Facebook's Data Center-Wide Power Management System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Based on Bicycle Dynamic Energy
© 2021 JETIR July 2021, Volume 8, Issue 7 www.jetir.org (ISSN-2349-5162) Developing A Vehicle - Based On Bicycle Dynamic Energy 1V Dhanush Kumar, 1Pavan Yadhav, 1Naveen Reddy A, 1P M Nitesh Kumar, 2Anand Babu K 1U G Scholar, 2Assistant Professor 1,2School of Mechanical Engineering, REVA University, Bengaluru-560064, Karnataka, India. Abstract:- There are so many vehicles that came to influence in the existing world. Their operating systems are based on usual fossil fuels system. At the present sense the fossil fuel can exceed only for a certain period after that we have to go for a change to other methods. Thus we have made an attempt to design and fabricate an ultimate system (solar cycle) which would produce cheaper and effective result than the existing system. This will be very useful needs of the world. An attempt is made in the fabrication of solar powered system for a two-wheeler. The drive system of the normal cycle is not altered. This system is two in one system. The cycle is operated either by pedaling manually battery and motor driving mechanism. Index Term: Dynamo, Throttle, Pedaling, Battery, Sprocket I. Introduction:- All vehicles that are in the market cause pollution and the fuel cost is also increasing day by day. In order to compensate the fluctuating fuel cost and reducing the pollution a good remedy is needed i.e. our transporting system. Due to ignition of hydrocarbon fuels, in the vehicle, sometime difficulties such as wear and tear may be high and more attention is needed for proper maintenance. -
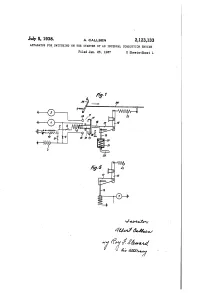
July 5, 1938. A. CALLSEN 2,123,133 APPARATUS for SWITCHING on the STARTER of an INTERNAL COMBUSTION ENGINE Filed Jan
July 5, 1938. A. CALLSEN 2,123,133 APPARATUS FOR SWITCHING ON THE STARTER OF AN INTERNAL COMBUSTION ENGINE Filed Jan. 25, 1937 2. Sheets-Sheet l July 5, 1938. A. CALS EN 2,123,133 APPARATUS FOR SWITCHING ON THE STARTER OF AN INTERNAL COMBUSTION ENGINE Filed Jan. 25, 1937 2. Sheets-Sheet 2 Patented July 5, 1938 2,123,133 UNITED STATES PATENT OFFICE 2,123,133 APPARATUS FOR SWITCHING ON THE STARTER OF AN INTERNAL COMBUSTION ENGINE Albert Casen, stuttgart-Botnang, Germany, as signor to Robert Bosch Gesellschaft mit be schrankter Haftung, a corporation of Ger many Application January 25, 1937, Serial No. 122,261 In Germany February 1, 1936 15 Claims. (Ch. 290-36) The invention relates to an apparatus for ing the starting exactly as When accelerating. switching on the starter of an internal combus The foot can thus be moved back even into its tion engine for use on vehicles, in which other initial position, and if desired, removed wholly elements of the vehicle control besides the starter from the pedal. 5 are operated by a common operating member. The invention is more particularly described In known apparatus of this kind, the clutch With reference to the accompanying drawings, in pedal or accelerator pedal is connected with the Which:- SWitch of the starter by a clutch which is engaged Figure 1 is a diagrammatic view of One arrange when the engine is stopped, while it is released ment of switch control apparatus. 0 by the vacuum of the engine induction pipe or Figures 2, 3, and 4 are similar views of alter 10 by a relay fed from the lighting dynamo when native constructions. -

