Chapter Three Cloud-Inotify: Cloud-Wide File Events
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ivoyeur: Inotify
COLUMNS iVoyeur inotify DAVE JOSEPHSEN Dave Josephsen is the he last time I changed jobs, the magnitude of the change didn’t really author of Building a sink in until the morning of my first day, when I took a different com- Monitoring Infrastructure bination of freeways to work. The difference was accentuated by the with Nagios (Prentice Hall T PTR, 2007) and is Senior fact that the new commute began the same as the old one, but on this morn- Systems Engineer at DBG, Inc., where he ing, at a particular interchange, I would zig where before I zagged. maintains a gaggle of geographically dispersed It was an unexpectedly emotional and profound metaphor for the change. My old place was server farms. He won LISA ‘04’s Best Paper off to the side, and down below, while my future was straight ahead, and literally under award for his co-authored work on spam construction. mitigation, and he donates his spare time to the SourceMage GNU Linux Project. The fact that it was under construction was poetic but not surprising. Most of the roads I [email protected] travel in the Dallas/Fort Worth area are under construction and have been for as long as anyone can remember. And I don’t mean a lane closed here or there. Our roads drift and wan- der like leaves in the water—here today and tomorrow over there. The exits and entrances, neither a part of this road or that, seem unable to anticipate the movements of their brethren, and are constantly forced to react. -

Monitoring File Events
MONITORING FILE EVENTS Some applications need to be able to monitor files or directories in order to deter- mine whether events have occurred for the monitored objects. For example, a graphical file manager needs to be able to determine when files are added or removed from the directory that is currently being displayed, or a daemon may want to monitor its configuration file in order to know if the file has been changed. Starting with kernel 2.6.13, Linux provides the inotify mechanism, which allows an application to monitor file events. This chapter describes the use of inotify. The inotify mechanism replaces an older mechanism, dnotify, which provided a subset of the functionality of inotify. We describe dnotify briefly at the end of this chapter, focusing on why inotify is better. The inotify and dnotify mechanisms are Linux-specific. (A few other systems provide similar mechanisms. For example, the BSDs provide the kqueue API.) A few libraries provide an API that is more abstract and portable than inotify and dnotify. The use of these libraries may be preferable for some applications. Some of these libraries employ inotify or dnotify, on systems where they are available. Two such libraries are FAM (File Alteration Monitor, http:// oss.sgi.com/projects/fam/) and Gamin (http://www.gnome.org/~veillard/gamin/). 19.1 Overview The key steps in the use of the inotify API are as follows: 1. The application uses inotify_init() to create an inotify instance. This system call returns a file descriptor that is used to refer to the inotify instance in later operations. -

