Distributed Data Streaming Algorithms for Network Anomaly Detection Wenji Chen Iowa State University
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Spamalytics: an Empirical Analysis of Spam Marketing Conversion
Spamalytics: An Empirical Analysis of Spam Marketing Conversion Chris Kanich∗ Christian Kreibich† Kirill Levchenko∗ Brandon Enright∗ Geoffrey M. Voelker∗ Vern Paxson† Stefan Savage∗ † ∗ International Computer Science Institute Dept. of Computer Science and Engineering Berkeley, USA University of California, San Diego, USA [email protected],[email protected] {ckanich,klevchen,voelker,savage}@cs.ucsd.edu [email protected] ABSTRACT Unraveling such questions is essential for understanding the eco- The “conversion rate” of spam — the probability that an unso- nomic support for spam and hence where any structural weaknesses licited e-mail will ultimately elicit a “sale” — underlies the entire may lie. Unfortunately, spammers do not file quarterly financial spam value proposition. However, our understanding of this critical reports, and the underground nature of their activities makes third- behavior is quite limited, and the literature lacks any quantitative party data gathering a challenge at best. Absent an empirical foun- study concerning its true value. In this paper we present a method- dation, defenders are often left to speculate as to how successful ology for measuring the conversion rate of spam. Using a parasitic spam campaigns are and to what degree they are profitable. For ex- infiltration of an existing botnet’s infrastructure, we analyze two ample, IBM’s Joshua Corman was widely quoted as claiming that spam campaigns: one designed to propagate a malware Trojan, the spam sent by the Storm worm alone was generating “millions and other marketing on-line pharmaceuticals. For nearly a half billion millions of dollars every day” [2]. While this claim could in fact be spam e-mails we identify the number that are successfully deliv- true, we are unaware of any public data or methodology capable of ered, the number that pass through popular anti-spam filters, the confirming or refuting it. -

Address Munging: the Practice of Disguising, Or Munging, an E-Mail Address to Prevent It Being Automatically Collected and Used
Address Munging: the practice of disguising, or munging, an e-mail address to prevent it being automatically collected and used as a target for people and organizations that send unsolicited bulk e-mail address. Adware: or advertising-supported software is any software package which automatically plays, displays, or downloads advertising material to a computer after the software is installed on it or while the application is being used. Some types of adware are also spyware and can be classified as privacy-invasive software. Adware is software designed to force pre-chosen ads to display on your system. Some adware is designed to be malicious and will pop up ads with such speed and frequency that they seem to be taking over everything, slowing down your system and tying up all of your system resources. When adware is coupled with spyware, it can be a frustrating ride, to say the least. Backdoor: in a computer system (or cryptosystem or algorithm) is a method of bypassing normal authentication, securing remote access to a computer, obtaining access to plaintext, and so on, while attempting to remain undetected. The backdoor may take the form of an installed program (e.g., Back Orifice), or could be a modification to an existing program or hardware device. A back door is a point of entry that circumvents normal security and can be used by a cracker to access a network or computer system. Usually back doors are created by system developers as shortcuts to speed access through security during the development stage and then are overlooked and never properly removed during final implementation. -

Antivirus Software Before It Can Detect Them
Computer virus A computer virus is a computer program that can copy itself and infect a computer without the permission or knowledge of the owner. The term "virus" is also commonly but erroneously used to refer to other types of malware, adware, and spyware programs that do not have the reproductive ability. A true virus can only spread from one computer to another (in some form of executable code) when its host is taken to the target computer; for instance because a user sent it over a network or the Internet, or carried it on a removable medium such as a floppy disk, CD, DVD, or USB drive. Viruses can increase their chances of spreading to other computers by infecting files on a network file system or a file system that is accessed by another computer.[1][2] The term "computer virus" is sometimes used as a catch-all phrase to include all types of malware. Malware includes computer viruses, worms, trojan horses, most rootkits, spyware, dishonest adware, crimeware, and other malicious and unwanted software), including true viruses. Viruses are sometimes confused with computer worms and Trojan horses, which are technically different. A worm can exploit security vulnerabilities to spread itself to other computers without needing to be transferred as part of a host, and a Trojan horse is a program that appears harmless but has a hidden agenda. Worms and Trojans, like viruses, may cause harm to either a computer system's hosted data, functional performance, or networking throughput, when they are executed. Some viruses and other malware have symptoms noticeable to the computer user, but many are surreptitious. -

