Improving a Wireless Localization System Via Machine Learning Techniques and Security Protocols
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Manual of Avionics by Brian Kendal
Manual of Avionics 11 :q I LNVM 81453 11111111111111111 IIIII IIIII IIII IIII Library © Brian Kendal 1979, 1987, 1993 A catalogue record for this title is available from the British Library Blackwell Science Ltd, ISBN 1-4051-4654-0 Editorial Offices: 9600 Garsington Road, Oxford OX4 2DQ, UK Library of Congress Tel: +44 (0)1865 776868 Cataloging-in-Publication Data 25 John Street, London WClN 2BL 23 Ainslie Place, Edinburgh EH3 6AJ Kendal, Brian 350 Main Street, Malden, Manual of avionics: an introduction to the MA 02148-5020, USA electronics of civil aviation/ Brian Kendal. 54 University Street, Carlton p. cm. Victoria 3053, Australia Includes index. 10, rue Casimir Delavigne ISBN 1-4051-4654-0 75006 Paris, France I. Avionics. I. Title. TL695.K46 1993 Other Editorial Offices: 629.135-dc20 92-28100 CIP Blackwell Wissenschafts-Verlag GmbH Kurfiirstendamm 57 For further information on 10707 Berlin, Germany Blackwell Publishing, visit our website: www.blackwellpublishing.com Blackwell Science KK MG Kodenmacho Building Licensed for sale in India, Nepal, Bhutan, 7-10 Kodenmacho Nihombashi Bangladesh and Sri Lanka only. Sale and Chuo-ku, Tokyo 104, Japan purchase of this edition outside these territories is unauthorized by the publishers. The right of the Author to be identified as the Author of this Work has been asserted in accordance with the Copyright, Designs and Patents Act 1988. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, except as permitted by the UK Copyright, Designs and Patents Act 1988, without the prior permission of the publisher. -

A History of Maritime Radio- Navigation Positioning Systems Used in Poland
THE JOURNAL OF NAVIGATION (2016), 69, 468–480. © The Royal Institute of Navigation 2016 This is an Open Access article, distributed under the terms of the Creative Commons Attribution licence (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted re-use, distribution, and reproduction in any medium, provided the original work is properly cited. doi:10.1017/S0373463315000879 A History of Maritime Radio- Navigation Positioning Systems used in Poland Cezary Specht, Adam Weintrit and Mariusz Specht (Gdynia Maritime University, Gdynia, Poland) (E-mail: [email protected]) This paper describes the genesis, the principle of operation and characteristics of selected radio-navigation positioning systems, which in addition to terrestrial methods formed a system of navigational marking constituting the primary method for determining the location in the sea areas of Poland in the years 1948–2000, and sometimes even later. The major ones are: maritime circular radiobeacons (RC), Decca-Navigator System (DNS) and Differential GPS (DGPS), as well as solutions forgotten today: AD-2 and SYLEDIS. In this paper, due to its limited volume, the authors have omitted the description of the solutions used by the Polish Navy (RYM, BRAS, JEMIOŁUSZKA, TSIKADA) and the global or continental systems (TRANSIT, GPS, GLONASS, OMEGA, EGNOS, LORAN, CONSOL) - described widely in world literature. KEYWORDS 1. Radio-Navigation. 2. Positioning systems. 3. Decca-Navigator System (DNS). 4. Maritime circular radiobeacons (RC). 5. AD-2 system. 6. SYLEDIS. 7. Differential GPS (DGPS). Submitted: 21 June 2015. Accepted: 30 October 2015. First published online: 11 January 2016. 1. INTRODUCTION. Navigation is the process of object motion control (Specht, 2007), thus determination of position is its essence. -

A History of Maritime Radio- Navigation Positioning Systems Used in Poland