Fsmonitor: Scalable File System Monitoring for Arbitrary Storage Systems
FSMonitor: Scalable File System Monitoring for Arbitrary Storage Systems Arnab K. Paul∗, Ryan Chardy, Kyle Chardz, Steven Tueckez, Ali R. Butt∗, Ian Fostery;z ∗Virginia Tech, yArgonne National Laboratory, zUniversity of Chicago fakpaul, [email protected], frchard, [email protected], fchard, [email protected] Abstract—Data automation, monitoring, and management enable programmatic management, and even autonomously tools are reliant on being able to detect, report, and respond manage the health of the system. Enabling scalable, reliable, to file system events. Various data event reporting tools exist for and standardized event detection and reporting will also be of specific operating systems and storage devices, such as inotify for Linux, kqueue for BSD, and FSEvents for macOS. How- value to a range of infrastructures and tools, such as Software ever, these tools are not designed to monitor distributed file Defined CyberInfrastructure (SDCI) [14], auditing [9], and systems. Indeed, many cannot scale to monitor many thousands automating analytical pipelines [11]. Such systems enable of directories, or simply cannot be applied to distributed file automation by allowing programs to respond to file events systems. Moreover, each tool implements a custom API and and initiate tasks. event representation, making the development of generalized and portable event-based applications challenging. As file systems Most storage systems provide mechanisms to detect and grow in size and become increasingly diverse, there is a need report data events, such as file creation, modification, and for scalable monitoring solutions that can be applied to a wide deletion. Tools such as inotify [20], kqueue [18], and FileSys- range of both distributed and local systems. -
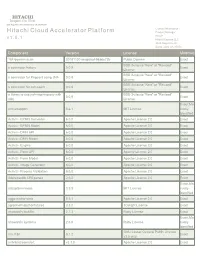
Hitachi Cloud Accelerator Platform Product Manager HCAP V 1
HITACHI Inspire the Next 2535 Augustine Drive Santa Clara, CA 95054 USA Contact Information : Hitachi Cloud Accelerator Platform Product Manager HCAP v 1 . 5 . 1 Hitachi Vantara LLC 2535 Augustine Dr. Santa Clara CA 95054 Component Version License Modified 18F/domain-scan 20181130-snapshot-988de72b Public Domain Exact BSD 3-clause "New" or "Revised" a connector factory 0.0.9 Exact License BSD 3-clause "New" or "Revised" a connector for Pageant using JNA 0.0.9 Exact License BSD 3-clause "New" or "Revised" a connector for ssh-agent 0.0.9 Exact License a library to use jsch-agent-proxy with BSD 3-clause "New" or "Revised" 0.0.9 Exact sshj License Exact,Ma activesupport 5.2.1 MIT License nually Identified Activiti - BPMN Converter 6.0.0 Apache License 2.0 Exact Activiti - BPMN Model 6.0.0 Apache License 2.0 Exact Activiti - DMN API 6.0.0 Apache License 2.0 Exact Activiti - DMN Model 6.0.0 Apache License 2.0 Exact Activiti - Engine 6.0.0 Apache License 2.0 Exact Activiti - Form API 6.0.0 Apache License 2.0 Exact Activiti - Form Model 6.0.0 Apache License 2.0 Exact Activiti - Image Generator 6.0.0 Apache License 2.0 Exact Activiti - Process Validation 6.0.0 Apache License 2.0 Exact Addressable URI parser 2.5.2 Apache License 2.0 Exact Exact,Ma adzap/timeliness 0.3.8 MIT License nually Identified aggs-matrix-stats 5.5.1 Apache License 2.0 Exact agronholm/pythonfutures 3.3.0 3Delight License Exact ahoward's lockfile 2.1.3 Ruby License Exact Exact,Ma ahoward's systemu 2.6.5 Ruby License nually Identified GNU Lesser General Public License ai's -

Displaying and Watching Directories Using Lazarus
Displaying and Watching directories using Lazarus Michaël Van Canneyt October 31, 2011 Abstract Using Lazarus, getting the contents of a directory can be done in 2 ways: a portable, and a unix-specific way. This article shows how to get the contents of a directory and show it in a window. Additionally, it shows how to get notifications of the Linux kernel if the contents of the directory changes. 1 Introduction Examining the contents of a directory is a common operation, both using command-line tools or a GUI file manager. Naturally, Free/Pascal and Lazarus offer an API to do this. In fact, there are 2 API’s to get the contents of a directory: one which is portable and will work on all platforms supported by Lazarus. The other is not portable, but resembles closely the POSIX API for dealing with files and directories. Each API has its advantages and disadvantages. Often, it is desirable to be notified if the contents of a directory changes: in a file manager, this can be used to update the display - showing new items or removing items as needed. This can also be done by scanning the contents of the directory at regular intervals, but it should be obvious that this is not as efficient. There are other scenarios when a notification of a change in a directory is interesting: for instance, in a FTP server, one may want to move incoming files to a location outside the FTP tree, or to a new location based on some rules (e.g. images to one directory, sound files to another). -

