Predicting Search Task Difficulty
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Fancytooltips Package∗†
The fancytooltips package∗y Robert Maˇr´ık [email protected] May 4, 2009 1 Introduction The package fancytooltips is a package for LATEX. The pdf can be created by pdflatex or by latex + dvips + AdobeDistiller1 + Adobe Acrobat2. It allows to create tooltips in a similar way like cooltooltips package, but the tooltip is a page from another PDF file. In this way you can use mathematics, pictures and animations in your tooltips. The resulting PDF file can be used also with free Abobe Reader. The tooltips are activated by clicking the active area on the screen and deac- tivated after closing page or by moving mouse outside the link. You can try the links here (Einstein's formula) and also here (animation { numbers from 1 to 6). You have to use the free Adobe Reader or nonfree Adobe Acrobat to see the effect (xpdf, evince and others fail to work with JavaScripts). For more examples how the presentation may look like see the example.pdf and example-min.pdf files in the examples subdirectory. The buttons are created using eforms.sty which is a part of AcroTeX bundle. 2 Usage 2.1 The file with tooltips The file with tooltips is an ordinary pdf file, one tooltip per page, tooltips should be in the top right corner at the page, in a colored box and the rest of the page should be transparent. If you consider to use movetips option (see below), then every page should have the dimensions equal to the dimen- sions of the colored box with tooltip3. -

Visualizing User Interface Events Event Stream Summarization Through Signs
Visualizing User Interface Events Event Stream Summarization through Signs Vagner Figueredo de Santana and Maria Cecília Calani Baranauskas Institute of Computing, University of Campinas (UNICAMP), Albert Einstein Av., 1251, Campinas, Brazil Keywords: Semiotics, User Interface Events, Visualization of Usage Data, Log Visualization, Event Icons, Icon Library, Image Library, User Interface Evaluation, Usability Evaluation, Accessibility Evaluation, Web Usage Mining. Abstract: Effective visual representation is related to how people interpret signs created to carry specific information. In the last years many user interface evaluation tools are considering detailed usage data to represent users’ actions. The volume of data gathered is leading developers to represent usage in a summarized way through graphical representations. If visual components used to represent complex data are not effective, then graphics used to summarize data may turn the interpretation of complex terms even harder. This work presents a study about graphical representations for user interface (UI) events and contributes with the validation of usage graph visualization and an open set of signs to support the summarization of client-side logs. The study involved 28 Information Technology specialists, potential users of UI evaluation tools. From the results one expects that evaluation tool developers, evaluators, and Web usage miners can reuse the validated usage graph representation and proposed set of signs to represent usage data in a summarized way. 1 INTRODUCTION these events is called, respectively, client-side logs and server-side logs (Santana and Baranauskas, The evaluation of user interface (UI) is a key task 2010a). when developing information systems and is part of In the last decade, website evaluation tools using a number of Software Engineering development server-side data (i.e., based on Web server logs) processes. -

Clickjacking: Attacks and Defenses
Clickjacking: Attacks and Defenses Lin-Shung Huang Alex Moshchuk Helen J. Wang Carnegie Mellon University Microsoft Research Microsoft Research [email protected] [email protected] [email protected] Stuart Schechter Collin Jackson Microsoft Research Carnegie Mellon University [email protected] [email protected] Abstract such as a “claim your free iPad” button. Hence, when Clickjacking attacks are an emerging threat on the web. the user “claims” a free iPad, a story appears in the user’s In this paper, we design new clickjacking attack variants Facebook friends’ news feed stating that she “likes” the using existing techniques and demonstrate that existing attacker web site. For ease of exposition, our description clickjacking defenses are insufficient. Our attacks show will be in the context of web browsers. Nevertheless, the that clickjacking can cause severe damages, including concepts and techniques described are generally applica- compromising a user’s private webcam, email or other ble to all client operating systems where display is shared private data, and web surfing anonymity. by mutually distrusting principals. We observe the root cause of clickjacking is that an Several clickjacking defenses have been proposed and attacker application presents a sensitive UI element of a deployed for web browsers, but all have shortcomings. target application out of context to a user (such as hiding Today’s most widely deployed defenses rely on frame- the sensitive UI by making it transparent), and hence the busting [21, 37], which disallows a sensitive page from user is tricked to act out of context. To address this root being framed (i.e., embedded within another web page). -

