Scalable Unix Tools on Parallel Processors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Software Developement Tools Introduction to Software Building
Software Developement Tools Introduction to software building SED & friends Outline 1. an example 2. what is software building? 3. tools 4. about CMake SED & friends – Introduction to software building 2 1 an example SED & friends – Introduction to software building 3 - non-portability: works only on a Unix systems, with mpicc shortcut and MPI libraries and headers installed in standard directories - every build, we compile all files - 0 level: hit the following line: mpicc -Wall -o heat par heat par.c heat.c mat utils.c -lm - 0.1 level: write a script (bash, csh, Zsh, ...) • drawbacks: Example • we want to build the parallel program solving heat equation: SED & friends – Introduction to software building 4 - non-portability: works only on a Unix systems, with mpicc shortcut and MPI libraries and headers installed in standard directories - every build, we compile all files - 0.1 level: write a script (bash, csh, Zsh, ...) • drawbacks: Example • we want to build the parallel program solving heat equation: - 0 level: hit the following line: mpicc -Wall -o heat par heat par.c heat.c mat utils.c -lm SED & friends – Introduction to software building 4 - non-portability: works only on a Unix systems, with mpicc shortcut and MPI libraries and headers installed in standard directories - every build, we compile all files • drawbacks: Example • we want to build the parallel program solving heat equation: - 0 level: hit the following line: mpicc -Wall -o heat par heat par.c heat.c mat utils.c -lm - 0.1 level: write a script (bash, csh, Zsh, ...) SED -

CIS 90 - Lesson 2
CIS 90 - Lesson 2 Lesson Module Status • Slides - draft • Properties - done • Flash cards - NA • First minute quiz - done • Web calendar summary - done • Web book pages - gillay done • Commands - done • Lab tested – done • Print latest class roster - na • Opus accounts created for students submitting Lab 1 - • CCC Confer room whiteboard – done • Check that headset is charged - done • Backup headset charged - done • Backup slides, CCC info, handouts on flash drive - done 1 CIS 90 - Lesson 2 [ ] Has the phone bridge been added? [ ] Is recording on? [ ] Does the phone bridge have the mike? [ ] Share slides, putty, VB, eko and Chrome [ ] Disable spelling on PowerPoint 2 CIS 90 - Lesson 2 Instructor: Rich Simms Dial-in: 888-450-4821 Passcode: 761867 Emanuel Tanner Merrick Quinton Christopher Zachary Bobby Craig Jeff Yu-Chen Greg L Tommy Eric Dan M Geoffrey Marisol Jason P David Josh ? ? ? ? Leobardo Gabriel Jesse Tajvia Daniel W Jason W Terry? James? Glenn? Aroshani? ? ? ? ? ? ? = need to add (with add code) to enroll in Ken? Luis? Arturo? Greg M? Ian? this course Email me ([email protected]) a relatively current photo of your face for 3 points extra credit CIS 90 - Lesson 2 First Minute Quiz Please close your books, notes, lesson materials, forum and answer these questions in the order shown: 1. What command shows the other users logged in to the computer? 2. What is the lowest level, inner-most component of a UNIX/Linux Operating System called? 3. What part of UNIX/Linux is both a user interface and a programming language? email answers to: [email protected] 4 CIS 90 - Lesson 2 Commands Objectives Agenda • Understand how the UNIX login • Quiz operation works. -

Unix Tools 2
Unix Tools 2 Jeff Freymueller Outline § Variables as a collec9on of words § Making basic output and input § A sampler of unix tools: remote login, text processing, slicing and dicing § ssh (secure shell – use a remote computer!) § grep (“get regular expression”) § awk (a text processing language) § sed (“stream editor”) § tr (translator) § A smorgasbord of examples Variables as a collec9on of words § The shell treats variables as a collec9on of words § set files = ( file1 file2 file3 ) § This sets the variable files to have 3 “words” § If you want the whole variable, access it with $files § If you want just the second word, use $files[2] § The shell doesn’t count characters, only words Basic output: echo and cat § echo string § Writes a line to standard output containing the text string. This can be one or more words, and can include references to variables. § echo “Opening files” § echo “working on week $week” § echo –n “no carriage return at the end of this” § cat file § Sends the contents of a file to standard output Input, Output, Pipes § Output to file, vs. append to file. § > filename creates or overwrites the file filename § >> filename appends output to file filename § Take input from file, or from “inline input” § < filename take all input from file filename § <<STRING take input from the current file, using all lines un9l you get to the label STRING (see next slide for example) § Use a pipe § date | awk '{print $1}' Example of “inline input” gpsdisp << END • Many programs, especially Okmok2002-2010.disp Okmok2002-2010.vec older ones, interac9vely y prompt you to enter input Okmok2002-2010.gmtvec • You can automate (or self- y Okmok2002-2010.newdisp document) this by using << Okmok2002_mod.stacov • Standard input is set to the 5 contents of this file 5 Okmok2010.stacov between << END and END 5 • You can use any label, not 5 just “END”. -

