ICER Evidence Rating Matrix: a User's Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Real-World Data for Health Technology
International Journal of Real-world data for health technology Technology Assessment in Health Care assessment for reimbursement decisions in Asia: current landscape and a way forward cambridge.org/thc Jing Lou1,* , Sarin KC2,*, Kai Yee Toh1, Saudamini Dabak2 , Amanda Adler3, Jeonghoon Ahn4 , Diana Beatriz S. Bayani1,5, Kelvin Chan6,7,8, Commentary Dechen Choiphel9, Brandon Chua10, Anne Julienne Genuino5, 5 11 1 12 *Joint first authors – contributed equally to Anna Melissa Guerrero , Brendon Kearney , Lydia Wenxin Lin , Yuehua Liu , the preparation of the first draft. Ryota Nakamura13, Fiona Pearce14, Shankar Prinja15 , Raoh-Fang Pwu16, Asrul †Joint senior authors – contributed equally to Akmal Shafie17, Binyan Sui12, Auliya Suwantika18, Yot Teerawattananon1,2,†, conceptualizing and designing the study, project management, supervising data Sean Tunis19, Hui-Min Wu16, John Zalcberg20,21, Kun Zhao12, collection and data analysis, critically revised 2,22,23, 1,24, the first draft and approved the final version. Wanrudee Isaranuwatchai † and Hwee-Lin Wee † Cite this article: Lou J et al (2020). Real-world 1Saw Swee Hock School of Public Health, National University of Singapore (NUS), Singapore, Singapore; 2Health data for health technology assessment for Intervention and Technology Assessment Program (HITAP), Ministry of Health, Mueang Nonthaburi, Thailand; reimbursement decisions in Asia: current 3National Institute for Health and Care Excellence (NICE), London, UK; 4Ewha Womans University, Seoul, South landscape and a way forward. International Korea; 5Health Technology Assessment Unit, Department of Health, Manila, Philippines; 6Sunnybrook Odette Journal of Technology Assessment in Health 7 8 – Cancer Centre, Toronto, Canada; Sunnybrook Research Institute, Toronto, Canada; Canadian Centre for Applied Care 36, 474 480. -

Efficacy and Effectiveness Models
Efficacy and Effectiveness models Graziano Onder Centro Medicina dell’Invecchiamento Università Cattolica del Sacro Cuore Rome - Italy EMA Workshop: Ensuring safe and effective medicines for an ageing population Definition Efficacy is the capacity to produce an effect. In medicine, it is the ability of an intervention or drug to produce a desired effect in expert hands and under ideal circumstances . Effectiveness is the capability of producing a desired result. In medicine, effectiveness relates to how well a treatment works in practice , as opposed to efficacy, which measures how well it works in RCT or laboratory studies. Ideal or real patient? Comorbidity Researchers have Multiple drugs largely shied away Physical function from the complexity Cognitive status Physical function of multiple chronic Affective status conditions Social status — avoidance that Incontinence results in expensive, COMPLEXITY COMPLEXITY Malnutrition potentially harmful care of unclear Falls benefit. Osteoporosis Tinetti M. NEJM2011 Efficacy and Effectiveness research Effectiveness research addresses practical questions about an intervention as it would occur in routine clinical practice, preserving the ‘ecology’ of care: hypothesis and study design are formulated based on information needed to make a decision. Efficacy research is aimed to better understand how and why an intervention works. Tunis SR. JAMA 2003 Efficacy and Effectiveness research 3 key features differentiates effectiveness (pragmatic or practical trials ) and efficacy research ( explanatory -