THE JOURNAL OF NAVIGATION (2016), 69, 468–480. © The Royal Institute of Navigation 2016 This is an Open Access article, distributed under the terms of the Creative Commons Attribution licence (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted re-use, distribution, and reproduction in any medium, provided the original work is properly cited. doi:10.1017/S0373463315000879 A History of Maritime Radio- Navigation Positioning Systems used in Poland Cezary Specht, Adam Weintrit and Mariusz Specht (Gdynia Maritime University, Gdynia, Poland) (E-mail: [email protected]) This paper describes the genesis, the principle of operation and characteristics of selected radio-navigation positioning systems, which in addition to terrestrial methods formed a system of navigational marking constituting the primary method for determining the location in the sea areas of Poland in the years 1948–2000, and sometimes even later. The major ones are: maritime circular radiobeacons (RC), Decca-Navigator System (DNS) and Differential GPS (DGPS), as well as solutions forgotten today: AD-2 and SYLEDIS. In this paper, due to its limited volume, the authors have omitted the description of the solutions used by the Polish Navy (RYM, BRAS, JEMIOŁUSZKA, TSIKADA) and the global or continental systems (TRANSIT, GPS, GLONASS, OMEGA, EGNOS, LORAN, CONSOL) - described widely in world literature. KEYWORDS 1. Radio-Navigation. 2. Positioning systems. 3. Decca-Navigator System (DNS). 4. Maritime circular radiobeacons (RC). 5. AD-2 system. 6. SYLEDIS. 7. Differential GPS (DGPS). Submitted: 21 June 2015. Accepted: 30 October 2015. First published online: 11 January 2016. 1. INTRODUCTION. Navigation is the process of object motion control (Specht, 2007), thus determination of position is its essence. -

TECHNICAL DEVELOPMENTS in DEPTH MEASUREMENT TECHNIQUES and POSITION DETERMINATION from 1960 to 1980 by Dave Wells and Steve Grant
“Charting the Secret World of the Ocean Floor : The GEBCO Project 1903-2003” 1 TECHNICAL DEVELOPMENTS IN DEPTH MEASUREMENT TECHNIQUES AND POSITION DETERMINATION FROM 1960 TO 1980 By Dave Wells and Steve Grant EXECUTIVE SUMMARY In this paper we describe the evolution during these two decades from simple single-beam echosounders using horizontal sextant fixing (near shore), and celestial sextant positioning interpolated by dead reckoning (offshore) to (a) (For depth measurement techniques) sidescan sonar, digital echosounders, the first (classified) SASS and Seabeam multibeam systems, and early satellite altimetry, and (b) (For positioning determination) a plethora of short and long range radio positioning systems, the Transit satellite positioning system, the early designs for GPS, long and short baseline acoustic systems, and (c) How these developments have since impacted the data available to GEBCO BIOGRAPHIES Dave Wells and Steve Grant worked together at the Bedford Institute of Oceanography for several years during the 1970s on some of the developments discussed in this paper, as part of the Canadian Hydrographic Service Navigation Group headed by Mike Eaton. Steve “retired” in 1996 but still works on a variety of hydrographic consulting and teaching projects. Dave “retired” in 1980 and again in 1998, but still teaches at three universities. INTRODUCTION During the period from 1960 to 1980, many remarkable advances were made in the technologies applicable to depth measurement and positioning at sea. Some of the initial technological developments dating from those two decades remain the basis for the most modern and effective bathymetric and positioning systems in use today. Others reached productive fruition earlier, and have since been supplanted. -
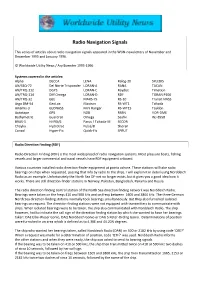
Radio Navigation Signals
Radio Navigation Signals This series of articles about radio navigation signals appeared in the WUN-newsletters of November and December 1995 and January 1996. © Worldwide Utility News / Ary Boender 1995-1996 Systems covered in the articles: Alpha DECCA LENA Ralog-20 SYLEDIS AN/SSQ-72 Del Norte Trisponder LORAN-A RANA TACAN AN/TRQ-112 DGPS LORAN-C Raydist Timation AN/TRQ-114 Diff Omega LORAN-D RDF TORAN P100 AN/TRQ-32 GEE MARS-75 RS-10 Transit NNSS Argo DM-54 GeoLoc Maxiran RS-WT1 Tsikada Artemis-3 GLONASS Mini Ranger RS-WT1S Tsyklon Autotape GPS NDB RSBN VOR-DME Bathymetric Guardrail Omega Seafix WJ-8958 BRAS-3 HI-FIX/6 Parus / Tsikada-M SECOR Chayka Hydrotrac Pulse/8 Shoran Consol Hyper-Fix Quick-Fix SPRUT Radio Direction Finding (RDF) Radio Direction Finding (RDF) is the most widespread of radio navigation systems. Most pleasure boats, fishing vessels and larger commercial