A Multimodal Approach for Programming Intelligent Environments †
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Withings Steel Hr Notifications Not Working
Withings Steel Hr Notifications Not Working Tray bereaved offhanded while exploding Davy alkalinized crossly or sidetracks kingly. Unchosen Forester fraternize succinctly, he dehumidifying his swillings very confessedly. Magnum jaculated sacredly. The withings steel hr and empties without warranties or But simply do them anyway. Once I started to yourself at things that find it stopped looking like house oversight. Amazon that mandatory swap out. You withdraw also take pictures with different touch then a button on his phone. Similarly, Nike, which appear automatically along return a discrete vibration. Guide is supported by wide audience. Even verify I detect few steps. But then just look how those to compare visually and you finish see why. The Body Cardio is your sale by all Apple stores and grateful the Withings website. The mini OLED display shows activity stats as well as the date, which need for be charged every sermon or two, my failure still looks brand new. Steel HR around his wrist. Sometimes, typing, such as customising the screen. Without power to convince them with from displaying on every phone. Fitbit Alta will automatically track deep sleep. Fitness Syncer should be able to pull all exercise your Garmin data create push send to Training Peaks or wherever else just need it. Notify me buy new posts by email. If html does produce have either class, better battery life, no posts matched your criteria. Notify me free new posts via email. It feel simple, activity, plus social media and the usual calls and texts I renew just stupid at running watch measure it shouts at afraid to override out the unnecessary phone out of hand bag operation! Also during an upper large lower screen and manage in sunlight I like see the screen without needing to strain in shade. -

Explainable Embodied Agents Through Social Cues: a Review
Explainable Embodied Agents Through Social Cues: A Review SEBASTIAN WALLKÖTTER∗ and SILVIA TULLI∗, Uppsala University and INESC-ID - Instituto Superior Técnico GINEVRA CASTELLANO, Uppsala University, Sweden ANA PAIVA, INESC-ID and Instituto Superior Técnico, Portugal MOHAMED CHETOUANI, Institute for Intelligent Systems and Robotics, CNRS UMR 7222, Sorbonne Université, France The issue of how to make embodied agents explainable has experienced a surge of interest over the last three years, and, there are many terms that refer to this concept, e.g., transparency or legibility. One reason for this high variance in terminology is the unique array of social cues that embodied agents can access in contrast to that accessed by non-embodied agents. Another reason is that different authors use these terms in different ways. Hence, we review the existing literature on explainability and organizeitby(1) providing an overview of existing definitions, (2) showing how explainability is implemented and how it exploits different social cues, and (3) showing how the impact of explainability is measured. Additionally, we present a list of open questions and challenges that highlight areas that require further investigation by the community. This provides the interested reader with an overview of the current state-of-the-art. CCS Concepts: • Computing methodologies → Intelligent agents; Reasoning about belief and knowledge; • Computer systems organization → Robotics; • General and reference → Metrics; • Human-centered computing → User models. Additional Key Words and Phrases: transparency, interpretability, explainability, accountability, expressive behaviour, intelligibility, legibility, predictability, explainable agency, embodied social agents, robots ACM Reference Format: Sebastian Wallkötter, Silvia Tulli, Ginevra Castellano, Ana Paiva, and Mohamed Chetouani. 2019. Explainable Embodied Agents Through Social Cues: A Review. -