Battle-Hardened Upstart Linux Plumbers 2013
Battle-Hardened Upstart Linux Plumbers 2013 James Hunt <[email protected]> and Dmitrijs Ledkovs <[email protected]> September, 2013 Table of Contents Utilities 1. Overview 3. Enablements 2. Design and Architecture cloud-init Event-based Design friendly-recovery Example Job gpg-key-compose SystemV Support Summary SystemV Runlevels 4. Quality Checks Bridges 5. Areas of Friction More Events 6. Links . 2 / 31 Overview of Upstart Revolutionary event-based /sbin/init system. Written by Scott James Remnant (Canonical, Google). Maintained by Canonical. Developed by Canonical and the community. PID 1 on every Ubuntu system since 2006 (introduced in Ubuntu 6.10 "Edgy Eft"). Systems booted using native Upstart jobs (not SysVinit compat) since Ubuntu 9.10 ("Karmic Koala") in 2009. Handles system boot and shutdown and supervises services. Provides legacy support for SystemV services. Upstart is a first-class citizen in Debian ([Debian Policy]). 3 / 31 Availability and Usage Runs on any modern Linux system. Used by... 6.10 ! 11.3/11.4 RHEL6 ChromeOS Now available in... 4 / 31 Platform Presence Upstart runs on all types of systems: Desktop systems Servers Embedded devices Thin clients (such as ChromeBooks, Edubuntu) Cloud instances Tablets Phones (Ubuntu Touch) . 5 / 31 Cloud Upstart is the #1 init system used in the cloud (through Ubuntu). Ubuntu, and thus Upstart, is used by lots of large well-known companies such as: HP AT&T Wikipedia Ericsson Rackspace Instagram twitpic … Companies moving to Ubuntu... Netflix . Hulu eBay 6 / 31 Versatility Upstart is simple and versatile The /sbin/init daemon only knows about events and processes: it doesn't dictate runlevel policy. -

Remote Filesystem Event Notification and Processing for Distributed Systems
ICDT 2021 : The Sixteenth International Conference on Digital Telecommunications Remote Filesystem Event Notification and Processing for Distributed Systems Kushal Thapa†‡, Vinay Lokesh*#, Stan McClellan†§ †Ingram School of Engineering *Dept. of Computer Science Texas State University San Marcos, TX, USA e-mail: ‡[email protected], #[email protected], §[email protected] Abstract— Monitoring and safeguarding the integrity of files networking solutions and architectures allow the users to in local filesystems is imperative to computer systems for many circumvent certain firewall restrictions, thus increasing purposes, including system security, data acquisition, and other complexity while introducing security risks. Here, we leverage processing requirements. However, distributed systems may the well-known network architecture where an Internet- have difficulty in monitoring remote filesystem events even reachable system acts as a middleman to establish a secure, though asynchronous notification of filesystem events on a bidirectional network connection between firewalled devices. remote, resource-constrained device can be very useful. This This approach is not new, however, comprehensive analysis paper discusses several aspects of monitoring remote filesystem of various parameters is difficult to obtain, so we provide some events in a loosely-coupled and distributed architecture. This results and discussion regarding the various configuration paper investigates a simple and scalable technique to enable secure remote file system monitoring using existing Operating options and performance of this architecture. System resident tools with minimum overhead. In Section II of this paper, we describe various tools that are generally used to monitor local filesystem events. We also Keywords— Secure Remote Filesystem Monitoring; Firewall; briefly discuss about Secure Shell Protocol Filesystem Distributed Architecture; Secure Network Communication; SSH; (SSHFS) [9] and Secure Shell Protocol (SSH) [12]. -

