Symantec™ Storage Foundation and High Availability Solutions 6.2.1 Release Notes - Solaris
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Netbackup ™ Enterprise Server and Server 8.0 - 8.X.X OS Software Compatibility List Created on September 08, 2021
Veritas NetBackup ™ Enterprise Server and Server 8.0 - 8.x.x OS Software Compatibility List Created on September 08, 2021 Click here for the HTML version of this document. <https://download.veritas.com/resources/content/live/OSVC/100046000/100046611/en_US/nbu_80_scl.html> Copyright © 2021 Veritas Technologies LLC. All rights reserved. Veritas, the Veritas Logo, and NetBackup are trademarks or registered trademarks of Veritas Technologies LLC in the U.S. and other countries. Other names may be trademarks of their respective owners. Veritas NetBackup ™ Enterprise Server and Server 8.0 - 8.x.x OS Software Compatibility List 2021-09-08 Introduction This Software Compatibility List (SCL) document contains information for Veritas NetBackup 8.0 through 8.x.x. It covers NetBackup Server (which includes Enterprise Server and Server), Client, Bare Metal Restore (BMR), Clustered Master Server Compatibility and Storage Stacks, Deduplication, File System Compatibility, NetBackup OpsCenter, NetBackup Access Control (NBAC), SAN Media Server/SAN Client/FT Media Server, Virtual System Compatibility and NetBackup Self Service Support. It is divided into bookmarks on the left that can be expanded. IPV6 and Dual Stack environments are supported from NetBackup 8.1.1 onwards with few limitations, refer technote for additional information <http://www.veritas.com/docs/100041420> For information about certain NetBackup features, functionality, 3rd-party product integration, Veritas product integration, applications, databases, and OS platforms that Veritas intends to replace with newer and improved functionality, or in some cases, discontinue without replacement, please see the widget titled "NetBackup Future Platform and Feature Plans" at <https://sort.veritas.com/netbackup> Reference Article <https://www.veritas.com/docs/100040093> for links to all other NetBackup compatibility lists. -
Chapter 11: Implementing File Systems In-Memory File-System Structures
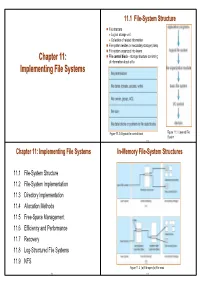
11.1 File-System Structure File structure z Logical storage unit z Collection of related information File system resides on secondary storage (disks) File system organized into layers Chapter 11: File control block – storage structure consisting Chapter 11: of information about a file Implementing File Systems Figure 11.2 A typical file-control block Figure 11.1 Layered File System 11.3 Chapter 11: Implementing File Systems In-Memory File-System Structures 11.1 File-System Structure 11.2 File-System Implementation 11.3 Directory Implementation 11.4 Allocation Methods 11.5 Free-Space Management 11.6 Efficiency and Performance 11.7 Recovery 11.8 Log-Structured File Systems 11.9 NFS Figure 11.3 (a) File open (b) File read 11.2 11.4 Virtual File Systems 11.4 Allocation Methods Virtual File Systems (VFS) provide an object-oriented way of implementing file systems. VFS allows the same system call interface (API) to be used for different types of An allocation method refers to how disk blocks are file systems. allocated for files: The API is to the VFS interface, rather than any specific type of file system. 11.4.1 Contiguous allocation 11.4.2 Linked allocation 11.4.3 Indexed allocation Figure 11.4 Schematic View of Virtual File System 11.5 11.7 11.3 Directory Implementation 11.4.1 Contiguous Allocation Linear list of file names with pointer to the data blocks. Each file occupies a set of contiguous blocks on the disk z advantage: simple to program Advantages z disadvantage: time-consuming to execute z Simple – only require starting location (block #) and Hash Table – linear list with hash data structure. -

Linux Last Updated: 2018-09-11 Legal Notice Copyright © 2018 Veritas Technologies LLC
Storage Foundation 7.4 Configuration and Upgrade Guide - Linux Last updated: 2018-09-11 Legal Notice Copyright © 2018 Veritas Technologies LLC. All rights reserved. Veritas and the Veritas Logo are trademarks or registered trademarks of Veritas Technologies LLC or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. This product may contain third-party software for which Veritas is required to provide attribution to the third-party (“Third-Party Programs”). Some of the Third-Party Programs are available under open source or free software licenses. The License Agreement accompanying the Software does not alter any rights or obligations you may have under those open source or free software licenses. Refer to the third-party legal notices document accompanying this Veritas product or available at: https://www.veritas.com/about/legal/license-agreements The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Veritas Technologies LLC and its licensors, if any. THE DOCUMENTATION IS PROVIDED "AS IS" AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. VERITAS TECHNOLOGIES LLC SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING, PERFORMANCE, OR USE OF THIS DOCUMENTATION. THE INFORMATION CONTAINED IN THIS DOCUMENTATION IS SUBJECT TO CHANGE WITHOUT NOTICE. -

