Extraction of Dynamic Patterns from Static Rna Expression Data: an Application to Hematological Neoplasms
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Defining Functional Interactions During Biogenesis of Epithelial Junctions
ARTICLE Received 11 Dec 2015 | Accepted 13 Oct 2016 | Published 6 Dec 2016 | Updated 5 Jan 2017 DOI: 10.1038/ncomms13542 OPEN Defining functional interactions during biogenesis of epithelial junctions J.C. Erasmus1,*, S. Bruche1,*,w, L. Pizarro1,2,*, N. Maimari1,3,*, T. Poggioli1,w, C. Tomlinson4,J.Lees5, I. Zalivina1,w, A. Wheeler1,w, A. Alberts6, A. Russo2 & V.M.M. Braga1 In spite of extensive recent progress, a comprehensive understanding of how actin cytoskeleton remodelling supports stable junctions remains to be established. Here we design a platform that integrates actin functions with optimized phenotypic clustering and identify new cytoskeletal proteins, their functional hierarchy and pathways that modulate E-cadherin adhesion. Depletion of EEF1A, an actin bundling protein, increases E-cadherin levels at junctions without a corresponding reinforcement of cell–cell contacts. This unexpected result reflects a more dynamic and mobile junctional actin in EEF1A-depleted cells. A partner for EEF1A in cadherin contact maintenance is the formin DIAPH2, which interacts with EEF1A. In contrast, depletion of either the endocytic regulator TRIP10 or the Rho GTPase activator VAV2 reduces E-cadherin levels at junctions. TRIP10 binds to and requires VAV2 function for its junctional localization. Overall, we present new conceptual insights on junction stabilization, which integrate known and novel pathways with impact for epithelial morphogenesis, homeostasis and diseases. 1 National Heart and Lung Institute, Faculty of Medicine, Imperial College London, London SW7 2AZ, UK. 2 Computing Department, Imperial College London, London SW7 2AZ, UK. 3 Bioengineering Department, Faculty of Engineering, Imperial College London, London SW7 2AZ, UK. 4 Department of Surgery & Cancer, Faculty of Medicine, Imperial College London, London SW7 2AZ, UK. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Protein Identities in Evs Isolated from U87-MG GBM Cells As Determined by NG LC-MS/MS
Protein identities in EVs isolated from U87-MG GBM cells as determined by NG LC-MS/MS. No. Accession Description Σ Coverage Σ# Proteins Σ# Unique Peptides Σ# Peptides Σ# PSMs # AAs MW [kDa] calc. pI 1 A8MS94 Putative golgin subfamily A member 2-like protein 5 OS=Homo sapiens PE=5 SV=2 - [GG2L5_HUMAN] 100 1 1 7 88 110 12,03704523 5,681152344 2 P60660 Myosin light polypeptide 6 OS=Homo sapiens GN=MYL6 PE=1 SV=2 - [MYL6_HUMAN] 100 3 5 17 173 151 16,91913397 4,652832031 3 Q6ZYL4 General transcription factor IIH subunit 5 OS=Homo sapiens GN=GTF2H5 PE=1 SV=1 - [TF2H5_HUMAN] 98,59 1 1 4 13 71 8,048185945 4,652832031 4 P60709 Actin, cytoplasmic 1 OS=Homo sapiens GN=ACTB PE=1 SV=1 - [ACTB_HUMAN] 97,6 5 5 35 917 375 41,70973209 5,478027344 5 P13489 Ribonuclease inhibitor OS=Homo sapiens GN=RNH1 PE=1 SV=2 - [RINI_HUMAN] 96,75 1 12 37 173 461 49,94108966 4,817871094 6 P09382 Galectin-1 OS=Homo sapiens GN=LGALS1 PE=1 SV=2 - [LEG1_HUMAN] 96,3 1 7 14 283 135 14,70620005 5,503417969 7 P60174 Triosephosphate isomerase OS=Homo sapiens GN=TPI1 PE=1 SV=3 - [TPIS_HUMAN] 95,1 3 16 25 375 286 30,77169764 5,922363281 8 P04406 Glyceraldehyde-3-phosphate dehydrogenase OS=Homo sapiens GN=GAPDH PE=1 SV=3 - [G3P_HUMAN] 94,63 2 13 31 509 335 36,03039959 8,455566406 9 Q15185 Prostaglandin E synthase 3 OS=Homo sapiens GN=PTGES3 PE=1 SV=1 - [TEBP_HUMAN] 93,13 1 5 12 74 160 18,68541938 4,538574219 10 P09417 Dihydropteridine reductase OS=Homo sapiens GN=QDPR PE=1 SV=2 - [DHPR_HUMAN] 93,03 1 1 17 69 244 25,77302971 7,371582031 11 P01911 HLA class II histocompatibility antigen, -

