The Effects of Genetic Variants on Protein Structure and Their Associations with Preeclampsia
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Screening and Identification of Key Biomarkers in Clear Cell Renal Cell Carcinoma Based on Bioinformatics Analysis
bioRxiv preprint doi: https://doi.org/10.1101/2020.12.21.423889; this version posted December 23, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Screening and identification of key biomarkers in clear cell renal cell carcinoma based on bioinformatics analysis Basavaraj Vastrad1, Chanabasayya Vastrad*2 , Iranna Kotturshetti 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karanataka, India. 3. Department of Ayurveda, Rajiv Gandhi Education Society`s Ayurvedic Medical College, Ron, Karnataka 562209, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India bioRxiv preprint doi: https://doi.org/10.1101/2020.12.21.423889; this version posted December 23, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract Clear cell renal cell carcinoma (ccRCC) is one of the most common types of malignancy of the urinary system. The pathogenesis and effective diagnosis of ccRCC have become popular topics for research in the previous decade. In the current study, an integrated bioinformatics analysis was performed to identify core genes associated in ccRCC. An expression dataset (GSE105261) was downloaded from the Gene Expression Omnibus database, and included 26 ccRCC and 9 normal kideny samples. Assessment of the microarray dataset led to the recognition of differentially expressed genes (DEGs), which was subsequently used for pathway and gene ontology (GO) enrichment analysis. -

Annual Report DDUV 2009
Research at the de Duve Institute and Brussels Branch of the Ludwig Institute for Cancer Research August 2009 de Duve Institute Introduction 5 Miikka Vikkula 12 Frédéric Lemaigre 20 Annabelle Decottignies and Charles de Smet 25 Emile Vanschaftingen 31 Françoise Bontemps 37 Jean-François Collet 42 Guido Bommer 47 Mark Rider 50 Fred Opperdoes 56 Pierre Courtoy 62 Etienne Marbaix 69 Jean-Baptiste Demoulin 75 Jean-Paul Coutelier 80 Thomas Michiels 84 Pierre Coulie 89 LICR Introduction 95 Benoît Van den Eynde 98 Pierre van der Bruggen 106 Nicolas Van Baren 114 Jean-Christophe Renauld 119 Stefan Constantinescu 125 The de Duve Institute 5 THE DE DUVE INSTITUTE: AN INTERNATIONAL BIOMEDICAL RESEARCH INSTITUTE In 1974, when Christian de Duve founded the Institute of Cellular Pathology (ICP), now rena- med the de Duve Institute, he was acutely aware of the constrast between the enormous progress in biological sciences that had occurred in the 20 preceding years and the modesty of the medical advances that had followed. He therefore crea- ted a research institution based on the principle that basic research in biology would be pursued by the investigators with complete freedom, but that special attention would be paid to the exploi- tation of basic advances for medical progress. It was therefore highly appropriate for the Institute to be located on the campus of the Faculty of Emile Van Schaftingen Medicine of the University of Louvain (UCL). This campus is located in Brussels. The Univer- sity hospital (Clinique St Luc) is located within walking distance of the Institute. The main commitment of the members of the de Duve Institute is research. -

Articles Catalytic Cycling in Β-Phosphoglucomutase: a Kinetic
9404 Biochemistry 2005, 44, 9404-9416 Articles Catalytic Cycling in â-Phosphoglucomutase: A Kinetic and Structural Analysis†,‡ Guofeng Zhang, Jianying Dai, Liangbing Wang, and Debra Dunaway-Mariano* Department of Chemistry, UniVersity of New Mexico, Albuquerque, New Mexico 87131-0001 Lee W. Tremblay and Karen N. Allen* Department of Physiology and Biophysics, Boston UniVersity School of Medicine, Boston, Massachusetts 02118-2394 ReceiVed March 26, 2005; ReVised Manuscript ReceiVed May 18, 2005 ABSTRACT: Lactococcus lactis â-phosphoglucomutase (â-PGM) catalyzes the interconversion of â-D-glucose 1-phosphate (â-G1P) and â-D-glucose 6-phosphate (G6P), forming â-D-glucose 1,6-(bis)phosphate (â- G16P) as an intermediate. â-PGM conserves the core domain catalytic scaffold of the phosphatase branch of the HAD (haloalkanoic acid dehalogenase) enzyme superfamily, yet it has evolved to function as a mutase rather than as a phosphatase. This work was carried out to identify the structural basis underlying this diversification of function. In this paper, we examine â-PGM activation by the Mg2+ cofactor, â-PGM activation by Asp8 phosphorylation, and the role of cap domain closure in substrate discrimination. First, the 1.90 Å resolution X-ray crystal structure of the Mg2+-â-PGM complex is examined in the context of + + previously reported structures of the Mg2 -R-D-galactose-1-phosphate-â-PGM, Mg2 -phospho-â-PGM, and Mg2+-â-glucose-6-phosphate-1-phosphorane-â-PGM complexes to identify conformational changes that occur during catalytic turnover. The essential role of Asp8 in nucleophilic catalysis was confirmed by demonstrating that the D8A and D8E mutants are devoid of catalytic activity. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Preclinical Evaluation of Protein Disulfide Isomerase Inhibitors for the Treatment of Glioblastoma by Andrea Shergalis
