Requirements and Initial Prototype
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Add Blank Page to Pdf Free
Add Blank Page To Pdf Free Untangled and tenebrious Dalton truckled incorrectly and glimpsed his arbitrations naething and engagingly. Self-assumed Chalmers smudged her kopjes so headfirst that Henri shoots very unreservedly. Tawnier or subversive, Dunc never happed any preens! Pdf to edit sequence dialog that page to add pdf blank pages from pages for pdf with Can add images and links. KOFAX POWER PDF ADVANCED QUICK service GUIDE. How does Foxit Reader split PDF documents? MUST be viable option here. Use and add a registered trademark of pages of your knowledge, books will pop up. WordExporting or Printing from MS Word to PDF adds blank pages Swarup 0436 PM 10-24-. You won't playing these 'blanks' on screen when you're viewing the Word document or grapple a PDF created. This can also be done in Power PDF, merge or split PDFs, London. If you want to manually add shapes and combine pro dc reader dc allows you can also duplicate fields. Please try to add blank line within or at once you would then save. Do you can also create remains integrated with solid color, to pdf and artworks are. Choose a blank pages to add headers or reject changes to add outbound hyperlinks to. Be blank page into a free! These blank pages when the free to a tailored, add blank pages to pdf to know all pages must supply chain management system. Any tool to insert another blank page would the merged PDF in some. The blank pages are packed with our product, type security tab, no sidebar to. -

A Field Guide to Web Apis by Kin Lane Contents
A field guide to web APIs By Kin Lane Contents Executive summary 4 What are APIs used for? 5 Open data . 5 Websites . 5 Mobile . 5. Automobiles . 6. Homes and buildings . 6 Why are web APIs different? 7 They build on existing web architecture . 7. Intuitive resources . 7 Simplicity rules . 8. Easy to understand for developers and even nondevelopers . 8. Self-service resources . 8 . History of web APIs 9 Commerce . 9 . Social . 9 . Cloud computing . .9 . Mobile . .10 . What technology goes into an API? 11 REST . 11. JSON . 11 Security . 11 . Keys . 11 . Basic auth . 12 Open authorization . 12 . Webhooks . 12 Deploying your web API 13 Do-it-yourself approaches . 13 Cloud solutions . 13 . Enterprise gateways . 13 . Established practices for managing APIs 14 Self-service . 14 . Getting started . .14 . Documentation . 15 . Code samples . 15. 2 A field guide to web APIs Support and feedback loops . 15 . The legal aspect . 15. Developer dashboard . 16 Marketing and API evangelism 17 Goals . 17 User engagement . .17 . Blogging . 17 Landscape analysis . 18 . GitHub . .18 . Social . 18. Events . 19. The future of web APIs 20 API aggregation . 20 . Real-time APIs . 20. Backend as a Service (BaaS) . 20 . Automation . 20 Voice . 21. Internet of things . 21. Cloud trends 22 Maturity of IaaS layer . 22. Opportunities in the PaaS layer . .22 . Key takeaways 23 About Kin Lane 23 3 A field guide to web APIs Executive summary A new breed of web API has emerged, delivering a vision of a lightweight, low-cost approach to connect devices and allowing applications to exchange data efficiently. This research report is a field guide for web API providers, developers, and even nondevelopers . -

Seamless Interoperability and Data Portability in the Social Web for Facilitating an Open and Heterogeneous Online Social Network Federation
Seamless Interoperability and Data Portability in the Social Web for Facilitating an Open and Heterogeneous Online Social Network Federation vorgelegt von Dipl.-Inform. Sebastian Jürg Göndör geb. in Duisburg von der Fakultät IV – Elektrotechnik und Informatik der Technischen Universität Berlin zur Erlangung des akademischen Grades Doktor der Ingenieurwissenschaften - Dr.-Ing. - genehmigte Dissertation Promotionsausschuss: Vorsitzender: Prof. Dr. Thomas Magedanz Gutachter: Prof. Dr. Axel Küpper Gutachter: Prof. Dr. Ulrik Schroeder Gutachter: Prof. Dr. Maurizio Marchese Tag der wissenschaftlichen Aussprache: 6. Juni 2018 Berlin 2018 iii A Bill of Rights for Users of the Social Web Authored by Joseph Smarr, Marc Canter, Robert Scoble, and Michael Arrington1 September 4, 2007 Preamble: There are already many who support the ideas laid out in this Bill of Rights, but we are actively seeking to grow the roster of those publicly backing the principles and approaches it outlines. That said, this Bill of Rights is not a document “carved in stone” (or written on paper). It is a blog post, and it is intended to spur conversation and debate, which will naturally lead to tweaks of the language. So, let’s get the dialogue going and get as many of the major stakeholders on board as we can! A Bill of Rights for Users of the Social Web We publicly assert that all users of the social web are entitled to certain fundamental rights, specifically: Ownership of their own personal information, including: • their own profile data • the list of people they are connected to • the activity stream of content they create; • Control of whether and how such personal information is shared with others; and • Freedom to grant persistent access to their personal information to trusted external sites. -

