Analysis of Key Drivers of Trading Performance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

RHF Use and Risk Disclosures
RHF Use and Risk Disclosures IT IS IMPORTANT THAT YOU READ AND FULLY UNDERSTAND THE FOLLOWING RISKS OF TRADING AND INVESTING IN YOUR SELF-DIRECTED ROBINHOOD FINANCIAL ACCOUNT. Use of Self-Directed Trading Accounts. All Customer Accounts are self-directed. Accordingly, unless Robinhood Financial clearly identifies a communication as an individualized recommendation, Customers are solely responsible for any and all orders placed in their Accounts and understand that all orders entered by them are based on their own investment decisions or the investment decisions of their duly authorized representative or agent. Consequently, any Customer of Robinhood Financial agrees that, unless otherwise agreed to in writing, neither Robinhood Financial nor any of its employees, agents, principals or representatives: ● provide investment advice in connection with a Customer Account; ● recommend any security, transaction or order; ● solicit orders; ● act as a market maker in any security; ● make discretionary trades; and ● produce or provide research. To the extent research materials or similar information is available through Robinhood.com or the websites of any of its affiliates, these materials are intended for informational and educational purposes only and they do not constitute a recommendation to enter into any securities transactions or to engage in any investment strategies. General Risks of Trading and Investing. All securities trading, whether in stocks, exchange-traded funds (“ETFs”), options, or other investment vehicles, is speculative in nature and involves substantial risk of loss. Robinhood Financial encourages its Customers to invest carefully and to use the information available at the websites of the SEC at http://www.sec.gov and FINRA at http://FINRA.org. -

IG Response to the Consultation on the Protection of Retail Investors in Relation to the Distribution of Cfds
IG Response to the Consultation on the Protection of Retail Investors in relation to the Distribution of CFDs. We would like to thank the CBI for giving us the opportunity to respond to the Consultation on the Protection of Retail Investors in relation to the Distribution of CFDs. This is an area that we feel very strongly about and we agree that as an industry we must take steps to protect retail clients. One of our main concerns is that the disproportionate implementation of investor protection measures may guide retail clients towards irresponsible firms that are outside the control or influence of the CBI, or indeed of any other EEA regulatory body. We hope that our response, including the quantitative analysis that has been provided and summarised within the appendices to this response, is useful and insightful and we ask that this information is given due consideration as part of the consultation process. 1. Which of the options outlined in this paper do you consider will most effectively and proportionately address the investor protection risks associated with the sale or distribution of CFDs to retail clients? Please give reasons for your answer. We believe that Option 2 would be the more effective and proportionate of the two options offered in CP107 (though we disagree with the details of the suggested leverage restriction regime included within that option – see answer 2(a), below). We think Option 1, a prohibition on the sale or distribution of CFDs to retail clients, would be a counterproductive and disproportionate measure that would be likely to lead to worse client outcomes – both for (i) the set of clients with sufficient understanding and a legitimate need to trade CFDs and (ii) vulnerable clients, for whom CFDs are unsuitable, who will be more likely to be successfully targeted by unscrupulous, unregulated firms. -

Thinkorswim Sharing
Reprinted from Technical Analysis of STOCK S & COMMODITIE S magazine. © 2014 Technical Analysis Inc., (800) 832-4642, http://www.traders.com PRODUCT REVIEW thinkorswim Sharing TD AMERITRADE, INC. SHORTENING THE found both within the thinkorswim AND AFFILIATES LEARNING CURVE platform and the thinkorswim web-based Website: www.thinkorswim.com, Traders who use thinkorswim as their trading platform: www.mytrade.com broker and trading, charting, and n thinkorswim is the actual trading Email: [email protected] analysis platform might just find that and analysis platform; a web and Product: Social media sharing all of those pertinent questions — and mobile version are also available tools and online community for more — can be answered within the thinkorswim users thinkorswim/MyTrade section of this n thinkorswim/Sharing is the broad, Price: Free for TD Ameritrade comprehensive analysis and trading descriptive name that encom- account holders platform. The platform already offers a passes all of the sharing features myriad of unique technical, analytical, linked to thinkorswim by Donald W. Pendergast Jr. and forecasting tools for serious trad- n thinkorswim/MyTrade is a web- ers and investors. Experienced traders site and section within the thinkor- nce an individual makes the using the thinkorswim/MyTrade tools swim platform where user-posted important decision to pursue the will have an eager audience of newer trades, ideas, and charts are dis- O goal of becoming a successful and maturing traders with whom they tributed to other MyTrade users trader, chooses a stock/option/forex/ can freely share their trade ideas, charts, commodity broker, and funds his ac- scans, watchlists, and chart layouts. -