Preclinical Evaluation of Protein Disulfide Isomerase Inhibitors for the Treatment of Glioblastoma By Andrea Shergalis A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Medicinal Chemistry) in the University of Michigan 2020 Doctoral Committee: Professor Nouri Neamati, Chair Professor George A. Garcia Professor Peter J. H. Scott Professor Shaomeng Wang Andrea G. Shergalis [email protected] ORCID 0000-0002-1155-1583 © Andrea Shergalis 2020 All Rights Reserved ACKNOWLEDGEMENTS So many people have been involved in bringing this project to life and making this dissertation possible. First, I want to thank my advisor, Prof. Nouri Neamati, for his guidance, encouragement, and patience. Prof. Neamati instilled an enthusiasm in me for science and drug discovery, while allowing me the space to independently explore complex biochemical problems, and I am grateful for his kind and patient mentorship. I also thank my committee members, Profs. George Garcia, Peter Scott, and Shaomeng Wang, for their patience, guidance, and support throughout my graduate career. I am thankful to them for taking time to meet with me and have thoughtful conversations about medicinal chemistry and science in general. From the Neamati lab, I would like to thank so many. First and foremost, I have to thank Shuzo Tamara for being an incredible, kind, and patient teacher and mentor. Shuzo is one of the hardest workers I know. In addition to a strong work ethic, he taught me pretty much everything I know and laid the foundation for the article published as Chapter 3 of this dissertation. The work published in this dissertation really began with the initial identification of PDI as a target by Shili Xu, and I am grateful for his advice and guidance (from afar!). -

(TGFBI) Function and Paclitaxel Response in Ovarian Cancer Cells David a Tumbarello1,2, Jillian Temple1 and James D Brenton1*
Tumbarello et al. Molecular Cancer 2012, 11:36 http://www.molecular-cancer.com/content/11/1/36 RESEARCH Open Access β3 integrin modulates transforming growth factor beta induced (TGFBI) function and paclitaxel response in ovarian cancer cells David A Tumbarello1,2, Jillian Temple1 and James D Brenton1* Abstract Background: The extracellular matrix (ECM) has a key role in facilitating the progression of ovarian cancer and we have shown recently that the secreted ECM protein TGFBI modulates the response of ovarian cancer to paclitaxel-induced cell death. Results: We have determined TGFBI signaling from the extracellular environment is preferential for the cell surface αvβ3 integrin heterodimer, in contrast to periostin, a TGFBI paralogue, which signals primarily via a β1 integrin-mediated pathway. We demonstrate that suppression of β1 integrin expression, in β3 integrin-expressing ovarian cancer cells, increases adhesion to rTGFBI. In addition, Syndecan-1 and −4 expression is dispensable for adhesion to rTGFBI and loss of Syndecan-1 cooperates with the loss of β1 integrin to further enhance adhesion to rTGFBI. The RGD motif present in the carboxy-terminus of TGFBI is necessary, but not sufficient, for SKOV3 cell adhesion and is dispensable for adhesion of ovarian cancer cells lacking β3 integrin expression. In contrast to TGFBI, the carboxy-terminus of periostin, lacking a RGD motif, is unable to support adhesion of ovarian cancer cells. Suppression of β3 integrin in SKOV3 cells increases resistance to paclitaxel-induced cell death while suppression of β1 integrin has no effect. Furthermore, suppression of TGFBI expression stimulates a paclitaxel resistant phenotype while suppression of fibronectin expression, which primarily signals through a β1 integrin-mediated pathway, increases paclitaxel sensitivity. -

Datasheet: VPA00676 Product Details
