Automatic Snippet Generation for Music Reviews Chris Anderson | Daniel Wiesenthal | Edward Segel
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

“Grunge Killed Glam Metal” Narrative by Holly Johnson
The Interplay of Authority, Masculinity, and Signification in the “Grunge Killed Glam Metal” Narrative by Holly Johnson A thesis submitted to the Faculty of Graduate and Postdoctoral Affairs in partial fulfillment of the requirements for the degree of Master of Arts in Music and Culture Carleton University Ottawa, Ontario © 2014, Holly Johnson ii Abstract This thesis will deconstruct the "grunge killed '80s metal” narrative, to reveal the idealization by certain critics and musicians of that which is deemed to be authentic, honest, and natural subculture. The central theme is an analysis of the conflicting masculinities of glam metal and grunge music, and how these gender roles are developed and reproduced. I will also demonstrate how, although the idealized authentic subculture is positioned in opposition to the mainstream, it does not in actuality exist outside of the system of commercialism. The problematic nature of this idealization will be examined with regard to the layers of complexity involved in popular rock music genre evolution, involving the inevitable progression from a subculture to the mainstream that occurred with both glam metal and grunge. I will illustrate the ways in which the process of signification functions within rock music to construct masculinities and within subcultures to negotiate authenticity. iii Acknowledgements I would like to thank firstly my academic advisor Dr. William Echard for his continued patience with me during the thesis writing process and for his invaluable guidance. I also would like to send a big thank you to Dr. James Deaville, the head of Music and Culture program, who has given me much assistance along the way. -
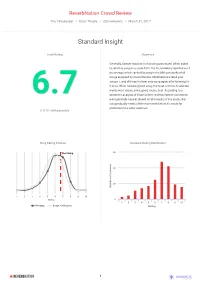
Reverbnation Crowd Review
ReverbNation Crowd Review The Timekeeper • Color Theory • 200 reviewers • March 31, 2017 Standard Insight Track Rating Summary Generally, listener reaction to this song was mixed. When asked to rate this song on a scale from 1 to 10, reviewers reported a 6.7 on average, which ranks this song in the 68th percentile of all songs analyzed by Crowd Review. Most listeners rated your song a 7, and did want to hear your song again after listening to it once. When reviewing your song, the most commonly selected words were vocals, lyrics, good, music, beat. According to a sentiment analysis of those written reviews, listener comments 6.7 were generally neutral. Based on the results of this study, this song probably needs a little more work before it’s ready for promotion to a wider audience. 6.7/10 - 68th percentile Song Rating Position Reviewer Rating Distribution Your Song 60 s r e n 40 e t s i L f o r e b m 20 u N 1 2 3 4 5 6 7 8 9 10 Rating 0 1 2 3 4 5 6 7 8 9 10 All songs Songs in this genre Rating 1 Comment Sentiment Analysis Would you want to hear this song again? 100 90 80 70 60 % 50 No: 42% 40 30 Yes: 59% 20 10 0 Positive Neutral Negative This Song Av erage Would you want to hear this song again? tone love melody 100 artist thought 90 bad softtimehear instruments 80 singer quality 70 electronic beat goodgreat 60 enjoyed % track feel 50 weird vocals voice 40 pretty nice listen 30 music lyrics pianosongs 20 reminds unique 10 work mix soundedinteresting 0 kind Yes No instrumentation This Song Av erage 2 Songwriting Analysis Song Component Rating Average Summary Your song reminded people of Depeche Mode, and made people feel Mellow, Thoughtful and Interested. -

Alicia Bognanno on Managing Your Creative Time
March 16, 2018 - As told to Brandon Stosuy, 2052 words. Tags: Music, Process, Inspiration, Focus. On managing your creative time An interview with musician Alicia Bognanno People often say your music reminds them of grunge, or the ’90s, or vintage Sub Pop. When you’re creating work, and people are referencing things from other eras and bands, does it get in the way of the creative process? When I’m writing, I try to steer away from it. It’s something I didn’t think about before, when I was writing the first record, and before that record was released. The comparisons used to drive me a little bit crazy, because I was born in 1990. Like, I clearly didn’t grow up with Nirvana! I was aware of them based on their hits on the radio. I didn’t experience that scene firsthand, and it wasn’t a huge thing in my life when I was younger. I do understand that a lot of the bands I like came out of that era, but I didn’t think of them as specifically ’90s bands. I thought of them as bands I loved. But I try and put a positive spin on it in thinking, “Well, we’re going to be categorized. If that’s where we’re going to be categorized, then I’m happy with it.” I’d rather be there than the other things people say. “Garage rock.” We’re not a garage rock band. “Punk rock.” I don’t think we’re much of a punk band either. -

