Visnet: Deep Convolutional Neural Networks for Forecasting Atmospheric Visibility
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Aerodrome Actual Weather – METAR Decode
Aerodrome Actual Weather – METAR decode Code element Example Decode Notes 1 Identification METAR — Meteorological Airfield Report, SPECI — selected special (not from UK civil METAR or SPECI METAR METAR aerodromes) Location indicator EGLL London Heathrow Station four-letter indicator 'ten twenty Zulu on the Date/Time 291020Z 29th' AUTO Metars will only be disseminated when an aerodrome is closed or at H24 aerodromes, A fully automated where the accredited met. observer is on duty break overnight. Users are reminded that reports AUTO report with no human of visibility, present weather and cloud from automated systems should be treated with caution intervention due to the limitations of the sensors themselves and the spatial area sampled by the sensors. 2 Wind 'three one zero Wind degrees, fifteen knots, Max only given if >= 10KT greater than the mean. VRB = variable. 00000KT = calm. 31015G27KT direction/speed max twenty seven Wind direction is given in degrees true. knots' 'varying between two Extreme direction 280V350 eight zero and three Variation given in clockwise direction, but only when mean speed is greater than 3 KT. variance five zero degrees' 3 Visibility 'three thousand two Prevailing visibility 3200 0000 = 'less than 50 metres' 9999 = 'ten kilometres or more'. No direction is required. hundred metres' Minimum visibility 'Twelve hundred The minimum visibility is also included alongside the prevailing visibility when the visibility in one (in addition to the 1200SW metres to the south- direction, which is not the prevailing visibility, is less than 1500 metres or less than 50% of the prevailing visibility west' prevailing visibility. A direction is also added as one of the eight points of the compass. -

A User's Guide to Co-Ops Visibility Sensor
A USER’S GUIDE TO CO-OPS VISIBILITY SENSOR OBSERVATIONS The American Meteorological Society defines visibility as “the greatest distance in a given direction at which it is just possible to see and identify with the unaided eye (a) in the daytime, a prominent dark object against the sky at the horizon, and (b) at night, a known, preferably unfocused, moderately intense light source. A wide variety of factors contribute to changing this distance. CO-OPS deploys automated visibility sensors at locations selected in concert with supporting PORTS® partners. The sites must be both acceptable for sensor operation and useful for the user. Because fog can be patchy, it is important for users to understand how to interpret the disseminated data. The sensors used by CO-OPS optically examine a small volume of air to determine the scattering characteristics of the air parcel, the most common technique used to measure visibility. Scatter can be caused by fog, smog, dust – any particles in the air will suffice. When the scatter is small the visibility is good, while large scatter means the visibility at the location of the sensor is poor. It is important to realize that the visibility range provided by the sensor, more correctly known as Meteorological Optical Range (MOR), is a measurement made at a single point. When fog or other scattering particles are uniformly widespread it may be reasonable to presume the MOR applies over large distances, ie. a reading of 5 nautical miles means a person will see sufficiently large objects at that distance. But such a presumption may not be valid, and the sensor has no way of observing MOR except at the deployment site. -
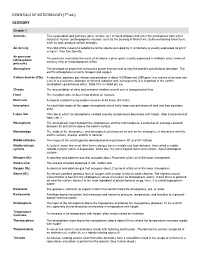
ESSENTIALS of METEOROLOGY (7Th Ed.) GLOSSARY
ESSENTIALS OF METEOROLOGY (7th ed.) GLOSSARY Chapter 1 Aerosols Tiny suspended solid particles (dust, smoke, etc.) or liquid droplets that enter the atmosphere from either natural or human (anthropogenic) sources, such as the burning of fossil fuels. Sulfur-containing fossil fuels, such as coal, produce sulfate aerosols. Air density The ratio of the mass of a substance to the volume occupied by it. Air density is usually expressed as g/cm3 or kg/m3. Also See Density. Air pressure The pressure exerted by the mass of air above a given point, usually expressed in millibars (mb), inches of (atmospheric mercury (Hg) or in hectopascals (hPa). pressure) Atmosphere The envelope of gases that surround a planet and are held to it by the planet's gravitational attraction. The earth's atmosphere is mainly nitrogen and oxygen. Carbon dioxide (CO2) A colorless, odorless gas whose concentration is about 0.039 percent (390 ppm) in a volume of air near sea level. It is a selective absorber of infrared radiation and, consequently, it is important in the earth's atmospheric greenhouse effect. Solid CO2 is called dry ice. Climate The accumulation of daily and seasonal weather events over a long period of time. Front The transition zone between two distinct air masses. Hurricane A tropical cyclone having winds in excess of 64 knots (74 mi/hr). Ionosphere An electrified region of the upper atmosphere where fairly large concentrations of ions and free electrons exist. Lapse rate The rate at which an atmospheric variable (usually temperature) decreases with height. (See Environmental lapse rate.) Mesosphere The atmospheric layer between the stratosphere and the thermosphere. -