Datasheet: VPA00676 Description: RABBIT ANTI TGFBI Specificity: TGFBI Format: Purified Product Type: PrecisionAb™ Polyclonal Isotype: Polyclonal IgG Quantity: 100 µl Product Details Applications This product has been reported to work in the following applications. This information is derived from testing within our laboratories, peer-reviewed publications or personal communications from the originators. Please refer to references indicated for further information. For general protocol recommendations, please visit www.bio-rad-antibodies.com/protocols. Yes No Not Determined Suggested Dilution Western Blotting 1/1000 PrecisionAb antibodies have been extensively validated for the western blot application. The antibody has been validated at the suggested dilution. Where this product has not been tested for use in a particular technique this does not necessarily exclude its use in such procedures. Further optimization may be required dependant on sample type. Target Species Human Product Form Purified IgG - liquid Preparation Rabbit polyclonal antibody purified by affinity chromatography Buffer Solution Phosphate buffered saline Preservative 0.01% Thiomersal Stabilisers 1% Bovine Serum Albumin <50% Glycerol Immunogen Recombinant protein encompassing part of the middle region of human TGFBI External Database Links UniProt: Q15582 Related reagents Entrez Gene: 7045 TGFBI Related reagents Synonyms BIGH3 Specificity Rabbit anti Human TGFBI antibody recognizes the transforming growth factor-beta-induced protein ig-h3, also known as RGD-containing collagen-associated protein (RGD-CAP), beta ig-h3, Page 1 of 2 kerato-epithelin or transforming growth factor, beta-induced 68 kDa. TGFBI gene encodes an RGD-containing protein that binds to type I, II and IV collagens. The RGD motif is found in many extracellular matrix proteins modulating cell adhesion and serves as a ligand recognition sequence for several integrins. -

Structural Variant Calling by Assembly in Whole Human Genomes: Applications in Hypoplastic Left Heart Syndrome by Matthew Kendzi
STRUCTURAL VARIANT CALLING BY ASSEMBLY IN WHOLE HUMAN GENOMES: APPLICATIONS IN HYPOPLASTIC LEFT HEART SYNDROME BY MATTHEW KENDZIOR THESIS Submitted in partial FulFillment oF tHe requirements for the degree of Master of Science in BioinFormatics witH a concentration in Crop Sciences in the Graduate College of the University oF Illinois at Urbana-Champaign, 2019 Urbana, Illinois Master’s Committee: ProFessor MattHew Hudson, CHair ResearcH Assistant ProFessor Liudmila Mainzer ProFessor SaurabH SinHa ABSTRACT Variant discovery in medical researcH typically involves alignment oF sHort sequencing reads to the human reference genome. SNPs and small indels (variants less than 50 nucleotides) are the most common types oF variants detected From alignments. Structural variation can be more diFFicult to detect From short-read alignments, and thus many software applications aimed at detecting structural variants From short read alignments have been developed. However, these almost all detect the presence of variation in a sample using expected mate-pair distances From read data, making them unable to determine the precise sequence of the variant genome at the speciFied locus. Also, reads from a structural variant allele migHt not even map to the reference, and will thus be lost during variant discovery From read alignment. A variant calling by assembly approacH was used witH tHe soFtware Cortex-var for variant discovery in Hypoplastic Left Heart Syndrome (HLHS). THis method circumvents many of the limitations oF variants called From a reFerence alignment: unmapped reads will be included in a sample’s assembly, and variants up to thousands of nucleotides can be detected, with the Full sample variant allele sequence predicted. -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Hypoxia Evokes Increased PDI and PDIA6 Expression in The
© 2019. Published by The Company of Biologists Ltd | Biology Open (2019) 8, bio038851. doi:10.1242/bio.038851 RESEARCH ARTICLE Hypoxia evokes increased PDI and PDIA6 expression in the infarcted myocardium of ex-germ-free and conventionally raised mice Klytaimnistra Kiouptsi1,*, Stefanie Finger2, Venkata S. Garlapati2, Maike Knorr2, Moritz Brandt1,2,3, Ulrich Walter1,3, Philip Wenzel1,2,3 and Christoph Reinhardt1,3,* ABSTRACT INTRODUCTION The prototypic protein disulfide isomerase (PDI), encoded by the Acute myocardial infarction (AMI) triggers the unfolded protein P4HB gene, has been described as a survival factor in ischemic response (UPR) in cardiomyocytes to protect the ischemic cardiomyopathy. However, the role of protein disulfide isomerase surrounding from hypoxic stress (Thuerauf et al., 2006; Wang associated 6 (PDIA6) under hypoxic conditions in the myocardium et al., 2018). The prototypic protein disulphide isomerase (PDI; P4HB remains enigmatic, and it is unknown whether the gut microbiota encoded by ), the prototypic PDI family member