Hierarchical Attention Prototypical Networks for Few-Shot Text Classification
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PH Braces for Fuel Crisis After Attacks on Saudi Oil Facilities
WEEKLY ISSUE @FilAmNewspaper www.filamstar.com Vol. IX Issue 545 1028 Mission Street, 2/F, San Francisco, CA 94103 Email: [email protected] Tel. (415) 593-5955 or (650) 278-0692 September 19-25, 2019 Elaine Chao (Photo: Wikimedia) VP Robredo faces resolution of her fraud, sedition cases Trump Transpo Sec. By Beting Laygo Dolor acting as presidential electoral tribu- by the Commission on Elections, which Chao under scrutiny Contributing Editor nal (PET) is expected to release the Marcos charged was an election taint- US NEWS | A2 decision on the vote recount of the ed with fraud and massive cheating. ANYTIME within the next week or 2016 elections filed by former sen- To prove his claim, Marcos so, Vice-president Leni Robredo can ator Ferdinand Marcos, Jr. against requested and was granted a manual expect a decision to be handed out in her. recount of votes in three provinces. two high-profile cases involving her. Robredo defeated Marcos by some TO PAGE A7 VP Leni Robredo (Photo: Facebook) In the first, the Supreme Court 250,000 votes based on the final tally ■ By Daniel Llanto FilAm Star Correspondent IN THE wake of the drone attacks on Saudi Arabia’s oil facilities, Foreign PH braces for fuel Affairs Sec. Teodoro Locsin Jr. said Riza Hontiveros (Photo: Facebook) the loss of half of the world’s top oil Divorce bill in producer is so serious it could affect the country “deeply” and cause the “Philip- crisis after attacks discussion at PH Senate pine boat to tip over.” PH NEWS | A3 “This is serious,” Locsin tweeted. -
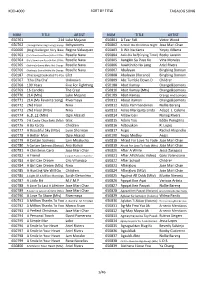
Kod-4000 Sort by Title Tagalog Song Num Title Artist Num
KOD-4000 SORT BY TITLE TAGALOG SONG NUM TITLE ARTIST NUM TITLE ARTIST 650761 214 Luke Mejares 650801 A Tear Fell Victor Wood 650762 ( Anong Meron Ang Taong ) Happy Itchyworms 650802 A Wish On Christmas Night Jose Mari Chan 650000 (Ang) Kailangan Ko'y Ikaw Regine Velasquez 650803 A Wit Na Kanta Yoyoy Villame 650763 (He's Somehow Been) A Part Of Me Roselle Nava 650804 Aalis Ka Ba?(Crying Time) Rocky Lazatin 650764 (He's Somehow Been)A Part Of Me Roselle Nava 650805 Aangkin Sa Puso Ko Vina Morales 650765 (Nothing's Gonna Make Me) Change Roselle Nava 650806 Aawitin Ko Na Lang Ariel Rivera 650766 (Nothing's Gonna)Make Me Change Roselle Nava 650807 Abalayan Bingbing Bonoan 650187 (This Song) Dedicated To You Lilet 650808 Abalayan (Ilocano) Bingbing Bonoan 650767 ‘Cha Cha Cha’ Unknown 650809 Abc Tumble Down D Children 650768 100 Years Five For Fighthing 650188 Abot Kamay Orange&Lemons 650769 16 Candles The Crest 650810 Abot Kamay (Mtv) Orange&Lemons 650770 214 (Mtv) Luke Mejares 650189 Abot-Kamay Orange And Lemons 650771 214 (My Favorite Song) Rivermaya 650811 About Kaman Orange&Lemons 650772 2Nd Floor Nina 650812 Adda Pammaneknek Nollie Bareng 650773 2Nd Floor (Mtv) Nina 650813 Adios Mariquita Linda Adapt. L. Celerio 650774 6_8_12 (Mtv) Ogie Alcasid 650814 Adlaw Gai-I Nanog Rivera 650775 9 & Cooky Chua Bakit (Mtv) Gloc 650815 Adore You Eddie Peregrina 650776 A Ba Ka Da Children 650816 Adtoyakon R. Lopez 650777 A Beautiful Sky (Mtv) Lynn Sherman 650817 Aegis Rachel Alejandro 650778 A Better Man Ogie Alcasid 650190 Aegis Medley Aegis 650779 A -