Useful Commands in Linux and Other Tools for Quality Control
Useful commands in Linux and other tools for quality control Ignacio Aguilar INIA Uruguay 05-2018 Unix Basic Commands pwd show working directory ls list files in working directory ll as before but with more information mkdir d make a directory d cd d change to directory d Copy and moving commands To copy file cp /home/user/is . To copy file directory cp –r /home/folder . to move file aa into bb in folder test mv aa ./test/bb To delete rm yy delete the file yy rm –r xx delete the folder xx Redirections & pipe Redirection useful to read/write from file !! aa < bb program aa reads from file bb blupf90 < in aa > bb program aa write in file bb blupf90 < in > log Redirections & pipe “|” similar to redirection but instead to write to a file, passes content as input to other command tee copy standard input to standard output and save in a file echo copy stream to standard output Example: program blupf90 reads name of parameter file and writes output in terminal and in file log echo par.b90 | blupf90 | tee blup.log Other popular commands head file print first 10 lines list file page-by-page tail file print last 10 lines less file list file line-by-line or page-by-page wc –l file count lines grep text file find lines that contains text cat file1 fiel2 concatenate files sort sort file cut cuts specific columns join join lines of two files on specific columns paste paste lines of two file expand replace TAB with spaces uniq retain unique lines on a sorted file head / tail $ head pedigree.txt 1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 6 0 0 7 0 0 8 0 0 9 0 0 10 -

Basic Plotting Codes in R
The Basics of R for Windows We will use the data set timetrial.repeated.dat to learn some basic code in R for Windows. Commands will be shown in a different font, e.g., read.table, after the command line prompt, shown here as >. After you open R, type your commands after the prompt in what is called the Console window. Do not type the prompt, just the command. R stores the variables you create in a working directory. From the File menu, you need to first change the working directory to the directory where your data are stored. 1. Reading in data files Download the data file from www.biostat.umn.edu/~lynn/correlated.html to your local disk directory, go to File -> Change Directory to select that directory, and then read the data in: > contact = read.table(file="timetrial.repeated.dat", header=T) Note: if the first row of the data file had data instead of variable names, you would need to use header=F in the read.table command. Now you have named the data set contact, which you can then see in R just by typing its name: > contact or you can look at, for example, just the first 10 rows of the data set: > contact[1:10,] time sex age shape trial subj 1 2.68 M 31 Box 1 1 2 4.14 M 31 Box 2 1 3 7.22 M 31 Box 3 1 4 8.00 M 31 Box 4 1 5 7.09 M 30 Box 1 2 6 8.55 M 30 Box 2 2 7 8.79 M 30 Box 3 2 8 9.68 M 30 Box 4 2 9 6.05 M 30 Box 1 3 10 6.25 M 30 Box 2 3 This data set has 6 variables, one each in a column, where sex and shape are character valued. -
APPENDIX a Aegis and Unix Commands
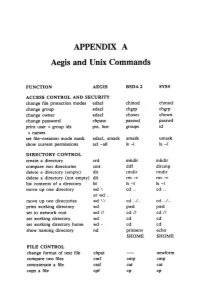
APPENDIX A Aegis and Unix Commands FUNCTION AEGIS BSD4.2 SYSS ACCESS CONTROL AND SECURITY change file protection modes edacl chmod chmod change group edacl chgrp chgrp change owner edacl chown chown change password chpass passwd passwd print user + group ids pst, lusr groups id +names set file-creation mode mask edacl, umask umask umask show current permissions acl -all Is -I Is -I DIRECTORY CONTROL create a directory crd mkdir mkdir compare two directories cmt diff dircmp delete a directory (empty) dlt rmdir rmdir delete a directory (not empty) dlt rm -r rm -r list contents of a directory ld Is -I Is -I move up one directory wd \ cd .. cd .. or wd .. move up two directories wd \\ cd . ./ .. cd . ./ .. print working directory wd pwd pwd set to network root wd II cd II cd II set working directory wd cd cd set working directory home wd- cd cd show naming directory nd printenv echo $HOME $HOME FILE CONTROL change format of text file chpat newform compare two files emf cmp cmp concatenate a file catf cat cat copy a file cpf cp cp Using and Administering an Apollo Network 265 copy std input to std output tee tee tee + files create a (symbolic) link crl In -s In -s delete a file dlf rm rm maintain an archive a ref ar ar move a file mvf mv mv dump a file dmpf od od print checksum and block- salvol -a sum sum -count of file rename a file chn mv mv search a file for a pattern fpat grep grep search or reject lines cmsrf comm comm common to 2 sorted files translate characters tic tr tr SHELL SCRIPT TOOLS condition evaluation tools existf test test -

