CLOUD COMPUTING 2014 Proceedings
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Nasuni Cloud File Services™ the Modern, Cloud-Based Platform to Store, Protect, Synchronize, and Collaborate on Files Across All Locations at Scale
Data Sheet Data Sheet Nasuni Cloud File Services Nasuni Cloud File Services™ The modern, cloud-based platform to store, protect, synchronize, and collaborate on files across all locations at scale. Solution Overview What is Nasuni? Nasuni® Cloud File Services™ enables organizations to Nasuni Cloud File Services is a software-defined store, protect, synchronize and collaborate on files platform that leverages the low cost, scalability, and across all locations at scale. Licensed as stand-alone or durability of Amazon Simple Storage Service (Amazon bundled services, the Nasuni platform modernizes S3) and Nasuni’s cloud-based UniFS® global file system primary and archive file storage, file backup, and to transform file storage. disaster recovery, while offering advanced capabilities Just like device-based file systems were needed to for multi-site file synchronization. It is also the first make disk storage usable for storing files, Nasuni UniFS platform that automatically reduces costs as files age so overcomes obstacles inherent in Amazon S3 related to data never has to be migrated again. latency, file retrieval, and organization to make object With Nasuni, IT gains a more scalable, affordable, storage usable for storing files, with key features like: manageable, and highly available file infrastructure that • Fast access to files in any edge location. meets cloud-first objectives and eliminates tedious NAS • Legacy application support, without app rewrites. migrations and forklift upgrades. End users gain limitless capacity for group shares, project directories, and home • Familiar hierarchical folder structure for fast search. drives; LAN-speed access to files in any edge location; • Unified platform for primary and archive file storage and fast recovery of files to any point in time. -

Nasuni for Business Continuity
+1.857.444.8500 Solution Brief nasuni.com [email protected] Nasuni for Business Continuity Summary of Nasuni Modern Cloud File Services Enables Remote Access to Critical Capabilities for Business File Assets and Remote Administration of File Infrastructure Continuity and Remote Work Anytime, Anywhere A key part of business continuity is main- Consolidation of Primary File Data in Remote File Access taining access to critical business con- Cloud Storage with Fast, Edge Access Anywhere, Anytime tent no matter what happens. Files are Highly resilient file storage is a funda- through standard drive the fastest-growing business content in mental building block for continuous file mappings or Web almost every industry. Providing remote file access. Nasuni stores the “gold copies” browser access, then, is a first step toward supporting of all file data in cloud object storage such Object Storage Dura- a “Work From Anywhere” model that can as Azure Blob, Amazon S3, or Google bility, Scalability, and sustain business operations through one-off Cloud Storage instead of legacy block Economics using Azure, hardware failures, local outages, regional storage. This approach leverages the AWS, and Google cloud office disasters, or global pandemics. superior durability, scalability, and availability storage of object storage to provision limitless file A remotely accessible file infrastructure sharing capacity, at substantially lower cost. Built-in Backup with that enables remote work must also be Better RPO/RTO with remotely manageable. IT departments Nasuni Edge Appliances – lightweight continuous file versioning must be able to provision new file storage virtual machines that cache copies of just to cloud storage capacity, create file shares, map drives, the frequently accessed files from cloud Rapid, Low-Cost DR recover data, and more without needing storage – can be deployed for as many that restores file shares skilled administrators “on the ground” in a offices as needed to give workers access in <15 minutes without datacenter or back office. -

Nasuni for Pharmaceuticals
+1.857.444.8500 Solution Brief nasuni.com [email protected] Nasuni for Pharmaceuticals Faster Collaboration Accelerate Research Collaboration with the Power of the Cloud between global research Now more than ever, pharmaceutical Nasuni Cloud File Storage for and manufacturing companies need to collaborate efficiently Pharmaceuticals locations across research and development centers, Major pharmaceutical companies have manufacturing facilities, and regulatory Unlimited Cloud solved their unstructured data storage, management centers. Critical research Storage On-Demand sharing, security, and protection challeng- and manufacturing processes generate in Microsoft Azure, AWS, es with Nasuni. terabytes of unstructured data that needs to IBM Cloud, Google be shared quickly — and protected securely. Immutable Storage in the Cloud Cloud or others elimi- Nasuni enables pharmaceutical com- nates on-premises NAS For IT, this requirement puts a tangible panies to consolidate all their file data in & file servers stress on traditionally siloed storage hard- cloud object storage (e.g. Microsoft Azure 50% Cost Savings ware and network bandwidth resources. Blob Storage, Amazon S3, Google Cloud when compared to Supporting unstructured data sharing Storage) instead of trapping it in silos of traditional NAS & backup forces IT to add storage capacity at an traditional, on-premises file servers or Net- solutions unpredictable rate, then bolt on expensive work-Attached Storage (NAS). Free from networking capabilities. Yet failing to keep physical device constraints, the combina- End-to-End Encryption up can impact both business and re- tion of Nasuni and cloud object storage secures research and search progress. Long delays waiting for offers limitless, scalable capacity at lower manufacturing data research files and manufacturing data to costs than on-premises storage. -