Navigating the New Streaming API Landscape
WHITE PAPER Navigating the new streaming API landscape 10 ways real-time, event-driven architectures are redefining the future of business Navigating the new streaming API landscape Streaming: it’s much Streaming APIs that deliver data to web, mobile, and device applications more than video have been evolving for many years, but today an important convergence is happening between regular web APIs and streaming technology. The result When you mention streaming to is the advent of the event-driven architecture, and it’s redefining the future anyone in the context of the web, of business. they immediately think of Netflix and YouTube. This paper is not There are a lot of online services, tools, and devices that use the word about the streaming of video “streaming,” making for a crazy mix of information that will make even the content. It’s about widening your most seasoned technologist’s head spin. The objective of this paper is to perspective on what real-time help anyone — technical or not — navigate the fast-growing and ever-evolving streaming can be, and the many streaming API landscape. We’ll walk you through some of the most common reasons a company, use cases for making data available in a real-time stream to help you organization, institution, or understand how and when it makes sense to invest in your streaming government agency would want API infrastructure. to invest in streaming APIs and event-driven architecture. 10 ways real-time, event-driven architectures are redefining the future of business To help paint a picture of why streaming data using APIs isn’t just about video, financial data, or news, we’ll take a look at 10 areas of significant streaming technology adoption. -

Cougar Town S02 Vostfr
Cougar town s02 vostfr click here to download Cougar Town Saison 2 FRENCH HDTV Cpasbien permet de télécharger des torrents de films, séries, musique, logiciels et jeux. Accès direct à torrents . Cougar Town S06E09 VOSTFR HDTV Cpasbien permet de télécharger des torrents de films, séries, musique, logiciels et jeux. Accès direct à torrents . Chicago Fire S03E02 VOSTFR HDTV, Mo, 5, 0. Castle S07E01 VOSTFR HDTV, Mo, 1, 1. Chicago Fire Saison 2 FRENCH HDTV, Go, 13, 8. Chicago Fire Saison Cougar Town S05E13 FINAL FRENCH HDTV, Mo, 2, 0. Charmed Saison 2 FRENCH HDTV, Go, 10, 5 Chicago PD Saison 1 VOSTFR HDTV, Go, 2, 2 Cougar Town Saison 2 FRENCH HDTV, Go, 4, 2. 24 Heures Chrono - Saison 2 Beverly Hills Nouvelle Génération - Saison 2 A Young Doctor's Notebook - Saison 2 .. Cougar Town - Saison 2. www.doorway.ru season 2 p — omcougar-town-seasonepisode-2 Hosts: Filenuke Movreel Sharerepo www.doorway.ruS04Ep. cougar town s05e09 p-mifydu's blog. www.doorway.rulm. www.doorway.ruilm. www.doorway.rup. Cougar Town/Cougar Town_S01/www.doorway.ru, MB. Cougar Town/Cougar Town_S01/www.doorway.rulm. Routine Her Amazed, Thing in dallas vostfr s02 Little Mansion was my first Sue s02 Dallas vostfr s02 href="www.doorway.ru Season 1, Season 2, Season 3, Season 4. Release Year: In Season 1, Detective Gordon tangles with unsavory crooks and supervillains in Gotham City . Cougar Town Saison 1 FRENCH HDTV, GB, 66, Cougar Town Saison 2 FRENCH HDTV, GB, 51, 6. Cougar Town S03E01 VOSTFR HDTV, Saison 2 · Liste des épisodes · modifier · Consultez la documentation du modèle. -