LITERATURE SEARCHING Veterinary Medicine Year 1
LITERATURE SEARCHING Veterinary Medicine Year 1 1 Wednesday, 11 November 2020 Literature Searching Presenter: Niala Dwarika-Bhagat Email: [email protected] 21/10/2020 2 Wednesday, 11 November 2020 Objectives To identify the 5 steps of Evidence-Based Veterinary Medicine (EBVM) To locate and determine resources for medical and health literature searching. Focus: o Database Searching – PubMed (free database) o Database Searching Ebscohost Medline (UWI Subscribed Databases) o Searching UWILinC o Locating e-Journals by subject To conduct effective hands-on online research To identify the FMS Vancouver referencing resources What is evidence-based medicine? "Evidence-based medicine (EBM) requires the integration of the best research with our clinical expertise and our patient's unique values and circumstances.“ From: Straus, Sharon E. (2005). Evidence-based medicine: How to practice and teach EBM, p. 1.[Source: https://veterinary-practice.com/article/embracing-evidence-based-medicine ] The practice of evidence-based medicine is a process of self-directed problem-based learning in which clinically relevant information about diagnosis, prognosis, and therapy is considered according to the best data available through research. [Source: https://www.medindia.net/patientinfo/evidence-based-medicine.htm#1 ] One commonly used definition of evidence-based medicine (EBM) is: “… the conscientious, explicit and judicious use of current best evidence in making decisions about the care of individual patients. The practice of EBM means integrating individual clinical expertise with the best available external clinical evidence from systematic research.” (Sackett et al., 2000) 4 Wednesday, 11 November 2020 What is EBVM? The practise of Evidence-Based Veterinary Medicine (EBVM) is the use of best available scientific evidence, in conjunction with clinical expertise and consideration of owner and patient factors, to make the best clinical decisions for patients. -
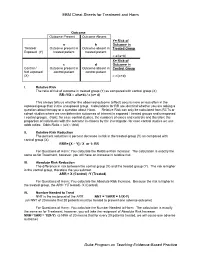
EBM Cheat Sheets for Treatment and Harm Duke Program on Teaching
EBM Cheat Sheets for Treatment and Harm Outcome Outcome Present Outcome Absent Y= Risk of a b Outcome in Treated/ Outcome present in Outcome absent in Treated Group Exposed (Y) treated patient treated patient = a/(a+b) X= Risk of c d Outcome in Control / Outcome present in Outcome absent in Control Group Not exposed control patient control patient (X) = c/(c+d) I. Relative Risk The ratio of risk of outcome in treated group (Y) as compared with control group (X) RR=Y/X = a/(a+b) / c (c+ d) This always tells us whether the observed outcome (effect) occurs more or less often in the exposed group than in the unexposed group. Calculations for RR are identical whether you are asking a question about therapy or a question about Harm. Relative Risk can only be calculated from RCTs or cohort studies where we can determine outcomes of interest in exposed / treated groups and unexposed / control groups. (Note: for case control studies, the numbers of cases and controls and therefore the proportion of individuals with the outcome is chosen by the investigator- for case control studies we use odds ratios: Odds Ratio = (a/c) / (b/d) II. Relative Risk Reduction The percent reduction is percent decrease in risk in the treated group (Y) as compared with control group (X) RRR= [X – Y] / X or 1- RR For Questions of Harm: You calculate the Relative Risk Increase: The calculation is exactly the same as for Treatment, however, you will have an increase in relative risk. III. Absolute Risk Reduction The difference in risk between the control group (X) and the treated group (Y). -

A National Strategy to Develop Pragmatic Clinical Trials Infrastructure
A National Strategy to Develop Pragmatic Clinical Trials Infrastructure Thomas W. Concannon, Ph.D.1,2, Jeanne-Marie Guise, M.D., M.P.H.3, Rowena J. Dolor, M.D., M.H.S.4, Paul Meissner, M.S.P.H.5, Sean Tunis, M.D., M.P.H.6, Jerry A. Krishnan, M.D., Ph.D.7,8, Wilson D. Pace, M.D.9, Joel Saltz, M.D., Ph.D.10, William R. Hersh, M.D.3, Lloyd Michener, M.D.4, and Timothy S. Carey, M.D., M.P.H.11 Abstract An important challenge in comparative effectiveness research is the lack of infrastructure to support pragmatic clinical trials, which com- pare interventions in usual practice settings and subjects. These trials present challenges that differ from those of classical efficacy trials, which are conducted under ideal circumstances, in patients selected for their suitability, and with highly controlled protocols. In 2012, we launched a 1-year learning network to identify high-priority pragmatic clinical trials and to deploy research infrastructure through the NIH Clinical and Translational Science Awards Consortium that could be used to launch and sustain them. The network and infrastructure were initiated as a learning ground and shared resource for investigators and communities interested in developing pragmatic clinical trials. We followed a three-stage process of developing the network, prioritizing proposed trials, and implementing learning exercises that culminated in a 1-day network meeting at the end of the year. The year-long project resulted in five recommendations related to developing the network, enhancing community engagement, addressing regulatory challenges, advancing information technology, and developing research methods. -

