Object Manipulation from Simplified Visual Cues
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Midwest Flow Fest Workshop Descriptions!
Ping Tom Memorial Park Chicago, IL Saturday, September 9 Area 1 Area 2 Area 3 Area 4 FREE! Intro Contact Mini Hoop Technicality VTG 1:1 with Fans Tutting for Flow Art- 11am Jay Jay Kassandra Morrison Jessica Mardini Dushwam Fancy Feet FREE! Poi Basics Performance 101 No Beat Tosses 12:30pm Perkulator Jessie Wags Matt O’Daniel Zack Lyttle FREE! Intro to Fans Better Body Rolls Clowning Around Down & Dirty- 2pm Jessica Mardini Jacquie Tar-foot Jared the Juggler Groundwork- Jay Jay Acro Staff 101 Buugeng Fundamentals Modern Dance Hoop Flowers Shapes & Hand 3:30pm Admiral J Brown Kimberly Bucki FREE! Fearless Ringleader Paths- Dushwam Inclusive Community Swap Tosses 3 Hoop Manipulation Tosses with Doubles 5pm Jessica Mardini FREE! Zack Lyttle Kassandra Morrison Exuro 6:30pm MidWest Flow Fest Instructor Showcase Sunday, September 10 Area 1 Area 2 Area 3 Area 4 Contact Poi 1- Intro Intro to Circle Juggle Beginner Pole Basics Making Organic 11am Matt O’Daniel FREE! Juan Guardiola Alice Wonder Sequences - Exuro Intermediate Buugeng FREE! HoopDance 101 Contact Poi 2- Full Performance Pro Tips 12:30pm Kimberly Buck Casandra Tanenbaum Contact- Matt O’Daniel Fearless Ringleader FREE! Body Balance Row Pray Fishtails Lazy Hooping Juggling 5 Ball 2pm Jacqui Tar-Foot Admiral J Brown Perkulator Jared the Juggler 3:30pm Body Roll Play FREE! Fundamentals: Admiral’s Way Contact Your Prop, Your Kassandra Morrison Reels- Dushwam Admiral J Brown Dance- Jessie Wags 5pm FREE! Cultivating Continuous Poi Tosses Flow Style & Personality Musicality in Motion Community- Exuro Juan Guardiola Casandra Tanenbaum Jacquie Tar-Foot 6:30pm MidWest Flow Fest Jam! poi dance/aerial staff any/all props juggling/other hoop Sponsored By: Admiral J. -

In-Jest-Study-Guide
with Nels Ross “The Inspirational Oddball” . Study Guide ABOUT THE PRESENTER Nels Ross is an acclaimed performer and speaker who has won the hearts of international audiences. Applying his diverse background in performing arts and education, Nels works solo and with others to present school assemblies and programs which blend physical theater, variety arts, humor, and inspiration… All “in jest,” or in fun! ABOUT THE PROGRAM In Jest school assemblies and programs are based on the underlying principle that every person has value. Whether highlighting character, healthy choices, science & math, reading, or another theme, Nels employs physical theater and participation to engage the audience, juggling and other variety arts to teach the concepts, and humor to make it both fun and memorable. GOALS AND OBJECTIVES This program will enhance awareness and appreciation of physical theater and variety arts. In addition, the activities below provide connections to learning standards and the chosen theme. (What theme? Ask your artsineducation or assembly coordinator which specific program is coming to your school, and see InJest.com/schoolassemblyprograms for the latest description.) GETTING READY FOR THE PROGRAM ● Arrange for a clean, well lit SPACE, adjusting lights in advance as needed. Nels brings his own sound system, and requests ACCESS 4560 minutes before & after for set up & take down. ● Make announcements the day before to remind students and staff. For example: “Tomorrow we will have an exciting program with Nels Ross from In Jest. Be prepared to enjoy humor, juggling, and stunts in this uplifting celebration!” ● Discuss things which students might see and terms which they might not know: Physical Theater.. -

Flexible Object Manipulation