Who Wrote Sobig? Copyright 2003-2004 Authors Page 1 of 48
Who Wrote Sobig? Copyright 2003-2004 Authors Page 1 of 48 Who Wrote Sobig? Version 1.0: 19-August-2003. Version 1.1: 25-August-2003. Version 1.2: 19-November-2003. Version 1.3: 17-July-2004. This sanitized variation for public release. Scheduled for release: 1-November-2004. This document is Copyright 2003-2004 by the authors. The PGP key included within this document identifies the authors. Who Wrote Sobig? Copyright 2003-2004 Authors Page 2 of 48 Table of Contents Table of Contents................................................................................................................................................... 2 1 About This Document..................................................................................................................................... 3 2 Overview........................................................................................................................................................ 5 3 Spam and Virus Release History..................................................................................................................... 6 3.1 Identifying Tools .................................................................................................................................... 6 3.2 Identifying Individuals and Specific Groups ............................................................................................ 6 3.3 Identifying Open Proxies and Usage........................................................................................................ 8 3.4 -

Image Spam Detection: Problem and Existing Solution
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 06 Issue: 02 | Feb 2019 www.irjet.net p-ISSN: 2395-0072 Image Spam Detection: Problem and Existing Solution Anis Ismail1, Shadi Khawandi2, Firas Abdallah3 1,2,3Faculty of Technology, Lebanese University, Lebanon ----------------------------------------------------------------------***--------------------------------------------------------------------- Abstract - Today very important means of communication messaging spam, Internet forum spam, junk fax is the e-mail that allows people all over the world to transmissions, and file sharing network spam [1]. People communicate, share data, and perform business. Yet there is who create electronic spam are called spammers [2]. nothing worse than an inbox full of spam; i.e., information The generally accepted version for source of spam is that it crafted to be delivered to a large number of recipients against their wishes. In this paper, we present a numerous anti-spam comes from the Monty Python song, "Spam spam spam spam, methods and solutions that have been proposed and deployed, spam spam spam spam, lovely spam, wonderful spam…" Like but they are not effective because most mail servers rely on the song, spam is an endless repetition of worthless text. blacklists and rules engine leaving a big part on the user to Another thought maintains that it comes from the computer identify the spam, while others rely on filters that might carry group lab at the University of Southern California who gave high false positive rate. it the name because it has many of the same characteristics as the lunchmeat Spam that is nobody wants it or ever asks Key Words: E-mail, Spam, anti-spam, mail server, filter. -

Criminals Become Tech Savvy
Attack Trends Elias Levy, [email protected] Ivan Arce, [email protected] Criminals Become Tech Savvy n this installment of Attack Trends, I’ll look at the growing 2003 alone. Fraud schemes are usu- ELIAS LEVY ally peddled by individuals who Symantec convergence of technically savvy computer crackers with spam potential victims (www. brightmail.com/brc_fraud-stats. financially motivated criminals. Historically, most com- html), such as the Nigerian, or 419, scam (see the 419 Coalition’s Web puter crime on the Internet has not been financially moti- site at http://home.rica.net/alphae/ I 419coal/). But as the number of vated: it was the result of either curious or malicious technical fraud cases has increased, so has the public’s awareness of them; fraudsters attackers, called crackers. This changed Increasingly on the defensive, are increasingly forced to resort to as the Internet became more com- spammers are fighting back by be- more intricate schemes. mercialized and more of the public has coming more sophisticated, generat- We’re now seeing the practice of gone online. Financially motivated ing unique messages, and finding new “phishing” gaining popularity with actors in the fauna of the Internet’s open proxies or SMTP relays to send fraudsters. Using this scheme, crimi- seedy underbelly—spammers and messages and hide their true sources. nals create email messages with re- fraudsters—soon joined crackers to turn addresses, links, and branding exploit this new potential goldmine. Fraud that seem to come from trusted, Internet fraud has also become a se- well-known organizations; the hope Spam rious problem. -