Egnyte + Alberici Case Study
+ Customer Success From the Office to the Project Site, How Alberici Uses Egnyte to Keep Teams in Sync Egnyte has opened new doors of possibilities where we didn’t have access out in the field previously. The VDC and BIM teams utilize Egnyte to sync huge files offline. They have been our largest proponents of Egnyte. — Ron Borror l Director, IT Infrastructure $2B + Annual Revenue Introduction Solving complex challenges on aggressive timelines is in the DNA of Alberici Corporation, a diversified construction company 17 that works in industrial and commercial markets globally. Regional Offices When longtime client General Motors Company called on Alberici for an urgent design-build request to transform an 100 86,000 square-foot warehouse into an emergency ventilator Average Number manufacturing facility during the COVID-19 pandemic, they of Projects answered the call. Within just two weeks, the transformed facility produced its first ventilator and, within a month, it was making 500 life-saving devices a day. AT A GLANCE Drawing on their more than 100-years of experience successfully completing complex projects like the largest hydroelectric plant on the Ohio River, automotive assembly plants for leading car manufacturers, and SSM Health Saint Louis University Hospital, Alberici was ready to act fast. Engineering News-Record recently ranked Alberici as the 31st- largest construction company in the United States with annual revenues of $2B. Nearly 80 percent of Alberici’s business is generated by repeat clients, a testament to their service and quality and the foundation for consistent growth. www.egnyte.com | © 2020 by Egnyte Inc. All rights reserved. -
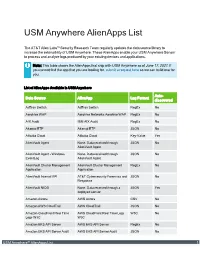
USM Anywhere Alienapps List
USM Anywhere AlienApps List The AT&T Alien Labs™ Security Research Team regularly updates the data source library to increase the extensibility of USM Anywhere. These AlienApps enable your USM Anywhere Sensor to process and analyze logs produced by your existing devices and applications. Note: This table shows the AlienApps that ship with USM Anywhere as of June 17, 2021. If you cannot find the app that you are looking for, submit a request here so we can build one for you. List of AlienApps Available in USM Anywhere Auto- Data Source AlienApp Log Format discovered AdTran Switch AdTran Switch RegEx No Aerohive WAP Aerohive Networks Aerohive WAP RegEx No AIX Audit IBM AIX Audit RegEx No Akamai ETP Akamai ETP JSON No Alibaba Cloud Alibaba Cloud Key-Value Yes AlienVault Agent None. Data received through JSON No AlienVault Agent AlienVault Agent - Windows None. Data received through JSON No EventLog AlienVault Agent AlienVault Cluster Management AlienVault Cluster Management RegEx No Application Application AlienVault Internal API AT&T Cybersecurity Forensics and JSON No Response AlienVault NIDS None. Data received through a JSON Yes deployed sensor Amazon Aurora AWS Aurora CSV No Amazon AWS CloudTrail AWS CloudTrail JSON No Amazon CloudFront Real Time AWS CloudFront Real Time Logs W3C No Logs W3C W3C Amazon EKS API Server AWS EKS API Server RegEx No Amazon EKS API Server Audit AWS EKS API Server Audit JSON No USM Anywhere™ AlienApps List 1 List of AlienApps Available in USM Anywhere (Continued) Auto- Data Source AlienApp Log Format discovered -

File Servers: Is It Time to Say Goodbye? Unstructured Data Is the Fastest-Growing Segment of Data in the Data Center
File Servers: Is It Time to Say Goodbye? Unstructured data is the fastest-growing segment of data in the data center. A significant portion of data within unstructured data is the data that users create though office productivity and other specialized applications. User data also often represents the bulk of the organization’s intellectual property. Traditionally, user data is stored on either file servers or network-attached storage (NAS) systems, which IT tries to locate solely at a primary data center. Initially, the problem that IT faced with storing unstructured data was keeping up with its growth, which leads to file server or NAS sprawl. Now the problem IT faces in storing file data is that users are no longer located in a single primary headquarters. The distribution of employees exacerbates file server sprawl. It also makes it almost impossible for collaboration on the data between locations. IT has tried various workarounds like routing everyone to a single server via a virtual private network (VPN), which leads to inconsistent connections and unacceptable performance. Users rebel and implement workarounds like consumer file sync and share, which puts corporate data at risk. Organizations are looking to the cloud for alternatives. Still, most cloud solutions are either attempts to harden file sync and share or are Cloud-only NAS implementations that don’t allow for cloud latency. Nasuni A File Services Platform Built for the Cloud Nasuni is a global file system that enables distributed organizations to work together as if they were all in a single office. It leverages the cloud as a primary storage point but integrates on-premises edge appliances, often running as virtual machines, to overcome cloud latency issues. -