Patient Engagement in Health Research: a How-To Guide for Researchers
Patient Engagement in Health Research: A How-to Guide for Researchers May 2018 (Version 8.0) Acknowledgement Thank you to all of the individuals and organizations who provided feedback on the iterations of this guide for researchers. • AbSPORU—Patient Engagement Platform Advisory Council (PEPAC) members • Alberta Health Services—Patient Engagement Reference Group • Alberta Health Services—Provincial Patient and Family Advisory Council • Alberta Health Services--Strategic Clinical Networks (Assistant Scientific Directors) • CIHR National Patient Engagement Working Group • IMAGINE Citizens • Individuals who took the Pragmatic Clinical Trials (PCT) course in September 2017, or participated in the PCT webinar in the Fall of 2017 Contents Overview 1 Why should I engage patients in health research? 1 How is patient engagement defined? 2 What does patient engagement in health research look like? 3 How does the “patient and researcher engagement in health research” 4 strategy differ from other participatory research approaches? How do I know I’m ready to engage patients in health research? 6 How do I use this Guide? 8 Step 1: Why 10 Why engage patients in health research? 10 What knowledge or perspectives do you seek from patients at the individual 11 level? Is research ethics approval required to engage patients in health research? 12 Step 2: Who 14 Who should I consider engaging in my research? 14 How many patients do I need to engage? 15 How do I decide how patients should be involved? 16 How do I find people to engage in my research? 19 Step -

NUMBER NEEDED to TREAT (CONTINUATION) Confidence
Number Needed to treat Confidence Interval for NNT • As with other estimates, it is important that the uncertainty in the estimated number needed to treat is accompanied by a confidence interval. • A common method is that proposed by Cook and Sacket (1995) and based on calculating first the confidence interval NUMBER NEEDED TO TREAT for the difference between the two proportions. • The result of this calculation is 'inverted' (ie: 1/CI) to give a (CONTINUATION) confidence interval for the NNT. Hamisu Salihu, MD, PhD Confidence Interval for NNT Confidence Interval for NNT • This computation assumes that ARR estimates from a sample of similar trials are normally distributed, so we can use the 95th percentile point from the standard normal distribution, z0.95 = 1.96, to identify the upper and lower boundaries of the 95% CI. Solution Class Exercise • In a parallel clinical trial to test the benefit of additional anti‐ hyperlipidemic agent to standard protocol, patients with acute Myocardial Infarction (MI) were randomly assigned to the standard therapy or the new treatment that contains standard therapy and simvastatin (an HMG‐CoA reductase inhibitor). At the end of the study, of the 2223 patients in the control group 622 died as compared to 431 of 2221 patients in the Simvastatin group. – Calculate the NNT and the 95% CI for Simvastatin – Is Simvastatin beneficial as additional therapy in acute cases of MI? 1 Confidence Interval Number Needed to for NNT Treat • The NNT to prevent one additional death is 12 (95% • A negative NNT indicates that the treatment has a CI, 9‐16). -

