Sparse Interpolation Over Finite Fields Via Low-Order Roots of Unity
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

THE DISTRIBUTION of PRIME NUMBERS Andrew Granville and K
THE DISTRIBUTION OF PRIME NUMBERS Andrew Granville and K. Soundararajan 0. Preface: Seduced by zeros 0.1. The prime number theorem, a brief history. A prime number is a positive integer which has no positive integer factors other than 1 and itself. It is difficult to determine directly from this definition whether there are many primes, indeed whether there are infinitely many. Euclid described in his Elements, an ancient Greek proof that there are infinitely many primes, a proof by contradiction, that today highlights for us the depth of abstract thinking in antiquity. So the next question is to quantify how many primes there are up to a given point. By studying tables of primes, Gauss understood, as a boy of 15 or 16 (in 1792 or 1 1793), that the primes occur with density log x at around x. In other words Z X 1 x dt π(x) := #{primes ≤ x} is approximately ≈ Li(x) where Li(x) := . log n log t n≤x 2 This leads to the conjecture that π(x)/Li(x) → 1 as x → ∞, which is hard to interpret x since Li(x) is not such a natural function. One can show that Li(x)/ log x → 1 as x → ∞, x so we can rephrase our conjecture as π(x)/ log x → 1 as x → ∞, or in less cumbersome notation that x (0.1.1) π(x) ∼ . log x It is not easy to find a strategy to prove such a result. Since primes are those integers with no prime factors less than√ or equal to their square-root, one obvious approach to counting the number of primes√ in ( x, x] is to try to estimate the number of integers up to x, with no prime factors ≤ x. -
Survey Report
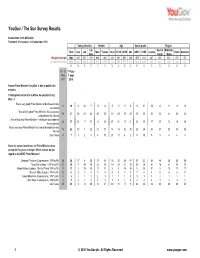
YouGov / The Sun Survey Results Sample Size: 1923 GB Adults Fieldwork: 31st August - 1st September 2010 Voting intention Gender Age Social grade Region Lib Rest of Midlands Total Con Lab Male Female 18-24 25-39 40-59 60+ ABC1 C2DE London North Scotland Dem South / Wales Weighted Sample 1923 635 557 179 938 985 232 491 661 539 1079 814 247 625 414 470 167 Unweighted Sample 1923 622 545 194 916 1007 124 505 779 515 1244 649 239 661 370 422 231 % %%% % % %%%%% % % % % % % 10 - 11 31 Aug - May 1 Sept 2007 2010 Former Prime Minister Tony Blair is due to publish his memoirs Thinking back to his time in office, do you think Tony Blair...? Was a very good Prime Minister and achieved many 11 10 4 22 7 11 8 5 11 11 8 9 11 12 8 11 9 10 successes Was a fairly good Prime Minister - his successes 38 37 23 58 42 40 35 38 43 39 29 38 35 35 32 41 43 32 outnumbered his failures Was a fairlyyp poor Prime Minister - his failures outnumbered 28 21 28 11 27 22 20 21 21 19 22 23 19 17 25 18 18 24 his successes Was a very poor Prime Minister and can be blamed for many 18 25 42 7 22 23 27 14 15 26 39 25 26 28 27 23 24 26 failures Don't know 5 7 3 2 3 4 10 21 10 4 2 5 10 9 8 6 6 8 Since the second world war, six Prime Ministers have served for five years or longer. -