The Law and Economics of Hedge Funds: Financial Innovation and Investor Protection Houman B
digitalcommons.nyls.edu Faculty Scholarship Articles & Chapters 2009 The Law and Economics of Hedge Funds: Financial Innovation and Investor Protection Houman B. Shadab New York Law School Follow this and additional works at: http://digitalcommons.nyls.edu/fac_articles_chapters Part of the Banking and Finance Law Commons, and the Insurance Law Commons Recommended Citation 6 Berkeley Bus. L.J. 240 (2009) This Article is brought to you for free and open access by the Faculty Scholarship at DigitalCommons@NYLS. It has been accepted for inclusion in Articles & Chapters by an authorized administrator of DigitalCommons@NYLS. The Law and Economics of Hedge Funds: Financial Innovation and Investor Protection Houman B. Shadab t Abstract: A persistent theme underlying contemporary debates about financial regulation is how to protect investors from the growing complexity of financial markets, new risks, and other changes brought about by financial innovation. Increasingly relevant to this debate are the leading innovators of complex investment strategies known as hedge funds. A hedge fund is a private investment company that is not subject to the full range of restrictions on investment activities and disclosure obligations imposed by federal securities laws, that compensates management in part with a fee based on annual profits, and typically engages in the active trading offinancial instruments. Hedge funds engage in financial innovation by pursuing novel investment strategies that lower market risk (beta) and may increase returns attributable to manager skill (alpha). Despite the funds' unique costs and risk properties, their historical performance suggests that the ultimate result of hedge fund innovation is to help investors reduce economic losses during market downturns. -

2017 Contributing Editors Joshua Ford Bonnie and Kevin P Kennedy
GETTING THROUGH THE DEAL Initial Public Offerings Initial Public Offerings Public Initial Contributing editors Joshua Ford Bonnie and Kevin P Kennedy 2017 Law Business Research 2017 © Law Business Research 2016 Initial Public Offerings 2017 Contributing editors Joshua Ford Bonnie and Kevin P Kennedy Simpson Thacher & Bartlett LLP Publisher Law The information provided in this publication is Gideon Roberton general and may not apply in a specific situation. [email protected] Business Legal advice should always be sought before taking Research any legal action based on the information provided. Subscriptions This information is not intended to create, nor does Sophie Pallier Published by receipt of it constitute, a lawyer–client relationship. [email protected] Law Business Research Ltd The publishers and authors accept no responsibility 87 Lancaster Road for any acts or omissions contained herein. Although Senior business development managers London, W11 1QQ, UK the information provided is accurate as of July 2016, Alan Lee Tel: +44 20 3708 4199 be advised that this is a developing area. [email protected] Fax: +44 20 7229 6910 Adam Sargent © Law Business Research Ltd 2016 Printed and distributed by [email protected] No photocopying without a CLA licence. Encompass Print Solutions First published 2015 Tel: 0844 2480 112 Dan White Second edition [email protected] ISSN 2059-5484 © Law Business Research 2016 CONTENTS Global overview 5 Japan 51 Joshua Ford -