Dartmouth College Dartmouth Digital Commons Dartmouth College Ph.D Dissertations Theses, Dissertations, and Graduate Essays 2-1-2010 Flexible Object Manipulation Matthew P. Bell Dartmouth College Follow this and additional works at: https://digitalcommons.dartmouth.edu/dissertations Part of the Computer Sciences Commons Recommended Citation Bell, Matthew P., "Flexible Object Manipulation" (2010). Dartmouth College Ph.D Dissertations. 28. https://digitalcommons.dartmouth.edu/dissertations/28 This Thesis (Ph.D.) is brought to you for free and open access by the Theses, Dissertations, and Graduate Essays at Dartmouth Digital Commons. It has been accepted for inclusion in Dartmouth College Ph.D Dissertations by an authorized administrator of Dartmouth Digital Commons. For more information, please contact [email protected]. FLEXIBLE OBJECT MANIPULATION A Thesis Submitted to the Faculty in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Computer Science by Matthew Bell DARTMOUTH COLLEGE Hanover, New Hampshire February 2010 Dartmouth Computer Science Technical Report TR2010-663 Examining Committee: (chair) Devin Balkcom Scot Drysdale Tanzeem Choudhury Daniela Rus Brian W. Pogue, Ph.D. Dean of Graduate Studies Abstract Flexible objects are a challenge to manipulate. Their motions are hard to predict, and the high number of degrees of freedom makes sensing, control, and planning difficult. Additionally, they have more complex friction and contact issues than rigid bodies, and they may stretch and compress. In this thesis, I explore two major types of flexible materials: cloth and string. For rigid bodies, one of the most basic problems in manipulation is the development of immo- bilizing grasps. The same problem exists for flexible objects. -

Contact Juggling of a Disk with a Disk-Shaped Manipulator
Received September 19, 2018, accepted September 29, 2018, date of publication October 12, 2018, date of current version November 8, 2018. Digital Object Identifier 10.1109/ACCESS.2018.2875410 Contact Juggling of a Disk With a Disk-Shaped Manipulator JI-CHUL RYU 1, (Member, IEEE), AND KEVIN M. LYNCH2, (Fellow, IEEE) 1Mechanical Engineering Department, Northern Illinois University, DeKalb, IL 60115, USA 2Neuroscience and Robotics Laboratory and Mechanical Engineering Department, Northwestern University, Evanston, IL 60208, USA Corresponding author: Ji-Chul Ryu ([email protected]) Part of this work was supported by NSF under Grant IIS-0964665. ABSTRACT In this paper, we present a feedback controller that enables contact juggling manipulation of a disk with a disk-shaped manipulator, called the mobile disk-on-disk. The system consists of two disks in which the upper disk (object) is free to roll on the lower disk (hand) under the influence of gravity. The hand moves with a full three degrees of freedom in a vertical plane. The proposed controller drives the object to follow a desired trajectory through rolling interaction with the hand. Based on the mathematical model of the system, dynamic feedback linearization is used in the design of the controller. The performance of the controller is demonstrated through simulations considering disturbances and uncertainties. INDEX TERMS Dynamic feedback linearization, nonprehensile manipulation, rolling manipulation, contact juggling. I. INTRODUCTION In this paper, the problem is simplified to a disk-shaped Manipulation is generally about moving an object from one object with a disk-shaped manipulator. This paper builds place to another. Methods to manipulate objects broadly fall on our previous work [5] on a rolling manipulation system into two categories: prehensile and nonprehensile. -

Mntr School Brochure Web
NONPROFIT ORG. U.S. Postage Paid Covington, KY Permit N. 258 My Nose Turns Red Theatre Company P.O. Box 120307 Covington, KY 41012 Return service requested Circus teaches all of the necessary physical literacy skills that children need to master for a lifetime of fitness. Bring My Nose Turns Red Youth Circus for an in-school performance / demonstration and follow it up with a day of skill workshops in juggling, balance and object manipulation. Our coaches will help your students walk across the wire, rock in the gym wheel, stand on the globe and balance on the rola bola, do hula hooping tricks, diabolo and the basics of juggling. www.mynoseturnsred.org and dexterity, object manipulation, hand-eye coordination hand-eye manipulation, object dexterity, and ance al B About l l A In-School Performances, Workshops, Residencies and Fundraisers In-School Performances Bring All About Balance to your school for an in-school performance / demonstration. Delight your students with a fast-paced 45-minute performance of balancing objects, wire-walking, juggling, unicycling and rolling on the gym wheel. Includes plenty of audience participation to keep your students fascinated and ready to participate. One-Day Residencies In addition to the performance of All About Balance, circus skill workshops can be set up as part of your physical education classes giving students the opportunity to learn age-appropriate circus skills. Skills include juggling, wire-walking, stilts, rolling globe, rola bola, hooping, diabolo and gym wheel. One-Week Residencies Learn circus skills, create clown characters and put on a show for the school community. -