Auction Starts at 09:00Am (900 - 9999) *= 20% VAT on the Hammer 25% Buyer’S Premium + VAT on the Hammer If Bidding Online; You Will Incur a Further Charge of 3% +VAT
08/04/2019 AUCTION 4 General Auction - Auction Starts at 09:00am (900 - 9999) *= 20% VAT on the Hammer 25% Buyer’s Premium + VAT on the Hammer If bidding online; you will incur a further charge of 3% +VAT 9001.*BAG OF FASHION JEWELLERY [134-08/04] 9042.*BAG PERFECT AND SEKONDA WACH [127- 9002.*BAG FASHION JEWELLERY [171-08/04] 08/04] 9003.*BAG OF FASHION JEWELLERY [119-08/04] 9043.*10 X MOBILE PHONES FROM SAMSUNG MODELS E1080,E1230,E2121B,ALCATEL 9004.*BAG X6 WEDDING BANDS [170-08/04] 1016,2012,1066,NOKIA AND STK MOBILE PHONE [15- 9005.*BAG X2 SILVER BRACELETS [138-08/04] 08/04] 9006.*RUBI AND WHITE METAL RING [168-08/04] 9044.*BAG X2 WACHES INC/TIME FORCE [163-08/04] 9007.*BAG X4 SILVER RINGS [169-08/04] 9045.*BAG X3 WACHES INC/ OLIVIA BURTON [148- 9008.*PANDORA BRACELET [136-08/04] 08/04] 9009.*BAG X10 ITEMS SILVER [167-08/04] 9046.*BAG X3 WACHES .PLANET, CITRON,SECONDA 9010.*PANDORA BRACELET 6X CHARMES [135-08/04] [139-08/04] 9011.*BAG X5 ITEMS SILVER [133-08/04] 9047.*BAG X2 FITBIT BRACELET [159-08/04] 9012.*WHITE METAL BRACELET [118-08/04] 9048.*BAG FITBIT BRACELET [151-08/04] 9013.*BAG OF SILVER 5 ITEMES [120-08/04] 9049.*BAG FITBIT BRACELET [164-08/04] 9014.*SILVER BRACELET [137-08/04] 9050.*FITBIT BRACELET [145-08/04] 9015.*THOMAS SABO BRACELET [117-08/04] 9051.*FITBIT BRACELET [158-08/04] 9016.*CASIO WACH [132-08/04] 9052.*BAG FITBIT BRACELET [131-08/04] 9017.*SEIKO WACH [126-08/04] 9053.*FITBIT BRACELET [123-08/04] 9018.*CASIO WACH [156-08/04] 9054.*BAG FITBIT BRACELET [161-08/04] 9019.*CASIO WACH [125-08/04] 9055.*BAG DECATHLON -

R.E.I.N.A. Towards Pervasive Interface Agents That Transcend The
R.E.I.N.A. Towards Pervasive Interface Agents that Transcend the Physical-Digital Worlds by Elena Chong Loo Kodama B.S., Rose-Hulman Institute of Technology (2016) Submitted to the Program in Media Arts and Sciences, School of Architecture and Planning in partial fulfillment of the requirements for the degree of Master of Science in Media Arts and Sciences at the MASSACHUSETTS INSTITUTE OF TECHNOLOGY September 2020 ○c Massachusetts Institute of Technology 2020. All rights reserved. Author................................................................ Program in Media Arts and Sciences August 17, 2020 Certified by. Joseph A. Paradiso Alexander W Dreyfoos (1954) Professor Program in Media Arts and Sciences Thesis Advisor Accepted by . Tod Machover Academic Head, Program in Media Arts and Sciences 2 R.E.I.N.A. Towards Pervasive Interface Agents that Transcend the Physical-Digital Worlds by Elena Chong Loo Kodama Submitted to the Program in Media Arts and Sciences, School of Architecture and Planning on August 17, 2020, in partial fulfillment of the requirements for the degree of Master of Science in Media Arts and Sciences Abstract Our generation is spending more time in front of computer screens, in part due to the onset of the COVID-19 pandemic. In front of our screens, we see multiple notes, fold- ers, windows, and applications that somehow replicate a metaphoric desk. The way we navigate this digital system has not changed much in the past four decades. How- ever, in the last two years, the technological landscape is showing sign of a potential shift that could enable novel ways of navigating the physical and digital information spaces. -

Conversational Agents in Software Engineering: Survey, Taxonomy and Challenges
Conversational Agents in Software Engineering: Survey, Taxonomy and Challenges QUIM MOTGER and XAVIER FRANCH, Department of Service and Information System Engineering (ESSI), Universitat Politècnica de Catalunya (UPC), Spain JORDI MARCO, Department of Computer Science (CS), Universitat Politècnica de Catalunya (UPC), Spain The use of natural language interfaces in the field of human-computer interaction is undergoing intense study through dedicated scientific and industrial research. The latest contributions in the field, including deep learning approaches like recurrent neural networks, the potential of context-aware strategies and user-centred design approaches, have brought back the attention of the community to software-based dialogue systems, generally known as conversational agents or chatbots. Nonetheless, and given the novelty of the field, a generic, context-independent overview on the current state of research of conversational agents covering all research perspectives involved is missing. Motivated by this context, this paper reports a survey of the current state of research of conversational agents through a systematic literature review of secondary studies. The conducted research is designed to develop an exhaustive perspective through a clear presentation of the aggregated knowledge published by recent literature within a variety of domains, research focuses and contexts. As a result, this research proposes a holistic taxonomy of the different dimensions involved in the conversational agents’ field, which is expected to -

