Audio Signal Representations for Indexing in the Transform Domain Emmanuel Ravelli, Gael Richard, Laurent Daudet
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download Media Player Codec Pack Version 4.1 Media Player Codec Pack
download media player codec pack version 4.1 Media Player Codec Pack. Description: In Microsoft Windows 10 it is not possible to set all file associations using an installer. Microsoft chose to block changes of file associations with the introduction of their Zune players. Third party codecs are also blocked in some instances, preventing some files from playing in the Zune players. A simple workaround for this problem is to switch playback of video and music files to Windows Media Player manually. In start menu click on the "Settings". In the "Windows Settings" window click on "System". On the "System" pane click on "Default apps". On the "Choose default applications" pane click on "Films & TV" under "Video Player". On the "Choose an application" pop up menu click on "Windows Media Player" to set Windows Media Player as the default player for video files. Footnote: The same method can be used to apply file associations for music, by simply clicking on "Groove Music" under "Media Player" instead of changing Video Player in step 4. Media Player Codec Pack Plus. Codec's Explained: A codec is a piece of software on either a device or computer capable of encoding and/or decoding video and/or audio data from files, streams and broadcasts. The word Codec is a portmanteau of ' co mpressor- dec ompressor' Compression types that you will be able to play include: x264 | x265 | h.265 | HEVC | 10bit x265 | 10bit x264 | AVCHD | AVC DivX | XviD | MP4 | MPEG4 | MPEG2 and many more. File types you will be able to play include: .bdmv | .evo | .hevc | .mkv | .avi | .flv | .webm | .mp4 | .m4v | .m4a | .ts | .ogm .ac3 | .dts | .alac | .flac | .ape | .aac | .ogg | .ofr | .mpc | .3gp and many more. -

Megui) Recommended Fix: Download Here
Join Forum | Login | Today's Posts | Tutorials | Windows 10 Forum | Windows 8 Forum Windows 7 Help Forums Windows 7 help and support Tutorials » Windows 7: Video Encoding x264 (MeGUI) Recommended Fix: Download Here Page 1 of 3 1 2 3 > Video Encoding (Using MeGUI x264 Encoder) MeGUI x264 Video Encoding Published by Wishmaster 15 Aug 2010 --How to Setup & Encode Content with MeGUI x264 Published by Encoder-- This tutorial will show you how to use MeGUI to create a MP4 or MKV file for your Media Center collection, from your legally owned DVD collection. Wishmaster I will not cover how to decrypt. This tutorial will be in 2 parts: Part 1: Installing,setting up,and configuring everything needed as well as the configuring the encoder itself. Part 2: The actual encoding process. Theres alot of info. to cover so lets get started. Step 1: The Essential Tools & Utilities 1) Shark007's Codec pack (optional) If you plan on using WMC for playback, and wish to use FFDshow as the decoder, you will need the 64bit add on as well. However, for the purposes of MeGUI, only the 32bit package is needed. [Please Note] You do not actually need any 3rd party Codecs such as FFDShow or Sharks codec pack. Both DVD and BluRay can be indexed and encoded with built in codecs. Extracting BluRay video streams to MKV format is the easiest way to work with them. You will need Haali splitter for these MKVs but if using Shark007s package, it is included.. You will need it only if you decide not to use this codec package. -

Ardour Export Redesign