PS TEXT EDIT Reference Manual Is Designed to Give You a Complete Is About Overview of TEDIT
Information Management Technology Library PS TEXT EDIT™ Reference Manual Abstract This manual describes PS TEXT EDIT, a multi-screen block mode text editor. It provides a complete overview of the product and instructions for using each command. Part Number 058059 Tandem Computers Incorporated Document History Edition Part Number Product Version OS Version Date First Edition 82550 A00 TEDIT B20 GUARDIAN 90 B20 October 1985 (Preliminary) Second Edition 82550 B00 TEDIT B30 GUARDIAN 90 B30 April 1986 Update 1 82242 TEDIT C00 GUARDIAN 90 C00 November 1987 Third Edition 058059 TEDIT C00 GUARDIAN 90 C00 July 1991 Note The second edition of this manual was reformatted in July 1991; no changes were made to the manual’s content at that time. New editions incorporate any updates issued since the previous edition. Copyright All rights reserved. No part of this document may be reproduced in any form, including photocopying or translation to another language, without the prior written consent of Tandem Computers Incorporated. Copyright 1991 Tandem Computers Incorporated. Contents What This Book Is About xvii Who Should Use This Book xvii How to Use This Book xvii Where to Go for More Information xix What’s New in This Update xx Section 1 Introduction to TEDIT What Is PS TEXT EDIT? 1-1 TEDIT Features 1-1 TEDIT Commands 1-2 Using TEDIT Commands 1-3 Terminals and TEDIT 1-3 Starting TEDIT 1-4 Section 2 TEDIT Topics Overview 2-1 Understanding Syntax 2-2 Note About the Examples in This Book 2-3 BALANCED-EXPRESSION 2-5 CHARACTER 2-9 058059 Tandem Computers -

Attitudes Toward Disability
School of Psychological Science Attitudes Toward Disability: The Relationship Between Attitudes Toward Disability and Frequency of Interaction with People with Disabilities (PWD) # Jennifer Kim, Taylor Locke, Emily Reed, Jackie Yates, Nicholas Zike, Mariah Es?ll, BridgeBe Graham, Erika Frandrup, Kathleen Bogart, PhD, Sam Logan, PhD, Chris?na Hospodar Introduc)on Methods Con)nued Conclusion The social and medical models of disability are sets of underlying assump?ons explaining Parcipants Connued Suppor?ng our hypothesis, the medical and social models par?ally mediated the people's beliefs about the causes and implicaons of disability. • 7.9% iden?fied as Hispanic/Lano & 91.5% did not iden?fy as Hispanic/Lano relaonship between contact and atudes towards PWD. • 2.6% iden?fied as Black/African American, 1.7% iden?fied as American Indian or Alaska • Compared to the social model, the medical model was more strongly associated • The medical model is the predominant model in the United States that is associated Nave, 23.3% iden?fied as Asian, 2.2% iden?fied as Nave Hawaiian or Pacific Islander, with contact and atudes. with the belief that disability is an undesirable status that needs to be cured (Darling & 76.7% iden?fied as White, & 2.1% iden?fied as Other • This suggests that more contact with PWD can help decrease medical model beliefs Heckert, 2010). This model focuses on the diagnosis, treatment and curave efforts • Average frequency of contact was about once a month in general, but may be slightly less effec?ve at promo?ng the social model beliefs. related to disability. -