Operator's Manual
OPERATOR'S MANUAL MODELS GR2020G GR2120 GR2120AU G R 2 0 2 0 G · G R 2 1 2 0 · G R 2 1 2 0 1BDAHAOAP0580 A AS . D . 1 - 1 . - . AK Code No. K1270-7122-1 U READ AND SAVE THIS MANUAL PRINTED IN U.S.A. © KUBOTA Corporation 2014 ABBREVIATION LIST Abbreviations Definitions API American Petroleum Institute PTO Power Take Off PT Permanent Type (=Ethylene glycol anti-freeze) rpm Revolutions Per Minute SAE Society of Automotive Engineers KRA Kubota Reverse Awareness System KUBOTA Corporation is ··· Since its inception in 1890, KUBOTA Corporation has grown to rank as one of the major firms in Japan. UNIVERSAL SYMBOLS To achieve this status, the company has through the years diversified the range of its products and services to a remarkable As a guide to the operation of your tractor, various universal symbols have been utilized on the instruments and extent. Nineteen plants and 16,000 employees produce over 1,000 controls. The symbols are shown below with an indication of their meaning. different items, large and small. All these products and all the services which accompany them, Safety Alert Symbol Coolant Temperature however, are unified by one central commitment. KUBOTA makes products which, taken on a national scale, are basic necessities. Gasoline Fuel Mower-Lowered position Products which are indispensable. Products which are intended to help individuals and nations fulfill the potential inherent in their Diesel Fuel Mower-Raised position environment. KUBOTA is the Basic Necessities Giant. Brake Headlight This potential includes water supply, food from the soil and from the sea, industrial development, architecture and construction, Parking Brake Headlight-ON transportation. -

History of Electric Light
SMITHSONIAN MISCELLANEOUS COLLECTIONS VOLUME 76. NUMBER 2 HISTORY OF ELECTRIC LIGHT BY HENRY SGHROEDER Harrison, New Jersey PER\ ^"^^3^ /ORB (Publication 2717) CITY OF WASHINGTON PUBLISHED BY THE SMITHSONIAN INSTITUTION AUGUST 15, 1923 Zrtie Boxb QSaftitnore (prcee BALTIMORE, MD., U. S. A. CONTENTS PAGE List of Illustrations v Foreword ix Chronology of Electric Light xi Early Records of Electricity and Magnetism i Machines Generating Electricity by Friction 2 The Leyden Jar 3 Electricity Generated by Chemical Means 3 Improvement of Volta's Battery 5 Davy's Discoveries 5 Researches of Oersted, Ampere, Schweigger and Sturgeon 6 Ohm's Law 7 Invention of the Dynamo 7 Daniell's Battery 10 Grove's Battery 11 Grove's Demonstration of Incandescent Lighting 12 Grenet Battery 13 De Moleyns' Incandescent Lamp 13 Early Developments of the Arc Lamp 14 Joule's Law 16 Starr's Incandescent Lamp 17 Other Early Incandescent Lamps 19 Further Arc Lamp Developments 20 Development of the Dynamo, 1840-1860 24 The First Commercial Installation of an Electric Light 25 Further Dynamo Developments 27 Russian Incandescent Lamp Inventors 30 The Jablochkofif " Candle " 31 Commercial Introduction of the Differentially Controlled Arc Lamp ^3 Arc Lighting in the United States 3;^ Other American Arc Light Systems 40 " Sub-Dividing the Electric Light " 42 Edison's Invention of a Practical Incandescent Lamp 43 Edison's Three-Wire System 53 Development of the Alternating Current Constant Potential System 54 Incandescent Lamp Developments, 1884-1894 56 The Edison " Municipal -

Powering the Electric Vehicle with a Dynamo Using Wind Energy
JOURNAL OF CRITICAL REVIEWS ISSN- 2394-5125 VOL 7, ISSUE 19, 2020 POWERING THE ELECTRIC VEHICLE WITH A DYNAMO USING WIND ENERGY Mr. Kamalpreet Singh1, Dr. Harbinder Singh2, Dr. Harpal Singh3, Dr. Mohit Srivastava4 1Computer Science Engineering, Chandigarh Engineering College, Landran, Mohali, India. 2,3,4Electronics and Communication Engineering Department, Chandigarh Engineering College, Landran, Mohali, India. E-mail: [email protected], [email protected], [email protected], [email protected] Received: 14 March 2020 Revised and Accepted: 8 July 2020 ABSTRACT: The main objective of this paper is to represent a method for powering the electric car with a dynamo using wind energy. We want to solve the major disadvantage faced by an electric vehicle that is the discharge of the battery in case there is no power source. In case there is no power station nearby then electric vehicle can’t reach its desired destination. To solve this problem dynamo can be used. Dynamo is a device that converts mechanical energy into electric energy. Hence by using this property of a dynamo, this problem can be solved. The description of this technique is placing a dynamo behind the radiator and fan in front of the radiator. A hole is created at the centre of the radiator to connect the dynamo with the fan using a shaft. Due to locomotion of a car fan will rotate and current will be produced with the help of a dynamo. This technique has one more benefit that is efficiency of heat dissipation from the radiator will increase with the help of a fan. -