Ardour Export Redesign Thorsten Wilms [email protected] Revision 2 2007-07-17 Table of Contents 1 Introduction 4 4.5 Endianness 8 2 Insights From a Survey 4 4.6 Channel Count 8 2.1 Export When? 4 4.7 Mapping Channels 8 2.2 Channel Count 4 4.8 CD Marker Files 9 2.3 Requested File Types 5 4.9 Trimming 9 2.4 Sample Formats and Rates in Use 5 4.10 Filename Conflicts 9 2.5 Wish List 5 4.11 Peaks 10 2.5.1 More than one format at once 5 4.12 Blocking JACK 10 2.5.2 Files per Track / Bus 5 4.13 Does it have to be a dialog? 10 2.5.3 Optionally store timestamps 5 5 Track Export 11 2.6 General Problems 6 6 MIDI 12 3 Feature Requests 6 7 Steps After Exporting 12 3.1 Multichannel 6 7.1 Normalize 12 3.2 Individual Files 6 7.2 Trim silence 13 3.3 Realtime Export 6 7.3 Encode 13 3.4 Range ad File Export History 7 7.4 Tag 13 3.5 Running a Script 7 7.5 Upload 13 3.6 Export Markers as Text 7 7.6 Burn CD / DVD 13 4 The Current Dialog 7 7.7 Backup / Archiving 14 4.1 Time Span Selection 7 7.8 Authoring 14 4.2 Ranges 7 8 Container Formats 14 4.3 File vs Directory Selection 8 8.1 libsndfile, currently offered for Export 14 4.4 Container Types 8 8.2 libsndfile, also interesting 14 8.3 libsndfile, rather exotic 15 12 Specification 18 8.4 Interesting 15 12.1 Core 18 8.4.1 BWF – Broadcast Wave Format 15 12.2 Layout 18 8.4.2 Matroska 15 12.3 Presets 18 8.5 Problematic 15 12.4 Speed 18 8.6 Not of further interest 15 12.5 Time span 19 8.7 Check (Todo) 15 12.6 CD Marker Files 19 9 Encodings 16 12.7 Mapping 19 9.1 Libsndfile supported 16 12.8 Processing 19 9.2 Interesting 16 12.9 Container and Encodings 19 9.3 Problematic 16 12.10 Target Folder 20 9.4 Not of further interest 16 12.11 Filenames 20 10 Container / Encoding Combinations 17 12.12 Multiplication 20 11 Elements 17 12.13 Left out 21 11.1 Input 17 13 Credits 21 11.2 Output 17 14 Todo 22 1 Introduction 4 1 Introduction 2 Insights From a Survey The basic purpose of Ardour's export functionality is I conducted a quick survey on the Linux Audio Users to create mixdowns of multitrack arrangements. -
Installation Manual
CX-20 Installation manual ENABLING BRIGHT OUTCOMES Barco NV Beneluxpark 21, 8500 Kortrijk, Belgium www.barco.com/en/support www.barco.com Registered office: Barco NV President Kennedypark 35, 8500 Kortrijk, Belgium www.barco.com/en/support www.barco.com Copyright © All rights reserved. No part of this document may be copied, reproduced or translated. It shall not otherwise be recorded, transmitted or stored in a retrieval system without the prior written consent of Barco. Trademarks Brand and product names mentioned in this manual may be trademarks, registered trademarks or copyrights of their respective holders. All brand and product names mentioned in this manual serve as comments or examples and are not to be understood as advertising for the products or their manufacturers. Trademarks USB Type-CTM and USB-CTM are trademarks of USB Implementers Forum. HDMI Trademark Notice The terms HDMI, HDMI High Definition Multimedia Interface, and the HDMI Logo are trademarks or registered trademarks of HDMI Licensing Administrator, Inc. Product Security Incident Response As a global technology leader, Barco is committed to deliver secure solutions and services to our customers, while protecting Barco’s intellectual property. When product security concerns are received, the product security incident response process will be triggered immediately. To address specific security concerns or to report security issues with Barco products, please inform us via contact details mentioned on https://www.barco.com/psirt. To protect our customers, Barco does not publically disclose or confirm security vulnerabilities until Barco has conducted an analysis of the product and issued fixes and/or mitigations. Patent protection Please refer to www.barco.com/about-barco/legal/patents Guarantee and Compensation Barco provides a guarantee relating to perfect manufacturing as part of the legally stipulated terms of guarantee. -

Ffmpeg Documentation Table of Contents