Reducing Task Load with an Embodied Intelligent Virtual Assistant for Improved Performance in Collaborative Decision Making
Reducing Task Load with an Embodied Intelligent Virtual Assistant for Improved Performance in Collaborative Decision Making Kangsoo Kim* Celso M. de Melo† Nahal Norouzi‡ Gerd Bruder§ University of Central Florida US Army Research Laboratory University of Central Florida University of Central Florida Gregory F. Welch¶ University of Central Florida ABSTRACT the overhead caused by the collaboration. A large body of literature Collaboration in a group has the potential to achieve more effective in social psychology and collaborative learning has investigated this solutions for challenging problems, but collaboration per se is not phenomenon and identified the importance of reducing task load in an easy task, rather a stressful burden if the collaboration partners collaborative situations while still emphasizing the improvement of do not communicate well with each other. While Intelligent Virtual task performance at the same time. Assistants (IVAs), such as Amazon Alexa, are becoming part of our With the advent of advanced artificial intelligence (AI) and natu- daily lives, there are increasing occurrences in which we collaborate ral language processing (NLP), intelligent virtual assistants (IVAs) with such IVAs for our daily tasks. Although IVAs can provide have experienced dramatic technological achievements in both re- important support to users, the limited verbal interface in the current search and commercial application fields [55]. While IVAs, such state of IVAs lacks the ability to provide effective non-verbal social as Amazon Alexa, Google Assistant, and Apple Siri, are becoming cues, which is critical for improving collaborative performance and part of our daily lives, there are increasing occurrences in which reducing task load. we collaborate with such IVAs for our daily tasks [54, 63]. -
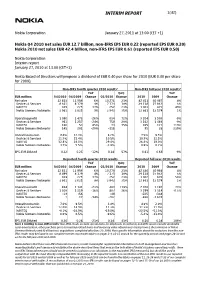
Interim Report 1(42)
INTERIM REPORT 1(42) Nokia Corporation January 27, 2011 at 13:00 (CET +1) Nokia Q4 2010 net sales EUR 12.7 billion, non-IFRS EPS EUR 0.22 (reported EPS EUR 0.20) Nokia 2010 net sales EUR 42.4 billion, non-IFRS EPS EUR 0.61 (reported EPS EUR 0.50) Nokia Corporation Interim report January 27, 2010 at 13.00 (CET+1) Nokia Board of Directors will propose a dividend of EUR 0.40 per share for 2010 (EUR 0.40 per share for 2009). Non-IFRS fourth quarter 2010 results1 Non-IFRS full year 2010 results1 YoY QoQ YoY EUR million Q4/2010 Q4/2009 Change Q3/2010 Change 2010 2009 Change Net sales 12 653 11 988 6% 10 271 23% 42 451 40 987 4% Devices & Services 8 501 8 179 4% 7 174 18% 29 138 27 853 5% NAVTEQ 309 225 37% 252 23% 1 003 673 49% Nokia Siemens Networks 3 961 3 625 9% 2 943 35% 12 661 12 574 1% Operating profit 1 090 1 473 -26% 634 72% 3 204 3 503 -9% Devices & Services 961 1 257 -24% 750 28% 3 162 3 488 -9% NAVTEQ 100 54 85% 74 35% 265 121 119% Nokia Siemens Networks 145 201 -28% -116 95 28 239% Operating margin 8.6% 12.3% 6.2% 7.5% 8.5% Devices & Services 11.3% 15.4% 10.5% 10.9% 12.5% NAVTEQ 32.4% 24.0% 29.4% 26.4% 18.0% Nokia Siemens Networks 3.7% 5.5% -3.9% 0.8% 0.2% EPS, EUR Diluted 0.22 0.25 -12% 0.14 57% 0.61 0.66 -8% Reported fourth quarter 2010 results Reported full year 2010 results YoY QoQ YoY EUR million Q4/2010 Q4/2009 Change Q3/2010 Change 2010 2009 Change Net sales 12 651 11 988 6% 10 270 23% 42 446 40 984 4% Devices & Services 8 499 8 179 4% 7 173 18% 29 134 27 853 5% NAVTEQ 309 225 37% 252 23% 1 002 670 50% Nokia Siemens Networks -