Feedback from HTC Vive Sensors Results in Transient Performance Enhancements on a Juggling Task in Virtual Reality
sensors Article Feedback from HTC Vive Sensors Results in Transient Performance Enhancements on a Juggling Task in Virtual Reality Filip Borglund 1,†, Michael Young 1,† , Joakim Eriksson 1 and Anders Rasmussen 2,3,* 1 Virtual Reality Laboratory, Design Sciences, Faculty of Engineering, Lund University, 221 00 Lund, Sweden; fi[email protected] (F.B.); [email protected] (M.Y.); [email protected] (J.E.) 2 Department of Neuroscience, Erasmus University Medical Center, 3000 DR Rotterdam, The Netherlands 3 Associative Learning, Department of Experimental Medical Science, Medical Faculty, Lund University, 221 00 Lund, Sweden * Correspondence: [email protected]; Tel.: +46-(0)-709746609 † Filip Borglund and Michael Young contributed equally. Abstract: Virtual reality headsets, such as the HTC Vive, can be used to model objects, forces, and interactions between objects with high perceived realism and accuracy. Moreover, they can accurately track movements of the head and the hands. This combination makes it possible to provide subjects with precise quantitative feedback on their performance while they are learning a motor task. Juggling is a challenging motor task that requires precise coordination of both hands. Professional jugglers throw objects so that the arc peaks just above head height, and they time their throws so that the second ball is thrown when the first ball reaches its peak. Here, we examined whether it is possible to learn to juggle in virtual reality and whether the height and the timing of the throws can be improved by providing immediate feedback derived from the motion sensors. Almost all participants became better at juggling in the ~30 min session: the height and timing of their throws Citation: Borglund, F.; Young, M.; improved and they dropped fewer balls. -

It's a Circus!
Life? It’s A Circus! Teacher Resource Pack INTRODUCTION Unlike many other forms of entertainment, such as theatre, ballet, opera, vaudeville, movies and television, the history of circus history is not widely known. The most popular misconception is that modern circus dates back to Roman times. But the Roman “circus” was, in fact, the precursor of modern horse racing (the Circus Maximus was a racetrack). The only common denominator between Roman and modern circuses is the word circus which, in Latin as in English, means "circle". Circus has undergone something of a revival in recent decades, becoming a theatrical experience with spectacular costumes, elaborate lighting and soundtracks through the work of the companies such as Circus Oz and Cirque du Soleil. But the more traditional circus, touring between cities and regional areas, performing under the big top and providing a more prosaic experience for families, still continues. The acts featured in these, usually family-run, circuses are generally consistent from circus to circus, with acrobatics, balance, juggling and clowning being the central skillsets featured, along with horsemanship, trapeze and tightrope work. The circus that modern audiences know and love owes much of its popularity to film and literature, and the showmanship of circus entrepreneurs such as P.T. Barnum in the mid 1800s and bears little resemblance to its humble beginnings in the 18th century. These notes are designed to give you a concise resource to use with your class and to support their experience of seeing Life? It’s a Circus! CLASSROOM CONTENT AND CURRICULUM LINKS Essential Learnings: The Arts (Drama, Dance) Health and Physical Education (Personal Development) Style/Form: Circus Theatre Physical Theatre Mime Clowning Themes and Contexts: Examination of the circus style/form and performance techniques, adolescence, resilience, relationships General Capabilities: Personal and Social Competence, Critical and Creative Thinking, Ethical Behaviour © 2016 Deirdre Marshall for Homunculus Theatre Co. -