E:\Ghcstop\AESOP Ghcstop Doc\Kernel\Ramdisk Howto\060405-Aesop2440-Ramdisk-Howto.Txt 200 06-04-06, 12:43:53오후 Aesop 2440 Kernel 2.6.13 Ramdisk Howto
파일: E:\ghcstop\AESOP_ghcstop_doc\kernel\ramdisk_howto\060405-aesop2440-ramdisk-howto.txt 200 06-04-06, 12:43:53오후 aesop 2440 kernel 2.6.13 ramdisk howto - 20060406(까먹고 민방위 못간날...^^) by godori 1. kernel설정을 다음과 같이 바꾼다. Device Drivers -> Block device쪽을 보시면.... Linux Kernel v2.6.13-h1940-aesop2440 Configuration qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq lqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq Block devices qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqk x Arrow keys navigate the menu. <Enter> selects submenus --->. x x Highlighted letters are hotkeys. Pressing <Y> includes, <N> excludes, x x <M> modularizes features. Press <Esc><Esc> to exit, <?> for Help, </> x x for Search. Legend: [*] built-in [ ] excluded <M> module < > module x x lqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqk x x x < > XT hard disk support x x x x <*> Loopback device support x x x x < > Cryptoloop Support x x x x <*> Network block device support x x x x < > Low Performance USB Block driver x x x x <*> RAM disk support x x x x (8) Default number of RAM disks x x x x (8192) Default RAM disk size (kbytes) x x x x [*] Initial RAM disk (initrd) support x x x x () Initramfs source file(s) x x x x < > Packet writing on CD/DVD media x x x x IO Schedulers ---> x x x x < > ATA over Ethernet support x x x x x x x x x x x x x x x x x x x mqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqj x tqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqu x <Select> < Exit > < Help > x mqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqj 여기서 8192 는 ramdisk size 입니다 . 만드는 ramdisk 크기에 맞게끔 바꿔주시고... File systems쪽에서 Linux Kernel v2.6.13-h1940-aesop2440 Configuration qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq lqqqqqqqqqqqqqqqqqqqqqqqqqqqqqq File systems qqqqqqqqqqqqqqqqqqqqqqqqqqqqqqqk x Arrow keys navigate the menu. -

Conflict Resolution Via Containerless Filesystem Virtualization
Dependency Heaven: Conflict Resolution via Containerless Filesystem Virtualization Anonymous Author(s) Abstract previous installation, effectively preventing concurrent ver- Resolving dependency versioning conflicts in applications sions of that library from coexisting. The same is true for is a long-standing problem in software development and packages whose executable names does not change across deployment. Containers have become a popular way to ad- releases; unless the user renames the existing executable dress this problem, allowing programs to be distributed in a files prior to the installation of a new version it is notpos- portable fashion and to run them under strict security con- sible to keep both installations around. The problem with straints. Due to the popularity of this approach, its use has that approach is that it breaks package managers, as the re- started to extend beyond its original aim, with users often named files will not be featured in the package manager’s creating containers bundling entire Linux distributions to database and, consequently, will not be tracked anymore. run mundane executables, incurring hidden performance Further, unless executables depending on the renamed files and maintenance costs. This paper presents an alternative are modified to reflect their new path, users need todefine approach to the problem of versioning resolution applied to which executable to activate at a given time, usually through locally-installed applications, through a virtualization tool tricky management of symbolic -

Hubblestack Documentation Release 2016.7.1
HubbleStack Documentation Release 2016.7.1 Christer Edwards Nov 10, 2016 Contents 1 Components 3 i ii HubbleStack Documentation, Release 2016.7.1 Welcome to the HubbleStack documentation! Hubble is a modular, open-source security compliance framework built on top of SaltStack. The project provides on- demand profile-based auditing, real-time security event notifications, automated remediation, alerting and reporting. Hubble can “dock” with any existing SaltStack installation, and requires very little work to get started. This document describes installation, configuration and general use. Contents 1 HubbleStack Documentation, Release 2016.7.1 2 Contents CHAPTER 1 Components Hubble is made up of four different components, each playing a role in the overall auditing of your systems. These components are described here: • Nova - Nova is Hubble’s profile-based auditing engine. • Pulsar - Pulsar is Hubble’s real-time event system. • Nebula- Nebula is Hubble’s security snapshot utility. • Quasar - Quasar is Hubble’s flexible reporting suite. Each of these components are modular, flexible, and easy to drop into place for any size infrastructure. While each of these components can be used standalone it is often required to combine each components with it’s corresponding Quasar module. Quasar modules are what connects Nova, Nebula and Pulsar to external endpoints such as Splunk, Slack, etc. New to HubbleStack? Explore some of these topics: 1.1 Nova Nova is the best place to get started with Hubble. Using pre-built security and compliance “profiles”, Nova will give you a complete picture of your security stance. Check out the installation docs: • Package Installation (stable) • Manual Installation (develop) Have a look at the Nova module list, and learn how audit modules work. -