Monitoring Internal Combustion Engines by Neural Network Based Virtual Sensing
Monitoring Internal Combustion Engines by Neural Network Based Virtual Sensing R.J.Howlett, M.M.de Zoysa, S.D.Walters Transfrontier Centre for Automotive Research (TCAR), Engineering Research Centre, University of Brighton, Brighton, U.K. Email [email protected] Abstract Over the past two decades the manufacturers of internal-combustion engines that are used in motor vehicles have been very successful in reducing the harmful side-effects of their products on the environment. However, they are under ever-increasing pressure to achieve further reductions in the quantities of polluting gases emitted by the engine, and a decrease in the amount of fuel consumed per kilometre. At the same time, vehicle characteristics that are desirable to the driver must not be compromised. Satisfying these diverse requirements requires precise engine control and comprehensive monitoring of the operational parameters of the power unit. Engines are highly price- sensitive, and it is desirable to achieve the increased level of measurement that is required for enhanced control without additional sensory devices. Thus, the indirect estimation of quantities of interest using virtual-sensor techniques, without direct measurement using dedicated sensors, is a research area with considerable potential. Intelligent-systems techniques, such as neural-networks, are attractive for application in this area because of their capabilities in pattern- recognition, signal analysis and interpretation. For this reason, the use of neural-networks in the monitoring and control of motor-vehicle engines is an area of research which is receiving increasing attention from both the academic and commercial research communities. A virtual-sensor technique, the Virtual Lambda Sensor, is described here which uses a neural-network for the estimation of air-fuel ratio in the engine. -

Emerson Replacement Motors
Emerson Replacement Motors Square Flange Pool And Spa Motors Category “S” SF Catalog Motor Length HP SF RPM Volt Freq Amps Number Frame Less Shaft Wgt Price Standard Efficient- Low Service Factor- Up-Rated- Switchless Design 6.5” Frame Diameter ¾ 1.27 3450 230/115 60 5.4/10.8 EB852 56Y 11.24 22 298.00 1 1.25 3450 230/115 60 7/14 EB853 56Y 11.74 25 340.00 1½ 1.10 3450 230/115 60 7.7/15.4 EB854 56Y 11.74 26 396.00 2 1.10 3450 230/115 60 10.8/21.6 EB859 56Y 12.99 33 508.00 2½ 1.04 3450 230 60 11.5 EB840 56Y 12.74 33 626.00 SF Catalog Motor Motor HP SF RPM Volt Freq Amps Number Frame Length Wgt Price Standard Efficient- Low Service Factor- Up-Rated- Switch Type 5.5” Frame Diameter ½ 1.30 3450 230/115 60 4.1/8.2 EUSQ1052/SQD5UP1 48Y 9.5 19 285.00 ¾ 1.27 3450 230/115 60 5.9/11.8 EUSQ1072/SQD7UP1 48Y 10.28 22 298.00 1 1.25 3450 230/115 60 7.4/14.8 EUSQ1102/SQD10UP1 48Y 10.78 24 340.00 1½ 1.10 3450 230/115 60 8.8/17.6 EUSQ1152/SQD15UP1 48Y 11.78 29 396.00 2 1.10 3450 230/115 60 9.2/18.4 EUSQ1202/SQD20UP1 48Y 12.28 33 508.00 . C-Flange Pool And Spa Motors Category “C” and “J” SF Catalog Motor Length HP SF RPM Volt Freq Amps Number Frame Less Shaft Wgt Price Standard Efficient- Low Service Factor- Up-Rated- Switchless Design 6.5” Frame Diameter ¾ 1.00 3450 230/115 60 4.4/8.8 EB227 56J 10.27 21 290.00 1 1.00 3450 230/115 60 6/12 EB228 56J 10.77 24 324.00 1½ 1.00 3450 230/115 60 7/14 EB229 56J 10.77 25 367.00 2 1.00 3450 230/115 60 9/18 EB230 56J 12.02 31 506.00 2½ 1.00 3450 230 60 10.5 EB231 56J 11.77 33 605.00 Standard Efficient- Low Service Factor- Up-Rated- Switch Type 5.5” Frame Diameter ¾ 1.00 3450 230/115 60 5.9/11.8 EUST1072/JD75UP1 56J 10.44 18 290.00 1 1.00 3450 230/115 60 6.8/13.6 EUST1102/JD10UP1 56J 11.19 19 324.00 1½ 1.00 3450 230/115 60 8.7/17.4 EUST1152/JD15UP1 56J 11.44 24 367.00 2 1.00 3450 230/115 60 9.2/18.4 EUST1202/JD20UP1 56J 11.94 28 506.00 Polaris Pool Sweep Pump- New Style ¾ 1.50 3450 115/230 60 12.8/6.0 EB625 56C 14.00 25 370.00 22-1 Emerson Replacement Motors Continued . -