Impact of Meteorology and Atmospheric Pollutants on Visibility
Atmos. Chem. Phys., 17, 2085–2101, 2017 www.atmos-chem-phys.net/17/2085/2017/ doi:10.5194/acp-17-2085-2017 © Author(s) 2017. CC Attribution 3.0 License. 60 years of UK visibility measurements: impact of meteorology and atmospheric pollutants on visibility Ajit Singh, William J. Bloss, and Francis D. Pope School of Geography, Earth and Environmental Sciences, University of Birmingham, Birmingham, B15 2TT, UK Correspondence to: Francis D. Pope ([email protected]) Received: 16 August 2016 – Discussion started: 26 August 2016 Revised: 6 January 2017 – Accepted: 17 January 2017 – Published: 13 February 2017 Abstract. Reduced visibility is an indicator of poor air qual- in aerosol particle properties. This approach may help con- ity. Moreover, degradation in visibility can be hazardous to strain global model simulations which attempt to generate human safety; for example, low visibility can lead to road, aerosol fields for time periods when observational data are rail, sea and air accidents. In this paper, we explore the com- scarce or non-existent. Both the measured visibility and the bined influence of atmospheric aerosol particle and gas char- modelled aerosol properties reported in this paper highlight acteristics, and meteorology, on long-term visibility. We use the success of the UK’s Clean Air Act, which was passed in visibility data from eight meteorological stations, situated in 1956, in cleaning the atmosphere of visibility-reducing pol- the UK, which have been running since the 1950s. The site lutants. locations include urban, rural and marine environments. Most stations show a long-term trend of increasing visi- bility, which is indicative of reductions in air pollution, es- pecially in urban areas. -

P2.55 Visibility Versus Precipitation Rate and Relative Humidity
P2.55 VISIBILITY VERSUS PRECIPITATION RATE AND RELATIVE HUMIDITY I. Gultepe1,2, and G. A. Isaac1 1Cloud Physics and Severe Weather Research Section, Science and Technology Branch, Environment Canada Toronto, Ontario, M3H 5T4, Canada 1. INTRODUCTION 2. OBSERVATIONS The purpose of this work is to analyze the The main observations used in the analysis were relationships between visibility and precipitation the precipitation rates for rain and snow from the rate (PR), and visibility and relative humidity Desert Research Institute (DRI) manufactured with respect to water (RHw), obtained from hot plates (Rasmussen et al., 2002), the surface measurements. Precipitation Occurrence Sensor System (POSS) (Sheppard, 1990), and from the Visalia FD12P, Presently, visibility parameterizations related to ice and liquid particle characteristics from the precipitation type in forecast models are not optical probes, visibility from the Belfort adequate because they represent mid-latitude visibility meter, the Vaisala FD12P and from the cloud systems (Stoelinga, 1999). Some previous fog measuring device (FMD), and relative works have shown that particle phase is an humidity and temperature from the Campbell important factor in the visibility calculation but Scientific instruments. Details on these usually it is ignored (Rasmussen et al., 1999). instruments can be found in Isaac et al. (2005) The relative humidity with respect to water in and Gultepe et al. (2006). forecast models is used for visibility parameterization but changes have been 3. ANALYSIS AND RESULTS continuously made because of the uncertainty in The data were collected during the Alliance Icing accurate RHw measurements (Smirnova et al., Research Study (AIRS 2) which was conducted 2000). -