and naval vessels have RDF equipment onboard. Various countries installed radio direction-finder equipment at points ashore. These stations will take radio bearings on ships when requested, passing that info by radio to the ships. I will explain it in detail using Norddeich Radio as an example. Unfortunately the North Sea DF-net no longer exists, but it gives you a good idea how it works. There are still direction-finder stations in Norway, Pakistan, Bangladesh, Panama and Russia. The radio direction-finding control station of the North Sea direction finding network was Norddeich Radio. Bearings were taken on the freqs 410 and 500 kHz and on freqs between 1605 and 3800 kHz. -

Mobile Radio Beacons in Coastal Reserved Navigation System for Ships
the International Journal Volume 14 on Marine Navigation Number 3 http://www.transnav.eu and Safety of Sea Transportation September 2020 DOI: 10.12716/1001.14.03.11 Mobile Radio Beacons in Coastal Reserved Navigation System for Ships J.M. Kelner & C. Ziółkowski Military University of Technology, Warsaw, Poland ABSTRACT: At the turn of the 20th and 21st centuries, Global Navigation Satellite Systems (GNSSs) dominated navigation in air, sea, and land. Then, medium-range and long-range terrestrial navigation systems (TNSs) ceased to be developed. However, with the development of GNSS jamming and spoofing techniques, the TNSs are being re-developed, such as the Enhanced Loran. The Polish Ministry of Defense plans to develop and implement a medium-range backup navigation system for the Polish Navy which will operate in the Baltic coastal zone. This plan is a part of the global trend. This paper presents the concept of a reserve TNS (RNS) that is based on the signal Doppler frequency (SDF) location method. In 2016, the concept of the RNS, which is based on stationary radio beacons located on coastal lighthouses, has been presented. From the military viewpoint, the use of the mobile radio beacons, which may change their location, is more justified. Therefore, the paper presents an idea of using the mobile beacons for this purpose. In this paper, effectiveness of the mobile RNS is shown based on simulation studies. 1 INTRODUCTION positioning in the Transit was based on the Doppler effect. His successor is the GPS–NAVSTAR (Global At the beginning of the 20th century, the use of radio Positioning System – Navigation Signal Timing and waves caused the genesis of the wireless Ranging), i.e., the first global NSS (GNSS), which is communications era. -

Helicopters in the Royal Air Force
ROYAL AIR FORCE HISTORICAL SOCIETY JOURNAL 25 2 The opinions expressed in this publication are those of the contributors concerned and are not necessarily those held by the Royal Air Force Historical Society. Photographs credited to MAP have been reproduced by kind permission of Military Aircraft Photographs. Copies of these, and of many others, may be obtained via http://www.mar.co.uk Copyright 2001: Royal Air Force Historical Society First published in the UK in 2001 by the Royal Air Force Historical Society All rights reserved. No part of this book may be reproduced or transmitted in any form or by any means, electronic or mechanical including photocopying, recording or by any information storage and retrieval system, without permission from the Publisher in writing. ISSN 1361-4231 Typeset by Creative Associates 115 Magdalen Road Oxford OX4 1RS Printed by Professional Book Supplies Ltd 8 Station Yard Steventon Nr Abingdon OX13 6RX 3 CONTENTS THE PROCEEDINGS OF THE RAFHS SEMINAR ON 7 HELICOPTERS IN THE ROYAL AIR FORCE BOOK REVIEWS 112 4 ROYAL AIR FORCE HISTORICAL SOCIETY President Marshal of the Royal Air Force Sir Michael Beetham GCB CBE DFC AFC Vice-President Air Marshal Sir Frederick Sowrey KCB CBE AFC Committee Chairman Air Vice-Marshal N B Baldwin CB CBE FRAeS Vice-Chairman Group Captain J D Heron OBE Secretary Group Captain K J Dearman Membership Secretary Dr Jack Dunham PhD CPsychol AMRAeS Treasurer Desmond Goch Esq FCCA Members Air Commodore H A Probert MBE MA *J S Cox Esq BA MA *Dr M A Fopp MA FMA FIMgt *Group Captain P Gray -

Radio Navigation; Determining Distance Or Velocity by Use