Playing with Fire
SPECIAL REPORT FINANCIAL INNOVATION February 25th 2012 Playing with fire SRFininnov1.indd 1 14/02/2012 15:09 SPECIAL REPORT FINANCIAL INNOVATION Playing with fire Financial innovation can do a lot of good, says Andrew Palmer. It is its tendency to excess that must be curbed FINANCIAL INNOVATION HAS a dreadful image these days. Paul CONTENTS Volcker, a former chairman of America’s Federal Reserve, who emerged 4 How innovation happens from the 2007-08 nancial crisis with his reputation intact, once said that The ferment of nance none of the nancial inventions of the past 25 years matches up to the ATM. Paul Krugman, a Nobel prize-winning economist-cum-polemicist, 5 Retail investors has written that it is hard to think of any big recent nancial break- The little guy throughs that have aided society. Joseph Stiglitz, another Nobel laureate, 6 Exchange-traded funds argued in a 2010 online debate hosted by The Economist that most inno- From vanilla to rocky road vation in the run-up to the crisis was not directed at enhancing the 9 High-frequency trading ability of the nancial sector to The fast and the furious perform its social functions. 11 Financial infrastructure Most of these critics have Of plumbing and promises market-based innovation in their sights. There is an enormous 12 Small rms amount of innovation going on On the side of the angels in other areas, such as retail pay- 13 Collateral ments, that has the potential to Safety rst change the way people carry and spend money. But the debate and hence this special reportfo- Glossary cuses mainly on wholesale pro- Finance has a genius for obscuring simple ducts and techniques, both be- ideas with technical jargon. -

Does the Glass Ceiling Exist? a Longitudinal Study of Women's
The Journal of Applied Business Research – May/June 2014 Volume 30, Number 3 Does The Glass Ceiling Exist? A Longitudinal Study Of Women’s Progress On French Corporate Boards Rey Dang, La Rochelle Business School, France Duc Khuong Nguyen, IPAG Business School, France Linh-Chi Vo, EM Normandie, France ABSTRACT In this article, we conduct a longitudinal study of women’s progress on French corporate boards of directors. We particularly focus on the extent to which women directors have circumvented the glass ceiling. Using a sample of SBF 120 companies over a 10-year period from 2000 to 2009, our results provide evidence of a significant increase in the number of women on French corporate boards. However, the corporate glass ceiling hypothesis is consistently rejected whatever the considered measure of female directors; i.e., the number of board seats held by women, the number of firms with a critical mass of female directors, and the number of directorships held by each women director. Keywords: Boards of Directors; Gender; Diversity; Corporate Governance 1. INTRODUCTION ver the period 2000-2009, the average participation rate of women in the labor market increased from 60 to 64 percent across the European Union’s 27 Members States. More specifically, in France, it went up from 60.3 to 64.9 percent.1 However, despite this notable progress, women remain under-represented Oin senior or executive positions (ILO, 2009).2 This lack of female representation on corporate boards of directors, which is commonly referred to as glass ceiling in practice and past academic studies, seems to be a global phenomenon because women on corporate boards (WOCB) represents less than 15% of board members in the United States, United Kingdom, Canada, Australia, and many European countries (Dang & Vo, 2012).3 Morrison et al. -

Adame V. Robinhood Financial, LLC Et
Case 5:20-cv-01769 Document 1 Filed 03/12/20 Page 1 of 72 1 THE RESTIS LAW FIRM, P.C. William R. Restis, Esq. (SBN 246823) 2 [email protected] 402 W. Broadway, Suite 1520 3 San Diego, California 92101 Telephone: +1.619.270.8383 4 Counsel for Plaintiff and the Putative Class 5 [Additional Counsel Listed On Signature Page] 6 7 8 9 10 UNITED STATES DISTRICT COURT 11 12 FOR THE NORTHERN DISTRICT OF CALIFORNIA 13 SAN JOSE DIVISION 14 ALEXANDER ADAME, individually and on Case No: 15 behalf of all others similarly situated, 16 Plaintiff, CLASS ACTION COMPLAINT 17 v. 18 DEMAND FOR JURY TRIAL ROBINHOOD FINANCIAL, LLC, a Delaware 19 limited liability company, ROBINHOOD SECURITIES, LLC, a Delaware limited liability 20 Company, and ROBINHOOD MARKETS, INC., a Delaware corporation, 21 22 23 Defendants. 24 25 26 27 28 CLASS ACTION COMPLAINT Case 5:20-cv-01769 Document 1 Filed 03/12/20 Page 2 of 72 1 Plaintiff Alexander Adame (“Plaintiff”), individually and on behalf of all others similarly 2 situated, brings this putative Class aCtion against Defendants Robinhood Financial, LLC 3 (“Robinhood Financial”), Robinhood SeCurities, LLC (“Robinhood SeCurities”), and Robinhood 4 Markets, Inc. (“Robinhood Markets”) (colleCtively, “Robinhood”), demanding a trial by jury. 5 Plaintiff makes the following allegations pursuant to the investigation of Counsel and based upon 6 information and belief, except as to the allegations speCifiCally pertaining to himself, whiCh are 7 based on personal knowledge. ACCordingly, Plaintiff alleges as follows: 8 NATURE OF THE ACTION 9 1. Robinhood is an online brokerage firm. -