Numbers 1 to 100
Numbers 1 to 100 PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Tue, 30 Nov 2010 02:36:24 UTC Contents Articles −1 (number) 1 0 (number) 3 1 (number) 12 2 (number) 17 3 (number) 23 4 (number) 32 5 (number) 42 6 (number) 50 7 (number) 58 8 (number) 73 9 (number) 77 10 (number) 82 11 (number) 88 12 (number) 94 13 (number) 102 14 (number) 107 15 (number) 111 16 (number) 114 17 (number) 118 18 (number) 124 19 (number) 127 20 (number) 132 21 (number) 136 22 (number) 140 23 (number) 144 24 (number) 148 25 (number) 152 26 (number) 155 27 (number) 158 28 (number) 162 29 (number) 165 30 (number) 168 31 (number) 172 32 (number) 175 33 (number) 179 34 (number) 182 35 (number) 185 36 (number) 188 37 (number) 191 38 (number) 193 39 (number) 196 40 (number) 199 41 (number) 204 42 (number) 207 43 (number) 214 44 (number) 217 45 (number) 220 46 (number) 222 47 (number) 225 48 (number) 229 49 (number) 232 50 (number) 235 51 (number) 238 52 (number) 241 53 (number) 243 54 (number) 246 55 (number) 248 56 (number) 251 57 (number) 255 58 (number) 258 59 (number) 260 60 (number) 263 61 (number) 267 62 (number) 270 63 (number) 272 64 (number) 274 66 (number) 277 67 (number) 280 68 (number) 282 69 (number) 284 70 (number) 286 71 (number) 289 72 (number) 292 73 (number) 296 74 (number) 298 75 (number) 301 77 (number) 302 78 (number) 305 79 (number) 307 80 (number) 309 81 (number) 311 82 (number) 313 83 (number) 315 84 (number) 318 85 (number) 320 86 (number) 323 87 (number) 326 88 (number) -

Heuristics on Class Groups: Some Good Primes Are Not Too Good
MATHEMATICSof computation VOLUME63, NUMBER207 JULY 1994, PAGES 329-334 HEURISTICS ON CLASS GROUPS: SOME GOOD PRIMES ARE NOT TOO GOOD HENRI COHEN AND JACQUESMARTINET Abstract. We correct some too optimistic predictions in an earlier paper of ours. 1 When generalizing to arbitrary relative extensions of number fields the Cohen and Lenstra heuristics of [1], it appeared that the natural hypothesis, namely not to include the p-components of the class groups for those p which divide the degree of a Galois closure, could be somewhat weakened, and we were led to the notion of a ""good prime" (cf. §2 below). Primes which do not divide the degree of the Galois closure are good, and we added some more primes to this list. In particular, 2 was considered to be a good prime for all cubic fields, though it divides the degree of the Galois closure when the field is not Galois. It was clear to us as soon as we began our work that these additional good primes could produce special difficulties [2, §3, p. 136]. However, the recent computations of G. Fung and H. Williams on nonreal cubic fields showed clearly that our recipes cannot be applied in a naive manner to the extra good primes. 2 Recall briefly some of the basic ideas of our heuristics. Let Ko be a fixed number field. We first consider (within a given algebraic closure of Q containing Ko ) a set of finite Galois extensions K/Ko with a given Galois group T (up to isomorphism) and for which the conjugacy classes of the infinite Frobenius substitutions attached to the real places of K0 are given. -

Gambling, Saving, and Lumpy Liquidity Needs Sylvan Herskowitz Online Appendix A. Additional Figures and Tables B. Sports Betting
Gambling, Saving, and Lumpy Liquidity Needs Sylvan Herskowitz Online Appendix A. Additional Figures and Tables B. Sports Betting Details B.1 Odds, Payouts, and Betting Structure B.2 Estimating the Rate of Return B.3 Characterizing Weekly Betting Profiles C. Model and Comparative Statics C.1 Demand for Gambles C.2 Increased Valuation of a Lumpy Expenditure C.3 Demand for Saving C.4 Changes in Saving Ability D. Contrasting Saving and Betting D.1 Balancing Patience and Return on Saving D.2 Estimating Return on Saving E. Additional Field Targeting Protocols 1 Appendix A: Additional Tables and Figures Figure A.1: Indirect Utility with Lumpy Good and Demand for Gambles 푉 푢 푌 − 푃 + 휂 Purchase No Purchase 푢 푌 휂 푃 푌∗ 푌 (a) Indirect utility with a lumpy good V V C E F 퐵 − 퐻 = 휎 = D + D 푚푖푛 퐵 + 푊 A + 푌 푌 ∗ ∗ 퐻 � − � � (b) Fair Gambles (c) Unfair Gambles Notes: Panel (a) shows indirect utility from income. For income levels Y > Y ∗, people will pay a price P to consume L with a utility payoff of η. Maximized utility is determined by income endowment and will be the envelope of the two pieces of the utility function. Panel (b) shows that someone with income level Y˜ will demand a fair gamble that risks reducing his income by B∗ for a chance to win W ∗ with a likelihood of winning, σ. Expected utility from the gamble is at E. Panel (c) shows that there is also demand for unfair gambles with the same loss and win amounts but win likelihood as low as σmin. -