A Review of Ocean/Sea Subsurface Water Temperature Studies from Remote Sensing and Non-Remote Sensing Methods
water Review A Review of Ocean/Sea Subsurface Water Temperature Studies from Remote Sensing and Non-Remote Sensing Methods Elahe Akbari 1,2, Seyed Kazem Alavipanah 1,*, Mehrdad Jeihouni 1, Mohammad Hajeb 1,3, Dagmar Haase 4,5 and Sadroddin Alavipanah 4 1 Department of Remote Sensing and GIS, Faculty of Geography, University of Tehran, Tehran 1417853933, Iran; [email protected] (E.A.); [email protected] (M.J.); [email protected] (M.H.) 2 Department of Climatology and Geomorphology, Faculty of Geography and Environmental Sciences, Hakim Sabzevari University, Sabzevar 9617976487, Iran 3 Department of Remote Sensing and GIS, Shahid Beheshti University, Tehran 1983963113, Iran 4 Department of Geography, Humboldt University of Berlin, Unter den Linden 6, 10099 Berlin, Germany; [email protected] (D.H.); [email protected] (S.A.) 5 Department of Computational Landscape Ecology, Helmholtz Centre for Environmental Research UFZ, 04318 Leipzig, Germany * Correspondence: [email protected]; Tel.: +98-21-6111-3536 Received: 3 October 2017; Accepted: 16 November 2017; Published: 14 December 2017 Abstract: Oceans/Seas are important components of Earth that are affected by global warming and climate change. Recent studies have indicated that the deeper oceans are responsible for climate variability by changing the Earth’s ecosystem; therefore, assessing them has become more important. Remote sensing can provide sea surface data at high spatial/temporal resolution and with large spatial coverage, which allows for remarkable discoveries in the ocean sciences. The deep layers of the ocean/sea, however, cannot be directly detected by satellite remote sensors. -

NATIONAL WEATHER SERVICE INSTRUCTION 10-813 NOVEMBER 18, 2020 Operations and Services Aviation Weather Services, NWSPD 10-8 TERMINAL AERODROME FORECASTS
Department of Commerce • National Oceanic & Atmospheric Administration • National Weather Service NATIONAL WEATHER SERVICE INSTRUCTION 10-813 NOVEMBER 18, 2020 Operations and Services Aviation Weather Services, NWSPD 10-8 TERMINAL AERODROME FORECASTS NOTICE: This publication is available at: http://www.nws.noaa.gov/directives/. OPR: W/AFS24 (M. Graf) Certified by: W/AFS24 (B. Entwistle) Type of Issuance: Routine SUMMARY OF REVISIONS: This directive supersedes NWS Instruction 10-813, Terminal Aerodrome Forecasts, dated November 21, 2016. Changes made include: • Section 3 – updated links and removed unnecessary footnote • Section 4 – updated ICAO and WMO manual and regulation numbers • Section 4 – allowed up to 8 FM groups for 30 hour TAF locations • Section 4.1 – updated coordination section to include the AWC (including NAMs) and the AAWU. Also included the 10-803 link. • Section 4.2 – Introduced topic of Digital Aviation Services (DAS) • Section 4.2 – added the word “specifically” to the definition of vicinity as defined by the FAA • Section 4.3 – updated to include the link for ASOS/AWOS limitations. • Section 4.9 – added ICAO verbiage to address the grey window for 00/06/12/18 UTC issuances • Section 4.11 – updated to include the link to the FAA’s list of core airports. • Section 4.13 – revised TAF examples to clearly show format of AMD NOT SKED • Section 6 – updated to include the link to 10-2003. • Section 7 – updated the Performance and Evaluation Branch’s verification link. • Appendix A – updated the definitions of Hail (GR) and Snow Pellets (GS) in the table. • Appendix B – renumbered sections • Appendix B Section 1 – the IWXXM TAF is explained (LT) • Appendix B Section 2.4.2 – updated wording to add more detail for low winds • Appendix B Section 2.6 – added verbiage to use 3 winter weather types judiciously • Appendix B Section 2.8 – LLWS section rewritten to improve clarity • Appendix B Section 2.9.1 – moved NDFD wording from TCF discussion to section 2.6 • Appendix B Section 2.9.1 – updated CDM/CCFP to TFM/TCF. -