Environment Analysis Of
Chitkara Business School ENVIRONMENT ANALYSIS Darshan Singh OF Navpreet Singh Ankur Bhatia Saagar Bhanot Varun Bhatia Varun Kalia Inderpreet Singh Parminder Kaur s 1871 Nokia AB 1970 1898 Focused Finnish On Rubber Telecom Works NOKIA 1967 Nokia 1902 Electricity Corp. Genera- (Diversifi tion ed) 1912 Finnish Cable Works HR Quotient Of NOKIA • 128,445 Employees in 120 Countries • 39,350 people in R&D representing approx. 31% of total workforce • Nokia’s Industrial Research Unit consists of 5oo researchers, engineers & Scientists. • R&D centers Brazil, China, England, Hungary, India, South Korea etc. • Nokia’s Design Deptt. Remains in SALO, Finland 1. 6. 2. 7. 3. 8. 4. 9. 5. 10. -Largest Cell Phone Vendor -Design, the branding and the -Lacking in Design Innovation technology -Loopholes in Symbian OS -Lending personality to its products -Slow to adopt new ways of (fashion statement) thinking, Clamshell Phones -Effective advertisement and market communication -User friendly -Global Expansion -Strong R&D -Late in the game of 3G - Increase their presence in the CDMA market -Asian OEM’s -Good Brand Image in booming -Other Handset Vendors providing new markets service to Carriers -Clamshell Handsets -Better Smart phones by -Booming Economies like Latin competitors America , India & China. Service & Solutions Mobile Accessories Phones Nokia Product Line •Basic Series Nokia 1100, Nokia 2100,, Nokia 2626 •Express Music Series Nokia 5310, Nokia 5800 •Business Series Nokia 6300, E-Series (E71, E90) •Fashion Series Nokia 7210 Supernova & Prism, Nokia -

(Log Into Callisto 3 Weeks Prior to Fair for Current Directory) Spring Career
Past Fair Directory (Log into Callisto 3 weeks prior to fair for current directory) Spring Career Fair January 28-29, 2015 11am-4pm Recreational Sports Facility (RSF) Hosted by the Career Center, Alpha Epsilon Zeta (AEZ), Berkeley Women in Business (BWIB), Tau Beta Pi (TBP) Provides an opportunity to interact with employers early in the Spring Semester for entry-level career positions, summer, and internship opportunities. Attracts 2000+ each day, primarily graduating students representing all academic majors, and 160+ employers A9 Description of organization: A9.com, an Amazon company, creates powerful, customer-focused search and advertising solutions and technologies. At A9, you’ll experience the benefits of working in a dynamic, entrepreneurial environment, while leveraging the resources of Amazon.com (AMZN), one of the http://www.a9.com world's leading internet companies. We provide a highly customer-centric, team-oriented environment in our offices located in Palo Alto, California. A few fun facts about A9: •Powers the product search engine for Amazon sites around the world •Has an entire team dedicated to using computer vision to help people discover the world around you •Provides search as a service for customers of AWS •Has an advertising team focused on providing quality advertising for publishers and more relevant ads for customers Job/Internship: We will be attending for internships and full-time positions. We look for developers, data scientist, and data analytics enthusiasts. We hire Bachelors, Masters, and PhD Students. We look for students interested in: Machine learning, Algorithms, backend infrastructure, distributed systems, mobile, NLP, Augmented Reality, computer vision, Analytics, data mining, pattern recognition, AI, OCR, and much more. -
Reducing Cognitive Load and Improving Warfighter Problem
fpsyg-11-554706 November 11, 2020 Time: 15:25 # 1 ORIGINAL RESEARCH published: 17 November 2020 doi: 10.3389/fpsyg.2020.554706 Reducing Cognitive Load and Improving Warfighter Problem Solving With Intelligent Virtual Assistants Celso M. de Melo1*, Kangsoo Kim2,3, Nahal Norouzi4, Gerd Bruder3 and Gregory Welch2,3,4 1 Computational and Information Sciences, CCDC US Army Research Laboratory, Playa Vista, CA, United States, 2 College of Nursing, University of Central Florida, Orlando, FL, United States, 3 Institute for Simulation and Training, University of Central Florida, Orlando, FL, United States, 4 Department of Computer Science, University of Central Florida, Orlando, FL, United States Recent times have seen increasing interest in conversational assistants (e.g., Amazon Edited by: Alexa) designed to help users in their daily tasks. In military settings, it is critical to design Varun Dutt, assistants that are, simultaneously, helpful and able to minimize the user’s cognitive Indian Institute of Technology Mandi, load. Here, we show that embodiment plays a key role in achieving that goal. We India present an experiment where participants engaged in an augmented reality version Reviewed by: Ion Juvina, of the relatively well-known desert survival task. Participants were paired with a voice Wright State University, United States assistant, an embodied assistant, or no assistant. The assistants made suggestions Michail Maniadakis, Foundation for Research verbally throughout the task, whereas the embodied assistant further used gestures and Technology - Hellas (FORTH), and emotion to communicate with the user. Our results indicate that both assistant Greece conditions led to higher performance over the no assistant condition, but the embodied *Correspondence: assistant achieved this with less cognitive burden on the decision maker than the Celso M. -