GNU Coreutils Cheat Sheet (V1.00) Created by Peteris Krumins ([email protected], -- Good Coders Code, Great Coders Reuse)
GNU Coreutils Cheat Sheet (v1.00) Created by Peteris Krumins ([email protected], www.catonmat.net -- good coders code, great coders reuse) Utility Description Utility Description arch Print machine hardware name nproc Print the number of processors base64 Base64 encode/decode strings or files od Dump files in octal and other formats basename Strip directory and suffix from file names paste Merge lines of files cat Concatenate files and print on the standard output pathchk Check whether file names are valid or portable chcon Change SELinux context of file pinky Lightweight finger chgrp Change group ownership of files pr Convert text files for printing chmod Change permission modes of files printenv Print all or part of environment chown Change user and group ownership of files printf Format and print data chroot Run command or shell with special root directory ptx Permuted index for GNU, with keywords in their context cksum Print CRC checksum and byte counts pwd Print current directory comm Compare two sorted files line by line readlink Display value of a symbolic link cp Copy files realpath Print the resolved file name csplit Split a file into context-determined pieces rm Delete files cut Remove parts of lines of files rmdir Remove directories date Print or set the system date and time runcon Run command with specified security context dd Convert a file while copying it seq Print sequence of numbers to standard output df Summarize free disk space setuidgid Run a command with the UID and GID of a specified user dir Briefly list directory -

Lab 2: Using Commands
Lab 2: Using Commands The purpose of this lab is to explore command usage with the shell and miscellaneous UNIX commands. Preparation Everything you need to do this lab can be found in the Lesson 2 materials on the CIS 90 Calendar: http://simms-teach.com/cis90calendar.php. Review carefully all Lesson 2 slides, even those that may not have been covered in class. Check the forum at: http://oslab.cis.cabrillo.edu/forum/ for any tips and updates related to this lab. The forum is also a good place to ask questions if you get stuck or help others. If you would like some additional assistance come to the CIS Lab on campus where you can get help from instructors and student lab assistants: http://webhawks.org/~cislab/. Procedure Please log into the Opus server at oslab.cis.cabrillo.edu via port 2220. You will need to use the following commands in this lab. banner clear finger man uname bash date history passwd whatis bc echo id ps who cal exit info type Only your command history along with the three answers asked for by the submit script will be graded. You must issue each command below (exactly). Rather than submitting answers to any questions asked below you must instead issue the correct commands to answer them. Your command history will be scanned to verify each step was completed. The Shell 1. What shell are you currently using? What command did you use to determine this? (Hint: We did this in Lab 1) 2. The type command shows where a command is located. -

Contents Contents
Contents Contents CHAPTER 1 INTRODUCTION ........................................................................................ 1 The Big Picture ................................................................................................. 2 Feature Highlights............................................................................................ 3 System Requirements:.............................................................................................14 Technical Support .......................................................................................... 14 CHAPTER 2 SETUP AND QUICK START........................................................................ 15 Installing Source Insight................................................................................. 15 Installing on Windows NT/2000/XP .........................................................................15 Upgrading from Version 2.......................................................................................15 Upgrading from Version 3.0 and 3.1 ........................................................................16 Insert the CD-ROM..................................................................................................16 Choosing a Drive for the Installation .......................................................................16 Using Version 3 and Version 2 Together ...................................................................17 Configuring Source Insight .....................................................................................17 -

Using Parallel Execution Perl Program on Multiple Biohpc Lab Machines
Using parallel execution Perl program on multiple BioHPC Lab machines This Perl program is intended to run on multiple machines, and it is also possible to run multiple programs on each machine. This Perl program takes 2 arguments: /programs/bin/perlscripts/perl_fork_univ.pl JobListFile MachineFile JobListFile is a file containing all the commands to execute – one per line. MachineFile is the file with the list of machines to be used (one per line), with a number of processes to execute in parallel on this machine following the machine name: cbsumm14 24 cbsumm15 24 cbsumm16 24 Typical examples of parallel Perl driver use are cases when the number of tasks exceeds the number of cores. For example, when the number of libraries in RAN-seq project is large (say 500), you can prepare a file with all tophat tasks needed (50 lines, no ‘&’ at the end of lines!, each of them on 7 cores) and then run 9 of them at a time on 2 64 core machines (using total 63 cores on each machine – 9 instances at a time using 7 cores each). Using multiple machines is more complicated than running parallel Perl driver on a single machine. Local directory /workdir is not visible across machines so the processes will need to use home directory for files storage and communication. Also, you need to enable program execution between BioHPC Lab machines without a need to enter your password. It can be done using the following commands: cd ~ ssh-keygen -t rsa (use empty password when prompted) cat .ssh/id_rsa.pub >> .ssh/authorized_keys chmod 640 .ssh/authorized_keys chmod 700 .ssh A good example is PAML simulation on 110 genes.