Storage Foundation Cluster File System Release Notes
Veritas Storage Foundation™ Cluster File System Release Notes HP-UX 5.0 Maintenance Pack 1 Veritas Storage Foundation Cluster File System Release Notes Copyright © 2007 Symantec Corporation. All rights reserved. Storage Foundation Cluster File System 5.0 Maintenance Pack 1 Symantec, the Symantec logo, Veritas, and Veritas Storage Foundation are trademarks or registered trademarks of Symantec Corporation or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Symantec Corporation and its licensors, if any. THIS DOCUMENTATION IS PROVIDED “AS IS” AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID, SYMANTEC CORPORATION SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING PERFORMANCE, OR USE OF THIS DOCUMENTATION. THE INFORMATION CONTAINED IN THIS DOCUMENTATION IS SUBJECT TO CHANGE WITHOUT NOTICE. The Licensed Software and Documentation are deemed to be “commercial computer software” and “commercial computer software documentation” as defined in FAR Sections 12.212 and DFARS Section 227.7202. Symantec Corporation 20330 Stevens Creek Blvd. Cupertino, CA 95014 www.symantec.com Printed in the United States of America. Third-party legal notices Third-party software may be recommended, distributed, embedded, or bundled with this Symantec product. -

Cloud, Virtualization, Data Storage Networking Fundementals
Complements of StorageIO This chapter download from the book “Cloud and Virtual Data Storage Networking” (CRC Press) by noted IT industry veteran and Server StorageIO founder Greg Schulz is complements of The Server and StorageIO Group (StorageIO). Learn more about the techniques, trends, technologies and products covered in this book by visiting storageio.com and storageioblog.com and register for events and other promotions. Follow us on twitter @storageio or on Google+ among other social media venues. Visit storageio.com/events to see upcoming seminars and activities Cloud and Virtual Data Storage Networking has been added to the Intel Recommended Reading List (IRRL) for Developers. Click on the image below to learn more about the IRRL. Learn more about Cloud and Virtual Data Storage Networking (CRC Press) by visiting storageio.com/books To become a chapter download sponsor or to discuss your other project opportunities contact us at [email protected] . Cloud and Virtual Data Storage Networking (CRC Press) by Greg Schulz ISBN: 978-1439851739 www.storageio.com Chapter 2 Cloud, Virtualization, and Data Storage Networking Fundamentals The more space you have, the more it seems to get filled up. – Greg Schulz In This Chapter • Storage (hardware, software, and management tools) • Block, file, direct attached, networked, and cloud storage • Input/output, networking, and related convergence topics • Public and private cloud products and services • Virtualization (applications, desktop, server, storage, and networking) This chapter provides a primer and overview of major IT resource components as well as how information is supported by them. Key themes and buzzwords discussed include block, file, object storage, and data sharing, along with public and private cloud products and services. -

Symantec™ Cluster Server 6.1 Bundled Agents Reference Guide - Solaris
Symantec™ Cluster Server 6.1 Bundled Agents Reference Guide - Solaris July 2015 Symantec™ Cluster Server Bundled Agents Reference Guide The software described in this book is furnished under a license agreement and may be used only in accordance with the terms of the agreement. Product version: 6.1 Document version: 6.1 Rev 3 Legal Notice Copyright © 2015 Symantec Corporation. All rights reserved. Symantec, the Symantec Logo, the Checkmark Logo, Veritas, Veritas Storage Foundation, CommandCentral, NetBackup, Enterprise Vault, and LiveUpdate are trademarks or registered trademarks of Symantec Corporation or its affiliates in the U.S. and other countries. Other names may be trademarks of their respective owners. The product described in this document is distributed under licenses restricting its use, copying, distribution, and decompilation/reverse engineering. No part of this document may be reproduced in any form by any means without prior written authorization of Symantec Corporation and its licensors, if any. THE DOCUMENTATION IS PROVIDED "AS IS" AND ALL EXPRESS OR IMPLIED CONDITIONS, REPRESENTATIONS AND WARRANTIES, INCLUDING ANY IMPLIED WARRANTY OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE OR NON-INFRINGEMENT, ARE DISCLAIMED, EXCEPT TO THE EXTENT THAT SUCH DISCLAIMERS ARE HELD TO BE LEGALLY INVALID. SYMANTEC CORPORATION SHALL NOT BE LIABLE FOR INCIDENTAL OR CONSEQUENTIAL DAMAGES IN CONNECTION WITH THE FURNISHING, PERFORMANCE, OR USE OF THIS DOCUMENTATION. THE INFORMATION CONTAINED IN THIS DOCUMENTATION IS SUBJECT TO CHANGE WITHOUT NOTICE. The Licensed Software and Documentation are deemed to be commercial computer software as defined in FAR 12.212 and subject to restricted rights as defined in FAR Section 52.227-19 "Commercial Computer Software - Restricted Rights" and DFARS 227.7202, "Rights in Commercial Computer Software or Commercial Computer Software Documentation", as applicable, and any successor regulations, whether delivered by Symantec as on premises or hosted services. -