Pen Computer Technology
Pen Computer Technology Educates the reader about the technologies involved in a pen computer Fujitsu PC Corporation www.fujitsupc.com For more information: [email protected] © 2002 Fujitsu PC Corporation. All rights reserved. This paper is intended to educate the reader about the technologies involved in a pen computer. After reading this paper, the reader should be better equipped to make intelligent purchasing decisions about pen computers. Types of Pen Computers In this white paper, "pen computer" refers to a portable computer that supports a pen as a user interface device, and whose LCD screen measures at least six inches diagonally. This product definition encompasses five generally recognized categories of standard products, listed in Table 1 below. PRODUCT TARGET PC USER STORAGE OPERATING RUNS LOCAL EXAMPLE CATEGORY MARKET INTERFACE SYSTEM PROGRAMS Webpad Consumer & No Standard Flash Windows CE, Only via Honeywell Enterprise browser memory Linux, QNX browser WebPAD II plug-ins CE Tablet Enterprise No Specialized Flash Windows CE Yes Fujitsu applications memory PenCentra Pen Tablet Enterprise Yes Windows & Hard drive Windows 9x, Yes Fujitsu specialized NT-4, 2000, Stylistic applications XP Pen-Enabled Consumer Yes Windows Hard drive Windows 9x, Yes Fujitsu & Enterprise 2000, XP LifeBook B Series Tablet PC Consumer Yes Windows Hard drive Windows XP Yes Many under & Enterprise Tablet PC development Edition Table 1: Categories of Pen Computers with LCD Displays of Six Inches or Larger Since the different types of pen computers are often confused, the following paragraphs are intended to help explain the key distinguishing characteristics of each product category. Pen Computers Contrasted Webpad: A Webpad's primary characteristic is that its only user interface is a Web browser. -

(12) Patent Application Publication (10) Pub. No.: US 2007/0211071 A1 Slotznick Et Al
US 20070211071A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2007/0211071 A1 Slotznick et al. (43) Pub. Date: Sep. 13, 2007 (54) METHOD AND APPARATUS FOR (52) U.S. Cl. .............................................................. 34.5/594 INTERACTING WITH A VISUALLY DISPLAYED DOCUMENT ON A SCREEN (57) ABSTRACT READER User interaction of a visually displayed document is pro vided via a graphical user interface (GUI). The document (76) Inventors: Benjamin Slotznick, Mt. Gretna, PA includes, and is parsed into, a plurality of text-based gram (US); Stephen C. Sheetz, Lititz, PA matical units. An input device modality is selected from a (US) plurality of input device modalities which determines the Correspondence Address: type of input device in which a user interacts with to make AKN GUMPSTRAUSS HAUER & FELD a selection. One or more grammatical units of the document L.L.P. are then selected using the selected type of input device. ONE COMMERCE SQUARE Each grammatical unit that is selected is read aloud to the 2005 MARKET STREET, SUITE 2200 user by loading the grammatical unit into a text-to-speech PHILADELPHIA, PA 19103 (US) engine. The text of the grammatical unit is thereby auto matically spoken. Furthermore, a Switching modality is (21) Appl. No.: 11/642,247 selected from a plurality of switching modalities. The (22) Filed: Dec. 20, 2006 Switching modality determines the manner in which one or more Switches are used to make a selection. Using the Related U.S. Application Data selected Switching modality, a user steps through at least Some of the grammatical units in an ordered manner by (60) Provisional application No. -