Kathryn Bernardo Winning Over Her Self-Doubt Bernardo’S Story Is Not Just All About Teleserye Roles
ittle anila L.M.ConfidentialMARCH - APRIL 2013 Stolen Art on the Rise in the Philippines MANILA, Philippines - Art dealers and buyers beware: Criminal syndicates have developed a taste for fine art and, moving like a pack of wolves, they know exactly what to get their filthy paws on and how to pass the blame on to unsuspecting gallery staffers or art collectors. Many artists, art galleries, and collectors who have fallen victim to heists can attest to this, but opt to keep silent. But do their silence merely perpetuate the growing art thievery in the industry? Because he could no longer agonize silently after a handful of his sought-after creations have been lost KATHRYN to recent robberies and break-ins, sculptor Ramon Orlina gave the Inquirer pertinent information on what appears to be a new art theft modus operandi that he and some of the galleries carrying his works Bernardo have come across. Perhaps the latest and most brazen incident was a failed attempt to ransack the Orlina atelier Winning Over in Sampaloc early in February! ORLINA’S “Protector,” Self-Doubt stolen from Alabang design space Creating alibis Two men claiming to be artists paid a visit to the sculptor’s Manila workshop and studio while the artist’s workers Student kills self over Tuition were on break; they told the staff they were in search of sculptures kept in storage. UP president: Reforms under way after coed’s tragedy The pair informed Orlina’s secretary that they wanted to purchase a few pieces immediately and MANILA, Philippines - In death, and its student support system In a statement addressed to the asked to be brought to where smaller works were Kristel Pilar Mariz Tejada has under scrutiny, UP president UP community and alumni, Pascual housed. -

Catalogue 2010
EQUIPO CINES DEL SUR Director_José Sánchez-Montes I Relaciones institucionales_Enrique Moratalla I Directores de programación_Alberto Elena, Casimiro Torreiro I Asesores de programación_María Luisa Ortega, Esteve Riambau I Programador Transcine y cinesdelsur.ext_ ÍNDICE José Luis Chacón I Gerencia_Elisabet Rus I Auxiliar administración_Nuria García I Documentación Audiovisual Festival_Jorge Rodríguez Puche, Rafael Moya Cuadros I Coordinador Producción_Enrique Novi I Producción_Clara Ruiz Molina, Daniel Fortanet I Coordinadora de comunicación, difusión y prensa_María Vázquez I Auxiliares de comunicación, difusión y prensa_ Ramón Antequera, Anne Munzert, Ana Cabello, José Manuel Peña I Jefa de prensa_Nuria Díaz I Comunicación y prensa_Estela 7 Presentación_Welcome Hernández, Isabel Díaz, Neus Molina I Márketing_José Ángel Martínez I Publicaciones_Carlos Martín I Catálogo_Laura 11 Jurado 2010_Jury 2010 Montero Plata I Gestión de programación, tráfico de copias y material promocional_Reyes Revilla I Auxiliares de programación, tráfico de copias y material promocional_Zsuzsi Gruber, Frederique Bernardis I Relaciones con la industria_Nina Frese I Auxiliar relaciones con la industria_Bram Hermans I Relaciones públicas_Magdalena 19 PROGRAMACIÓN_Programming Lorente I Coordinador de invitados_Enrique Novi I Invitados_Marichu Sanz de Galdeano, Toni Anguiano I Asesor Consejería de Cultura_Benito Herrera I Protocolo_María José Gómez I Web_Enrique Herrera, María Vázquez I 21 Secciones Oficial e Itinerarios_Official and Itineraries Sections Coordinador -
Special Issue on Film Criticism
semi-annual peer-reviewed international online journal VOL. 93 • NO. 1 • MAY 2020 of advanced research in literature, culture, and society UNITAS SPECIAL ISSUE ON FILM CRITICISM ISSN: 0041-7149 Indexed in the International Bibliography of the ISSN: 2619-7987 Modern Language Association of America About the Issue Cover From top to bottom: 1. Baconaua - One Big Fight Productions & Waning Crescent Arts (2017); 2. Respeto - Dogzilla, Arkeofilms, Cinemalaya, CMB Film Services, & This Side Up (2017); 3. Ebolusyon ng Isang Pamilyang Pilipino - Sine Olivia, Paul Tañedo Inc., & Ebolusyon Productions (2004); 4. Himala - Experimental Cinema of the Philippines (1982); and 5. That Thing Called Tadhana - Cinema One Originals, Epicmedia, Monoxide Works, & One Dash Zero Cinetools (2014). UNITAS is an international online peer-reviewed open-access journal of advanced research in literature, culture, and society published bi-annually (May and November). UNITAS is published by the University of Santo Tomas, Manila, Philippines, the oldest university in Asia. It is hosted by the Department of Literature, with its editorial address at the Office of the Scholar-in-Residence under the auspices of the Faculty of Arts and Letters. Hard copies are printed on demand or in a limited edition. Copyright @ University of Santo Tomas Copyright The authors keep the copyright of their work in the interest of advancing knowl- edge but if it is reprinted, they are expected to acknowledge its initial publication in UNITAS. Although downloading and printing of the articles are allowed, users are urged to contact UNITAS if reproduction is intended for non-individual and non-commercial purposes. Reproduction of copies for fair use, i.e., for instruction in schools, colleges and universities, is allowed as long as only the exact number of copies needed for class use is reproduced. -