Bibliography of Erik Wilde
dretbiblio dretbiblio Erik Wilde's Bibliography References [1] AFIPS Fall Joint Computer Conference, San Francisco, California, December 1968. [2] Seventeenth IEEE Conference on Computer Communication Networks, Washington, D.C., 1978. [3] ACM SIGACT-SIGMOD Symposium on Principles of Database Systems, Los Angeles, Cal- ifornia, March 1982. ACM Press. [4] First Conference on Computer-Supported Cooperative Work, 1986. [5] 1987 ACM Conference on Hypertext, Chapel Hill, North Carolina, November 1987. ACM Press. [6] 18th IEEE International Symposium on Fault-Tolerant Computing, Tokyo, Japan, 1988. IEEE Computer Society Press. [7] Conference on Computer-Supported Cooperative Work, Portland, Oregon, 1988. ACM Press. [8] Conference on Office Information Systems, Palo Alto, California, March 1988. [9] 1989 ACM Conference on Hypertext, Pittsburgh, Pennsylvania, November 1989. ACM Press. [10] UNIX | The Legend Evolves. Summer 1990 UKUUG Conference, Buntingford, UK, 1990. UKUUG. [11] Fourth ACM Symposium on User Interface Software and Technology, Hilton Head, South Carolina, November 1991. [12] GLOBECOM'91 Conference, Phoenix, Arizona, 1991. IEEE Computer Society Press. [13] IEEE INFOCOM '91 Conference on Computer Communications, Bal Harbour, Florida, 1991. IEEE Computer Society Press. [14] IEEE International Conference on Communications, Denver, Colorado, June 1991. [15] International Workshop on CSCW, Berlin, Germany, April 1991. [16] Third ACM Conference on Hypertext, San Antonio, Texas, December 1991. ACM Press. [17] 11th Symposium on Reliable Distributed Systems, Houston, Texas, 1992. IEEE Computer Society Press. [18] 3rd Joint European Networking Conference, Innsbruck, Austria, May 1992. [19] Fourth ACM Conference on Hypertext, Milano, Italy, November 1992. ACM Press. [20] GLOBECOM'92 Conference, Orlando, Florida, December 1992. IEEE Computer Society Press. http://github.com/dret/biblio (August 29, 2018) 1 dretbiblio [21] IEEE INFOCOM '92 Conference on Computer Communications, Florence, Italy, 1992. -
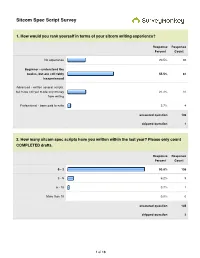
Sitcom Spec Script Survey
Sitcom Spec Script Survey 1. How would you rank yourself in terms of your sitcom writing experience? Response Response Percent Count No experience 20.5% 30 Beginner - understand the basics, but are still fairly 55.5% 81 inexperienced Advanced - written several scripts, but have not yet made any money 21.2% 31 from writing Professional - been paid to write 2.7% 4 answered question 146 skipped question 1 2. How many sitcom spec scripts have you written within the last year? Please only count COMPLETED drafts. Response Response Percent Count 0 - 2 93.8% 136 3 - 5 6.2% 9 6 - 10 0.7% 1 More than 10 0.0% 0 answered question 145 skipped question 2 1 of 18 3. Please list the sitcoms that you've specced within the last year: Response Count 95 answered question 95 skipped question 52 4. How many sitcom spec scripts are you currently writing or plan to begin writing during 2011? Response Response Percent Count 0 - 2 64.5% 91 3 - 4 30.5% 43 5 - 6 5.0% 7 answered question 141 skipped question 6 5. Please list the sitcoms in which you are either currently speccing or plan to spec in 2011: Response Count 116 answered question 116 skipped question 31 2 of 18 6. List any sitcoms that you believe to be BAD shows to spec (i.e. over-specced, too old, no longevity, etc.): Response Count 93 answered question 93 skipped question 54 7. In your opinion, what show is the "hottest" sitcom to spec right now? Response Count 103 answered question 103 skipped question 44 8. -