Lunworks for Solaris Version 1.0
Document: 313429201 LUNWorks for Solaris Version 1.0 Installation Manual LUNWorks for Solaris Version 1.0 Installation Manual Information contained in this publication is subject to change. In the event of changes, the publication will be revised. Comments concerning its contents should be directed to: Information Development Storage Technology Corporation One StorageTek Drive Louisville, CO 80028-2201 USA Information Control Statement: The information in this document is confidential and proprietary to Storage Technology Corporation and may be used only under terms of the product license or nondisclosure agreement. The information in this document, including any associated software program, may not be disclosed, disseminated, or distributed in any manner without written consent of Storage Technology Corporation. Limitations on Warranties and Liability: This document neither extends nor creates warranties of any nature, expressed or implied. Storage Technology Corporation cannot accept any responsibility for your use of the information in this document or for your use of any associated software program. You are responsible for backing up your data. You should be careful to ensure that your use of the information complies with all applicable laws, rules, and regulations of the jurisdictions in which it is used. No part or portion of this document may be reproduced in any manner or in any form without the written permission of Storage Technology Corporation. © 2000, Storage Technology Corporation, Louisville, CO, USA. All rights reserved. -

The Evolution of File Systems
The Evolution of File Systems Thomas Rivera, Hitachi Data Systems Craig Harmer, April 2011 SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individuals may use this material in presentations and literature under the following conditions: Any slide or slides used must be reproduced without modification The SNIA must be acknowledged as source of any material used in the body of any document containing material from these presentations. This presentation is a project of the SNIA Education Committee. Neither the Author nor the Presenter is an attorney and nothing in this presentation is intended to be nor should be construed as legal advice or opinion. If you need legal advice or legal opinion please contact an attorney. The information presented herein represents the Author's personal opinion and current understanding of the issues involved. The Author, the Presenter, and the SNIA do not assume any responsibility or liability for damages arising out of any reliance on or use of this information. NO WARRANTIES, EXPRESS OR IMPLIED. USE AT YOUR OWN RISK. The Evolution of File Systems 2 © 2012 Storage Networking Industry Association. All Rights Reserved. 2 Abstract The File Systems Evolution Over time additional file systems appeared focusing on specialized requirements such as: data sharing, remote file access, distributed file access, parallel files access, HPC, archiving, security, etc. Due to the dramatic growth of unstructured data, files as the basic units for data containers are morphing into file objects, providing more semantics and feature- rich capabilities for content processing This presentation will: Categorize and explain the basic principles of currently available file system architectures (e.g. -

The File Systems Evolution
The File Systems Evolution Christian Bandulet Principal Engineer, Sun Microsystems SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individuals may use this material in presentations and literature under the following conditions: Any slide or slides used must be reproduced without modification The SNIA must be acknowledged as source of any material used in the body of any document containing material from these presentations. This presentation is a project of the SNIA Education Committee. Neither the Author nor the Presenter is an attorney and nothing in this presentation is intended to be nor should be construed as legal advice or opinion. If you need legal advice or legal opinion please contact an attorney. The information presented herein represents the Author's personal opinion and current understanding of the issues involved. The Author, the Presenter, and the SNIA do not assume any responsibility or liability for damages arising out of any reliance on or use of this information. NO WARRANTIES, EXPRESS OR IMPLIED. USE AT YOUR OWN RISK. The File Systems Evolution © 2009 Storage Networking Industry Association. All Rights Reserved. 2 Abstract The File Systems Evolution File Systems impose structure on the address space of one or more physical or virtual devices. Starting with local file systems over time additional file systems appeared focusing on specialized requirements such as data sharing, remote file access, distributed file access, parallel files access, HPC, archiving, security etc.. Due to the dramatic growth of unstructured data files as the basic units for data containers are morphing into file objects providing more semantics and feature-rich capabilities for content processing. -

