UAV Lidar Point Cloud Segmentation of a Stack
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

(LTA) Evaluation of the Baton Rouge Urban Renewal and Mobility Plan
Louisiana Transportation Authority (LTA) Evaluation of the Baton Rouge Urban Renewal and Mobility Plan (BUMP) to Develop the Project as a Public Private Partnership (P3) October 20, 2015 – Final (With Redactions) TABLE OF CONTENTS EXECUTIVE SUMMARY ............................................................................................................ 1 Proposal Overview .................................................................................................................... 1 Construction Cost...................................................................................................................... 1 Tolling ....................................................................................................................................... 1 Traffic and Revenue (T&R) ...................................................................................................... 2 Feasibility .................................................................................................................................. 2 Findings..................................................................................................................................... 3 1.0 CHAPTER ONE – State & Federal Legislation Summary ................................................... 4 1.1 Louisiana State Legislation .............................................................................................. 4 1.2 Federal Legislation .......................................................................................................... -

Spaghetti Junction Final Report, Vanderbilt Senior Design 2020
Spaghetti Junction Final Report, Vanderbilt Senior Design 2020 Brooks Davis, Jacob Ferguson, Will Braeuner Table of Contents I. Introduction………………………………………………………………………………..3 II. Significance………………………………………………………………………………..4 III. Preliminary Research……………………………………………………………………...6 A. Pedestrian Travel………..……………………………………………...…………6 B. Bicycle Travel……………………………………………………………………..7 C. Automobile Travel………………………………………………………………...8 D. Public Transport…………………………………………………………………...9 IV. Design Goals……………………………………………………………………………..10 V. Design Results & Recommendations……………………………………………………10 VI. Further Research & Final Thoughts……...……………………………………………....14 VII. References………………………………………………………………………………..15 VIII. Appendices A. Traffic Projections……………………………………………………………….17 B. Spaghetti Junction Redesigned…………………………………………………..18 C. Visualizing Woodland Street…………………………………...………………..20 D. Visualizing Main Street………………………………………………………….22 E. Revised Schedule………………………………………………………………...23 2 I. Introduction: Nashville, like many other cities, is experiencing rapid growth and must address increasing demands on current transportation resources. As a result, it is important for Nashville to use its existing traffic networks in the most efficient and effective manner. East Nashville’s intersection of Ellington Parkway, I-24, Main St, Spring St, and Dickerson Pike, nicknamed “Spaghetti Junction,” consumes over 85 acres of space with interchanges and unusable land. This is nearly equivalent to Atlanta’s Tom Moreland Interchange or L.A.’s Pregerson Interchange, the -

Leveraging Industrial Heritage in Waterfront Redevelopment
University of Pennsylvania ScholarlyCommons Theses (Historic Preservation) Graduate Program in Historic Preservation 2010 From Dockyard to Esplanade: Leveraging Industrial Heritage in Waterfront Redevelopment Jayne O. Spector University of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/hp_theses Part of the Historic Preservation and Conservation Commons Spector, Jayne O., "From Dockyard to Esplanade: Leveraging Industrial Heritage in Waterfront Redevelopment" (2010). Theses (Historic Preservation). 150. https://repository.upenn.edu/hp_theses/150 Suggested Citation: Spector, Jayne O. (2010). "From Dockyard to Esplanade: Leveraging Industrial Heritage in Waterfront Redevelopment." (Masters Thesis). University of Pennsylvania, Philadelphia, PA. This paper is posted at ScholarlyCommons. https://repository.upenn.edu/hp_theses/150 For more information, please contact [email protected]. From Dockyard to Esplanade: Leveraging Industrial Heritage in Waterfront Redevelopment Abstract The outcomes of preserving and incorporating industrial building fabric and related infrastructure, such as railways, docks and cranes, in redeveloped waterfront sites have yet to be fully understood by planners, preservationists, public administrators or developers. Case studies of Pittsburgh, Baltimore, Philadelphia/ Camden, Dublin, Glasgow, examine the industrial history, redevelopment planning and approach to preservation and adaptive reuse in each locale. The effects of contested industrial histories, -