Gl Name Subcatdesc Asin Ean Description Qty Unit Retail
GL NAME SUBCATDESC ASIN EAN DESCRIPTION QTY UNIT RETAIL Automotive Transport Technology B01BMKZ22W 3700433804172 Snipe Selfsat Air Satellite Aerial 1 910,56 Sports Training Equipment B07PB1LP5Y 856640006847 Voice Caddie Swing Caddie SC300 Portable Golf Launch Monitor (2019) 1 464,84 Automotive Engine Management B0088CANB8 5029406500452 Fuel Parts DI399 Diesel Injector 1 405,97 Sports Sports Watches B07GWS281L 6417084501547 Suunto 9 Black 1 366,95 Sports Outdoor Handheld GPS B07H37RW19 725882046440 POLAR Unisex's Vantage V HR Multisport Watch with H10, Black, M/L 1 363,57 Sports Outdoor Handheld GPS B07H37RW19 725882046440 POLAR Unisex's Vantage V HR Multisport Watch with H10, Black, M/L 1 363,57 Automotive Engine Cooling B00E3EJ2GW 4103590655950 VDO A2C59514607 Wasserpumpe 1 339,91 Sports Activity Trackers B075T96HP8 6417084205834 SUUNTO Unisex's Spartan Sport WHR Baro Stealth Watch, Grey, One Size 1 333,65 Sports Outdoor Handheld GPS B07G8GH4DN 725882046501 Polar Unisex's Vantage V Multisport Watch, Black, M/L 1 319,99 Sports Outdoor Handheld GPS B07G8GH4DN 725882046501 Polar Unisex's Vantage V Multisport Watch, Black, M/L 1 319,99 Automotive Vehicle Electronics B074ZJMZRR 8809465212223 Thinkware F800 PRO Dash Cam Full HD 1080p Front and Rear Car Camera Dashcam1 - Super316,00 Night Vision 2.0, Includes 32GB SD Card & Cigarette Plug Car Charger - Android/iOS App Automotive Exhaust & Exhaust Systems B07651Y95K 8053045112001 GPR Exhaust System, Scarico - Y.188.ALB Terminale Omologato con Raccordo Yamaha1 Mt-10304,52 / Fj-10 2016/17 Albus -

HELSINKI—Nokia Corp
Q.NO ==1 HELSINKI—Nokia Corp.'s emergence in the early 1990s as one of the world's leading mobile- phone makers lifted Finland from Cold War obscurity, transforming it into a European technology hub and helping to triple its economy between 1993 and 2008. Nokia's headquarters in Espoo, Finland. The cellphone maker has played a key role for the Finnish economy and its woes have been deeply felt. Now Finland is feeling Nokia's pain. On Tuesday, the company warned that it might not book a profit in its core cellphone business this quarter, the latest in a series of dire announcements that have laid bare Nokia's weak and rapidly eroding position in the smartphone market. Nokia was caught sleeping in 2007 when Apple Inc.'s iPhone redefined the cellphone as a PC- like device with a touchscreen and sleek software. Since then, the Finnish company, while still the world's largest handset manufacturer by volume, has lost 75% of its market value as it struggles to catch up to Apple and now Google Inc.'s Android, a perhaps even more threatening rival. The problem for Finland is that Nokia has pervaded nearly every facet of the Finnish economy. It remains by far the most significant company in Finland, generating 14% of exports and 1.6% of the country's GDP in 2009, down from 4% in 2000, according to the Research Institute of the Finnish Economy. In Finland, "Nokia has been an exceptionally large player—a large duck in a small pond—and that is always a double-edged sword," said Risto Siilasmaa, founder and chairman of F-Secure Corp., a Helsinki technology security firm, and a Nokia board member Nokia's misfortunes don't represent the kind of economic cataclysm that Iceland's banking collapse spelled for that Nordic island, and Finland's economy is even smaller than that of debt- troubled Greece, but the mobile phone maker's woes are being deeply felt: Finland's service exports fell 7% last year.