Kernel Architecture File System
Kernel Architecture File System Kernel File System: Author: SREENIVAS REDDY BATHULA Introduction: Network File System (NFS) protocols are initially developed by SUN Micro Systems and IBM. NFS are end user friendly because of remote system file sharing and friendly authorization. Many File Systems in Linux is possible because of open source code, so everyone have equal chance to develop, make it efficient and compatible for their work. At present there is more then 20 different file systems. The developing file systems can handle huge number of large files competing with time and varies operating system features. Some of the most frequently used file systems, which are present in the market are discussed here briefly. Those file systems are : EXT2, EXT3, EXT4, ReiserFS, GFS, GPFS, JFS, NSS, NTFS, FAT32, NWFS, OCFS2, PMS, VFS, VxFS and XFS. EXT 2/3/4 : EXT2 + Journals = EXT3 EXT3 + POSIX extended file access + htrees = EXT4 EXT4 + EXT3 + extents = ReiserFS Journalling : Journalling is a type of filesystem that handle a log of recent meta-data. Journaling reducess time spent on recovering a filesystem. It is applicable even when we have group of cluster nodes. This meta-data Journalling widely used in Linux. Specially in ReiserFS, XFS, JFS, ext3 and GFS. EXT2 most popular file system. EXT2 stands for 'second extended file system'. It replaced Minix file system. Positive point is data lose protection negative is Ext2 doesn't have journalling so it breaks easily. EXT3 is basically ext2 plus a journal. Fast & robust. You can switch between ext2 and ext3. EXT3 take care about metadata. So you never lose a file. -

Supported File and File System Sizes for HFS and JFS
Supported File and File System Sizes for HFS and JFS Executive Summary ................................................................................................................................. 2 Hierarchical File System (HFS) Supported Sizes ........................................................................................... 2 JFS (VxFS) Supported Sizes ....................................................................................................................... 3 Large File System (> 2 TB) Compatibility Issue .......................................................................................... 5 Large Files with Memory Mapping ......................................................................................................... 5 Large File System (> 4 TB) File System Block Size Issues ............................................................................ 5 Related JFS Patches ................................................................................................................................. 6 Related Information ................................................................................................................................. 6 Executive Summary Beginning with HP-UX 10.01, the supported sizes for files and file systems on HP-UX have gradually increased. This white paper summarizes the supported sizes for HP-UX 10.01 through HP-UX 11i v3 (B.11.31). Hierarchical File System (HFS) Supported Sizes Table 1 lists the maximum file and file system sizes that HFS supports. Note: -

Sun Fire E25K Server Datasheet
DATASHEET Sun Fire™ E25K Server < High-volume, mission-critical computing with leading investment protection and headroom to grow. The flagship Sun Fire™ E25K server is a a well-balanced compute platform. Sun’s 72-processor (up to 144 threads) datacenter proven multithreaded Solaris OS also offers system based on the new UltraSPARC® IV+ additional high-end features such as Memory processor with Chip Multithreading (CMT) Placement Optimization, which, when coupled technology, and is engineered with the most with superior hardware technologies such sophisticated availability, scalability, and as the UltraSPARC IV+ processor and the Sun Key Feature Highlights manageability features to meet the highest Fireplane interconnect, deliver predictable • Delivers up to 5 times the levels of mission-critical computing. performance for demanding applications. The performance of UltraSPARC III Sun Fire E25K server provides uptime through The Sun Fire E25K server delivers the highest servers and nearly double the built-in hardware redundancy and intelligent levels of reliability and availability through full performance of UltraSPARC IV system monitoring, diagnosis, and recovery hardware redundancy, Dynamic Reconfigura- servers in the same footprint. provided with the Predictive Self-Healing. tion, and Predictive Self-Healing. With up to • Scales up to 72 processors with Organizations can also conveniently and 18 fault-isolated domains and thousands of 144 threads and up to 576GB quickly deploy mission-critical applications memory for heavily threaded Solaris™ Containers, the Sun Fire E25K server using the factory-integrated Solaris OS and commercial applications. provides unprecedented virtualization capabil- Java™ Enterprise System software stack. • Unique Solaris OS application ities for enterprise consolidation. The Solaris The Sun Fire E25K server offers “pay as your compatibility guarantee enables OS and Sun Fire E25K server combination grow” resources with Capacity on Demand seamless migration to newer processor offers a balanced system architecture with technologies.