Study of a Highly Effective and Affordable Highway Interchange - ITL Interchange
Available online at www.CivileJournal.org Civil Engineering Journal Vol. 6, No. 4, April, 2020 Technical Note Study of a Highly Effective and Affordable Highway Interchange - ITL Interchange Goran Jovanović a*, Rafko Atelšek b* a MSc, Civil Engineer, Appia Company for Design, Research and Engineering d.o.o. (Appia d.o.o), Ljubljana, Slovenia. b BSc, EE, Appia Company for Design, Research and Engineering d.o.o. (Appia d.o.o.), Ljubljana, Slovenia. Received 26 December 2019; Accepted 01 March 2020 Abstract In this paper we present a new solution for the highway interchange, which represents the best compromise between the traffic capacity, the land area used and construction cost. The difference between the known and the new design solution is in the implementation of the opposite directional ramps which are widely separated in the area of the interchange. In the middle, between the directional ramps, some space is created for the left directional ramps. Interchange should be used for four-way highway interchanges or other heavy traffic roads junction in order to increase the capacity and traffic safety at the crossing point. It has no conflict points. ITL Interchange left directional ramps is much shorter than all other known solutions for interchanges. The interchange is built in two levels. These two facts significantly lower the cost of construction. The study compares different types of interchanges. We made a geometric comparison and performance measures. In geometric comparison, the greatest advantages of the ITL interchange are the shortest overall roadway length and the shortest overpasses length. Therefore, such an interchange is advantageous in terms of construction and maintenance costs. -

NDOT Roadside Vegetation Establishment and Management
NDOT Roadside Vegetation Establishment and Management This document supersedes previous versions of this document and NDOT’s Chemical Usage Guidelines, Seeding Handbook and Mowing Guidelines. 2021 Table of Contents Page No. Document Development .................................................................................................................... 1 Introduction ............................................................................................................................................... 3 Roadside Stabilization Practices .................................................................................................. 7 Protected Plant Species and Sensitive Resources in the Right of Way ................. 9 Seeding ....................................................................................................................................................... 11 Appendix: Suggested Seed Mixtures for Nebraska Roadsides ......................... 23-33 Installing and Maintaining Sod ....................................................................................................... 35 Planting and Maintaining Trees ..................................................................................................... 37 Managing Roadside Vegetation .................................................................................................... 41 Part 1 – NDOT Protocol for Integrated Vegetation Management ...................... 41 Part 2 – Compliance with the Pesticide Use General Permit .............................. -

Innovative Roadway Design Making Highways More Likeable
September 2006 INNOVATIVE ROADWAY DESIGN MAKING HIGHWAYS MORE LIKEABLE By Peter Samuel Project Director: Robert W. Poole, Jr. POLICY STUDY 348 The Galvin Mobility Project America’s insufficient and deteriorating transportation network is choking our cities, hurt- ing our economy, and reducing our quality of life. But through innovative engineering, value pricing, public-private partnerships, and innovations in performance and manage- ment we can stop this dangerous downward spiral. The Galvin Mobility Project is a major new policy initiative that will significantly increase our urban mobility and help local officials move beyond business-as-usual transportation planning. Reason Foundation Reason Foundation’s mission is to advance a free society by developing, applying, and promoting libertarian principles, including individual liberty, free markets, and the rule of law. We use journalism and public policy research to influence the frameworks and actions of policymakers, journalists, and opinion leaders. Reason Foundation’s nonpartisan public policy research promotes choice, competition, and a dynamic market economy as the foundation for human dignity and progress. Reason produces rigorous, peer-reviewed research and directly engages the policy process, seeking strategies that emphasize cooperation, flexibility, local knowledge, and results. Through practical and innovative approaches to complex problems, Reason seeks to change the way people think about issues, and promote policies that allow and encourage individuals and voluntary institutions to flourish. Reason Foundation is a tax-exempt research and education organization as defined under IRS code 501(c)(3). Reason Foundation is supported by voluntary contributions from indi- viduals, foundations, and corporations. The views are those of the author, not necessarily those of Reason Foundation or its trustees. -
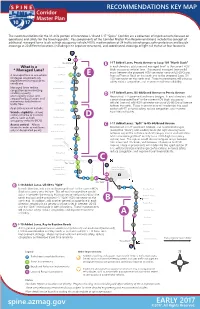
Map Handout 010417
RECOMMENDATIONS KEY MAP The recommendations for the 31-mile portion of Interstates I-10 and I-17 “Spine” Corridor are a collection of improvements focused on operations and safety for the traveling public. Key components of the Corridor Master Plan Recommendations include the concept of additional managed lanes (such as high occupancy vehicle/HOV), modernization of 24 traffic interchanges, safer pedestrian and bicycle crossings at 20 different locations (including nine separate structures), and coordinated crossings of light rail transit at four locations. 63 “North Stack” E I-17 Added Lanes, Peoria Avenue to Loop 101 "North Stack" In each direction, add a second managed lane* to the current HOV What is a Union Hills Drive 47 * Managed Lane? (high occupancy vehicle) lane. This second managed lane would occur between the proposed HOV connector ramp at US-60/Grand A managed lane is one where Bell Road 26 16 46 E Avenue/Thomas Road on the south end to the proposed Loop 101 strategies are proactively 45 HOV connector on the north end. These improvements will enhance implemented in response to Greenway Road 15 44 safety, reduce congestion, and improve travel time reliability. conditions. Managed lanes reduce Thunderbird Road 14 43 congestion by maximizing existing capacity, D I-17 Added Lanes, US-60/Grand Avenue to Peoria Avenue encouraging transit and Cactus Road 13 Reconstruct I-17 pavement and many bridges. In each direction, add carpool/vanpool usage, and a second managed lane* to the current HOV (high occupancy minimizing turbulence in Peoria Avenue 12 42 vehicle) lane and add HOV connector ramps to US-60/Grand Avenue traffic flow. -