Cellular and Molecular Signatures in the Disease Tissue of Early
Cellular and Molecular Signatures in the Disease Tissue of Early Rheumatoid Arthritis Stratify Clinical Response to csDMARD-Therapy and Predict Radiographic Progression Frances Humby1,* Myles Lewis1,* Nandhini Ramamoorthi2, Jason Hackney3, Michael Barnes1, Michele Bombardieri1, Francesca Setiadi2, Stephen Kelly1, Fabiola Bene1, Maria di Cicco1, Sudeh Riahi1, Vidalba Rocher-Ros1, Nora Ng1, Ilias Lazorou1, Rebecca E. Hands1, Desiree van der Heijde4, Robert Landewé5, Annette van der Helm-van Mil4, Alberto Cauli6, Iain B. McInnes7, Christopher D. Buckley8, Ernest Choy9, Peter Taylor10, Michael J. Townsend2 & Costantino Pitzalis1 1Centre for Experimental Medicine and Rheumatology, William Harvey Research Institute, Barts and The London School of Medicine and Dentistry, Queen Mary University of London, Charterhouse Square, London EC1M 6BQ, UK. Departments of 2Biomarker Discovery OMNI, 3Bioinformatics and Computational Biology, Genentech Research and Early Development, South San Francisco, California 94080 USA 4Department of Rheumatology, Leiden University Medical Center, The Netherlands 5Department of Clinical Immunology & Rheumatology, Amsterdam Rheumatology & Immunology Center, Amsterdam, The Netherlands 6Rheumatology Unit, Department of Medical Sciences, Policlinico of the University of Cagliari, Cagliari, Italy 7Institute of Infection, Immunity and Inflammation, University of Glasgow, Glasgow G12 8TA, UK 8Rheumatology Research Group, Institute of Inflammation and Ageing (IIA), University of Birmingham, Birmingham B15 2WB, UK 9Institute of -

Placenta-Derived Exosomes Continuously Increase in Maternal
Sarker et al. Journal of Translational Medicine 2014, 12:204 http://www.translational-medicine.com/content/12/1/204 RESEARCH Open Access Placenta-derived exosomes continuously increase in maternal circulation over the first trimester of pregnancy Suchismita Sarker1, Katherin Scholz-Romero1, Alejandra Perez2, Sebastian E Illanes1,2,3, Murray D Mitchell1, Gregory E Rice1,2 and Carlos Salomon1,2* Abstract Background: Human placenta releases specific nanovesicles (i.e. exosomes) into the maternal circulation during pregnancy, however, the presence of placenta-derived exosomes in maternal blood during early pregnancy remains to be established. The aim of this study was to characterise gestational age related changes in the concentration of placenta-derived exosomes during the first trimester of pregnancy (i.e. from 6 to 12 weeks) in plasma from women with normal pregnancies. Methods: A time-series experimental design was used to establish pregnancy-associated changes in maternal plasma exosome concentrations during the first trimester. A series of plasma were collected from normal healthy women (10 patients) at 6, 7, 8, 9, 10, 11 and 12 weeks of gestation (n = 70). We measured the stability of these vesicles by quantifying and observing their protein and miRNA contents after the freeze/thawing processes. Exosomes were isolated by differential and buoyant density centrifugation using a sucrose continuous gradient and characterised by their size distribution and morphology using the nanoparticles tracking analysis (NTA; Nanosight™) and electron microscopy (EM), respectively. The total number of exosomes and placenta-derived exosomes were determined by quantifying the immunoreactive exosomal marker, CD63 and a placenta-specific marker (Placental Alkaline Phosphatase PLAP). -