FRC Board Diversity and Effectiveness in FTSE 350
Leadership Institute Board Diversity and Effectiveness in FTSE 350 Companies July 2021 Acknowledgements Report written by: Mary Akimoto, Osman Anwar, Molly Broome, Dragos Diac, Dr Randall S Peterson, Dr Sergei Plekhanov, Simon Osborne and Vyla Rollins We thank the following individuals on the joint LBSLI/SQW research team for their contributions to this research: • Ruth Cluness, LBSLI • Tom Gosling, LBSLI • Brent Hamerla, LBSLI • Letitia Joseph, LBSLI • Barbara Moorer, LBSLI • Andrei Visiteu, LBSLI • Desi Zlatanova, LBSLI We also give a special thank you to our team of research interviewers: • Eva Beazley • Helen Beedham • Christine de Largy • Kathryn Gordon • Dr JoEllyn Prouty McLaren The London Business School Leadership Institute expresses its thanks to all of our stakeholder and collaborators, who supported our research efforts. We would like to express our specific gratitude to the following individuals, for their invaluable guidance, comments, suggestions and support throughout this project: Kit Bingham, Charlie Brown, Gerry Brown, Sue Clark, Louis Cooper, John Dore, Lisa Duke, Roshy Dwyer, Farrer & Co (Anisha Birk, Natalie Rimmer, Peter Wienand), Louise Fowler, Dr Julian Franks, Dr Karl George MBE, Dr Tom Gosling, Dr Byron Grote, Fiona Hathorn, Jonathan Hayward, Susan Hooper, Dr Ioannis Ioannou, Bernhard Kerres, LBS Accounts department (Akposeba Mukoro, Janet Nippard), LBS Advancement department (Luke Ashby, Susie Balch, Nina Bohn, Ian Frith, Sarah Jeffs, Maria Menicou), LBS Executive Education, LBS Research & Faculty Office and -

Examining Drivers of Trading Volume in European Markets
Received: 28 July 2016 Accepted: 19 December 2017 DOI: 10.1002/ijfe.1608 RESEARCH ARTICLE Examining drivers of trading volume in European markets Bogdan Batrinca | Christian W. Hesse | Philip C. Treleaven Department of Computer Science, Abstract University College London, Gower Street, London WC1E 6BT, UK This study presents an in‐depth exploration of market dynamics and analyses potential drivers of trading volume. The study considers established facts from Correspondence Bogdan Batrinca, Department of the literature, such as calendar anomalies, the correlation between volume and Computer Science, University College price change, and this relation's asymmetry, while proposing a variety of time London, Gower Street, London WC1E series models. The results identified some key volume predictors, such as the 6BT, UK. Email: [email protected] lagged time series volume data and historical price indicators (e.g. intraday range, intraday return, and overnight return). Moreover, the study provides empirical evi- Funding information dence for the price–volume relation asymmetry, finding an overall price asymme- Engineering and Physical Sciences Research Council (EPSRC) UK try in over 70% of the analysed stocks, which is observed in the form of a moderate overnight asymmetry and a more salient intraday asymmetry. We conclude that JEL Classification: C32; C52; C58; G12; volatility features, more recent data, and day‐of‐the‐week features, with a notable G15; G17 negative effect on Mondays and Fridays, improve the volume prediction model. KEYWORDS asymmetric models, behavioural finance, European stock market, feature selection, price volume relation, trading volume 1 | INTRODUCTION which was $63tn in 2011 (World Federation of Exchanges, 2012) and $49tn in 2012 (World Federation of Exchanges, This study investigates the drivers affecting the trading 2013). -