Teachers Study Guide
MARK NIZER in cooperation with Lincoln Center for the Performing Arts PRESENTS: Students Study Guide http://nizer.com Produced by Mark Nizer for Lincoln Center for the Performing Arts ©1995-2003 INTRODUCTION “Do you think juggling’s a mere trick?” the little man asked, sounding wounded. “An amusement for the gapers? A means of picking up a crown or two at a provincial carnival? It is all those things, yes, but first it is a way of life, a friend, a creed, a species of worship.” “And a kind of poetry,” said Carabella. Sleet nodded. “Yes, that too. And a mathematics. It teaches calmness, control, balance, a sense of the placement of things and the underlying structure of motion. There is silent music to it. Above all there is discipline.” -Lord Valentine’s Castle, Robert Silverberg THE SKILL OF JUGGLING Juggling is unique to humans, although some staged photographs have given the illusion of animals juggling (See photo 2). The only exceptions are seals. There are performing seals that work with one ball as well, as if not better, than the world's best jugglers. Juggling involves not only the throwing between the hands of three or more objects, it also includes balancing, bouncing, kicking, rolling, spinning, and any other type of object manipulation without deceit. Most people seldom see juggling performed outside of the circus tent. There, it is usually a peripheral part of the clown performances, and only rarely a separate "act." Juggling is also inaccurately associated with magic. Photo 1: Mark Nizer bounce juggling 5 balls off the floor. -
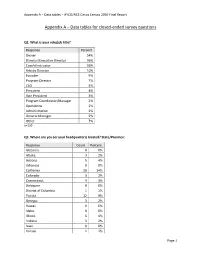
Appendix a – Data Tables – AYCO/ACE Circus Census 2020 Final Report
Appendix A – Data tables – AYCO/ACE Circus Census 2020 Final Report Appendix A – Data tables for closed-ended survey questions Q2. What is your role/job title? Response Percent Owner 54% Director/Executive Director 36% Coach/Instructor 26% Artistic Director 10% Founder 9% Program Director 7% CEO 5% President 4% Vice President 3% Program Coordinator/Manager 2% Operations 2% Administration 2% General Manager 2% Other 7% n=139 Q3. Where are you (or your headquarters) located? State/Province: Response Count Percent Alabama 0 0% Alaska 3 2% Arizona 5 4% Arkansas 0 0% California 20 14% Colorado 3 2% Connecticut 4 3% Delaware 0 0% District of Columbia 1 1% Florida 12 9% Georgia 3 2% Hawaii 0 0% Idaho 0 0% Illinois 6 4% Indiana 3 2% Iowa 0 0% Kansas 1 1% Page 1 Appendix A – Data tables – AYCO/ACE Circus Census 2020 Final Report Q3. Where are you (or your headquarters) located? State/Province: (continued) Response Count Percent Kentucky 1 1% Louisiana 1 1% Maine 0 0% Maryland 2 1% Massachusetts 11 8% Michigan 2 1% Minnesota 3 2% Mississippi 0 0% Missouri 1 1% Montana 1 1% Nebraska 1 1% Nevada 3 2% New Hampshire 1 1% New Jersey 1 1% New Mexico 3 2% New York 10 7% North Carolina 6 4% North Dakota 0 0% Ohio 4 3% Oklahoma 1 1% Oregon 3 2% Pennsylvania 3 2% Rhode Island 0 0% South Carolina 0 0% South Dakota 0 0% Tennessee 2 1% Texas 7 5% Utah 1 1% Vermont 3 2% Virginia 1 1% Washington 4 3% West Virginia 0 0% Wisconsin 2 1% Wyoming 0 0% n=139 Page 2 Appendix A – Data tables – AYCO/ACE Circus Census 2020 Final Report Q4. -
Reducing the Object Control Skills Gender Gap in Elementary School Boys and Girls
Advances in Physical Education, 2020, 10, 155-168 https://www.scirp.org/journal/ape ISSN Online: 2164-0408 ISSN Print: 2164-0386 Reducing the Object Control Skills Gender Gap in Elementary School Boys and Girls Dwayne P. Sheehan*, Karin Lienhard, Diala Ammar Mount Royal University, Calgary, Canada How to cite this paper: Sheehan, D. P., Abstract Lienhard, K., & Ammar, D. (2020). Reduc- ing the Object Control Skills Gender Gap in Purpose: This study was aimed to understand the effect of a customized Elementary School Boys and Girls. Ad- physical education (PE) program on object control skills (OCS) in third grade vances in Physical Education, 10, 155-168. schoolgirls, and to compare their skills to their male counterparts. Methods: https://doi.org/10.4236/ape.2020.102014 Seventy-six children (32 girls, 44 boys) aged 8 - 9 years were assessed