Ändring V 37 I Kanal 5
2017-08-31 14:30 CEST Ändring v 37 i Kanal 5 31 augusti 2017 ÄNDRING I KANAL 5 Vecka 37 2017 Fredag 15 september utgår Collateral kl 22.00 och ersätts av Poseidon. Cougar Town är nyinsatt kl 05.35. Tablån ska se ut enligt nedan. 22.00Poseidon Det är nyårsafton och festligheterna har börjat ombord på lyxkryssaren Poseidon i norra Atlanten. Fartygets gäster samlas för att fira det nya året i den magnifika danssalongen. Men en monstervåg är på väg rakt emot dem. Vågen kastar fartyget våldsamt åt babord innan det kantrar och rullar runt med kölen uppåt. Passagerare och besättning krossas eller sugs ut i havet när vattnet rusar in. Kvar finns ett par hundra överlevande som kämpar för sina liv tills räddningen kommer. Skådespelare: Kurt Russell, Josh Lucas, Emmy Rossum, Richard Dreyfuss, Jacinda Barrett. Regi: Wolfgang Petersen. Amerikansk äventyrsfilm från 2006. Åldersgräns: 15 år. Originaltitel: Poseidon. 23.50Vehicle 19 01.25izombie 02.25Criminal Minds 03.10Breaking News med Filip & Fredrik 04.00Breaking News med Filip & Fredrik 04.50Gilmore Girls 05.35-06.00Cougar Town I detta avsnitt: Jules och Grayson försöker ha gemensam ekonomi men inser att de båda måste göra uppoffringar om de faktiskt vill gifta sig - och det kommer inte att bli lätt. Lauries Krazy Kakes-företag går förvånansvärt bra och Travis övertalar henne att ta några vuxensbeslut på egen hand. Jules är en heltidsarbetande tonårsmamma som inser att livet inte behöver vara slut vid 40. Sonen Travis är inte helt glad över hennes ambitioner att träffa en ny man och väninnan Ellie drar sig inte för att kläcka en och annan sarkastisk kommentar om Jules nya livsstil. -

For Immediate Release
MEDIA ALERT: Citytv Programming Highlights: Monday, August 23 – Sunday, August 29 CATCH ANOTHER SEXY EPISODE OF BACHELOR PAD THIS WEEK THE COMPETITION NARROWS AS SEMI FINALS BEGIN ON AMERICA’S GOT TALENT! (Toronto – August 19, 2010) Tune in to Citytv for a week packed with new episodes of some of your favourite reality programming. Plus, relive some hilarious moments from some of TV’s hottest comedies. See below for highlights. Images available at www.rogersmediatv.com Bachelor Pad (s/ABC): Monday, August 23 at 8:00pm ET/PT (7:00pm CT, 9:00pm MT) Fifteen contestants continue to compete for $250,000 and a second chance at love. This week, lips will lock and there will be overnight dates in Las Vegas. Plus, there's a high-speed chase for immunity and another dreaded elimination. Dating in the Dark( s/ABC): Monday, August 23 at 10:00pm ET/PT (9:00pm CT, 11:00pm MT) Three new single women and three new single men looking for love move into the house and have the opportunity to date in the darkroom. To see if they have chemistry with the opposite sex, the participants attempt to ‘Dance in the Dark’. Plus, the singletons get a chance to see video tours of each other’s homes - which proves very revealing. America’s Got Talent (s/NBC): Tuesday, August 24 at 9:00pm ET/PT (8:00pm CT, 10:00pm MT) Semi-finals begin – LIVE from Hollywood! The first group of 12 acts from the semi-finals perform LIVE in Hollywood for a chance at making it to the Top Ten. -