VICE President KONTRABIDAS
2018 FEBRUARY NEW Kapuso Loveteam? Andre & Klea ANNULMENT OK lo PHILIPPINES - The House of Rep- Under the bill, marriage annulments veteam? resentatives has approved a proposed law that eliminates the costly judicial ANNULMENT process for marriage annulment. continued on page 25 JADINE movie ‘Never Not love you’ not happening? Am-FILIPINO star in HollYwood Dengue Vaccine Versace Assassination TV Show Side Effects PEOPLE Who use Blown out of EMOJIS a LOT have More sex proportion VICE President Office will DISaPPear Binibining Pilipinas 4th year longest FILIPINOS TOP on Binibining Pilipinas contestants like Agatha Romero (TOP)and crossover This photo, taken on April 4, 2016, shows a nurse showing vials of beauty queen Catriona Gray (ABOVE) the dengue vaccine Dengvaxia, developed by French medical giant are ready to represent the Philippines. Sanofi Pasteur, during a vaccination program at an elementary school in Metro Manila. A group of physicians and scientists has issued a statement expressing dismay at how the controversy surrounding the an- PORNHUB ti-dengue Dengvaxia vaccine has started to WHY showbiz need GOOD “erode” public confidence in the country’s vaccination programs. The statement, which was emailed to media outfits, was signed by 58 doctors, in- cluding former Health secretaries Esparan- KONTRABIDAS za Cabral and Manuel Dayrit. “The unnecessary fear and panic, largely brought about by the imprudent language reduce and unsubstantiated accusations by persons whose qualifications to render any expert opinion on the matter are questionable, at best, have caused many parents to resist having their children avail of life saving STRESS vaccines that our government gives,” the SEX statement read. -

How I Became Thekneejerkcritic T R a N S L a T E D B Y J O E L D a V I D
How I Became TheKneejerkCritic TRANSLATED BY JOEL DAVID Ricardo Espino Lopez GMA Network – Entertainment, Talk/Variety Who is this self-important TheKneeJerkCritic who is presumptuous enough to review movies as if he had the qualifications to do so? The nerve! He said the nerve, right?... The answer is, he is a self-published blogger. He does not read maga- zines, e-zines, or broadsheets. Even the tabloids steered clear. TheKneeJerkCritic is a blog that focuses on reviewing local and foreign films, plus a few stage presentations, while using street-based off-the- cuff language with more than just a sprinkling of bekinese or gay lingo. It is actually a spin-off of my earlier online alter ego, Ishna Vera [snobbish], which I started around 2006. My attempts as Ishna Vera were diverse and directionless and came out only occasionally. Only when I felt like acting up. Ooops sorry, force of habit. I meant, only when I needed to state something. My first “review” was not really even an actual review. It was more a reaction piece, my personal take on film as an experience rather than a review about the movie. See Evidence A, an early sample of the groundbreaking pink indie film Antonio’s Secret [directed by Joselito Altarejos, Beyond the Box & Viva Digital, 2008]: LOPEZ: HOW I BECAME THEKNEEJERKCRITIC UNITAS 137 I missed catching Antonio’s Secret when the director’s cut was shown last year I think. I managed to get hold of a copy recently and I excitedly popped it into the player. The narrative of Antonio’s Secret goes like this: .. -