CH2 Freeway Metropolis Pp92-115 150.Pdf
Freeway Metropolis Is Houston the world’s most freeway-focused city—the ultimate freeway metropolis? There are many potential competitors for such a distinction, and typically Los Angeles is automatically awarded that title. But Houston’s freeways have a certain design feature that elevates the freeway to a higher level of importance in the functioning of the city than nearly all other cities. It’s a feature that exists extensively only in Texas, and its prevalence in Houston is unequalled by any other city. The freeway design feature is, of course, the freeway frontage road. Because of the frontage road, Houston’s freeways are more than just transportation corridors. They form the city’s principal commercial strips and business centers. Whether you are going to work, going shopping, going out to eat, staying at a hotel, seeking medical care, or buying a car in Houston, there’s a good chance your destination will have a freeway address. The frontage road heavily influences development patterns, and the resulting land-use form is perhaps the most freeway-focused in the world. The frontage road has also influenced many other distinguishing design features of Houston’s freeways, including the extensive use of high mast illumination and the five- level freeway-to-freeway interchange. The frontage road increases the physical presence of the Houston freeway, adding at least 120 feet (37 m) to the freeway right-of-way footprint. Better yet, Texans and Houstonians like their frontage roads. The frontage road is almost as much a part of Texas as barbecue, cowboy boots, and oil wells, as the Texas Transportation Commission found out in 2001 when it tried to curtail the use of frontage roads on future freeways. -

Grafica Broadsheet
The Local Expression. April 2019 Quarterly 2 / 4 The Local Expression. As a modern African manufacturer we have developed a range in- spired and influenced by African design – Grafica. The local expression is attitude and Africa made one; an homage to the 01 02 03 Crates Blocks Skew Lines fabric of our cities. Quarterly 2/4_April 2019 The bold commercial collection of 3 tufted tile designs delivers a robust, graphic pattern A stack-style design inspired Urban life in Africa is an Africa is a place of contrast, to hard-working floors. The African designs are by our local make-shift, can- organised chaos – a vibrant a clash of perspectives, woven do culture. Crates embodies grid of energy where cultures together to create the bold synergy inspired by our cultural landscape and is our the iconic marketplace form in converge for the daily hustle. that we call home. An expression a pattern rooted in humility Blocks pays tribute to all the of our local anything goes modern expression of Africa’s abundant creativity. and hard work. hustlers. Keep hustling. attitude – this is Skew Lines. The Grafica Story. Quarterly 2/4_April 2019 01. Crates 02. Blocks 03. Skew Lines As an African manufacturer that pays special attention to detail, when it came to developing a new commercial range inspired by African design we avoided the typical clichés, and looked instead to the everyday objects that make up our cities. Belgotex's homage to African design is an Life moves pretty fast, and it was only when we stopped to Then, inspired by all that colour, texture and myriad graphic look around us that we noticed how the greatest inspiration elements we created a product comprising three distinct exploration of Africa’s abundant creativity, inspired were those seemingly commonplace, everyday scenes that ranges: blocks, crates and skew lines. -