AVL Consumption Measurement Systems
AVL Consumption Measurement Systems Integrated Consumption Testing Solutions from Engine Testbed up to On-Road Application and Flow Measurement for Component Testing AVL Consumption Measurement Systems YOUR BENEFITS MARKET REQUIREMENTS AVL APPROACH • Shorter time needed to achieve development targets due to reliable AVL More stringent laws and regulations with regard to The call for higher test bed efficiency does not only More than 50 years of know-how in the field of con- consumption measurement systems, ensuring high levels of engine test bed CO2 and fuel consumption reductions in combination mean an easy installation and quick commission- sumption measurement technology, clever modular availability. with rapidly growing measurement costs are rais- ing procedure for the measurement system; it also product concepts in combination with a global ing the pressure on OEMs to develop engines even means a reliable fuel supply for the engine with pre- presence, sophisticated service and system compe- • Substantially reducing testing effort by means of shorter measurement faster. Development engineers of diesel and gasoline selected parameters, such as fuel temperature and tences make AVL the market leader in the field of times and high levels of measurement accuracy (for example, the reduc- engines are increasingly forced to implement mea- pressure. Highly precise fuel temperature control is consumption measurement. tion of the measurement effort during automatic engine calibration). surements in automatic operation with ever shorter required to achieve high measurement accuracy in measurement times, or in transient modes. the overall system at the engine test bed, even in • Protection of investments through modular design: Easy subsequent ex- case of low fuel consumption values. -

Dynamo Or Magneto-Electric Ma Chine. No
(Model.) 2. Sheets-Sheet i. C. E. BALL Dynamo or Magneto-Electric Ma Chine. No. 238,631. Patented March 8, 1881. Sir - Z “ZZZZZZZZZZZZZ ZO m/ITNESSES. JNVENTOR, 4 TTORNEY: N, PETERS. PHOTO-THOGRAPHER, was lingtoN. O. C. - - (Model.) 2. Sheets-Sheet 2, C. E. BALL Dynamo or Magneto-Electric Machine. No. 238,631. Patented March 8, 1881. MITWESSES. IWYENTOR, 4/26.4%rver- a 6. 322 1427, 72-7---Y, 4 roRVE3 N.PETER8, Pioto-liographER. WashiGTON, d. c. UNITED STATES PATENT OFFICE. CHARLES E. BALL, OF PHILADELPHIA, PEN NSYLVANIA. DYNAMO OR MAGNETO ELECTRIC MACH NE. SPECIFICATION forming part of Letters Patent No. 238,681, dated March 8, 1881. Application filed November 18, 1880. (Model.) To all chon it may concern: the armatures between the opposite poles of Be it known that I, CHARLES E. BALL, a the same magnet, as is usual, I arrange them citizen of the United States, residing at the to rotate between unlike poles of two or more city of Philadelphia, in the county of Philadel field-magnets, and preferably in opposite di 55 phia and State of Pennsylvania, have invented rections. Each of the field-magnets has its new and useful Improvements in Dynamo or poles opposed to two armatures, while, con Magneto Electric Machines, of which the fol versely, each armature rotates within the in lowing is a specification, reference being had fluence of the opposing poles, respectively, of to the accompanying drawings, wherein two field-magnets, and hence I obtain two O Figure 1 is a plan of a (ly namo or magneto sepalate and (listinct coln stant currents from electric machine, composed of two field-mag as may allnatures. -