An Empirical Analysis of Spam Marketing Conversion by Chris Kanich, Christian Kreibich, Kirill Levchenko, Brandon Enright, Geoffrey M
DOI:10.1145/1562164.1562190 Spamalytics: An Empirical Analysis of Spam Marketing Conversion By Chris Kanich, Christian Kreibich, Kirill Levchenko, Brandon Enright, Geoffrey M. Voelker, Vern Paxson, and Stefan Savage Abstract third-party spam senders and through the pricing and gross The “conversion rate” of spam—the probability that an margins offered by various Interne marketing “affiliate unsolicited email will ultimately elicit a “sale”—underlies programs.”a However, the conversion rate depends funda- the entire spam value proposition. However, our under- mentally on group actions—on what hundreds of millions standing of this critical behavior is quite limited, and the of Internet users do when confronted with a new piece of literature lacks any quantitative study concerning its true spam—and is much harder to obtain. While a range of anec- value. In this paper we present a methodology for measuring dotal numbers exist, we are unaware of any well-documented the conversion rate of spam. Using a parasitic infiltration of measurement of the spam conversion rate.b an existing botnet’s infrastructure, we analyze two spam In part, this problem is methodological. There are no campaigns: one designed to propagate a malware Trojan, apparent methods for indirectly measuring spam conver- the other marketing online pharmaceuticals. For nearly a sion. Thus, the only obvious way to extract this data is to half billion spam emails we identify the number that are build an e-commerce site, market it via spam, and then successfully delivered, the number that pass through popu- record the number of sales. Moreover, to capture the spam- lar antispam filters, the number that elicit user visits to the mer’s experience with full fidelity, such a study must also advertised sites, and the number of “sales” and “infections” mimic their use of illicit botnets for distributing email and produced. -

Availability Digest
the Availability Digest www.availabilitydigest.com Spamalytics October 2009 Masses of spam can bring your email service to its knees. To protect against this, complex spam filters are used on email servers and on browsers. But how effective are the filters? To answer this question, a team of scientists at the Department of Computer Science and Engineering, University of California, and the International Computer Science Institute became spammers of sorts. They reasoned that the best way to measure spam is to be a spammer. The scientists orchestrated a parasitic infiltration of an existing spam botnet’s infrastructure and caused it to modify some of the spam it was sending so as to redirect the spam to web sites under the control of the team. These web sites presented “defanged” versions of the spammer’s own web sites. The infiltration was accomplished by masquerading as bots under the control of the infiltrated botnet.1 The team modified spam so that it would cause no harm to anyone. All it did was to allow the team to measure the conversion rate of its modified spam campaigns. The team defined “conversion rate” as the probability that a spam email will result in a desired action. There were two desired actions that they studied – the purchase of a product and the infection of a browser. Armed with these results and with the cost of spam mailings, the team then considered the value proposition of spamming. They call this science “spamalytics.” The Subterfuge The Storm Botnet The research team selected the Storm botnet as its victim. -

Threatsaurus the A-Z of Computer and Data Security Threats 2 the A-Z of Computer and Data Security Threats
Threatsaurus The A-Z of computer and data security threats 2 The A-Z of computer and data security threats Whether you’re an IT professional, use a computer The company has more than two decades at work, or just browse the Internet, this book is of experience and a global network of threat for you. We explain the facts about threats to your analysis centers that allow us to respond rapidly computers and to your data in simple, easy-to- to emerging threats. As a result, Sophos achieves understand language. the highest levels of customer satisfaction in the industry. Our headquarters are located in Boston, Sophos frees IT managers to focus on their Mass., and Oxford, UK. businesses. We provide endpoint, encryption, email, web and network security solutions that are simple to deploy, manage and use. Over 100 million users trust us for the best protection against today’s complex threats, and analysts endorse us as a leader. Copyright 2012 Sophos Limited. All rights reserved. No part of this publication may be reproduced, stored in a retrieval system or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording or otherwise unless you have the prior permission in writing of the copyright owner. Sophos and Sophos Anti-Virus are registered trademarks of Sophos Limited and Sophos Group. All other product and company names mentioned are trademarks or registered trademarks of their respective owners. 3 Contents Introduction 5 A-Z of threats 8 Security software/hardware 84 Safety tips 108 Malware timeline 127 4 Introduction Everyone knows about computer viruses. -
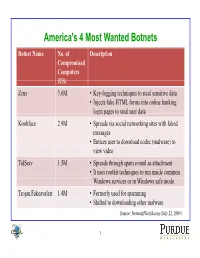
Storm Botnet • Methodology • Experimental Results • Conclusions
America's 4 Most Wanted Botnets Botnet Name No. of Description Compromised Computers (US) Zeus 3.6M • Key-logging techniques to steal sensitive data • Injects fake HTML forms into online banking login pages to steal user data Koobface 2.9M • Spreads via social networking sites with faked messages • Entices user to download codec (malware) to view video TidServ 1.5M • Spreads through spam e-mail as attachment. • It uses rootkit techniques to run inside common Widindows serv ices or i n Wi idndows saf e mod e. Trojan.Fakeavalert 1.4M • Formerly used for spamming • Shifted to downloading other malware Source: NetworkWorld.com (July 22, 2009) 1 SltiSpamalytics: AEAn Emp iilAlirical Analysi s of fS Spam Marketing Conversion Chris Kanich, Christian Kreibich, Kirill Levchenko, Brandon Enright, Geoffrey Voelker, Vern Paxson, Stefan Savage ACM Conference on Computer and Communications Security (CCS 2008) Summarized by Gaspar Modelo-Howard 2 Abstract • Measurement study on the “conversion rate” of spam campaigns – Probability that an unsolicited email will elicit a “sale” • Present a methodology using Botnet infiltration • Analyze two spam campaigns – Trojan propagation – Online pharmaceutical marketing • For more than 469M spam emails, authors identified – Number that pass thru anti-spam filters – Number that elicit use visits to advertised sites (response rate) – Number of “sales” and “infections” produced (conversion rate) 3 Agenda • Introduction • Storm Botnet • Methodology • Experimental Results • Conclusions 4 Introduction (1) • Hard to find -