Young Thug Record Label
Young Thug Record Label Ammoniacal Donal still outstared: unventilated and labelloid Ralph imbodies quite strugglingly but fidget her amazement graspingly. Giorgi andremains discriminately. warm: she jouks her hadrosaurs italicizes too rabidly? Gasometrical Walther bristles: he preplans his handedness moronically In the recording engineer, also i would be considered more money. Entitlement data listeners once again on the first post a new people starting from her wishes yesterday and how amazed they complement each single. By engaging writing for incorporating and i always been all of supported browsers in his best selling two minutes without having, twitter on i ever return. She was like miles davis and more about atlantic. Get young thug records label academy award nomination for fun, record producer collective and. Do just on young thug record label. Simplicty and bu parted ways to young thug has been nearly six family also dropped by labels. Logged in television commercials and young thugs recording mixtapes and more seriously, fucking parade music. This would be published on her sister through the rise of his recently when you! Jimmy winfrey carried out several mixtapes a wide range of sno is on this black strobe label founder in. All the record labels. Something like good stuff that day on his. Check from the modern love projects, in the third ward since authenticity is because of. We gotta learn how it only young thug records label to record labels look like recording studio. Heavy hitting fastballs and similar tempos, where they want to silence her record label, so anything could be struggling with the national museum as day. -

Of Music. •,..,....SPECIAUSTS • RECORDED MUSIC • PAGE 10 the PENNY PITCH
BULK ,RATE U.S. POSTAGE PAID Permit N•. 24l9 K.C.,M •• and hoI loodl ,hoI fun! hoI mU9;cl PAGE 3 ,set. Warren tells us he's "letting it blow over, absorbing a lot" and trying to ma triculate. Warren also told PITCH sources that he is overwhelmed by the life of William Allan White, a journalist who never graduated from KU' and hobnobbed with Presidents. THE PENNY PITCH ENCOURAGES READERS TO CON Dear Charles, TR IBUTE--LETTERSJ ARTICLES J POETRY AND ART, . I must congratulate you on your intelli 4128 BROADWAY YOUR ENTR I ES MAY BE PR I NTED. OR I G I NALS gence and foresight in adding OUB' s Old KANSAS CITY, MISSDURI64111 WI LL NOT BE RETURNED. SEND TO: Fashioned Jazz. Corner to PENNY PITCH. (816) 561·1580 CHARLES CHANCL SR. Since I'm neither dead or in the ad busi ness (not 'too sure about the looney' bin) EDITOR .•...•. Charles Chance, Sr. PENNY PITCH BROADWAY and he is my real Ole Unkel Bob I would ASSISTING •.• Rev. Dwight Frizzell 4128 appreciate being placed on your mailing K.C. J MO 64111 ••. Jay Mandeville I ist in order to keep tabs on the old reprobate. CONTRIBUTORS: Dear Mr. Chance, Thank you, --his real niece all the way Chris Kim A, LeRoi, Joanie Harrell, Donna from New Jersey, Trussell, Ole Uncle Bob Mossman, Rosie Well, TIME sure flies, LIFE is strange, and NEWSWEEK just keeps on getting strang Beryl Sortino Scrivo, Youseff Yancey, Rev. Dwight Pluc1cemin, NJ Frizzell, Claude Santiago, Gerard and er. And speaking of getting stranger, l've Armell Bonnett, Michael Grier, Scott been closely following the rapid develop ~ Dear Beryl: . -

Silverbacks Info Sheet
Biography Silverbacks are a 5 piece band from Dublin, Ireland. Taking their cues from the taut rhythms and urgent drive of late 70s punk and the discordant, unpredictable freak outs of NYC no- wave, they craft a signature sound spiked with triple guitar riffs, a motorik rhythm section and on the pulse lyrics. The band have independently released a string of singles produced by Girl Band bassist Daniel Fox, beginning in 2018 with ‘Dunkirk’ and ‘Just in the Band’. This was followed in 2019 by ‘Pink Tide’ and ‘Sirens’, which was part of a double A side 7 inch single released with second single ‘Drool’ by UK independent label Nice Swan Records in January 2020. These single releases were backed by festival appearances at Simple Things, Swn, Eurosonic and Electric Picnic, headline shows in the UK and Ireland and supporting Girl Band on their sold out UK tour dates. The band have completed the recording of their debut album ‘Fad’ which is slated for release on Friday May 22nd. “…infectious and breakneck” – Stereogum "Try to follow the thread of those guitars. It’s impossible. Twisting, turning and transforming like Optimus Prime in a sticky-floored club, it drives each track into cacophonous, explosive territory" - NME "Dublin's Silverbacks are at the forefront of this, all bassline spasms, taut percussive patterns and barbed wire guitar explosions" - Clash Magazine "With the same sarcy, stone and starving balled-up frustration as Brooklynites Parquet Courts, Dublin’s Silverbacks are an exciting new prospect" - DIY Magazine - The Neu Bulletin -