ON the SELBERG-ERD˝OS PROOF of the PRIME NUMBER THEOREM 1. Introduction the Prime Numbers, and Specifically Their Enumerating F
ON THE SELBERG-ERDOS} PROOF OF THE PRIME NUMBER THEOREM ASHVIN A. SWAMINATHAN Abstract. In this article, we discuss the first elementary proof, due to Selberg and Erd}os, of the Prime Number Theorem. In particular, we begin with a presentation of the Selberg symmetry formula and proceed to give a detailed account of the proof as published by Erd}osin 1949. 1. Introduction The prime numbers, and specifically their enumerating function π defined by π(x) = #fprimes p : p ≤ xg; have been a source of fascination to mathematicians for thousands of years. As early as 300 BC, Euclid discussed a simple proof of the infinitude of primes (i.e. the unboundedness of π) in his famed Elements. As late as the 1700s, Euler discovered another, more informative proof that there are infinitely many primes: in fact, he showed that the primes are so frequent among the integers that the series X 1 p prime p diverges. Drawing on Euler's methods and employing inputs from complex analy- sis, like the study of Dirichlet series and Landau's Theorem, Dirichlet proved that there are infinitely many primes in arithmetic progressions. Such tools, and in particular the complex analytic properties of the Riemann ζ-function, were funda- mental in establishing the first asymptotic for π(x). As an adolescent in the late R x 1700s, Gauss had correctly posited that π(x) ∼ x= log x ∼ Li(x) := 2 dt= log t, but it took a century for his conjecture to be proven. In the 1840s via elementary methods, Chebyshev explicitly computed constants c1 < 1 < c2, both close to 1 in value, such that π(x) (1) c < < c ; 1 x= log x 2 a result that provided a partial validation of Gauss' conjecture. -

1. Company Introduction 2. Factory Facilities 3. License 4. Products 5
0 - List - 1. Company introduction 2. Factory facilities 3. License 4. products 5. Control system 6. Main reference 1 1. Company Introduction Summarize company/establishment WORLD E&C Co., Ltd / March 20, 1999 • Absorption Chiller : Double life hot water, Single effect hot water, Steam fired absorption chiller, Heat Pump Item • Absorption chiller and heater : Gas/Oil, Exhaust gas, (Integrated type, Multi type) • Screw chiller, Condensing unit • Air Handling Unit : Exhaust heat recovery type, standard type • Total asset: USD 12 Million(2017) Finance • Annual sale : USD 18 Million(2017) Plottage 10,500㎡ • Factory Factory 4,500㎡ Factory scale (Hwasung-si) Office/R&D center 750㎡ • Anyang branch 165㎡ 662, Seokpo-ri, Jangan-myeon Hwaseong-si, Kyeonggi • Head office / factory Province, Republic of Korea Address • Sales/CS 1207, Digital empire B, 906-4, Gwanyang-dong, Dongan-gu, (Anyang branch) Anyang-si, Kyeonggi Province, Republic of Korea Homepage http://www.worldenc.com/ 2 Company History 2009 Development of exhaust gas absorption chiller-heater 2017 Initiate national project of development of Heat pump and transformer 2007 Registration of patent (Double Lift Hot water Driven Absorption Chiller) Initiate national project of development of Adsorption Chiller 2006 Development of Double lift Hot water Absorption Chiller 2016 Certificate of Designation of Excellent Product by Public Procurement Development of Single Effect Hot water Driven Absorption Chiller Service Registration of Direct Fired Absorption Chiller & Heater in Certificate INNO BIZ by SMBA Korea Public Procurement Agency Certificate of green technology 2005 Registration license for making specific facility, Certificate of venture company (Double Lift Hot water Driven Absorption Chiller) Establish research affiliated with World E&C Co., Ltd. -

