800+ 163,90% AMD Athlon 64 X2 Dual Core 6000+ 168,00% AMD Athlon 64 X2 Dual Core 6400+ 162,10% AMD Athlon 7750 Dual-Core 154,20% AMD Athlon 7850 Dual-Core 176,70% AMD Athlon Dual Core 4850B 176,90% AMD Athlon Dual Core 5200B 146,70% AMD Athlon Dual Core 5400B 151,60% AMD Athlon Dual Core 5600B 164,50% AMD Athlon II N350 Dual-Core 153,60% AMD Athlon II N370 Dual-Core 162,90% AMD Athlon II X2 215 155,70% AMD Athlon II X2 220 149,90% AMD Athlon II X2 225 152,60% AMD Athlon II X2 235e 161,60% AMD Athlon II X2 240 178,00% AMD Athlon II X2 240e 161,00% AMD Athlon II X2