Eastex Freeway, US 59 North
226 Houston Freeways Eastex Freeway, US 59 North Clearing out the old and bringing in the new is a reg- Eastex Freeway ular event on Houston’s freeways, but sometimes the Designated as freeway 1945, 1953 transformation is especially satisfying. In the case of the First freeway section open 1953 Eastex Freeway, the “old” was the original, antiquated 1950s-era design, Houston’s last vestige of a first gen- Freeway complete 1970 (to Bush eration freeway. The “new” is a state-of-the-art freeway, Intercontinental Airport) among the best in Houston. Getting from old to new was a Reconstruction 1991–ongoing particularly long and painful process due to the seeming- Max traffic volume, 2001 192,000 vehicles per day ly interminable delays during construction, but by the late Future construction Expansion north of 1990s Eastex Freeway motorists were finally driving on Houston; complete their new freeway. After the transformation was complete, interchange at Beltway 8 there was surely no doubt: new is better. Origins �������� The Eastex Freeway was Houston’s second freeway to ������ be constructed, after the Gulf Freeway. The section from ��� downtown to Loop 137, just north of present-day Loop �� ������� ���� �� �� 610, was authorized by the Texas Transportation Commis- �������������� �� � ��� sion in May 1945 when the commission approved a small ����������� ���� group of freeways that would form the basis for Houston’s early freeway plan. By November 1948 city and state of- ������ ���� ���� ���� ��� �� ���� ficials had determined that the US 59 freeway would be ���������������� ����� ������� routed just east of Jensen Drive, leading to the informal ���� designation of the route as the Jensen Drive Freeway. -

Celebrating a Century of Simply the Best in Service, Safety and Innovation 1960S Introduction
CELEBRATING A CENTURY OF SIMPLY THE BEST IN SERVICE, SAFETY AND INNOVATION 1960s INTRODUCTION marks the year On the state level, we are indeed grateful for the turning point in of Georgia DOT’s transportation that came in 2015 with the passage by state lawmakers 2016centennial! of the Transportation Funding Act (TFA). This historic legislation On August 16, 1916, the provides a sustainable transportation revenue source to address Georgia Highway Commission— Georgia’s transportation needs, and to restore and maintain the state’s 1900s now Georgia Department of critical transportation infrastructure. Transportation—was created. While we celebrate 100 years of Simply the Best in Safety, Service And for the last 100 years, and Innovation, we reflect on our past accomplishments, but our Georgia DOT has played a key work is not done. There are challenges to come in the next 100 years role in the growth and transformation of the state with transportation and beyond. The automobile of the future will have a tremendous infrastructure improvements that increase economic growth through impact on transportation, and finding new and innovative ways to expanded markets and increased job opportunities. address freight and mobility concerns will always be a primary goal 1920s In every decade of Georgia DOT’s 100-year history, road building for us. Our strategic goals of planning and constructing the best set has improved mobility, enhanced quality of life, presented significant of mobility-focused projects on schedule; making safety investments business opportunities beyond the paving of a road, and encouraged and improvements where the traveling public is most at risk; making innovation. -

Template 1St Macedonian Congress on Roads
www.prvkongreszapatista.mk [email protected] NEW TYPE OF HIGHWAY INTERCHANGE: ITL INTERCHANGE Goran Jovanović1, Rafko Atelšek2, 1 MScCEng, Appia d.o.o., Slovenia, [email protected] 2 BScEE, Appia d.o.o., Slovenia, [email protected] Abstract In this paper we present a new solution for the highway interchange, which represents the best compromise between the traffic capacity, the land area used and construction cost. The difference between the known and the new design solution is in the implementation of the opposite directional ramps which are widely separated in the area of the interchange. In the middle, between the directional ramps, some space is created for the left directional ramps. Therefore, the interchange is called Inside Turning Left Interchange - ITL Interchange. ITL Interchange should be used for four-way highway interchanges or other heavy traffic roads junction in order to increase the capacity and traffic safety at the crossing point. It has no conflict points. ITL Interchange left directional ramps are much shorter than all other known solutions for interchanges. The interchange is built in two levels. These two facts significantly lower the cost of construction. The solution is protected by a patent. Key words Highway, ITL Interchange, Left directional ramp, Traffic capacity 1. INTRODUCTION Modern highway interchanges and other heavy traffic roads interchanges have to ensure the highest possible traffic safety and capacity. Most of these interchanges are located on the outskirts of major cities and also in urban areas where the size of the interchanges is conditioned by the space available. The financial aspect, which defray the costs of construction and maintenance of the interchange, is also very important.