Subject Index
Subject Index Many of these terms are defined in the glossary, others are defined in the Prime Curios! themselves. The boldfaced entries should indicate the key entries. γ 97 Arecibo Message 55 φ 79, 184, see golden ratio arithmetic progression 34, 81, π 8, 12, 90, 102, 106, 129, 136, 104, 112, 137, 158, 205, 210, 154, 164, 172, 173, 177, 181, 214, 219, 223, 226, 227, 236 187, 218, 230, 232, 235 Armstrong number 215 5TP39 209 Ars Magna 20 ASCII 66, 158, 212, 230 absolute prime 65, 146, 251 atomic number 44, 51, 64, 65 abundant number 103, 156 Australopithecus afarensis 46 aibohphobia 19 autism 85 aliquot sequence 13, 98 autobiographical prime 192 almost-all-even-digits prime 251 averaging sets 186 almost-equipandigital prime 251 alphabet code 50, 52, 61, 65, 73, Babbage 18, 146 81, 83 Babbage (portrait) 147 alphaprime code 83, 92, 110 balanced prime 12, 48, 113, 251 alternate-digit prime 251 Balog 104, 159 Amdahl Six 38 Balog cube 104 American Mathematical Society baseball 38, 97, 101, 116, 127, 70, 102, 196, 270 129 Antikythera mechanism 44 beast number 109, 129, 202, 204 apocalyptic number 72 beastly prime 142, 155, 229, 251 Apollonius 101 bemirp 113, 191, 210, 251 Archimedean solid 19 Bernoulli number 84, 94, 102 Archimedes 25, 33, 101, 167 Bernoulli triangle 214 { Page 287 { Bertrand prime Subject Index Bertrand prime 211 composite-digit prime 59, 136, Bertrand's postulate 111, 211, 252 252 computer mouse 187 Bible 23, 45, 49, 50, 59, 72, 83, congruence 252 85, 109, 158, 194, 216, 235, congruent prime 29, 196, 203, 236 213, 222, 227, -

The Properties of RSA Key Generation Process in Software Libraries
Masaryk University Faculty of Informatics The properties of RSA key generation process in software libraries Master’s Thesis Bc. Matúš Nemec Brno, Spring 2016 Declaration Hereby I declare that this paper is my original authorial work, which I have worked out on my own. All sources, references, and literature used or excerpted during elaboration of this work are properly cited and listed in complete reference to the due source. Bc. Matúš Nemec Advisor: RNDr. Petr Švenda, Ph.D. 3 Acknowledgement Many thanks to Petr Švenda for his guidance and valuable advice. Access to computing and storage facilities owned by parties and projects contributing to the National Grid Infrastructure MetaCentrum, provided under the programme "Projects of Large Research, Development, and Innovations Infrastructures" (CESNET LM2015042), is greatly appreciated. 5 Abstract This thesis surveys cryptographic libraries and compares different approaches to RSA key generation, selection of a prime and primality testing. Attacks on RSA keys are examined and properties of weak keys are discussed. The algorithms used in practice are compared to recommendations and requirements defined in international stan- dards. Distributions of RSA keys and primes produced by different implementations are matched to corresponding algorithms. Additional properties of the keys and the key generation process are examined in order to establish criteria which make it possible to guess an algorithm based on the output of a black-box key generator. 6 Keywords RSA, cryptographic library, prime -
Introduction to Higher Mathematics Unit #4: Number Theory
Introduction to Higher Mathematics Unit #4: Number Theory Joseph H. Silverman Version Date: January 2, 2020 Contents 1 Number Theory — Lecture #1 1 1.1 What is Number Theory? . .1 1.2 Square Numbers and Triangle Numbers . .5 Exercises . 10 2 Number Theory — Lecture #2 13 2.1 Pythagorean Triples . 13 2.2 Pythagorean Triples and the Unit Circle . 18 Exercises . 20 3 Number Theory — Lecture #3 23 3.1 Divisibility and the Greatest Common Divisor . 23 3.2 Linear Equations and Greatest Common Divisors . 27 Exercises . 32 4 Number Theory — Lecture #4 37 4.1 Primes and Divisibility . 37 4.2 The Fundamental Theorem of Arithmetic . 40 Exercises . 43 5 Number Theory — Lecture #5 45 5.1 Congruences . 45 5.2 Congruences, Powers, and Fermat’s Little Theorem . 49 Exercises . 54 6 Number Theory — Lecture #6 57 6.1 Prime Numbers . 57 6.2 Counting Primes . 61 Exercises . 65 7 Number Theory — Lecture #7 69 7.1 The Fibonacci Sequence . 69 7.2 The Fibonacci Sequence Modulo m ................. 75 7.3 The Fibonacci Sequence: Supplement . 76 Draft: January 2, 2020 2 c 2018, J. Silverman CONTENTS 3 Exercises . 78 8 Number Theory — Lecture #8 83 8.1 Squares Modulo p ........................... 83 Exercises . 88 9 Number Theory — Lecture #9 91 9.1 Is −1 a Square Modulo p? Is 2?................... 91 9.2 Quadratic Reciprocity to the Rescue . 99 −1 (p−1)=2 9.3 Proof that p = (−1) [Supplement] . 102 Exercises . 105 A Class Exercise: Lecture #1: Mix and Match Number Types 107 B Class Exercise: Lecture #2: Pythagorean-Like Triples 108 C Class Exercise: Lecture #3: Least Common Multiples 109 D Class Exercise: Lecture #4: Further Travels in the E-Zone 110 E Class Exercise: Lecture #5: Polynomial Roots Modulo m 111 F Class Exercise: Lecture #6: Sums of Reciprocals 112 G Class Exercise: Lecture #7: The 3n + 1 Problem 113 H Class Exercise: Lecture #8: Cubes Modulo p 115 I Class Exercise: Lecture #9: 116 Draft: January 2, 2020 c 2018, J. -