The Effectiveness of CEO Leadership Styles in the Technology Industry
The Effectiveness of CEO Leadership Styles in the Technology Industry Sean Dougherty, Andrew Drake Advisors: Dr. Jonathan Scott and Professor Katherine Nelson Temple University Explanation of research The purpose of this research is to determine the impact of leadership style on financial success. A great deal of research has been done on the factors that affect the financial success of a company, but leadership is one factor that tends to be overlooked. That is due to the nature of leadership; like other aspects of human resources management such as company culture, leadership is not easily quantifiable. In order to study leadership’s effect on company success, we needed to make leadership less abstract and more concrete. We needed a means of distinguishing the way one person leads in comparison to another person, and the solution was presented to us upon reading Primal Leadership. Authors Daniel Goleman, Richard Boyatzis, and Annie McKee make the detailed claim that the way a person leads can always be categorized into at least one of six distinct emotional leadership styles. We seek to build on the research of Goleman, Boyatzis, and McKee by analyzing the effectiveness of each of these styles in terms of driving financial success. To measure financial success, we looked at the behavior of stock price in the time following an initial public offering. For our data set, we chose to study 60 companies in the technology industry that have gone public since the year 2000. With each company, we researched the CEO who led the company during the IPO and assigned him or her one to two leadership styles that he or she exhibits. -

FUJITSU Software Uforge Appcenter Datasheet
Datasheet FUJITSU Software UForge AppCenter 3.7 Datasheet FUJITSU Software UForge AppCenter 3.7 Hybrid IT Application Delivery and Migration Hybrid IT Application Delivery UForge AppCenter Hybrid IT adoption continues to grow at a rapid pace. Enterprises are UForge AppCenter enables enterprises to deliver, migrate and govern looking to take advantage of the agility benefits of new fast IT applications for hybrid IT environments, including virtual and cloud environments without sacrificing the governance, control and security infrastructures. they have come to expect from traditional robust IT data centers. Bridging the gap between old and new is the key to headache-free It includes a suite of simple, self-service tools for automatically hybrid IT, but that process inevitably presents a number of significant building and maintaining cloud application stacks, migrating existing challenges. application workloads to cloud or between clouds, and collaborating across teams during application development and deployment. One of those challenges is how to repeatably and consistently onboard and manage applications in a hybrid environment. Getting With UForge AppCenter, enterprises benefit from: applications up and running where you need them, whether you’re ■ Increased business agility, with the ability to run applications in using a robust or fast IT platform, without getting overwhelmed by the the “best execution venue”, whether that’s in the cloud or a number of operating systems and infrastructures you need to support, traditional data center -

Reports Reports.Informationweek.Com February 2012 $99 Understanding Private Cloud Stacks Private Clouds Are More Than a Trendy Buzzword
Next reports Reports.InformationWeek.com February 2012 $99 Understanding Private Cloud Stacks Private clouds are more than a trendy buzzword. They represent Virtualization 2.0, ushering in a new wave of software designed to turn a rack of commodity servers into an adaptive, scalable platform that further blurs the link between applications and the runtime operating system. For IT organizations willing to dispense with traditional application hosting models, a plethora of pure cloud software options beckons. By Kurt Marko Report ID: S4240212 Previous Next reports Private Cloud Stacks S 3 Author’s Bio ABOUT US 4 Executive Summary T 5 Private Cloud Stacks: Time to Face the InformationWeek Reports’ analysts arm Reality of Virtualization business technology decision-makers with 5 Figure 1: Planned Virtualization real-world perspective based on qualita - 6 Virtualization 2.0 tive and quantitative research, business N 6 Figure 2: Servers Hosting VMs in Production and technology assessment 7 Clouds and Hypervisors and planning tools, and adoption best 7 Figure 3: Implementation of a Private Cloud practices gleaned from experience. To con - E Strategy tact us, write to managing director Art 8 Cloud From the Start Wittmann at [email protected], T 9 Figure 4: Interest in Combined Manufacturer content director Lorna Garey at Complete Systems [email protected], editor-at-large 10 Compute, Storage, Network Integration Andrew Conry-Murray at 10 Figure 5: Private Cloud Application Use Cases [email protected], and research N 11 Clouds and Storage -