at base- Received: May 4, 2020 line, after an all-girls six-week intervention program (post-test), and after six Accepted: May 25, 2020 weeks of resuming co-educational regular PE (retention). Assessments in- Published: May 28, 2020 cluded the upper limb coordination subtest from the Bruininks-Oseretsky Copyright © 2020 by author(s) and Test of Motor Proficiency, second edition (BOT-2), and the ball skills com- Scientific Research Publishing Inc. ponent of the Test of Gross Motor Development, version three (TGMD-3). This work is licensed under the Creative Results: Findings from both assessment tools showed that boys had signifi- Commons Attribution International cantly better upper limb coordination and ball skills at baseline (P < 0.05), License (CC BY 4.0). -
Object Manipulation 1.5: Basic Overhand Throw 1 3 - 5 Year Olds
DATE: ORGANIZATION/PROGRAM: ACTIVITY LEADER: CURRICULAR COMPETENCY & OUTCOME: Students develop and demonstrate GROUP OR CLASS: movement skills in a variety of activities. Object Manipulation 1.5: Basic Overhand Throw 1 3 - 5 year olds TIME: 30 minutes SKILLS: Throw, balance, hop, skip EQUIPMENT: Bean bags or small foam balls, hula hoops, empty baskets or cardboard boxes Introduction (2 - 3 minutes) Gather the children in the activity area and sit down in a circle. Describe in 20-30 seconds what you will be doing today. Explain any special safety rules for the session. Warm-up: Mirror Mirror (5 - 6 minutes) • Either indoors or outdoors, ask the children to form a large semi-circle around you. • Face the children so they can see you and you can see them. • Without leaving your spot, ask the children to imitate you as you demonstrate different movements: » Hopping » Jumping » Bending » Swaying » Spinning » Skipping » Running » Balancing on the spot (try different balance poses) • Just like a mirror, the children should try to move with you as you perform each movement. Activity 1: Target Throw (8 - 10 minutes) • Ask children to sit cross-legged on the floor and watch you. • Demonstrate how to do a basic overhand throw with a bean bag or small foam ball: » Stand facing your target (e.g. hula hoop on wall, box or basket on its side on top of a table). » Turn sideways so your throwing arm is farthest from the target. » Point your other hand at the target, then raise your throwing arm. » Throw your bean bag and turn your body as you throw. -
Engendering Community Through Performance and Play at the Euphoria and Scorched Nuts Regional Burns Bryan Schmidt
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2012 "Welcome Home!": Engendering Community Through Performance and Play at the Euphoria and Scorched Nuts Regional Burns Bryan Schmidt Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] THE FLORIDA STATE UNIVERSITY COLLEGE OF VISUAL ARTS, THEATER & DANCE ―WELCOME HOME!‖: ENGENDERING COMMUNITY THROUGH PERFORMANCE AND PLAY AT THE EUPHORIA AND SCORCHED NUTS REGIONAL BURNS By BRYAN SCHMIDT A Thesis submitted to the School of Theater in partial fulfillment of the requirements for the degree of Master of Arts Degree Awarded: Summer Semester, 2012 Bryan Schmidt defended this thesis on April 25, 2012. The members of the supervisory committee were: Elizabeth Osborne Professor Directing Thesis Mary Karen Dahl Committee Member Krzystof Salata Committee Member The Graduate School has verified and approved the above-named committee members, and certifies that the thesis has been approved in accordance with university requirements. ii For my parents Susan and William, and my brother Kevin. iii ACKNOWLEDGEMENTS Special Thanks to Beth Osborne for her tireless, crucial help and encouragement throughout the writing process, and for introducing me to the world of Burning Man; Mary Karen Dahl, for her insightful guidance especially during the planning stages of the project; Kris Salata, for serving on my committee, pointing me to fascinating theory, and engaging in lengthy discussions that helped me form my argument; Aaron C. Thomas, and George McConnell for each providing invaluable help during some of this project‘s most consternating moments; Natalya Baldyga for pointing me towards several texts that formed critical components of my research; Rebecca Ormiston, Susan Schmidt, and William Schmidt for help and support.