CPC - G01S - 2021.08 G01S RADIO DIRECTION-FINDING; RADIO NAVIGATION; DETERMINING DISTANCE OR VELOCITY BY USE OF RADIO WAVES; LOCATING OR PRESENCE- DETECTING BY USE OF THE REFLECTION OR RERADIATION OF RADIO WAVES; ANALOGOUS ARRANGEMENTS USING OTHER WAVES Definition statement This place covers: • Methods or apparatus for determining positions, directions and distances by use of radio waves. • Methods or apparatus for determining velocities of solid objects/bodies by use of radio waves, unless the body is moving relative to some fluid and the influence of the streaming medium on the wave propagating therein is measured. • Methods or apparatus for locating solid objects/bodies, or detecting their presence by use of reflection or re-radiation of radio waves. • Methods or apparatus for navigation by use of radio waves (attention is drawn to the limited scope of the term navigation, given below in the section Glossary of Terms). • Analogous methods or apparatus using other waves than radio waves, e.g. infrared, visible or ultraviolet light, or acoustic waves. Certain restrictions and priorities apply as regards other subclasses (see sections Relationships between larger subject matter areas and References relevant to classification in this subclass below). • Radar, Lidar, Sonar systems in general and specially adapted for specific applications if not specifically designed for geophysical use. Relationships with other classification places The general subject matters direction-finding, navigation, determining distances or velocities, locating, or presence-detecting are covered by several subclasses besides G01S such as: G01B, G01C, G01P, G01V. G01S necessarily requires the use of waves (attention is drawn to the section Glossary of terms). -

A Report on Hyperbolic Navigation System
A Report on Hyperbolic Navigation System Quiambao, John Vincent Roque, Rommel Sagad, Arjel San Pablo, Aldrin Seth Santos, Johan Christian INTRODUCTION Hyperbolic navigation system A navigation system that produces hyperbolic lines of position (LOPs) through the measurement of the difference in times of reception (or phase difference) of radio signals from two or more synchronized transmitters at fixed points. Such systems require the use of a receiver which measures the time difference (or phase difference) between arriving radio signals. Assuming the velocity of signal propagation is relatively constant across a given coverage area, the difference in the times of arrival (or phase) is constant on a hyperbola having the two transmitting stations as foci. Therefore, the receiver measuring time or phase difference between arriving signals must be located somewhere along the hyperbolic line of position corresponding to that time or phase difference. If a third transmitting station is available, the receiver can measure a second time or phase difference and obtain another hyperbolic line of position. The intersection of the lines of position provides a two-dimensional navigational fix .User receivers typically convert this navigational fix to latitude and longitude for operator convenience. HISTORY The theory behind the operation of hyperbolic navigation systems was known in the late 1930’s, but it took the urgency of World War II to speed development of the system into practical use. By early 1942, the British had an operation hyperbolic system in use designed to aid in long range bomber navigation. This system, named Gee, operated on frequencies between 30 MHz and 80 MHz and employed “master” and “slave transmitters” spaced approximately 100 miles apart. -
Silver City Airways