The Points on a Shimura Variety Modulo a Prime of Good Reduction
THE POINTS ON A SHIMURA VARIETY MODULO A PRIME OF GOOD REDUCTION J. S. Milne September 8, 1991 Abstract. We explain, in the case of good reduction, the conjecture of Langlands and Rapoport describing the structure of the points on the reduction of a Shimura variety (Langlands and Rapoport 1987, 5.e, p169), and we derive from it the formula conjectured in (Kottwitz 1990, 3.1), which expresses a certain trace as a sum of products of (twisted) orbital integrals. Also we introduce the notion of an integral canonical model for a Shimura variety, and we extend the conjecture of Langlands and Rapoport to Shimura varieties defined by groups whose derived group is not simply connected. Finally, we briefly review Kottwitz’s stabilization of his formula. Contents 0. Introduction 2 1. Shimura varieties 8 2. Integral canonical models 15 3. The pseudomotivic groupoid 20 4. Statement ofthe main conjecture 31 5. The points ofSh K (G, X) with coordinates in Fq 39 6. Integral formulas 43 7. A criterion for effectiveness 48 8. Stabilization 53 Appendix A. Groupoids and tensor categories 56 Appendix B. The cohomology ofreductive groups 68 Appendix C. Relation to the trace on the intersection cohomology groups 81 References 87 Partially supported by the National Science Foundation. Not supported by the ICS, CIA, NRO, DSRP, NSA, DIA, USAF, Army, ONI, TIARA, INR, DOE, FBI, or any other intelligence agency of the United States government. 1 2J.S.MILNE 0. Introduction After giving an outline ofthe article, we discuss some ofthe history ofthe problems described here. Then we make some general comments, and list some of our notations. -

On the Greatest Prime Factor of Some Divisibility Sequences
ON THE GREATEST PRIME FACTOR OF SOME DIVISIBILITY SEQUENCES AMIR AKBARY AND SOROOSH YAZDANI ABSTRACT. Let P (m) denote the greatest prime factor of m. For integer a > 1, M. Ram Murty and S. Wong proved that, under the assumption of the ABC conjecture, n 2− P (a − 1) ,a n for any > 0. We study analogues results for the corresponding divisibility sequence over the function field Fq(t) and for some divisibility sequences associated to elliptic curves over the rational field Q. In honor of M. Ram Murty on his sixtieth birthday 1. INTRODUCTION AND RESULTS Let P (m) denote the greatest prime factor of the integer m. Several authors investigated the size of P (2n − 1). In [12, Lemma 3] Schinzel proved that P (2n − 1) ≥ 2n + 1; for n ≥ 13: In 1965, Erdos˝ [3, p. 218] conjectured that P (2n − 1) lim = 1: n!1 n This conjecture has been recently resolved by Stewart [16]. More generally, for integers a > b > 0, one can consider lower bounds in terms of n for P (an −bn). The first general result on this problem is due to Zsigmondy [18] and independently to Birkhoff and Vandiver [2] who showed that P (an − bn) ≥ n + 1: The best known result on this problem is the recent result of Stewart [16, Formula (1.8)] that states n n 1+ 1 P (a − b ) ≥ n 104 log log n ; for n sufficiently large in terms of the number of distinct prime factors of ab. Note that the above lower bound for a = 2 and b = 1 implies Erdos’˝ conjecture.