FAQ Release V1
FAQ Release v1 The Syncthing Authors Jul 28, 2020 CONTENTS 1 What is Syncthing?1 2 Is it “syncthing”, “Syncthing” or “SyncThing”?3 3 How does Syncthing differ from BitTorrent/Resilio Sync?5 4 What things are synced?7 5 Is synchronization fast?9 6 Why is the sync so slow? 11 7 Why does it use so much CPU? 13 8 Should I keep my device IDs secret? 15 9 What if there is a conflict? 17 10 How do I serve a folder from a read only filesystem? 19 11 I really hate the .stfolder directory, can I remove it? 21 12 Am I able to nest shared folders in Syncthing? 23 13 How do I rename/move a synced folder? 25 14 How do I configure multiple users on a single machine? 27 15 Does Syncthing support syncing between folders on the same system? 29 16 When I do have two distinct Syncthing-managed folders on two hosts, how does Syncthing handle moving files between them? 31 17 Is Syncthing my ideal backup application? 33 18 Why is there no iOS client? 35 19 How can I exclude files with brackets ([]) in the name? 37 20 Why is the setup more complicated than BitTorrent/Resilio Sync? 39 21 How do I access the web GUI from another computer? 41 i 22 Why do I get “Host check error” in the GUI/API? 43 23 My Syncthing database is corrupt 45 24 I don’t like the GUI or the theme. Can it be changed? 47 25 Why do I see Syncthing twice in task manager? 49 26 Where do Syncthing logs go to? 51 27 How can I view the history of changes? 53 28 Does the audit log contain every change? 55 29 How do I upgrade Syncthing? 57 30 Where do I find the latest release? 59 31 How do I run Syncthing as a daemon process on Linux? 61 32 How do I increase the inotify limit to get my filesystem watcher to work? 63 33 How do I reset the GUI password? 65 ii CHAPTER ONE WHAT IS SYNCTHING? Syncthing is an application that lets you synchronize your files across multiple devices. -

Red Hat Enterprise Linux 7 7.8 Release Notes
Red Hat Enterprise Linux 7 7.8 Release Notes Release Notes for Red Hat Enterprise Linux 7.8 Last Updated: 2021-03-02 Red Hat Enterprise Linux 7 7.8 Release Notes Release Notes for Red Hat Enterprise Linux 7.8 Legal Notice Copyright © 2021 Red Hat, Inc. The text of and illustrations in this document are licensed by Red Hat under a Creative Commons Attribution–Share Alike 3.0 Unported license ("CC-BY-SA"). An explanation of CC-BY-SA is available at http://creativecommons.org/licenses/by-sa/3.0/ . In accordance with CC-BY-SA, if you distribute this document or an adaptation of it, you must provide the URL for the original version. Red Hat, as the licensor of this document, waives the right to enforce, and agrees not to assert, Section 4d of CC-BY-SA to the fullest extent permitted by applicable law. Red Hat, Red Hat Enterprise Linux, the Shadowman logo, the Red Hat logo, JBoss, OpenShift, Fedora, the Infinity logo, and RHCE are trademarks of Red Hat, Inc., registered in the United States and other countries. Linux ® is the registered trademark of Linus Torvalds in the United States and other countries. Java ® is a registered trademark of Oracle and/or its affiliates. XFS ® is a trademark of Silicon Graphics International Corp. or its subsidiaries in the United States and/or other countries. MySQL ® is a registered trademark of MySQL AB in the United States, the European Union and other countries. Node.js ® is an official trademark of Joyent. Red Hat is not formally related to or endorsed by the official Joyent Node.js open source or commercial project.