V9 User Manual (PDF)
This section of the manual gives a basic introduction to AB Tutor, and describes some of the concepts, such as network layout and passwords. AB Tutor manual Introduction What is AB Tutor? Basic ABT setup Advanced setup options Introduction to passwords Startup passwords Connection password Startup switches Introduction What is AB Tutor? AB Tutor is a networked classroom, instruction, monitoring and teaching tool that lets you train students in a networked classroom or lab, simply, effectively, at a very affordable price. Teachers, trainers and administrators can use the software to easily control, manage, monitor and support their students. This is a list of the key features of AB Tutor Cross platform Windows central server Windows and Mac tutor applications Windows and Mac client applications Computer Monitoring Real-time remote screen watch Simultaneous watch by multiple tutors Network efficient sizeable thumbnail views, with changeable refresh times Create different thumbnail arrangements for each group Monitor running applications and files Identify what site/file the student is working on Monitor and log student activity (applications, printing, websites and keystrokes) Take time and name-stamped snapshots of student activity Record and play back student screen activity Live search for users/computers Monitor multiple class groups simultaneously Keyword Notification Inform tutor when specific keywords are typed Automatically take snapshots of violations Trigger remote screen recording upon violation View and export all violations -
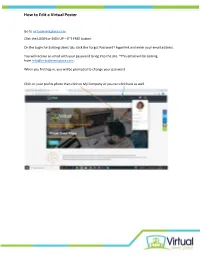
How to Edit a Virtual Poster
How to Edit a Virtual Poster Go to virtualeventplace.com. Click the LOGIN or SIGN UP – IT’S FREE button. On the Login for Existing Users tab, click the Forgot Password? hyperlink and enter your email address. You will receive an email with your password to log into the site. *This email will be coming from [email protected]. When you first log-in, you will be prompted to change your password. Click on your profile photo then click on My Company or you can click here as well. How to Edit a Virtual Poster Click on the Admin Button Mouseover the Tradeshow tab and click on Booths (your poster is considered a “booth”) Scroll down and you will have the option to Display/Edit your poster booth by clicking the arrow. How to Edit a Virtual Poster You will then be able to view your poster booth in edit mode. *Please note that the overall booth design will look different than the screenshots below but the editing capabilities remain the same. How to Edit a Virtual Poster You can click on any of the Edit icons to begin editing each section of your poster booth. Clicking on the section’s Edit icon, you can add in any information you would like. You can also edit the header of each section when in the editing pop up for that section. How to Edit a Virtual Poster Have a video to share to one of the panels? Select the embedded video option when editing the section. Note that videos must be hosted on YouTube and either unlisted or public (not private). -

10 Things You Can Do in 10 Minutes with the Toolkit
10 Things You Can Do in 10 Minutes With The Toolkit Darryl Hopkins Nilufer Uslu Avectra Agenda • Introduction – Purpose – What is the Toolkit? • 10 Exercises in 10 Minutes • Conclusion • Questions Purpose • Quick and easy improvements to your site that you may not know you could do with the Toolkit • Old and new tricks that are not necessarily in the training curriculum • 10 things to expand our vision and explore possibilities with the Toolkit What is the Toolkit? • History – Before AMS, Avectra built CMS – Software to build software • Concept – Everything is a data row in a database table – An engine to render this data into a web page • What does it do? – Helps expand database and software to address custom needs – Keeps customizations in structure, allows getting new features/bug fixes via upgrades and service packs • Who uses it? – Clients – Partners – Avectra Developers (R&D, Implementers) 1 of 10 – Child Forms • Adding a Copy Record Feature to a child form • BONUS: Two varieties of child form mouseover previews Requirement • Ability to copy an existing organization relationship of an individual Solution • Modify individual organization child form • Add a “copy” link in a child form to allow user to copy an existing record • Link will open the “Add” page and default certain values based on the record being copied Modify Child Form • Save a tiny “copy” GIF file in /iweb/images/img_copy.gif • Modify the Child Form Select SQL: • See wiki for more. Result • Before: • After: Result • When user clicks “copy” link, add form pops up and -
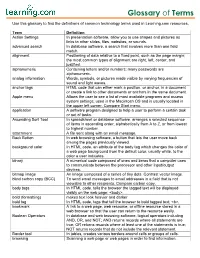
Glossary of Terms
Glossary of Terms Use this glossary to find the definitions of common technology terms used in Learning.com resources. Term Definition Action Settings In presentation software, allow you to use shapes and pictures as links to other slides, files, websites, or sounds. advanced search In database software, a search that involves more than one field match. alignment Positioning of data relative to a fixed point, such as the page margin; the most common types of alignment are right, left, center, and justified. alphanumeric Containing letters and/or numbers; many passwords are alphanumeric. analog information Words, symbols, or pictures made visible by varying frequencies of sound and light waves. anchor tags HTML code that can either mark a position, or anchor, in a document or create a link to other documents or anchors in the same document. Apple menu Allows the user to see a list of most available programs and access system settings; used in the Macintosh OS and is usually located in the upper left corner. Compare Start menu. application A software program designed to help a user to perform a certain task or set of tasks. Ascending Sort Tool In spreadsheet or database software, arranges a selected sequence of items in ascending order, alphabetically from A to Z, or from lowest to highest number. attachment A file sent along with an email message. Back Button In web browsing software, a button that lets the user move back among the pages previously viewed. background color In HTML code, an attribute of the body tag which changes the color of a web page background from the default color, usually white, to the color a user indicates. -

