3. Climbing Fiber Input Preferentially Signals Correctly Timed Movements
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

FIRST PROOF Cerebellum
Article Number : EONS : 0736 GROSS ANATOMY Cerebellum Cortex The cerebellar cortex is an extensive three-layered sheet with a surface approximately 15 cm laterally THE HUMAN CEREBELLUM (‘‘little brain’’) is a and 180 cm rostrocaudally but densely folded around significant part of the central nervous system both three pairs of nuclei. The cortex is divided into three in size and in neural structure. It occupies approxi- transverse lobes: Anterior and posterior lobes are mately one-tenth of the cranial cavity, sitting astride separated by the primary fissure, and the smaller the brainstem, beneath the occipital cortex, and flocculonodular lobe is separated by the poster- contains more neurons than the whole of the cerebral olateral fissure (Fig. 1). The anterior and posterior cortex. It consists of an extensive cortical sheet, lobes are folded into a number of lobules and further densely folded around three pairs of nuclei. The folded into a series of folia. This transverse organiza- cortex contains only five main neural cell types and is tion is then divided at right angles into broad one of the most regular and uniform structures in the longitudinal regions. The central vermis, named for central nervous system (CNS), with an orthogonal its worm-like appearance, is most obvious in the ‘‘crystalline’’ organization. Major connections are posterior lobe. On either side is the paravermal or made to and from the spinal cord, brainstem, and intermediate cortex, which merges into the lateral sensorimotor areas of the cerebral cortex. hemispheres. The most common causes of damage to the cerebellum are stroke, tumors, or multiple sclerosis. -

Three-Dimensional Comparison of Ultrastructural Characteristics at Depressing and Facilitating Synapses Onto Cerebellar Purkinje Cells
The Journal of Neuroscience, September 1, 2001, 21(17):6666–6672 Three-Dimensional Comparison of Ultrastructural Characteristics at Depressing and Facilitating Synapses onto Cerebellar Purkinje Cells Matthew A. Xu-Friedman,1 Kristen M. Harris,2 and Wade G. Regehr1 1Department of Neurobiology, Harvard Medical School, Boston, Massachusetts 02115, and 2Department of Biology, Boston University, Boston, Massachusetts 02215 Cerebellar Purkinje cells receive two distinctive types of exci- vesicles per release site to test whether this number determines tatory inputs. Climbing fiber (CF) synapses have a high proba- the probability of release and synaptic plasticity. PF and CF bility of release and show paired-pulse depression (PPD), synapses had the same number of anatomically docked vesi- whereas parallel fiber (PF) synapses facilitate and have a low cles (7–8). The number of docked vesicles at the CF does not probability of release. We examined both types of synapses support a simple model of PPD in which release of a single using serial electron microscopic reconstructions in 15-d-old vesicle during the first pulse depletes the anatomically docked rats to look for anatomical correlates of these differences. PF vesicle pool at a synapse. Alternatively, only a fraction of ana- and CF synapses were distinguishable by their overall ultra- tomically docked vesicles may be release ready, or PPD could structural organization. There were differences between PF and result from multivesicular release at each site. Similarities in the CF synapses in how many release sites were within 1 mofa number of docked vesicles for PF and CF synapses indicate mitochondrion (67 vs 84%) and in the degree of astrocytic that differences in probability of release are unrelated to the ensheathment (67 vs 94%). -

Cerebellar Histology & Circuitry
Cerebellar Histology & Circuitry Histology > Neurological System > Neurological System CEREBELLAR HISTOLOGY & CIRCUITRY SUMMARY OVERVIEW Gross Anatomy • The folding of the cerebellum into lobes, lobules, and folia allows it to assume a tightly packed, inconspicuous appearance in the posterior fossa. • The cerebellum has a vast surface area, however, and when stretched, it has a rostrocaudal expanse of roughly 120 centimeters, which allows it to hold an estimated one hundred billion granule cells — more cells than exist within the entire cerebral cortex. - It is presumed that the cerebellum's extraordinary cell count plays an important role in the remarkable rehabilitation commonly observed in cerebellar stroke. Histology Two main classes of cerebellar nuclei • Cerebellar cortical neurons • Deep cerebellar nuclei CEREBELLAR CORTICAL CELL LAYERS Internal to external: Subcortical white matter Granule layer (highly cellular) • Contains granule cells, Golgi cells, and unipolar brush cells. Purkinje layer 1 / 9 • Single layer of large Purkinje cell bodies. • Purkinje cells project a fine axon through the granule cell layer. - Purkinje cells possess a large dendritic system that arborizes (branches) extensively and a single fine axon. Molecular layer • Primarily comprises cell processes but also contains stellate and basket cells. DEEP CEREBELLAR NUCLEI From medial to lateral: Fastigial Globose Emboliform Dentate The globose and emboliform nuclei are also known as the interposed nuclei • A classic acronym for the lateral to medial organization of the deep nuclei is "Don't Eat Greasy Food," for dentate, emboliform, globose, and fastigial. NEURONS/FUNCTIONAL MODULES • Fastigial nucleus plays a role in the vestibulo- and spinocerebellum. • Interposed nuclei are part of the spinocerebellum. • Dentate nucleus is part of the pontocerebellum. -