Whole Exome Sequencing in Families at High Risk for Hodgkin Lymphoma: Identification of a Predisposing Mutation in the KDR Gene
Hodgkin Lymphoma SUPPLEMENTARY APPENDIX Whole exome sequencing in families at high risk for Hodgkin lymphoma: identification of a predisposing mutation in the KDR gene Melissa Rotunno, 1 Mary L. McMaster, 1 Joseph Boland, 2 Sara Bass, 2 Xijun Zhang, 2 Laurie Burdett, 2 Belynda Hicks, 2 Sarangan Ravichandran, 3 Brian T. Luke, 3 Meredith Yeager, 2 Laura Fontaine, 4 Paula L. Hyland, 1 Alisa M. Goldstein, 1 NCI DCEG Cancer Sequencing Working Group, NCI DCEG Cancer Genomics Research Laboratory, Stephen J. Chanock, 5 Neil E. Caporaso, 1 Margaret A. Tucker, 6 and Lynn R. Goldin 1 1Genetic Epidemiology Branch, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; 2Cancer Genomics Research Laboratory, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; 3Ad - vanced Biomedical Computing Center, Leidos Biomedical Research Inc.; Frederick National Laboratory for Cancer Research, Frederick, MD; 4Westat, Inc., Rockville MD; 5Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD; and 6Human Genetics Program, Division of Cancer Epidemiology and Genetics, National Cancer Institute, NIH, Bethesda, MD, USA ©2016 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol.2015.135475 Received: August 19, 2015. Accepted: January 7, 2016. Pre-published: June 13, 2016. Correspondence: [email protected] Supplemental Author Information: NCI DCEG Cancer Sequencing Working Group: Mark H. Greene, Allan Hildesheim, Nan Hu, Maria Theresa Landi, Jennifer Loud, Phuong Mai, Lisa Mirabello, Lindsay Morton, Dilys Parry, Anand Pathak, Douglas R. Stewart, Philip R. Taylor, Geoffrey S. Tobias, Xiaohong R. Yang, Guoqin Yu NCI DCEG Cancer Genomics Research Laboratory: Salma Chowdhury, Michael Cullen, Casey Dagnall, Herbert Higson, Amy A. -

Identification of Key Pathways and Genes in Dementia Via Integrated Bioinformatics Analysis
bioRxiv preprint doi: https://doi.org/10.1101/2021.04.18.440371; this version posted July 19, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Identification of Key Pathways and Genes in Dementia via Integrated Bioinformatics Analysis Basavaraj Vastrad1, Chanabasayya Vastrad*2 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karnataka, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India bioRxiv preprint doi: https://doi.org/10.1101/2021.04.18.440371; this version posted July 19, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract To provide a better understanding of dementia at the molecular level, this study aimed to identify the genes and key pathways associated with dementia by using integrated bioinformatics analysis. Based on the expression profiling by high throughput sequencing dataset GSE153960 derived from the Gene Expression Omnibus (GEO), the differentially expressed genes (DEGs) between patients with dementia and healthy controls were identified. With DEGs, we performed a series of functional enrichment analyses. Then, a protein–protein interaction (PPI) network, modules, miRNA-hub gene regulatory network and TF-hub gene regulatory network was constructed, analyzed and visualized, with which the hub genes miRNAs and TFs nodes were screened out. Finally, validation of hub genes was performed by using receiver operating characteristic curve (ROC) analysis. -