ffmpeg Documentation Table of Contents 1 Synopsis 2 Description 3 Detailed description 3.1 Filtering 3.1.1 Simple filtergraphs 3.1.2 Complex filtergraphs 3.2 Stream copy 4 Stream selection 5 Options 5.1 Stream specifiers 5.2 Generic options 5.3 AVOptions 5.4 Main options 5.5 Video Options 5.6 Advanced Video options 5.7 Audio Options 5.8 Advanced Audio options 5.9 Subtitle options 5.10 Advanced Subtitle options 5.11 Advanced options 5.12 Preset files 6 Tips 7 Examples 7.1 Preset files 7.2 Video and Audio grabbing 7.3 X11 grabbing 7.4 Video and Audio file format conversion 8 Syntax 8.1 Quoting and escaping 8.1.1 Examples 8.2 Date 8.3 Time duration 8.3.1 Examples 8.4 Video size 8.5 Video rate 8.6 Ratio 8.7 Color 8.8 Channel Layout 9 Expression Evaluation 10 OpenCL Options 11 Codec Options 12 Decoders 13 Video Decoders 13.1 rawvideo 13.1.1 Options 14 Audio Decoders 14.1 ac3 14.1.1 AC-3 Decoder Options 14.2 ffwavesynth 14.3 libcelt 14.4 libgsm 14.5 libilbc 14.5.1 Options 14.6 libopencore-amrnb 14.7 libopencore-amrwb 14.8 libopus 15 Subtitles Decoders 15.1 dvdsub 15.1.1 Options 15.2 libzvbi-teletext 15.2.1 Options 16 Encoders 17 Audio Encoders 17.1 aac 17.1.1 Options 17.2 ac3 and ac3_fixed 17.2.1 AC-3 Metadata 17.2.1.1 Metadata Control Options 17.2.1.2 Downmix Levels 17.2.1.3 Audio Production Information 17.2.1.4 Other Metadata Options 17.2.2 Extended Bitstream Information 17.2.2.1 Extended Bitstream Information - Part 1 17.2.2.2 Extended Bitstream Information - Part 2 17.2.3 Other AC-3 Encoding Options 17.2.4 Floating-Point-Only AC-3 Encoding -

Important Notice Regarding Software
Important Notice Regarding Software The software package installed in this product includes software licensed to Onkyo & Pioneer Corporation (hereinafter, called “O&P Corporation”) directly or indirectly by third party developers. Please be sure to read this notice regarding such software. Notice Regarding GNU GPL/LGPL-applicable Software This product includes the following software that is covered by GNU General Public License (hereinafter, called "GPL") or by GNU Lesser General Public License (hereinafter, called "LGPL"). O&P Corporation notifies you that, according to the attached GPL/LGPL, you have right to obtain, modify, and redistribute software source code for the listed software. ソフトウェアに関する重要なお知らせ 本製品に搭載されるソフトウェアには、オンキヨー & パイオニア株式会社(以下「弊社」とします)が 第三者より直接的に又は間接的に使用の許諾を受けたソフトウェアが含まれております。これらのソフト ウェアに関する本お知らせを必ずご一読くださいますようお願い申し上げます。 GNU GPL / LGPL 適用ソフトウェアに関するお知らせ 本製品には、以下の GNU General Public License(以下「GPL」とします)または GNU Lesser General Public License(以下「LGPL」とします)の適用を受けるソフトウェアが含まれております。 お客様は添付の GPL/LGPL に従いこれらのソフトウェアソースコードの入手、改変、再配布の権利があ ることをお知らせいたします。 Package List パッケージリスト alsa-conf-base glibc-gconv alsa-conf glibc-gconv-utf-16 alsa-lib glib-networking alsa-utils-alsactl gstreamer1.0-libav alsa-utils-alsamixer gstreamer1.0-plugins-bad-aiff alsa-utils-amixer gstreamer1.0-plugins-bad-bluez alsa-utils-aplay gstreamer1.0-plugins-bad-faac avahi-autoipd gstreamer1.0-plugins-bad-mms base-files gstreamer1.0-plugins-bad-mpegtsdemux base-passwd gstreamer1.0-plugins-bad-mpg123 bluez5 gstreamer1.0-plugins-bad-opus busybox gstreamer1.0-plugins-bad-rawparse -

Ogg Audio Codec Download
Ogg audio codec download click here to download To obtain the source code, please see the xiph download page. To get set up to listen to Ogg Vorbis music, begin by selecting your operating system above. Check out the latest royalty-free audio codec from Xiph. To obtain the source code, please see the xiph download page. Ogg Vorbis is Vorbis is everywhere! Download music Music sites Donate today. Get Set Up To Listen: Windows. Playback: These DirectShow filters will let you play your Ogg Vorbis files in Windows Media Player, and other OggDropXPd: A graphical encoder for Vorbis. Download Ogg Vorbis Ogg Vorbis is a lossy audio codec which allows you to create and play Ogg Vorbis files using the command-line. The following end-user download links are provided for convenience: The www.doorway.ru DirectShow filters support playing of files encoded with Vorbis, Speex, Ogg Codecs for Windows, version , ; project page - for other. Vorbis Banner Xiph Banner. In our effort to bring Ogg: Media container. This is our native format and the recommended container for all Xiph codecs. Easy, fast, no torrents, no waiting, no surveys, % free, working www.doorway.ru Free Download Ogg Vorbis ACM Codec - A new audio compression codec. Ogg Codecs is a set of encoders and deocoders for Ogg Vorbis, Speex, Theora and FLAC. Once installed you will be able to play Vorbis. Ogg Vorbis MSACM Codec was added to www.doorway.ru by Bjarne (). Type: Freeware. Updated: Audiotags: , 0x Used to play digital music, such as MP3, VQF, AAC, and other digital audio formats. -