A Number-Needed-To-Treat Analysis of the EMAX Trial
Efficacy of Umeclidinium/Vilanterol Versus Umeclidinium or Salmeterol: A Number-Needed-to-Treat Analysis of the EMAX Trial Poster No. 1091 (A3326) 1 2 3 1 2 3 4 5 Respiratory Medicine and Allergology, Lund University, Lund, Sweden; Centre de Pneumologie, Institut Universitaire de Cardiologie et de Pneumologie de Québec, Université Laval, QC, Canada; Department of Medicine, Pulmonary and Critical Care Medicine, University Medical Center Giessen and Marburg, Bjermer L , Maltais F , Vogelmeier CF , Naya I , Jones PW , 4 5 6 6 5 5 7 8 9 Philipps-Universität Marburg, Germany, Member of the German Center for Lung Research (DZL); Global Specialty & Primary Care, GSK, Brentford, Middlesex, UK (at the time of the study) and RAMAX Ltd., Bramhall, Cheshire, UK; GSK, Brentford, Middlesex, UK; Precise Approach Ltd, contingent worker on assignment at Tombs L , Boucot I , Compton C , Lipson DA , Keeley T , Kerwin E GSK, Stockley Park West, Uxbridge, Middlesex, UK; 7Respiratory Clinical Sciences, GSK, Collegeville, PA, USA and Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA, USA; 8GSK, Stockley Park West, Uxbridge, Middlesex, UK; 9Clinical Research Institute of Southern Oregon, Medford, OR, USA Background Results ● The relative treatment benefits with long-acting muscarinic antagonist/long-acting Patients β -agonist (LAMA/LABA) combination therapy versus LAMA or LABA monotherapy have not been Table 1. Patient demographics and clinical characteristics Figure 2. Hazard ratio for a first moderate/severe exacerbation or CID at Week 24 2 ● Demographics and baseline characteristics are shown in Table 1. demonstrated in symptomatic, inhaled corticosteroid (ICS)-free patients with COPD who have a low UMEC/VI vs UMEC UMEC/VI vs SAL UMEC/VI UMEC SAL risk of exacerbations. -

Routine Circumcision of Newborn Infants Re
A Trade-off Analysis of Routine Newborn Circumcision Dimitri A. Christakis, MD, MPH*‡; Eric Harvey, PharmD, MBA‡; Danielle M. Zerr, MD, MPH*; Chris Feudtner, MD, PhD*§; Jeffrey A. Wright, MD*; and Frederick A. Connell, MD, MPH‡i Abstract. Background. The risks associated with outine circumcision of newborn infants re- newborn circumcision have not been as extensively mains controversial.1–3 Although a recent evaluated as the benefits. Rpolicy statement by the American Academy Objectives. The goals of this study were threefold: 1) of Pediatrics recommended that parents be given to derive a population-based complication rate for new- accurate and unbiased information regarding the born circumcision; 2) to calculate the number needed to risks and benefits of the procedure,3 accomplishing harm for newborn circumcision based on this rate; and this task of well informed consent is hindered both 3) to establish trade-offs based on our complication rates and published estimates of the benefits of circumcision by the lack of precise information about potential including the prevention of urinary tract infections and harm and by the lack of clear ways to present this penile cancer. information. Methods. Using the Comprehensive Hospital Ab- The benefits of circumcision have been described stract Reporting System for Washington State, we retro- in numerous previous studies using a variety of spectively examined routine newborn circumcisions methodologies.4–8 Reported benefits include reduc- performed over 9 years (1987–1996). We used Interna- tion in the risk of penile cancer,9 urinary tract in- tional Classification of Diseases, Ninth Revision codes fections (UTIs),4,5 and sexually transmitted diseas- to identify both circumcisions and complications and es.10,11 Although the extent to which circumcision limited our analyses to children without other surgical decreases the risk of each of these outcomes has procedures performed during their initial birth hospi- been debated,6,12–15 a consensus appears to be talization. -