Festival Guide Fdcpchannel.Ph 1 Table of Contents
SAMA ALL OCT. 31 - DEC. 13, 2020 PPP SHORT FILM SHOWCASE NOV. 20 - DEC. 13, 2020 PPP MAIN FEATURE FILM SHOWCASE FESTIVAL GUIDE FDCPCHANNEL.PH 1 TABLE OF CONTENTS SHORT FILM SHOWCASE Special Screening: Anak Dalita 13 Cinemarya Premiere 15 Sine Katabataan 18 Regional Shorts 20 MAIN FEATURE FILM SHOWCASE Premium 33 Classics 47 Documentary 52 Romance 57 Youth and Family 63 Genre 68 From the Regions 73 Pang-Oscars 78 Tribute 83 Bahaghari 88 PPP Retro 93 Special Feature 97 Main Feature Film Showcase Calendar 99 Events Schedule 107 The Film Development Council of the Philippines (FDCP) is the national film agency responsible for film policies and programs to ensure the economic, cultural and educational development of the Philippine film industry. It aims to encourage the production of quality films and to conduct film-related events that enhance the skills of the Filipino talents. The agency also leads the film industry’s participation in domestic and foreign film markets, and local and international film festivals, and is tasked to preserve and protect films as part of the country’s national cultural heritage. PISTA NG PELIKULANG PILIPINO is a multi-day festival of original Filipino films that will be seen and enjoyed nationwide. This highly successful showcase of our film industry’s ingenuity and artistry began in August 2017 in partnership with cinemas throughout the country with the objective of creating wider platforms for Filipino films to gain more audience share and profit, as well as to promote excellence in filmmaking. Now on its fourth year and in light of the pandemic, PPP premieres in the FDCP Channel online in support of Filipino filmmakers and producers to feature an exciting curation of 90 full feature films and 80 short films. -

YCC 2019.Indb
The Film Desk of the Young Critics Circle The 29th Annual “During currently trying times, Circle Citations it is imperative to look for for Distinguished spaces of resistance such as Achievement those offered by the arts, and cinema in particular. Aside in Film for from attempting to challenge 2018 the status quo, filmmakers need to negotiate the very + spaces from which they can SINE SIPAT: pose this interrogation.” Recasting Roles and Images, Stars, Awards, and Criticism August 16, 2019 Jorge B. Vargas Museum University of the Philippines Roxas Avenue, UP Campus | Diliman, Quezon City } The 28th Annual CIRCLE CITATIONS for Distinguished Achievement in 2018Film for + SINE SIPAT: Recasting Roles and Images, Stars, Awards, and Criticism 1 2 The Citation he Film Desk of the Young Critics Circle (YCC) first gave its annual citations in film achievement in 1991, a year after the YCC was Torganized by 15 reviewers and critics. In their Declaration of Principles, the members expressed the belief that cultural texts always call for active readings, “interactions” in fact among different readers who have the “unique capacities to discern, to interpret, and to reflect... evolving a dynamic discourse in which the text provokes the most imaginative ideas of our time.” The Film Desk has always committed itself to the discussion of film in the various arenas of academe and media, with the hope of fostering an alternative and emergent articulation of film critical practice, even within the severely debilitating culture of “awards.” binigay ng Film Desk ng Young Critics Circle (YCC) ang unang taunang pagkilala nito sa kahusayan sa pelikula noong 1991, ang taon pagkaraang maitatag ang YCC ng labinlimang tagapagrebyu at kritiko. -

November 2008 Issue
Volume XXVI No. 11 November 2008 www.filipinostar.org Survey report reveals plight of Filipino caregivers, need for reforms Montreal, November 20, 2008 CTV news aired the release of a study about the plight of Filipino caregivers which brought to the attention of the public what the Live-in Caregiver Program is all about and how it has affected the lives of migrant workers who are mostly women. The study was undertaken through the collaborative efforts of PINAY members and the students and researchers of McGill University’s School of Social Work and the assistance of specialists from UQAM. PINAY, an organization of Filipino women in Quebec, founded in 1991, has been playing a key role in the struggle to protect the rights and welfare of migrants and immigrants, especially Filipina domestic workers and their families living and working in Quebec. During a seminar held at 6767 Cote des Neiges, a dramatization of the difficult working conditions of live-in caregivers, was an eye opener to what has long been hidden in the privacy of homes where they work. It Some members and officers of PINAY pose for souvenir after the seminar held on Sunday, November 9, 2008 at Centre See Page 4 - Filipino caregivers Resources Communutaire, 6767 Cote des Neiges, in Montreal. CTV aired the video of this seminar only on Nov. 20, 2008. No clear winner in leaders debate Laguna Province TOURISM |PAGE 10 Contents Cooperative News . .p. 3 Tourism . p. 6-7 Community News . p. 8 Global Perspectives . p. 10 Premier Jean Charest PQ Leader Pauline Marois ADQ Leader Mario Dumont Philippine Cuisine . -