Information Contained in a METAR Example METAR Codes
METAR METAR is a format for reporting weather information. A METAR weather report is predominantly used by pilots in fulfillment of a part of a pre-flight weather briefing, and by meteorologists, who use aggregated METAR information to assist in weather forecasting. Raw METAR is the most common format in the world for the transmission of observational weather data. [citation needed] It is highly standardized through the International Civil Aviation Organization (ICAO), which allows it to be understood throughout most of the world. Information contained in a METAR A typical METAR contains data for the temperature, dew point, wind speed and direction, precipitation, cloud cover and heights, visibility, and barometric pressure. A METAR may also contain information on precipitation amounts, lightning, and other information that would be of interest to pilots or meteorologists such as a pilot report or PIREP, colour states and runway visual range (RVR). In addition, a short period forecast called a TRED may be added at the end of the METAR covering likely changes in weather conditions in the two hours following the observation. These are in the same format as a Terminal Aerodrome Forecast (TAF). The complement to METARs, reporting forecast weather rather than current weather, are TAFs. METARs and TAFs are used in VOLMET broadcasts. Example METAR codes International METAR codes The following is an example METAR from Burgas Airport in Burgas, Bulgaria. It was taken on 4 February 2005 at 16:00 Coordinated Universal Time (UTC). METAR LBBG 041600Z 12003MPS 310V290 1400 R04/P1500 R22/P1500U +S BK022 OVC050 M04/M07 Q1020 OSIG 9949//91= • METAR indicates that the following is a standard hourly observation. -

Key to Aerodrome Forecast (TAF) and Aviation Routine Weather Report (METAR) (Front)
Key to Aerodrome Forecast (TAF) and Aviation Routine Weather Report (METAR) (Front) KEY to AERODROME FORECAST (TAF) and U.S. Department of Transportation AVIATION ROUTINE WEATHER REPORT Federal Aviation (METAR) (FRONT) Administration TAF KPIT 091730Z 091818 15005KT 5SM HZ FEW020 WS010/31022KT FM 1930 30015G25KT 3SM SHRA OVC015 TEMPO 2022 1/2SM +TSRA OVC008CB FM0100 27008KT 5SM SHRA BKN020 OVC040 PROB40 0407 1SM -RA BR FM1015 18005KT 6SM -SHRA OVC020 BECMG 1315 P6SM NSW SKC METAR KPIT 091955Z COR 22015G25KT 3/4SM R28L/2600FT TSRA OVC010CB 18/16 A2992 RMK SLP045 T01820159 FORECAST EXPLANATION REPORT TAF Message type : TAF-routine or TAF AMD-amended forecast, METAR METAR-hourly, SPECI-special or TESTM-non-commissioned ASOS report KPIT ICAO location indicator KPIT 091730Z Issuance time: ALL times in UTC “Z”, 2-digit date, 4-digit time 091955Z 091818 Valid period: 2-digit date, 2-digit beginning, 2-digit ending times In U.S. METAR: CORrected of; or AUTOmated ob for automated COR report with no human intervention; omitted when observer logs on 15005KT Wind: 3 digit true-north direction , nearest 10 degrees (or VaRiaBle); 22015G25KT next 2-3 digits for speed and unit, KT (KMH or MPS); as needed, Gust and maximum speed; 00000KT for calm; for METAR, if direction varies 60 degrees or more, Variability appended, e.g., 180V260 5SM Prevailing visibility; in U.S., Statute Miles & fractions; above 6 miles in 3/4SM TAF Plus6SM. (Or, 4-digit minimum visibility in meters and as required, lowest value with direction) Runway Visual Range: R; 2-digit runway designator Left, Center, or R28L/2600FT Right as needed; “/”, Minus or Plus in U.S., 4-digit value, FeeT in U.S., (usually meters elsewhere); 4-digit value Variability 4-digit value (and tendency Down, Up or No change) HZ Significant present, forecast and recent weather: see table (on back) TSRA FEW020 Cloud amount, height and type: SKy Clear 0/8, FEW >0/8-2/8, OVC 010CB SCaTtered 3/8-4/8, BroKeN 5/8-7/8, OVerCast 8/8; 3-digit height in hundreds of ft; Towering CUmulus or CumulonimBus in METAR; in TAF, only CB. -