Creating and Configuring a Custom Visualization Component
ORACLE CORPORATION Creating and Configuring a Custom Visualization Component Oracle Big Data Discovery Version 1.1.x Copyright © 2015, Oracle and/or its affiliates. All rights reserved Oracle Big Data Discovery v1.1.x Page 1 of 38 Rev 1 Table of Contents Overview .........................................................................................................................................3 Process Overview .....................................................................................................................4 Creating a Custom Visualization Component in Studio’s Control Panel ......................4 Instantiating and Configuring a CVC in a Studio Project: .............................................13 Overview of the API features of the Donut_Pie Chart Example ..................................16 Publishing a Custom Visualization Component ..................................................................17 Unpublishing a Custom Visualization Component .............................................................17 Deleting a Custom Visualization Component .....................................................................17 Visualization Configuration ....................................................................................................18 EQL........................................................................................................................................18 Token Substitution ...............................................................................................................19 -

Web Programming
Web Programming Lecture 4 – JavaScript and HTML Documents The JavaScript Execution Environment • Browsers display XHTML documents in a window, which is an object in its own right. JavaScript has a Window object that represents the window displaying the document. • All JavaScripts can see the various properties of the Window object. • Every Window has a Document object that represents the display XHTML documents, which has properties of its own. 1 Window Object History Location Document Link Anchor Text Form Select Text- Options Radio Button box Check- Password Submit Reset box The Document Object Model • DOM ( Document Object Model) is an API (Application Programming Interface) that defines an interface between HTML documents and application program. • It is an abstract model that applies to a variety of programming language. • Essentially, the various structures in an HTML document that are marked up with tags are considered objects, complete with properties and methods. • The attributes of an HTML tag corresponds to a property for the corresponding object. 2 A table in XHTML <!DOCTYPE html> <!-- table2.html A simple table to demonstrate DOM trees --> <html lang = "en"> <head> <title> A simple document </title> <meta charset = "utf-8" /> </head> <body> <table> <tr> <th> </th> <td> Apple </td> <td> Orange </td> </tr> <tr> <th> Breakfast </th> <td> 1 </td> <td> 0 </td> </tr> </table> </body> </html> 3 DOM Structure of the Document Document <head> <body> <title> <table> "A simple document" <tr> <tr> <th> <td> <td> <th> <td> <td> Apple Orange Breakfast 0 1 DOM – An Example • The following tag: <input type = "text" name = "address"> corresponds to an object, which has two properties type (which is text ) and name (which is address ). -

Mouse, Touch, Or Fich: Comparing Traditional Input Modalities to a Novel Pre-Touch Technique
Mouse, Touch, or Fich: Comparing Traditional Input Modalities to a Novel Pre-Touch Technique Jonas Müller, Lea Rieger, Ilhan Aslan, Christoph Anneser, Malte Sandstede, Felix Schwarzmeier, Björn Petrak and Elisabeth André [email protected] Human-Centered Multimedia Lab, Augsburg University Augsburg, Germany ABSTRACT However, an increasing number of today’s personal computers Finger touch and mouse-based interaction are today’s predominant are equipped with touch screens. These touch interfaces usually lack modalities to interact with screen-based user interfaces. Related a similar technique to mouseover, which would allow especially work suggests that new techniques interweaving pre-touch sensing novice users of a graphical user interface to safely explore the and touch are useful future alternatives. In this paper, we introduce application without having to be cautious of performing errors Fich, a novel pre-touch technique that augments conventional touch (e.g., pressing the wrong links or buttons) and recovering from interfaces with tooltips and further “fingerover” effects, opening these. up the space in front of the screen for user interaction. To study Constraints of graphical touch interfaces are well known. Fellow Fich in-depth, we developed a Fich-enabled weather application and researchers have, for example, proposed combining touch with compared user experience and interface discovery (“serendipity”) pre-touch sensing (e.g., [2, 9, 12]) in order to address them. While of Fich against the traditional input modalities Mouse and finger techniques combining touch and mid-air interaction have already Touch in a user study with 42 subjects. We report on the results, been proposed in previous research, there is a gap in studying the implying Fich’s user experience to be rated significantly higher effects of such techniques in typical everyday applications with in terms of hedonic quality and significantly lower in terms of multiple pre-touch enabled interactive elements, and in comparing pragmatic quality, as compared to traditional input modalities.