E Resources in the Medical Sciences
E-RESOURCES IN THE MEDICAL SCIENCES E-RESOURCES IN THE MEDICAL SCIENCES Presenter: Niala Dwarika-Bhagat October 2020 OBJECTIVES • To understand literature searching within a basic EBM (Evidence Based Medicine) framework. • Online Resources: to expose participants to databases - free and library-subscribed - available for medical/health sciences research. • Search Strategy: basic introduction • Hands-on: hands-on opportunity is included and databases – free / subscribed would be explored. What is EBM and why should I care? BMJ: • It's about integrating individual clinical expertise and the best external evidence. • Good doctors use both individual clinical expertise and the best available external evidence, and neither alone is enough. • Evidence based medicine is the conscientious, explicit, and judicious use of current best evidence in making decisions about the care of individual patients. • Evidence based medicine is not “cookbook” medicine. • Without clinical expertise, practice risks becoming tyrannised by evidence, for even excellent external evidence may be inapplicable to or inappropriate for an individual patient. • Without current best evidence, practice risks becoming rapidly out of date, to the detriment of patients. • Evidence based medicine is not restricted to randomised trials and meta-analyses. It involves tracking down the best external evidence with which to answer our clinical questions. Source: https://www.bmj.com/content/312/7023/71.full.print What EBM skills do you need? • Information mastery find the best evidence for every day practice • Assessment - relevance before rigor. Is the evidence patient- oriented? • Evaluation- information about therapies, diagnostic tests, and clinical decision rules. Understand basic statistics. • Efficiency - having at fingertips "just in time" information at the point of care using web based and/or handheld computer based information and tools for clinical decision making • Evaluation - expert-based information, including colleagues, presentations, reviews and guidelines. -

PCS PFA (Cycle 1 2021)
Cycle 1 2021 Funding Cycle PCORI Funding Announcement: Pragmatic Clinical Studies To Evaluate Patient-Centered Outcomes Published January 5, 2021 This PCORI Funding Announcement (PFA) applies to the funding cycle that closes May 4, 2021, at 5 pm ET. Submission Instructions, templates, and other resources are available at https://www.pcori.org/funding-opportunities/announcement/pragmatic-clinical-studies-cycle- 1-2021. CLOSED About PCORI The Patient-Centered Outcomes Research Institute (PCORI) was authorized by Congress in 2010 as a nonprofit, nongovernmental organization. PCORI’s purpose, as defined by our authorizing legislation, is to help patients, caregivers, clinicians, policy makers, and other healthcare system stakeholders make better-informed health decisions by “advancing the quality and relevance of evidence about how to prevent, diagnose, treat, monitor, and manage diseases, disorders, and other health conditions” and by promoting the dissemination and uptake of this evidence. PCORI is committed to transparency and a rigorous stakeholder-driven process that emphasizes patient engagement. PCORI uses a variety of forums and public comment periods to obtain public input to enhance its work. PCORI helps people make informed healthcare decisions and improves healthcare delivery and outcomes by producing and promoting high-integrity, evidence-based information that comes from research guided by patients and other stakeholders. Patient-Centered Outcomes Research Institute 1828 L St., NW, Suite 900 Washington, DC 20036 Phone: 202-827-7700 -

Evidence Process Documentation
Evidence Process for Hip Pain Guideline Research 9-26-17 Guideline Review using ADAPTE method and AGREE II instrument – 9/19/2017 ~60 Potentially relevant guidelines identified in various resources* 16 Guidelines appraised ~44 using AGREE II analysis Guidelines Excluded Exclusion Criteria: Non-English language Pediatrics Age of Publication Ex-U.S. focus 11 5 Limited information on advanced imaging Guidelines meeting AGREE II inclusion threshold Guidelines not meeting AGREE II inclusion of combined total score ≥ 90 threshold of combined total score ≥ 90 AND Rigor of Development Scaled Domain Score AND Rigor of Development Scaled Domain Score Percentage > 50% Percentage > 50% All were included in detailed ADAPTE recommendation analysis *Information Resources: Ovid Medline, NCBI PubMed, National Guideline Clearinghouse, Guidelines International Network, TRIP Database, Choosing Wisely, Cochrane Database, Agency for Healthcare Research and Quality, and numerous specialty society websites Additional Internet and bibliographic searches were performed for all phases of research For use only in connection with development of AUC by the CDI Quality Institute’s Multidisciplinary Committee Evidence Process for Hip Pain Guideline Research 9/26/2017 Systematic Literature Research –Ovid Medline Database (01/01/2016 – 09/06/2017) PICO: Suspected stress or fragility fracture with negative or indeterminate x-ray High-Level and Prospective Search Strategy: (fractur* and (hip or femoral)) AND (CT or computed tomography or computed tomography arthrogram or