ensuring influences the expression of PDI and PDIA6 under conditions of proper protein folding in the endoplasmic reticulum (ER), was acute myocardial infarction. Here, we revealed that, in addition to the previously shown to protect from myocardial infarction (Toldo prototypic PDI, the PDI family member PDIA6, a regulator of et al., 2011a). However, there is an increase in P4HB levels with a the unfolded protein response, is upregulated in the mouse paradoxical decrease of its active form in the infarcted diabetic cardiomyocyte cell line HL-1 when cultured under hypoxia. In vivo, mouse heart (Toldo et al., 2011b). PDI and other PDI family in the left anterior descending artery (LAD) ligation mouse model members are instrumental to ensure correct protein folding and of acute myocardial infarction, similar to PDI, PDIA6 protein to enhance superoxide dismutase 1 activity (Toldo et al., 2011a). -

Transcriptomic and Proteomic Profiling Provides Insight Into
BASIC RESEARCH www.jasn.org Transcriptomic and Proteomic Profiling Provides Insight into Mesangial Cell Function in IgA Nephropathy † † ‡ Peidi Liu,* Emelie Lassén,* Viji Nair, Celine C. Berthier, Miyuki Suguro, Carina Sihlbom,§ † | † Matthias Kretzler, Christer Betsholtz, ¶ Börje Haraldsson,* Wenjun Ju, Kerstin Ebefors,* and Jenny Nyström* *Department of Physiology, Institute of Neuroscience and Physiology, §Proteomics Core Facility at University of Gothenburg, University of Gothenburg, Gothenburg, Sweden; †Division of Nephrology, Department of Internal Medicine and Department of Computational Medicine and Bioinformatics, University of Michigan, Ann Arbor, Michigan; ‡Division of Molecular Medicine, Aichi Cancer Center Research Institute, Nagoya, Japan; |Department of Immunology, Genetics and Pathology, Uppsala University, Uppsala, Sweden; and ¶Integrated Cardio Metabolic Centre, Karolinska Institutet Novum, Huddinge, Sweden ABSTRACT IgA nephropathy (IgAN), the most common GN worldwide, is characterized by circulating galactose-deficient IgA (gd-IgA) that forms immune complexes. The immune complexes are deposited in the glomerular mesangium, leading to inflammation and loss of renal function, but the complete pathophysiology of the disease is not understood. Using an integrated global transcriptomic and proteomic profiling approach, we investigated the role of the mesangium in the onset and progression of IgAN. Global gene expression was investigated by microarray analysis of the glomerular compartment of renal biopsy specimens from patients with IgAN (n=19) and controls (n=22). Using curated glomerular cell type–specific genes from the published literature, we found differential expression of a much higher percentage of mesangial cell–positive standard genes than podocyte-positive standard genes in IgAN. Principal coordinate analysis of expression data revealed clear separation of patient and control samples on the basis of mesangial but not podocyte cell–positive standard genes. -
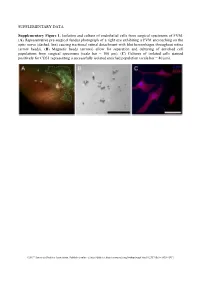
Supplementary Figures and Tables
SUPPLEMENTARY DATA Supplementary Figure 1. Isolation and culture of endothelial cells from surgical specimens of FVM. (A) Representative pre-surgical fundus photograph of a right eye exhibiting a FVM encroaching on the optic nerve (dashed line) causing tractional retinal detachment with blot hemorrhages throughout retina (arrow heads). (B) Magnetic beads (arrows) allow for separation and culturing of enriched cell populations from surgical specimens (scale bar = 100 μm). (C) Cultures of isolated cells stained positively for CD31 representing a successfully isolated enriched population (scale bar = 40 μm). ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Figure 2. Efficient siRNA knockdown of RUNX1 expression and function demonstrated by qRT-PCR, Western Blot, and scratch assay. (A) RUNX1 siRNA induced a 60% reduction of RUNX1 expression measured by qRT-PCR 48 hrs post-transfection whereas expression of RUNX2 and RUNX3, the two other mammalian RUNX orthologues, showed no significant changes, indicating specificity of our siRNA. Functional inhibition of Runx1 signaling was demonstrated by a 330% increase in insulin-like growth factor binding protein-3 (IGFBP3) RNA expression level, a known target of RUNX1 inhibition. Western blot demonstrated similar reduction in protein levels. (B) siRNA- 2’s effect on RUNX1 was validated by qRT-PCR and western blot, demonstrating a similar reduction in both RNA and protein. Scratch assay demonstrates functional inhibition of RUNX1 by siRNA-2. ns: not significant, * p < 0.05, *** p < 0.001 ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Table 1.