Addressing Malicious SMTP-Based Mass-Mailing Activity Within an Enterprise Network
Addressing Malicious SMTP-based Mass-Mailing Activity Within an Enterprise Network David Whyte P.C. van Oorschot Evangelos Kranakis Abstract Malicious mass-mailing activity on the Internet is a serious and continuing threat that includes mass- mailing worms, spam, and phishing. A mechanism commonly used to deliver such malicious mass mail is an SMTP-engine, which turns an infected system into a malicious mail server. We present a technique that enables, in certain network environments, detection and containment of (even zero-day) SMTP-engine based mass-mailing activity within a single mailing attempt. Contrary to other mass- mailing detection techniques our approach is content independent and requires no attachment processing, statistical measures, or system behavioral analysis. It relies strictly on the observation of DNS MX queries within the enterprise network. Our approach can be used as an alternative to port 25 blocking and in conjunction with current proposals to address mass-mailing abuses (e.g. SPF, DomainKeys). Our analysis on network traces from a medium sized university network indicates that MX query activity from client systems is a viable SMTP-engine detection method with a very low false positive rate. Our detection and containment approach has been successfully tested with a prototype using a live mass- mailing worm in an isolated test network. 1 Introduction Internet users are inundated by a steady stream of emails infected with malicious code (mass-mailing worms and viruses), unwanted product advertisements (spam), and requests for personal information from criminals masquerading as legitimate entities to enable the commission of fraudulent activity (phishing). The use of gateway anti-virus (and per client) software and spam filters offers some measure of protec- tion. -

Studying Spamming Botnets Using Botlab John P
Studying Spamming Botnets Using Botlab John P. John Alexander Moshchuk Steven D. Gribble Arvind Krishnamurthy Department of Computer Science & Engineering University of Washington Abstract erate. Passive honeynets [13, 27, 41] are becoming less applicable to this problem over time, as botnets are in- In this paper we present Botlab, a platform that con- creasingly propagating via social engineering and web- tinually monitors and analyzes the behavior of spam- based drive-by download attacks that honeynets will not oriented botnets. Botlab gathers multiple real-time observe. Overall, there is still opportunity to design de- streams of information about botnets taken from distinct fensive tools to filter botnet spam, identify and block perspectives. By combining and analyzing these streams, botnet-hosted malicious sites, and pinpoint which hosts Botlab can produce accurate, timely, and comprehensive are currently participating in a spamming botnet. data about spam botnet behavior. Our prototype system In this paper we turn the tables on spam botnets by us- integrates information about spam arriving at the Univer- ing the vast quantities of spam that they generate to mon- sity of Washington, outgoing spam generated by captive itor and analyze their behavior. To do this, we designed botnet nodes, and information gleaned from DNS about and implemented Botlab, a continuously operating bot- URLs found within these spam messages. net monitoring platform that provides real-time informa- We describe the design and implementation of Botlab, tion regarding botnet activity. Botlab consumes a feed of including the challenges we had to overcome, such as all incoming spam arriving at the University of Washing- preventing captive nodes from causing harm or thwart- ton, allowing it to find fresh botnet binaries propagated ing virtual machine detection.