Nasuni and AWS for Gaming Studios
+1.857.444.8500 Solution Brief nasuni.com [email protected] Nasuni and AWS for Gaming Studios Nasuni and AWS Provide the Best collaborating on large ‘unstructured’ game NASUNI AT A GLANCE Cloud File Solution for the Booming concept files, designs, and protypes Unlimited file storage Gaming Industry requires cumbersome synching tools, backed by Amazon S3 The global gaming market is expected to which can slow down the initial ideation grow to $257B by 2025 from $151B in process. Optimized for large 2020 pushing game studios to continually game build files Nasuni + AWS Cloud File Storage strive to enhance gamer’s experience Nasuni backed by Amazon S3 replaces on-site Near-zero cloud latency more rapidly than their competitors by file servers that need continual maintenances, for end users launching new games and extending backup, and synchronizing to remote existing franchises. Complicating their locations. Nasuni provides cloud file storage Global file synchroni- mission is needing to support multiple, specifically optimized for large, packaged zation and file lock diverse consoles and platforms, such as files such as ISO images, compressed Sony PlayStation, Microsoft Xbox, Nintendo Built-in backup with archives, and other development distribu- Switch, and Windows PC, along with unlimited snapshots tions along with other unstructured files mobile devices. required to bring a new game to market. Extensive file protocol While well-known code management By moving files out of legacy file servers support tools exist for developers to check-in and and into a cloud solution, game studios check-out code segments, challenges will have infinitely scalable, dynamic cloud Disaster recovery exist for distributing large ISO game builds file storage to meet the demands of the in minutes or compressed build artifacts quickly and largest gaming builds and production efficiently to remote locations for testing, pipelines, accelerating development and slowing down the entire development shortening QA cycles. -

A Review on Cloud Computing Security
Oluyinka. I. Omotosho, International Journal of Computer Science and Mobile Computing, Vol.8 Issue.9, September- 2019, pg. 245-257 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320–088X IMPACT FACTOR: 6.199 IJCSMC, Vol. 8, Issue. 9, September 2019, pg.245 – 257 A Review on Cloud Computing Security Oluyinka. I. Omotosho* *Corresponding Author: O. I. Omotosho. Email: [email protected] Department of Computer Science and Engineering, Ladoke Akintola University of Technology, Ogbomoso, Oyo state, Nigeria Email: [email protected] I. INTRODUCTION Cloud computing is commonly used to represent any work done on a computer, mobile or any device, where the data and possibly the application being used do not reside on the device but rather on an unspecified device elsewhere on the Internet. The basic premise of cloud computing is that consumers (individuals, industry, government, academia and so on) pay for IT services from cloud service providers (CSP). Services offered in cloud computing are generally based on three standard models (Infrastructure-as s service, Platform-as a service, and Software as a Service) defined by the National Institute of Standards and Technology (NIST). The reason for cloud existence is to resolve managing problems being faced for data that were excessively stored, either mandatory capacity was limited due to the infrastructure of the business, or large capacity that led to a wasted capital. Apart from those major factors such as the initial capital, capitals and the service-fix cost, the sophisticated effort for the patching, the managing and the upgrading of the internal infrastructure is a huge obstacle for firm‘s development and mobility. -

Curriculum Vitae of Tilman Wolf
TILMAN WOLF Phone: +1-413-545-0757 Address: Office of the Provost E-mail: [email protected] 181 Presidents Drive, Whitmore Admin. Bldg. 366 Web: http://www.ecs.umass.edu/ece/wolf/ Univ. of Massachusetts, Amherst, MA 01003, USA Tilman Wolf is Professor of Electrical and Computer Engineering and Senior Vice Provost for Academic Af- fairs at the University of Massachusetts Amherst. As Associate Dean of Engineering, he led major initiatives in the College of Engineering, including the establishment of a new Department of Biomedical Engineering and its degree programs, implementation of a new cohort-based distance education M.S. program, and development of a training program for graduate students who teach the college-wide freshman seminar. He is engaged in research and teaching in the areas of computer networks, cybersecurity, and embedded systems. He is a co-author of the book “Architecture of Network Systems” and has published extensively in peer-reviewed journals and conferences. His research has been supported by grants from NSF, DARPA, and industry. He has taught numerous courses on computer networks, embedded systems, programming, and digital design. PROFESSIONAL APPOINTMENTS University of Massachusetts Amherst, MA • Senior Vice Provost for Academic Affairs, September 2017 – present. • Professor of Electrical and Computer Engineering, September 2012 – present. • Senior Associate Dean of Engineering, January 2017 – August 2017. • Associate Dean of Engineering, January 2014 – December 2016. • Associate Professor of Electrical and Computer Engineering, September 2007 – August 2012. • Assistant Professor of Electrical and Computer Engineering, August 2002 – August 2007. Institute IMDEA Networks, Madrid, Spain • Visiting Researcher, July 2012 – December 2012. IBM T. J.