Command-Line Sound Editing Wednesday, December 7, 2016
21m.380 Music and Technology Recording Techniques & Audio Production Workshop: Command-line sound editing Wednesday, December 7, 2016 1 Student presentation (pa1) • 2 Subject evaluation 3 Group picture 4 Why edit sound on the command line? Figure 1. Graphical representation of sound • We are used to editing sound graphically. • But for many operations, we do not actually need to see the waveform! 4.1 Potential applications • • • • • • • • • • • • • • • • 1 of 11 21m.380 · Workshop: Command-line sound editing · Wed, 12/7/2016 4.2 Advantages • No visual belief system (what you hear is what you hear) • Faster (no need to load guis or waveforms) • Efficient batch-processing (applying editing sequence to multiple files) • Self-documenting (simply save an editing sequence to a script) • Imaginative (might give you different ideas of what’s possible) • Way cooler (let’s face it) © 4.3 Software packages On Debian-based gnu/Linux systems (e.g., Ubuntu), install any of the below packages via apt, e.g., sudo apt-get install mplayer. Program .deb package Function mplayer mplayer Play any media file Table 1. Command-line programs for sndfile-info sndfile-programs playing, converting, and editing me- Metadata retrieval dia files sndfile-convert sndfile-programs Bit depth conversion sndfile-resample samplerate-programs Resampling lame lame Mp3 encoder flac flac Flac encoder oggenc vorbis-tools Ogg Vorbis encoder ffmpeg ffmpeg Media conversion tool mencoder mencoder Media conversion tool sox sox Sound editor ecasound ecasound Sound editor 4.4 Real-world -
CSE-800 User Guide
ClickShare CSE-800 User guide ENABLING BRIGHT OUTCOMES Registered office: Barco NV President Kennedypark 35, 8500 Kortrijk, Belgium www.barco.com/en/support www.barco.com Barco NV Beneluxpark 21, 8500 Kortrijk, Belgium www.barco.com/en/support www.barco.com Barco ClickShare Product Specific End User License Agreement1 THIS PRODUCT SPECIFIC USER LICENSE AGREEMENT (EULA) TOGETHER WITH THE BARCO GENERAL EULA ATTACHED HERETO SET OUT THE TERMS OF USE OF THE SOFTWARE. PLEASE READ THIS DOCUMENT CAREFULLY BEFORE OPENING OR DOWNLOADING AND USING THE SOFTWARE. DO NOT ACCEPT THE LICENSE, AND DO NOT INSTALL, DOWNLOAD, ACCESS, OR OTHERWISE COPY OR USE ALL OR ANY PORTION OF THE SOFTWARE UNLESS YOU CAN AGREE WITH ITS TERMS AS SET OUT IN THIS LICENSE AGREEMENT. 1. Entitlement Barco ClickShare (the “Software”) offered as a wireless presentation solution that includes the respective software components as further detailed in the applicable Documentation. The Software can be used upon purchase from, and subject to payment of the relating purchase price to, a Barco authorized distributor or reseller of the ClickShare base unit and button or download of the authorized ClickShare applications (each a “Barco ClickShare Product”). • Term The Software can be used under the terms of this EULA from the date of first use of the Barco ClickShare Product, for as long as you operate such Barco ClickShare Product. • Deployment and Use The Software shall be used solely in association with a Barco ClickShare Product in accordance with the Documentation issued by Barco for such Product. 2. Support The Software is subject to the warranty conditions outlined in the Barco warranty rider. -
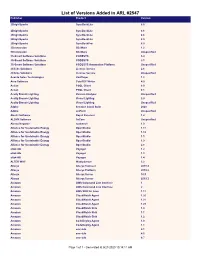
List of Versions Added in ARL #2547 Publisher Product Version