High Visibility Clothing for Heavy & Highway Construction
HIGH VISIBILITY CLOTHING FOR HEAVY & HIGHWAY CONSTRUCTION Fatalities Total 305 Workers Must Be Seen 9 8 5 According to the U.S. Bureau of Labor Statistics (BLS), “The most common 15 event associated with fatal occupational injuries incurred at a road construction site was worker struck by vehicle, mobile equipment. Of the 639 total fatal occupational injuries at road construction sites during the 2003–07period, 305 were due to a worker being struck by a vehicle or mobile equipment.” The BLS article further reports that more workers are struck and killed by construction equipment (38 percent) than by cars, vans and tractor-trailers (33 percent). As such, work zone “runovers” and “backovers” are clearly the greatest hazard to roadway construction workers and, by far, the leading cause of death. The use of high visibility clothing is one important strategy in reducing the number of “struck-by” deaths on road construction sites. Dump Truck Pickup Truck Semi Truck Car Roller/Paver Grader/Planer/ Van Backhoe Scraper HIGH VISIBILITY CLOTHING FOR HEAVY & HIGHWAY CONSTRUCTION Standards and Regulations ANSI/ISEA 107 U.S. Federal Highway Administration This standard provides performance criteria for Manual on Uniform Traffic Control Devices Several agencies of the the materials to be used in high visibility PPE, (MUTCD) 6D.03 (2009): All workers, including specifies minimum areas and, where appropri- emergency responders, within the right-of-way federal U.S. government ate, recommends placement of the materials. who are exposed either to traffic -

M.Sc. in Meteorology Physical Meteorology Part 2 Atmospheric
M.Sc. in Meteorology Physical Meteorology Part 2 Prof Peter Lynch Atmospheric Thermodynamics Mathematical Computation Laboratory Dept. of Maths. Physics, UCD, Belfield. 2 Atmospheric Thermodynamics Outline of Material Thermodynamics plays an important role in our quanti- • 1 The Gas Laws tative understanding of atmospheric phenomena, ranging from the smallest cloud microphysical processes to the gen- • 2 The Hydrostatic Equation eral circulation of the atmosphere. • 3 The First Law of Thermodynamics The purpose of this section of the course is to introduce • 4 Adiabatic Processes some fundamental ideas and relationships in thermodynam- • 5 Water Vapour in Air ics and to apply them to a number of simple, but important, atmospheric situations. • 6 Static Stability The course is based closely on the text of Wallace & Hobbs • 7 The Second Law of Thermodynamics 3 4 We resort therefore to a statistical approach, and consider The Kinetic Theory of Gases the average behaviour of the gas. This is the approach called The atmosphere is a gaseous envelope surrounding the Earth. the kinetic theory of gases. The laws governing the bulk The basic source of its motion is incoming solar radiation, behaviour are at the heart of thermodynamics. We will which drives the general circulation. not consider the kinetic theory explicitly, but will take the thermodynamic principles as our starting point. To begin to understand atmospheric dynamics, we must first understand the way in which a gas behaves, especially when heat is added are removed. Thus, we begin by studying thermodynamics and its application in simple atmospheric contexts. Fundamentally, a gas is an agglomeration of molecules. -

Metar Abbreviations Metar/Taf List of Abbreviations and Acronyms
METAR ABBREVIATIONS http://www.alaska.faa.gov/fai/afss/metar%20taf/metcont.htm METAR/TAF LIST OF ABBREVIATIONS AND ACRONYMS $ maintenance check indicator - light intensity indicator that visual range data follows; separator between + heavy intensity / temperature and dew point data. ACFT ACC altocumulus castellanus aircraft mishap MSHP ACSL altocumulus standing lenticular cloud AO1 automated station without precipitation discriminator AO2 automated station with precipitation discriminator ALP airport location point APCH approach APRNT apparent APRX approximately ATCT airport traffic control tower AUTO fully automated report B began BC patches BKN broken BL blowing BR mist C center (with reference to runway designation) CA cloud-air lightning CB cumulonimbus cloud CBMAM cumulonimbus mammatus cloud CC cloud-cloud lightning CCSL cirrocumulus standing lenticular cloud cd candela CG cloud-ground lightning CHI cloud-height indicator CHINO sky condition at secondary location not available CIG ceiling CLR clear CONS continuous COR correction to a previously disseminated observation DOC Department of Commerce DOD Department of Defense DOT Department of Transportation DR low drifting DS duststorm DSIPTG dissipating DSNT distant DU widespread dust DVR dispatch visual range DZ drizzle E east, ended, estimated ceiling (SAO) FAA Federal Aviation Administration FC funnel cloud FEW few clouds FG fog FIBI filed but impracticable to transmit FIRST first observation after a break in coverage at manual station Federal Meteorological Handbook No.1, Surface