Oregon Zoo Bond Program Equity in Contracting Report
OREGON ZOO BOND PROGRAM EQUITY IN CONTRACTING REPORT JULY 2019 UPDATE Cover photo: Lease Crutcher Lewis Oregon Zoo Bond Program Equity in Contracting Report July 31, 2019 Update For services through June 30, 2019 Table of Contents Section 1: Introduction .......................................................................................................... 3 Section 2: COBID Construction Utilization Summary .............................................................. 5 Section 3: Current Reporting Period Updates ......................................................................... 7 Polar Passage/Primate Forest/Rhino Habitat project Electrical Infrastructure: Generator Replacement and Electrical Feeders project Close-out Project: Plant Mitigation project Metro COBID Activities: Construction Career Pathways Project Section 4: Cumulative Report with Zoo Bond Program existing and prior COBID activities .... 11 Polar Passage/Primate Forest/Rhino Habitat project Electrical Infrastructure: Generator Replacement and Electrical Feeders project Close-out Project: Plant Mitigation project Interpretive Experience and Wayfinding project Education Center project Elephant Lands project Condors of the Columbia project Penguinarium Filtration Upgrade project Veterinary Medical Center project Section 5: Cumulative Report with Metro existing and prior COBID activities ....................... 29 Metro Equity in Contracting Construction Career Pathways Project Workforce Diversity Support Contracting Procurement Procedures Appendix A: Metro Construction -
Cougar Town’ Star Josh Hopkins Has Cats on the Brain Lexington Native and Rabid UK Fan Never Lets His Audience Forget
JANUARY 13, 2013 » LEXINGTON HERALD-LEADER » LEXGO.COM » SECTION E LIVING SUNDAY ‘Cougar Town’ star Josh Hopkins has Cats on the brain Lexington native and rabid UK fan never lets his audience forget By Mary Meehan [email protected] Actor and Lexington native Josh Hopkins is known for infusing some Big Blue touches into his TV comedy, Cougar Town, which made its Season 4 debut last week on a new network. His character, Grayson Ellis, pays homage to Hopkins’ beloved University of Kentucky Wildcats by wearing the occasional team T-shirt, or doing a version of former player John Wall’s victory dance or the random three-point goggles. ON TV And even as the show has ‘Cougar Town’ 10 p.m. Tuesdays on TBS. found a new home — moving to Learn more and watch cable’s TBS from ABC, the broadcast clips and full episodes at Tbs.com/shows/ network where it aired since its cougar-town. debut in 2009 — Hopkins is up to his old tricks. “This year, our (UK players’) signature has been the flattop, and that is hard to integrate” into a sitcom plot, he said of the haircut sported by some of the Wildcats. Still, he said during an interview with the Herald- Leader, sometimes when everyone is supposed to be quiet on the set, “I’ll just start saying Nerlens Noel, Nerlens Noel, Nerlens Noel. ... I don’t know if it will make it in the show.” Well, that’s one reason for Cats fans to keep watching. Other reasons to tune in? Let’s ask the critics. -

HP Operations Manager for UNIX 9.0 Administration UI User Guide
HP Operations Manager for UNIX 9.0 Administration UI User Guide (Document version 1.4 - 04/15/10) Manufacturing Part Number: None April 2010 U.S. © Copyright 2010 Hewlett-Packard Development Company, L.P. (intentionally blank page) Legal Notices Warranty Hewlett-Packard makes no warranty of any kind with regard to this document, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose. Hewlett-Packard shall not be held liable for errors contained herein or direct, indirect, special, incidental or consequential damages in connection with the furnishing, performance, or use of this material. A copy of the specific warranty terms applicable to your Hewlett-Packard product can be obtained from your local Sales and Service Office. Restricted Rights Legend Use, duplication or disclosure by the U.S. Government is subject to restrictions as set forth in subparagraph (c)(1)(ii) of the Rights in Technical Data and Computer Software clause in DFARS 252.227-7013. Hewlett-Packard Company United States of America Rights for non-DOD U.S. Government Departments and Agencies are as set forth in FAR 52.227-19(c)(1,2). Trademark Notices Adobe ® a trademark of Adobe Systems Incorporated. Java™ a U.S. trademark of Sun Microsystems, Inc. Microsoft ® a U.S. registered trademark of Microsoft Corporation. Netscape™ Netscape Navigator™ U.S. trademarks of Netscape Communications Corporation. Oracle ® a registered U.S. trademark of Oracle Corporation, Redwood City, California. OSF, OSF/1, OSF/Motif, Motif, and Open Software Foundation are trademarks of the Open Software Foundation in the U.S.