Sharon's Noranian Turn: Stardom, Embodiment, and Language in Philippine Cinema
UC Irvine UC Irvine Previously Published Works Title Sharon’s Noranian Turn: Stardom, Embodiment, and Language in Philippine Cinema Permalink https://escholarship.org/uc/item/6867483k Journal Discourse, 31(3) Author Lim, Bliss Cua Publication Date 2009-10-01 Peer reviewed eScholarship.org Powered by the California Digital Library University of California Sharon's Noranian Turn: Stardom, Embodiment, and Language in Philippine Cinema Bliss Cua Lim Discourse, Volume 31, Number 3, Fall 2009, pp. 318-358 (Article) Published by Wayne State University Press For additional information about this article http://muse.jhu.edu/journals/dis/summary/v031/31.3.lim01.html Access Provided by University of California @ Irvine at 11/09/10 7:10PM GMT Sharon’s Noranian Turn: Stardom, Embodiment, and Language in Philippine Cinema Bliss Cua Lim Writing in 1965 under the pseudonym Quijano de Manila, National Artist Nick Joaquin vividly describes an era when the decline of the great Philippine film studios spawned an unbridled “star system still in apogee.” In the 1960s, star worship fuels the popular cinema and feeds “the avarice of the independent producer.” The middle- class lament that mainstream Filipino movies are hardly “quality” pictures, Joaquin writes impatiently, misses the point: “The movie fans crowd to a local movie not because they expect a sensible story or expert acting or even good entertainment”; instead, they go to the movies to see the stars they adore—action film kings Fernando Poe Jr. and Joseph Estrada, glamour goddesses Amalia Fuentes and Susan Roces. “Our movie idols remain idolized, whatever the quality of their vehicles, as long as they remain impossibly young, impossibly glamorous, impossibly beautiful”1 (figure 1). -

Legal Wife's Angel Locsin & Maja Salvador
TFC’S BIGGEST STARS ARE COMING TO TORONTO!!! Unkabogable Vice Ganda Legal Wife’s Angel Locsin & Maja Salvador Bride for Rent’s Xian Lim Mirabella’s Enrique Gil Mr. Pure Energy Gary Valenciano plus!!! Kapamilya Celebrity Bingo hosted by Be Careful with My Heart’s Doris (Tart Carlos) & Sabel (Vivieka Ravanes) plus!!! Pinoy Food Booths, Tiangge, Giveaways & more! Advertisements go a long way with WAVES MAY 2014 Vol. 3 No.5 filipinonewswaves@ gmail.com (647) 718-1360 Miriam, Chiz & The US bases are Abad in Napo-list back? By Waves News staff By Waves News staff Justice Secretary Leila de Lima meets with Senate Blue Ribbon committee chairman Teofisto Guingona III to discuss the ‘Napolist’ yesterday. De Lima submitted the list signed by Janet Napoles (inset) to Guingona during a closed-door hearing at the sena- tor’s office. On November 24, 1992, the American Flag was lowered in Subic for the last time and The accuser becomes the accused. Senator Miriam Santiago, one of the most the last 1,416 Sailors and Marines at Subic Bay Naval Base left by plane from Naval Air vocal and staunchest critic/accuser of her lawmaker colleagues in the senate, Station Cubi Point and by the USS Belleau Wood. This withdrawal marked the first time has become herself the accused in the notorious “Pork Barrel Scandal”or the since the 16th century that no foreign military forces were present in the Philippines. Prioriy Development Assistance Fund(PDAF) scam involving billions and bil- In US President Obama’s recent visit, a new security agreement, the Enhanced De- lions of pesos in government money.