2141.Full.Pdf
The Journal of Neuroscience, June 1989, g(8): 2141-2150 Physiological and Anatomical Studies of the Interactions Between Purkinje Cells and Basket Cells in the Cat’s Cerebellar Cortex: Evidence for a Unitary Relationship Daniel L. O’Donoghue,a James S. King, and Georgia A. Bishop Department of Anatomy and Neuroscience Program, The Ohio State University, Columbus, Ohio 43210 Intracellular recordings have been obtained from neurons in tions of these units with HRP revealed that the responseswere lobule V of the cat’s vermis, which were identified as basket obtained from basket cells. cells following intracellular injections of HRP. Stimulation of Basket cells are interneurons that are located in the lower the inferior cerebellar peduncle or peripheral nerves elicited molecular layer of the cerebellar cortex (Fox et al., 1967; Mug- an initial depolarizing and subsequent hyperpolarizing re- naini, 1972; Palay and Chan-Palay, 1974). Their somata are sponse. Neither potential could be graded with changes in interspersedbetween and within the dendritic trees of Purkinje stimulus intensity; both displayed all-or-none properties at cells (Fox et al., 1967; Palay and Chan-Palay, 1974); their den- threshold levels of stimulation. The depolarization and hy- drites extend toward the pial surface, and their axons are pri- perpolarization were confirmed as an excitatory postsyn- marily oriented in the sagittal plane. Descendingcollaterals of aptic potential and an inhibitory postsynaptic potential (IPSP), theseaxons form a unique pericellular basket around the somata respectively, on the basis of their response to intracellular and axon hillocks of Purkinje cells, defined as the pinceau by injections of hyperpolarizing and depolarizing currents into Ram6n y Cajal (19 11). -

Synaptic Remodeling Between Climbing Fibers and Purkinje Cells in the Developing Cerebellum Begins with Positive Feedback Addition of Synapses
bioRxiv preprint doi: https://doi.org/10.1101/627299; this version posted May 3, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. The rich get richer: synaptic remodeling between climbing fibers and Purkinje cells in the developing cerebellum begins with positive feedback addition of synapses. AUTHORS Alyssa Michelle Wilson1*✝, Richard Schalek2, Adi Suissa-Peleg2,3, Thouis Ray Jones4, Seymour Knowles-Barley5, Hanspeter Pfister3, Jeff William Lichtman6*. 1Department of Physics, Harvard University, Cambridge, MA 02138, USA 2Center for Brain Science, Harvard University, Cambridge, MA 02138, USA 3School of Engineering and Applied Sciences, Harvard University, Cambridge, MA 02138, USA 4Broad Institute, Cambridge, MA 02142, USA 5Volpara Health Technologies, Wellington, 6011, New Zealand 6Department of Molecular and Cellular Biology, Harvard University, Cambridge, MA 02138, USA *Correspondence: [email protected] (A.M.W.), [email protected] (J.W.L.) ✝Lead Contact SUMMARY During postnatal development, cerebellar climbing fibers strongly innervate a subset of their original Purkinje cell targets and eliminate their connections from the rest. In the adult, each climbing fiber innervates a small number of Purkinje cells and each Purkinje cell is innervated by a single climbing fiber. To get insight about the processes responsible for this remapping, we reconstructed serial electron microscopy datasets from mice during the first postnatal week. In contrast to adult connectivity, individual neonatal climbing fibers innervate many nearby Purkinje cells, and multiple climbing fibers innervate each Purkinje cell. -