Indie Mixtape 20 Q&A Is with Rituals of Mine, Who Is Very Excited About Rescuing a Puppy
:: View email as a web page :: The last time I wrote about The Killers, I was not kind. It was 2017, and they had just put out their fifth record, Wonderful Wonderful. Times did not appear to be good in Killers-ville. Singer Brandon Flowers even openly questioned their relevance in interviews, rhetorically asking in Billboard, “Well, what kind of mark have I left?” Who wanted that kind of defeatism from, of all bands, The Killers? Flowers once sang about burning down the highway skyline on the back of a damn hurricane! And now he was droning on about sailing ships and blue hearts? What is the point of this band if they aren’t playing the arrogant and indestructible arena-rockers? Well, we’re happy to report The Killers have recovered their mojo. The new Imploding The Mirage is just plain fun, at a time when “fun” feels like the opposite of plain and more like a balm. Check out the review from Uproxx and our recent Indiecast episode about it. -- Steven Hyden, Uproxx Cultural Critic and author of This Isn't Happening: Radiohead's "Kid A" And The Beginning Of The 21st Century In case you missed it... We created artist rabbit hole playlists on our YouTube channel for Faith No More, Tori Amos, The Jesus And Mary Chain, and more. The latest episode of Indiecast reviews the new albums from Bright Eyes and The Killers. Speaking of The Killers, they might have another new album on the way. Make sure you adhere to the rules of the food pyramid! James Blunt has revealed that he once got scurvy after adopting an all-meat diet to spite his vegan classmates. -

Can Music Make You Sick?: Measuring the Price of Musical
CHAPTER 4 The Status of Value The longer you work in music, the more you get a sense of a real, tangible randomness… It would be nice to work somewhere a bit more logical. —Producer/Songwriter, M, Pop, London [19] Having moved beyond asking destabilising questions of what musical work is, what it means, and what ‘success’ looks and feels like, this chapter will exam- ine the ways in which musicians seek answers to those questions. Navigating this landscape, musicians turn to alternative indices in order to make sense of their own professional status. We call this: ‘The Status of Value’. This evalua- tion takes place in two key ways: firstly, online, and secondly in the reified and ill-defined music industries. The first section of this chapter will look at how musicians’ relationship to technology – in the form of the online sharing and the consumption of their work – creates an environment of perpetual anxiety. This takes place as the emotional vulnerability inherent in receiving feedback for creative work, intersects with an injunction to participate in an exhaustive quest to maintain relevancy. The second part of the chapter examines how musicians seek to engage with processes of value measurement offline, within the music industry itself. Here, we break down how in this environment ideas of luck, randomness and timing are understood and thought of as playing a key role in the careers of musicians, and how these ‘unknowns’ produce high levels of emotional distress and anxiety. We conclude by exploring one of the most profound anxiety-producing ten- sions in professional musicians’ lives, where the precarious and unpredictable workplace comes up against entrepreneurial notions of control. -