Battery Charged Power Cycle
International Journal of Scientific & Engineering Research Volume 9, Issue 5, May-2018 ISSN 2229-5518 109 BATTERY CHARGED POWER CYCLE Nitin madhavi1, Mayuresh Shirke2,Prayag Kharpade3, Mustaq Shaikh4, Prof. Ashish Bandewar5 1Student, Saraswati college of engineering,India, [email protected] 2Student, Saraswati college of engineering,India, [email protected] 3Student, Saraswati college of engineering,India, [email protected] 4Student, Saraswati college of engineering,India, [email protected] 5Professor, Saraswati college of engineering,India, [email protected] . Abstract: This paper presents the development of an Keywords: BLDC Motor, Dynamo, Throttle, Circuit, associate degree, “Electric Bicycle System” with an Lead-acid Batteries. innovative approach. The aim of this paper is to show that the normal bi-cycle can be upgraded to electric one by some means– that including the development of a regenerative braking system and innovative BLDC motor control – but also uses real- time sensing and the powers of crowd sourcing to improve the cycling experience; get IJSERIntroduction: When thinking of possible senior more people riding bikes; and to aid in the design and projects, we all decided that we wanted to do development of cities. Electric bikes have simultaneously something that would somehow be beneficial to the gained popularity in many regions of the world and some planet. We decided that the electric bicycle would be have suggested that it could provide an even higher level of service compared to existing systems. There are several the best fit. The electric bicycle offers a cleaner challenges that are related electric cycle design: electric- alternative to travel short-to-moderate distances assisted range, recharging protocol and battery checkout rather than driving a gasoline-powered car. -

Download Paper (1.05
Paper ID #18466 Education through Applied Learning and Hands-on Practical Experience with Flex Fuel Vehicles Dr. Hazem Tawfik, State University of New York, Farmingdale Prof. Tawfik obtained his Ph.D. in Mechanical Engineering, from University of Waterloo, Ontario, Canada. He has held a number of industrial & academic positions and affiliations with organizations that included Brookhaven National Laboratory (BNL), Rensselaer Polytechnic Institute (RPI), Stony Brook University (SBU), Massachusetts Institute of Technology (MIT), Atomic Energy of Canada Inc., Ontario Hydro, NASA Kennedy, NASA Marshall Space Flight Centers, and the U.S. Naval Surface Warfare Cen- ter at Carderock, Md. Dr. Tawfik is the co-author of more than 60 research papers in the areas of Hydrogen Fuel Cells, Biomass Energy, Thermo- fluids and Two Phase Flow published in prestigious peer reviewed journals and conference symposiums. He holds numerous research awards and owns the rights to four patents in the Polymer Electrolyte Membrane (PEM) fuel cells area. Currently, Dr. Tawfik is a SUNY Distinguished Service Professor and the Director of the Institute for Research and Technology Transfer (IRTT) at Farmingdale State College of the State University of New York. Dr. Yeong Ryu, State University of New York, Farmingdale YEONG S. RYU graduated from Columbia University with a Ph.D. and Master of Philosophy in Mechan- ical Engineering in 1994. He has served as an associate professor of Mechanical Engineering Technology at Farmingdale State College (SUNY) since 2006. In addition, he has conducted various research projects at Xerox Corporation (1994-1995), Hyundai Motor Corporation (1995-1997), and New Jersey Institute of Technology (2001-2003). -

Martinlogan Dynamo Subwoofer
TMD YNAM OTM user’s manual M A RTI N L O G A N ® the loudspeaker technology company CONTENTS Contents . .2 Room Acoustics . .15 Installation in Brief . .3 Your Room Introduction. .4 Terminology About the Controls . .5 Solid Footing . 16 Connections and Control Settings . .6 Home Theater . .17 Before Connecting the Dynamo Frequently Asked Questions & Troubleshooting. .18 2-Channel Mode General Information . .19 Multi-Channel Mode . 7 Specifications 2-Channel/Multi-Channel Mode . 8 Warranty and Registration 2-Channel Using Speaker Level Inputs . 9 Service 2-Channel Mode With 2-Channel Output. 10 Glossary of Audio Terms . .20 Sub Out—Using Multiple Dynamos . 11 Notes . .22 AC Power Connection . 12 Replacing the Fuse Break-In Placement . .13 Listening Position Ask Your Dealer Enjoy Yourself Installing Dynamo in a Cabinet . 14 2 Contents INSTALLATION IN BRIEF We know that you are eager to hear your new Dynamo sub- Step 1: Unpacking woofer, so this section is provided to allow fast and easy set Remove your new Dynamo subwoofer from its packing. up. Once you have it operational, please take the time to Please note, Dynamo's grill cover should not be used read, in depth, the rest of the information in this manual. in the standard down firing configuration. The grill It will give you perspective on how to attain the greatest cover is supplied for use while the Dynamo is ori- possible performance from this most exacting woofer system. entated in the optional front firing configuration (see page 14). If you experience any difficulties in setup or operation of the Dynamo, please refer to the Placement, Room Acoustics Step 2: Placement and Connections and Control Settings sections.