Multiple Climbing Fibers Signal to Molecular Layer Interneurons
ARTICLES Multiple climbing fibers signal to molecular layer interneurons exclusively via glutamate spillover Germa´n Szapiro & Boris Barbour Spillover of glutamate under physiological conditions has only been established as an adjunct to conventional synaptic transmission. Here we describe a pure spillover connection between the climbing fiber and molecular layer interneurons in the rat cerebellar cortex. We show that, instead of acting via conventional synapses, multiple climbing fibers activate AMPA- and NMDA- type glutamate receptors on interneurons exclusively via spillover. Spillover from the climbing fiber represents a form of glutamatergic volume transmission that could be triggered in a regionalized manner by experimentally observed synchronous climbing fiber activity. Climbing fibers are known to direct parallel fiber synaptic plasticity in interneurons, so one function of this spillover is likely to involve controlling synaptic plasticity. http://www.nature.com/natureneuroscience Spillover of neurotransmitter—action at synaptic contacts other than unknown type of axodendritic (or axosomatic) contact17. Despite those where it was released—has proved to be a controversial subject. extensive and tight apposition between axonal (climbing fiber) and For simple, small glutamatergic synapses, spillover has only rarely been somatodendritic (interneuron) membranes, the apparent absence of reported1,2 at activity levels that are physiologically plausible, and vesicles and glutamate receptors argues against classical synaptic modeling suggests that the spillover of glutamate at simple synapses transmission occurring at these junctions. is probably not significant3 (but see ref. 4). It has been argued that Here we confirm the existence of the climbing fiber–interneuron spillover would reduce synaptic independence and thus reduce the connection and characterize its mechanism of transmission. -
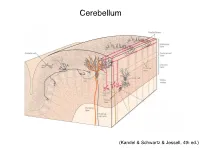
Cerebellum and Activation of the Cerebellum IO ST During Nonmotor Tasks
Cerebellum (Kandel & Schwartz & Jessell, 4th ed.) Granule186 cells are irreducibly smallChapter (6-8 7 μm) stellate cell basket cell outer synaptic layer PC rs cap PC layer grc Go inner 6 μm synaptic layer Figure 7.15 Largest cerebellar neuron occupies more than a 1,000-fold greater volume than smallest neuron. Thin section (~1 μ m) through monkey cerebellar cortex. Purkinje cell body (PC) and nucleus are far larger than those of granule cell (grc). The latter cluster to leave space for mossy fiber terminals to form glomeruli with grc dendritic claws and space for Golgi cells (Go). Note rich network of capillaries (cap). Fine, scat- tered dots are mitochondria. Courtesy of E. Mugnaini. brain ’ s most numerous neuron, this small cost grows large (see also chapter 13). Much of the inner synaptic layer is occupied by the large axon terminals of mossy fibers (figures 7.1 and 7.16). A terminal interlaces with multiple (~15) dendritic claws, each from a different but neighboring granule cell, and forms a complex knot (glomerulus ), nearly as large as a granule cell body (figures 7.1 and 7.16). The mossy fiber axon fires at an unusually high mean rate (up to 200 Hz) and is therefore among the brain’ s thickest (figure 4.6). To match the axon’ s high rate, a terminal expresses 150 active zones, 10 per postsynaptic granule cell (figure 7.16). These sites are capable of driving … and most expensive. 190 Chapter 7 10 4 8 3 9 19 10 10 × 6 × 2 2 4 ATP/s/cell ATP/s/cell ATP/s/m 1 2 0 0 astrocyte astrocyte Golgi cell Golgi cell basket cell basket cell stellate cell stellate cell granule cell granule cell mossy fiber mossy fiber Purkinje cell Purkinje Purkinje cell Purkinje Bergman glia Bergman glia climbing fiber climbing fiber Figure 7.18 Energy costs by cell type. -