Vanguard P 0 Box 2600 Valley Forge, PA 19482-2600
Vanguard P 0 Box 2600 Valley Forge, PA 19482-2600 610-669-1000 www.vanguard.com March15,2013 Submitted electronically Elizabeth M. Murphy, Secretary U.S. Securities and Exchange Commission 100 F Street, N E Washington, D.C. 20549-1090 RE: NYSE Petition for Rulemaking Under Section 13(f) of the Securities Exchange Act of 1934; File No. 4-659 Dear Ms. Murphy: The Vanguard Group, Inc. ("Vanguard") 1 appreciates the opportunity to express its views to the Commission on the petition for rulemaking under Section 13(f) ofthe Securities Exchange Act of 1934 ("Exchange Act") that was submitted on February I, 2013 by NYSE Euronext ("NYSE"), a long with the Society ofCorporate Secretaries and Governance Professionals and the National Investor Relations Institute (the "NYSE Petition"). We strongly oppose the NYSE Petition's proposed shortening of the reporting deadline applicable to institutional investment managers under Exchange Act Rule 13f-1 from 45 calendar days after calendar quarter end to two business days after calendar quarter end . A shorter delay for release of this information could expand the opportunities for predatory trading practices that ha1m the interests ofmutual fund shareholders. Vanguard's mutual funds and ETFs invest in thousands of issuers to seek to provide long-term investment returns for fund shareholders. We are concerned that the release of information contained in Form 13F reports on a mere two-day delay provides opportunities for hedge funds, speculators, proprietary trading desks, and certain other professional traders to exploit the information in ways that are hmmful to fund shareholders, particularly by "front running" fund trades. -
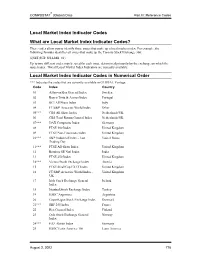
Local Market Index Indicator Codes in Numerical
® COMPUSTAT (Global) Data Part III: Reference Codes Local Market Index Indicator Codes What are Local Market Index Indicator Codes? These codes allow you to identify those issues that make up a local market index. For example, the following formula identifies all issues that make up the Toronto Stock Exchange 300: @SET($GI+$FI,LMII=81) Up to two different codes may be used for each issue, determined primarily by the exchange on which the issue trades. Not all Local Market Index Indicators are currently available. Local Market Index Indicator Codes in Numerical Order *** Indicates the codes that are currently available in GLOBAL Vantage Code Index Country 01 Affarsvarlden General Index Sweden 02 Banco Totta & Acores Index Portugal 03 BCI All Share Index Italy 04 FT/S&P Actuaries World Index Other 05*** CBS All Share Index Netherlands/UK 06 CBS Total Return General Index Netherlands/UK 07*** DAX Composite Index Germany 08 FTSE 100 Index United Kingdom 09 FTSE Non-Financials Index United Kingdom 10*** S&P Industrial Index - Last United States Trading Day 11*** FTSE All-Share Index United Kingdom 12 Bombay SE Natl Index India 13 FTSE 250 Index United Kingdom 14*** Vienna Stock Exchange Index Austria 15 FTSE SmallCap EX IT Index United Kingdom 16 FT/S&P Actuaries World Index - United Kingdom UK 17 Irish Stock Exchange General Ireland Index 18 Istanbul Stock Exchange Index Turkey 19 HSBC Argentina Argentina 20 Copenhagen Stock Exchange Index Denmark 21*** SBF 250 Index France 22 Hex General Index Finland 23 Oslo Stock Exchange General Norway