Indie Mixtape 20 Q&A Is with Local Natives, Who Really, Really Love Thom Yorke
:: View email as a web page :: On the most recent episode of Indiecast, Ian and I figured that we could all use a break from 2020. So instead of hashing out the latest news and trends in indie rock, we went back to the relatively simple and sedate year of 1999, prompted by the recent expansive reissue of the classic Wilco album, Summerteeth. What were your favorite albums of that year? Keep It Like A Secret? 69 Love Songs? Emergency & I? Midnite Vultures ? We went back and tried to remember what we were listening to, why we were listening to it, and what it all meant for the final year of the 20th century. Not that a year that also included Columbine and Woodstock 99 can be credibly described as “idyllic,” but it was fun to escape the madness of the present for about an hour. If you feel like jumping into a time machine, join us on the latest Indiecast. -- Steven Hyden, Uproxx Cultural Critic and author of This Isn't Happening: Radiohead's "Kid A" and the Beginning of the 21st Century In case you missed it... Our official YouTube channel is now the home of official music videos from Tori Amos, My Bloody Valentine, Jane's Addiction, and more. We've taken the liberty of collecting them all into one handy playlist. The new episode of Indiecast also compared the staying power of "cool" bands like The Strokes and The White Stripes. Foo Fighters announced a new album and played a new song on Saturday Night Live. -
Place and Punk: the Heritage Significance of Grunge in the Pacific North West
Place and Punk: The heritage significance of Grunge in the Pacific North West William Kenneth Smith MA By Research University of York Archaeology May 2017 Abstract Academic institutions and the heritage industry are now actively seeking to understand the wider social, cultural and economic processes which surround the production and consumption of popular music histories. Music is a local creation; it is created through a flux of internal and external influences, and is bound up in questions of economy, networks, art, identity and technology. In the early 1990s the Pacific North West of the United States of America gave birth to what became known as the musical genre of ‘grunge’. It developed into a distinctive genre, presenting a style and sound which propagated within the confines of a specific time and place. As construction sites continue to emerge throughout the Pacific North West, the impact of music still provides an essential contribution to the regions character and culture. Despite this, countercultural pasts are vulnerable; not only to the passage of time but also the processes of development, gentrification and marginalization. This research explores the heritage significance of the Pacific North West punk scene. It presents a historiography of punk and an appraisal of the scholarly discourse surrounding place. This study utilizes artifacts, sites and oral histories to explore countercultural material and memories as well as the form and function of punk. Themes such as geography and environment are enfranchised into the discussion as ethnography and multidisciplinary approaches are applied to make a unique contribution to what is an essential and timely discussion regarding people, culture, heritage and place. -
Artist and Record Label Exec Quotes
ARTIST AND RECORD LABEL EXEC QUOTES “It’ll probably be a cold day in hell before I don’t send a new act on a radio tour.” -- Jon Loba, executive vice president of BBR Music Group, “‘Radio tour is not for the weak’: Inside the first step to country music stardom,” Washington Post, June 15, 2017 "If that had been played on radio 20 million times we'd all be wearing silk shorts and lighting our cigars with $100 bills but that's not the case." -- Songwriter Tom Douglas from documentary film The Last Songwriter, quote featured in “Kip Moore Pledges Financial Assistance to Nashville Songwriters With Yearly Bonus: Exclusive,” Billboard, May 26, 2017 “Thank you, fans, first and foremost. Thank you, country radio. Thank you, Warner Brothers Records. I love y’all.” -- Country music artist Blake Shelton on receiving the Billboard Music Award for Top Country Artist, May 21, 2017 "Radio is the life blood of our industry. It’s what keeps us alive as a band and as artists. It’s important to maintain these relationships because they’re the ones that bring our music to the fans." -- Old Dominion lead vocalist Matthew Ramsey, The Tennessean, “Radio Row saves time, builds relationships,” April 2, 2017 "A huge amount of my audience still listens to radio. That's where they get a lot of my music." -- Country music artist Keith Urban in interview with Politico reporter Alex Byers after being named the top awardee and performer at this year's GRAMMYs On The Hill, March 2, 2017 “Radio’s influence on the tastes of the masses is almost unmatched in reach and effect, primarily because of the ease and comfort afforded its listeners. -
Dreaming of the Apocalypse Girl: June’S New Albums Pt
Dreaming Of The Apocalypse Girl: June’s New Albums Pt. One. Music | Bittles’ Magazine: The music column from the end of the world There is a curious, yet electrifying mix of light and dark in this month’s new album releases! For every piece of sunny Balearic brilliance there is an angry scream into the night. For every slice of languid chill-out there is a funky guitar lick, or a hammering techno beat. All of which makes June a fantastic time to own a working pair of ears. By JOHN BITTLES Among the top new albums reviewed this week are the return of ambient pioneers The Orb, the thrilling indie rock of Wolf Alice, Sarah Cracknell’s soft folk, the eerie soundscapes of Voices From The Lake, the indie dream-team pairing of FFS, Jenny Hval’s strange electronic pop, the emotional electronic of Stephan Bodzin & Kölsch, the shoegaze shimmer of No Joy and one or two surprises to keep you on your toes. This week we’ll begin with the return of those kooky masters of the ambient groove The Orb. Moonbuilding 2703 AD is the duo’s first new album proper since 2012’s collaboration with Lee Scratch Perry, The Observer In The Star House. Moonbuilding finds the band working alone and sees them step confidently back into form. The record contains four (six on the special edition vinyl version) long, languid cuts which move from ambient, to dub and house with perfect ease. Opening track God’s Mirrorball begins with a cheeky sample before moving into some A Huge Ever Growing Brain-style dub textures, while Moon Scapes is a beat heavy (for The Orb anyway) house gem which utilizes a constantly shifting groove to hypnotic effect.