The Organization of the Corticonuclear and Olivocerebellar Climbing Fiber
Journal of Neurocytology 33, 5–21 (2004) The organization of the corticonuclear and olivocerebellar climbing fiber projections to the rat cerebellar vermis: The congruence of projection zones and the zebrin pattern JAN VOOGD∗ and TOMJ.H.RUIGROK Department of Neuroscience, Erasmus MC, Rotterdam, P.O. Box 1738, 3000 DR Rotterdam, The Netherlands [email protected] Received 23 May 2003; revised 2 September 2003; accepted 2 September 2003 Abstract The zonal organization of the corticonuclear and the olivocerebellar climbing fiber projections to the vermis of the cerebellum of the rat was compared to the pattern of zebrin-positive and zebrin-negative bands in material double-stained for zebrin II and for different anterograde tracers injected in subnuclei of the inferior olive, or retrograde tracers injected in the cerebellar and vestibular target nuclei of the Purkinje cells of the vermis. Projection zones A1,AX,X,B,CX in the vermis and A2 (accessory A zone) and C2 in the hemisphere were defined by their efferent corticonuclear and their afferent climbing fiber connections, and were found to share the same topographical framework with the zebrin pattern. Introduction There are words that stick in your mind. Among our 1994), the low affinity nerve growth factor receptor favorites are Sanford L. Palay’s statement on synaptic protein (Dusart et al., 1994), protein kinase C delta vesicles, which “like chocolates, come in a variety of (Chen & Hillman, 1993) the glutamate transporter shapes and sizes, and are stuffed with different kind EAAT4 (Dehnes et al., 1998) and the metabotropic of fillings’’ (1967) and his remark on the “chemical id- glutamate receptor mGluR1b (Mateos et al., 2001), to iosyncrasy’’ of non-synaptic monoaminergic cerebellar name only a few. -

Zonal Organization of the Climbing Fiber Projection to the Flocculus And
THE JOURNAL OF COMPARATIVE NEUROLOGY ,7562340 (1995) Zonal Organization of the Climbing Fiber Projection to the Flocculus and Nodulus of the Rabbit: A Combined Axonal Tracing and Acetylcholinesterase Histochemical Study J. TAN, N.M. GERRITS, R. NANHOE, J.I. SIMPSON, AND J. VOOGD Department of Anatomy, Erasmus University Rotterdam, 3000 DR Rotterdam, The Netherlands; (J.T., N.M.G., J.V.), General Hospital Middelheim, Department of Neurology, Middelheim, Belgium (R.N.),and Department of Physiology and Biophysics, New York University Medical Center, New York, New York 10016 (J.I.S.) ABSTRACT The localization and termination of olivocerebellar fibers in the flocculus and nodulus of the rabbit were studied with anterograde axonal transport methods [wheatgerm agglutinin- horseradish peroxidase (WGA-HRP) and tritiated leucinel and correlated with the compart- ments in the white matter of these lobules delineated with acetylcholinesterase histochemistry (Tan et al. J. Comp. Neurol., 1995, this issue). Olivocerebellar fibers originating from the caudal dorsal cap travel through floccular compartments FC2 and FC4 to terminate as climbing fibers in floccular zones FZII and FZIv. Fibers from the rostral dorsal cap and the ventrolateral outgrowth traverse compartments FC1 and FC3,which are interleaved with compartments FC2 and FC4! and terminate in zones FZ1 and FZiIi. Fibers from the rostral pole of the medial accessory olive traverse the Cz compartment and terminate in the Cz zone. FZ1-111 extend into the adjoining folium (folium p) of the ventral paraflocculus. The C2 zone continues across folium p into other folia of the ventral paraflocculus and into the dorsal paraflocculus. Four compartments and five zones were distinguished in the nodulus. -

The Distribution of Climbing and Mossy
The Journal of Neuroscience, June 1, 2003 • 23(11):4645–4656 • 4645 The Distribution of Climbing and Mossy Fiber Collateral Branches from the Copula Pyramidis and the Paramedian Lobule: Congruence of Climbing Fiber Cortical Zones and the Pattern of Zebrin Banding within the Rat Cerebellum Jan Voogd,2 Joanne Pardoe,1 Tom J. H. Ruigrok,2 and Richard Apps1 1Department of Physiology, University of Bristol, BS8 1TD Bristol, United Kingdom, and 2Department of Neuroscience, Erasmus MC, 3000 DR Rotterdam, The Netherlands Individual cerebellar cortical zones defined by the somatotopy of climbing fiber responses and by their olivo-cortico-nuclear connections located in the paramedian lobule and the copula pyramidis of the rat cerebellum were microinjected with cholera toxin B subunit. Collateral branches of climbing and mossy fibers were mapped and related to the pattern of zebrin-positive and -negative bands of Purkinje cells. Climbing fiber collaterals from the copula distribute to the anterior lobe: from the paramedian lobule mainly to lobulus simplex and rostral crus I. Climbing fibers terminating in particular zones (X, A2 ,C1 ,CX ,C2 ,C3 ,D1 , and D2 ) in the paramedian lobule or the copula collateralize to one or two corresponding zones in lobulus simplex, crus I and II, the paraflocculus, and/or the anterior lobe. These zones can be defined by their relationship to the pattern of zebrin banding. Collaterals from mossy fibers, labeled from the same injection sites in the copula and paramedian lobule, often distribute bilaterally in a symmetrical pattern of multiple but ill-defined longitudinalstripsintheanteriorlobeand/orlobulussimplex.Oneormoreoftheselongitudinalaggregatesofmossyfibercollateralswas always found subjacent to the strip(s) of labeled climbing fiber collaterals arising from the same locus in the paramedian lobule or the copula. -