List of Versions Added in ARL #2547 Publisher Product Version 2BrightSparks SyncBackLite 8.5 2BrightSparks SyncBackLite 8.6 2BrightSparks SyncBackLite 8.8 2BrightSparks SyncBackLite 8.9 2BrightSparks SyncBackPro 5.9 3Dconnexion 3DxWare 1.2 3Dconnexion 3DxWare Unspecified 3S-Smart Software Solutions CODESYS 3.4 3S-Smart Software Solutions CODESYS 3.5 3S-Smart Software Solutions CODESYS Automation Platform Unspecified 4Clicks Solutions License Service 2.6 4Clicks Solutions License Service Unspecified Acarda Sales Technologies VoxPlayer 1.2 Acro Software CutePDF Writer 4.0 Actian PSQL Client 8.0 Actian PSQL Client 8.1 Acuity Brands Lighting Version Analyzer Unspecified Acuity Brands Lighting Visual Lighting 2.0 Acuity Brands Lighting Visual Lighting Unspecified Adobe Creative Cloud Suite 2020 Adobe JetForm Unspecified Alastri Software Rapid Reserver 1.4 ALDYN Software SvCom Unspecified Alexey Kopytov sysbench 1.0 Alliance for Sustainable Energy OpenStudio 1.11 Alliance for Sustainable Energy OpenStudio 1.12 Alliance for Sustainable Energy OpenStudio 1.5 Alliance for Sustainable Energy OpenStudio 1.9 Alliance for Sustainable Energy OpenStudio 2.8 alta4 AG Voyager 1.2 alta4 AG Voyager 1.3 alta4 AG Voyager 1.4 ALTER WAY WampServer 3.2 Alteryx Alteryx Connect 2019.4 Alteryx Alteryx Platform 2019.2 Alteryx Alteryx Server 10.5 Alteryx Alteryx Server 2019.3 Amazon AWS Command Line Interface 1 Amazon AWS Command Line Interface 2 Amazon AWS SDK for Java 1.11 Amazon CloudWatch Agent 1.20 Amazon CloudWatch Agent 1.21 Amazon CloudWatch Agent 1.23 Amazon -

Forcepoint DLP Supported File Formats and Size Limits
Forcepoint DLP Supported File Formats and Size Limits Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 This article provides a list of the file formats that can be analyzed by Forcepoint DLP, file formats from which content and meta data can be extracted, and the file size limits for network, endpoint, and discovery functions. See: ● Supported File Formats ● File Size Limits © 2021 Forcepoint LLC Supported File Formats Supported File Formats and Size Limits | Forcepoint DLP | v8.8.1 The following tables lists the file formats supported by Forcepoint DLP. File formats are in alphabetical order by format group. ● Archive For mats, page 3 ● Backup Formats, page 7 ● Business Intelligence (BI) and Analysis Formats, page 8 ● Computer-Aided Design Formats, page 9 ● Cryptography Formats, page 12 ● Database Formats, page 14 ● Desktop publishing formats, page 16 ● eBook/Audio book formats, page 17 ● Executable formats, page 18 ● Font formats, page 20 ● Graphics formats - general, page 21 ● Graphics formats - vector graphics, page 26 ● Library formats, page 29 ● Log formats, page 30 ● Mail formats, page 31 ● Multimedia formats, page 32 ● Object formats, page 37 ● Presentation formats, page 38 ● Project management formats, page 40 ● Spreadsheet formats, page 41 ● Text and markup formats, page 43 ● Word processing formats, page 45 ● Miscellaneous formats, page 53 Supported file formats are added and updated frequently. Key to support tables Symbol Description Y The format is supported N The format is not supported P Partial metadata -

Cd Ripping Guide
CD RIPPING GUIDE for an average user Nikola Kasic Ver.7.0, March 2007 INTRODUCTION The time has come for me to rip my CD collection and put it on my home server. Actually, I tried to do it an year ago and was hit by the complexity of the subject and postponed it for some later time. I simply wasn't ready to dig deeply enough to master offsets, cue sheets, gaps and other issues. I thought it's just a matter of putting CD in the drive, choose file format and click button, and being overwhelmed with technical issues/choices I just gave up, being scared that if I make a wrong choice I'll have to re-rip all my collection later again. I don't consider myself an audiophile. My CD collection is about 150-200 CDs and I don't spend too much time listening music from CDs. My hi-fi (home theater) equipment is decent, but doesn't cost a fortune and has a dedicated room. However, it's good enough to make it easily noticeable when CD has errors, or music is ripped at low bitrate. Therefore, I prefer that equipment is limiting factor when enjoying music, rather then the music source quality. My main reason for moving music from CDs to files might sound strange. I had DVD jukebox (Sony, 200 places) which I was filling with CDs and only a few DVDs and really enjoyed not having to deal with CDs and cases all over the place. They were protected from kids and I had photo album with sleeves where I was storing CD covers, so it was easy to find disc number in jukebox.