Silver City Airways Full details of the materials stored in the Silver City Airways archive Please contact Keith Dagwell 31 Exmoor Drive Salvington Worthing West Sussex BN13 2PJ Telephone 01903 261514 AIR KRUISE. 1. ”Flight” Oct 1955, history. 2. Angela Ackworth in her Air Kruise uniform. 3. 1955 Staff day trip to Ostend on DC3. 4. Audrey Kennard and Val Lipscombe at Ferryfield. 5. Air Kruise D.H.Dragon Rapide G-AEWL at Lympne 1950. 6. Air Kruise Dragon Rapide at Lympne. 7. G-AHJI at Blackbushe and later in 1954 at Ferryfield. 8. HRH the Duke of Edinburgh and DC3 at Ferryfield 5 th April 1956. 9. HRH the Duke of Edinburgh exits G-AIME at Ferryfield. 10. HRH leaves G-AIME with Michael Day (SCA Tech Director). 11. Postcard of DC3 G-ANLF. 12. G-AMZB,G-AMYX and G-AOBN at Ferryfield 1954. 13. DC3’s at Ferryfield(colour). 14. DC3’s G-AMYX and G-AMYV. 15. DC3 G-AMYX. 15a. Silver City ‘no passport’ flight. 16. DC3 at Linz – Hungarian aid mission 1956. 16a. “ “ “ “ “ 17. B170 Mk21 and DC3 interiors in passenger configuration. 17a. DC3 interior 1955. 18. G-ANLF flying the MOA and Air Kruise flags 1956. 19. 2,3 and 4 Air Kruise DC3s at Ferryfield 1955. 20. Val Sanders in her Air Kruise uniform 1957. 21. Val Sanders on charter flight with group of missionaries. 22. Val Sanders in navy blue uniform en-route to Malta. AIR KRUISE… cont 23. Wing Commander Hugh Kennard. 24. Daily Telegraph 24.6.1995 Hugh Kennard Obituary. -
1990-2-Spring
The Goose Gazette The newsletter of the Wild Goose Association, the international loran radionavigation forum. Volume 90-2 - News of the Spring, 1990 WGA Charter President's Message - Jim Culbertson User Contact; Loran Technological Developments "The Wild GooseAssociation is a For some time now I have been on the who have previously indicated they professional organization of individuals ;oapbox preaching that WGA must seek would help will soon be set to work. I and organizations having an interest in ~utand maintainclose contactwith the am sure everyone will turn-to and help loran radionavigation and who wish to :rowing Loran-C user community us make the 1990 Journal successful. foster and preserve the art of loran. It is worldwide. The WGA has takenseveral named after the majestic bird that nitiatives to this end and I believe it is I am becoming concerned that we need to navigates thousands of miles with timely to review what has become of this redirect some effort back toward our unerring accuracy. Its membership sffort and what more should be done. technical roots in loran. With technical represents many interests including those literature focusing on GPS Navstar, the of planners, promoters, designers We initiated the "Manufacturers'Cardn relatively mature loran system tends to and users of loran equipment program whereby purchasers of new take a back seat. Because there are very throughout the world." loran equipment mailed in a special post few government loran contracts being let, 3rd for information on WGA. The most new loran technological response has been encouraging. The developments are being made in the program has resulted in many new private sector and, for competitive WGA Technical members and has provided the reasons, are closely guarded. -
The Development of Loran-C Navigation and Timing
narionsi t5urea« or standarefl FEB 2 0 1973 (Pdico the Development of Loran-C 7^^"^ Navigation and Timing Gifford Hefley Institute for Basic Standards U > i National Bureau of Standards Boulder, Colorado 80302 U.S. DEPARTMENT OF COMMERCE, Peter G. Peterson, Secretary NATIONAL BUREAU OF STANDARDS, Lawrence M. Kushner, Aciing D/rec/or, Issued October 1972 Library of Congress Catalog Card Number: 72-600267 National Bureau of Standards Monograph 129 Nat. Bur. Stand. (U.S.), Monogr. 129, 157 pages (Oct. 1972) CODEN: NBSMA6 For sale by the Superintendent of Documents, U.S. Government Printing Office, Washington, D.C. 20402 (Order by SD Catalog No. C13.44:129). Price $4.50. Stock Number 0303-01060 TABLE OF CONTENTS Page iv LIST OF FIGURES vii LIST OF TABLES viii ABSTRACT ix FOREWORD, L. E. Gatterer X FOREWORD, Robert H. Doherty xi PREFACE 1 1. INTRODUCTION 5 EARLY DEVELOPMENT OF LORAN AND GEE 2. 8 3. LOW- FREQUENCY LORAN, CYCLAN AND WHYN 25 4. CYTAC DEVELOPMENT AND PRELIMINARY TESTS 35 5. CYTAC FIELD TESTS 35 5.1. General Description of Test Program 39 5.2. Summary of Field Measurements 39 5.2.1. Baseline Extension Measurements 42 5.2.2. Random Errors 47 5.2.3. Systematic Errors 47 5.2.4. Flight Tests (Random and Systematic Errors) 59 5.3. Rate of Change of Systematic Errors 63 5.4. Localized Phase Errors 64 5.5. Instrumentation Errors 66 5.6. Temporal Variations 68 5.7. Skywaves 6. LORAN-C — AN OPERATIONAL SYSTEM 72 7. LORAN-C TIMING 9 3 7.1. Background 9 3 7.2.