Neocortex-Cerebellum Circuits for Cognitive Processing
Trends in Neurosciences Review Neocortex–Cerebellum Circuits for Cognitive Processing Mark J. Wagner1,* and Liqun Luo1,* Although classically thought of as a motor circuit, the cerebellum is now understood to Highlights contribute to a wide variety of cognitive functions through its dense interconnections with the Classic studies have mainly focused neocortex, the center of brain cognition. Recent investigations have shed light on the nature on sensorimotor information trans- of cerebellar cognitive processing and information exchange with the neocortex. We review mitted through the two cerebellar findings that demonstrate widespread reward-related cognitive input to the cerebellum, as input pathways, granule cells and well as new studies that have characterized the codependence of processing in the neocortex climbing fibers. Recent in- and cerebellum. Together, these data support a view of the neocortex–cerebellum circuit as a vestigations indicate that the cere- joint dynamic system both in classical sensorimotor contexts and reward-related, cognitive pro- bellum receives diverse reward expectation-related information via cessing. These studies have also expanded classical theory on the computations performed by granule cells, and reward predic- the cerebellar circuit. tion error signals via climbing fi- bers. The cerebellum may in turn Cerebellum and Cognitive Function reciprocally influence brain-wide The cerebellum was traditionally thought to contribute mainly to motor coordination [1–4]. However, reward circuitry via output path- more -

Origin of Climbing Fiber Neurons and Their Developmental Dependence Onptf1a
10924 • The Journal of Neuroscience, October 10, 2007 • 27(41):10924–10934 Development/Plasticity/Repair Origin of Climbing Fiber Neurons and Their Developmental Dependence on Ptf1a Mayumi Yamada,1 Mami Terao,1 Toshio Terashima,2 Tomoyuki Fujiyama,1 Yoshiya Kawaguchi,3 Yo-ichi Nabeshima,1 and Mikio Hoshino1,4 1Department of Pathology and Tumor Biology, Kyoto University Graduate School of Medicine, Sakyo-ku, Kyoto 606-8501, Japan, 2Division of Anatomy and Neurobiology, Department of Neuroscience, Kobe University Graduate School of Medicine, Kobe 650-0017, Japan, 3Department of Surgery and Surgical Basic Science, Kyoto University Graduate School of Medicine, Sakyo-ku, Kyoto 606-8507, Japan, and 4Department of Biochemistry and Cellular Biology, National Institute of Neuroscience, National Center of Neurology and Psychiatry, Kodaira, Tokyo 187-8502, Japan Climbing fiber (CF) neurons in the inferior olivary nucleus (ION) extend their axons to Purkinje cells, playing a crucial role in regulating cerebellarfunction.However,littleisknownabouttheirpreciseplaceofbirthanddevelopmentalmolecularmachinery.Here,wedescribe the origin of the CF neuron lineage and the involvement of Ptf1a ( pancreatic transcription factor 1a) in CF neuron development. Ptf1a protein was found to be expressed in a discrete dorsolateral region of the embryonic caudal hindbrain neuroepithelium. Because expres- sion of Ptf1a is not overlapping other transcription factors such as Math1 (mouse atonal homolog 1) and Neurogenin1, which are suggested to define domains within caudal hindbrain neuroepithelium (Landsberg et al., 2005), we named the neuroepithelial region the Ptf1a domain. Analysis of mice that express -galactosidase from the Ptf1a locus revealed that CF neurons are derived from the Ptf1a domain. In contrast, retrograde labeling of precerebellar neurons indicated that mossy fiber neurons are not derived from Ptf1a- expressing progenitors.