Genetic Variability in a Holstein Population Using SNP Markers and Their Use for Monitoring Mating Strategies
https://doi.org/10.22319/rmcp.v10i3.4842 Article Genetic variability in a Holstein population using SNP markers and their use for monitoring mating strategies Kathy Scienski a,b,c Angelo Ialacci c Alessandro Bagnato c Davide Reginelli d Marina Durán-Aguilar e Maria Giuseppina Strillacci c* a Texas A&M University, College Station. Interdisciplinary Program in Genetics. Texas, USA. b Texas A&M University. Department of Animal Science, Texas, USA. c Università degli Studi di Milano. Department of Veterinary Medicine, Via Trentacoste 2, 20134 Milano, Italy. d Università degli Studi di Milano. Azienda Agraria Didattico Sperimentale Angelo Menozzi, Landriano, Pavia, Italy. e Universidad Autónoma de Querétaro. Facultad de Ciencias Naturales. Querétaro. México. * Corresponding author: [email protected] Abstract: As genotyping costs continue to decrease, the demand for genotyping has increased among farmers. In most livestock herds, an important issue is controlling the increase in inbreeding coefficient. While this remains a large motive to genotype, producers are often unaware of the other benefits that genotyping could bring. The aim of this study was to demonstrate that SNP chips could be used as an effective herd management tool by utilizing a population of Italian Holstein-Friesian cattle. After filtering, the total number 643 Rev Mex Cienc Pecu 2019;10(3):643-663 of animals and SNPs retained for analyses were 44 and 27,365, respectively. The principal component analyses (PCA) were able to identify a sire and origin-of-sire effect within the herd, while determining that sires do not influence individual genomic selection index values. The inbreeding coefficients calculated from genotypes (FIS) provided a glimpse into the herd’s heterozygosity and determined that the genetic variability is being well maintained. -

Tumor Gene Chromosome Coordinate Variant Hgvsc Hgvsp ADAM29 4
Supplementary material J Clin Pathol Supplementary table 1 : Genetic alterations identified in the four tumors analyzed. Genetic alterations Tumor Gene Chromosome Coordinate Variant HGVSc HGVSp ADAM29 4 175899088 G>G/T NM_014269.4:c.2412G>T NP_055084.3:p.Arg804Ser ANKRD36 2 97833499 G>G/C NM_001164315.1:c.1628G>C NP_001157787.1:p.Gly543Ala CBX2 17 77757739 G>G/A NM_005189.2:c.497G>A NP_005180.1:p.Arg166Gln CDH1 16 68846080 C>C/T NM_004360.3:c.1051C>T NP_004351.1:p.Gln351Ter CDRT15 17 14139702 G>G/A NM_001007530.1:c.308C>T NP_001007531.1:p.Ala103Val CNIH3 1 224927032 A>A/T NM_152495.1:c.457A>T NP_689708.1:p.Met153Leu CTBP2 10 126686682 A>A/T NM_022802.2:c.2036T>A NP_073713.2:p.Ile679Asn CTBP2 10 126686692 C>C/T NM_022802.2:c.2026G>A NP_073713.2:p.Asp676Asn CX3CR1 3 39307802 C>C/T NM_001171174.1:c.295G>A NP_001164645.1:p.Asp99Asn FAM8A1 6 17601058 G>G/A NM_016255.2:c.418G>A NP_057339.1:p.Ala140Thr FOXC1 6 1611802 G>G/GGGC NM_001453.2:c.1139_1141dupGCG NP_001444.2:p.Gly380dup GBE1 3 81698058 C>C/T NM_000158.3:c.640G>A NP_000149.3:p.Ala214Thr HAUS4 14 23421618 A>A/C NM_017815.2:c.249T>G NP_060285.2:p.Ile83Met HES4 1 935076 T>T/A NM_001142467.1:c.278A>T NP_001135939.1:p.Lys93Ile HOMEZ 14 23745840 C>C/G NM_020834.2:c.597G>C NP_065885.2:p.Gln199His ICAM5 19 10404565 G>G/A NM_003259.3:c.1657G>A NP_003250.3:p.Glu553Lys IL32 16 3119297 C>C/CG NM_004221.4:c.514dupG NP_004212.4:p.Asp172GlyfsTer12 IQSEC2 X 53264161 G>G/A NM_001111125.2:c.3707C>T NP_001104595.1:p.Ser1236Phe IVL 1 152883493 T>T/A NM_005547.2:c.1220T>A NP_005538.2:p.Val407Glu KIR2DL1 -

Mouse Sptbn5 Conditional Knockout Project (CRISPR/Cas9)
https://www.alphaknockout.com Mouse Sptbn5 Conditional Knockout Project (CRISPR/Cas9) Objective: To create a Sptbn5 conditional knockout Mouse model (C57BL/6J) by CRISPR/Cas-mediated genome engineering. Strategy summary: The Sptbn5 gene (NCBI Reference Sequence: NM_001370938 ; Ensembl: ENSMUSG00000074899 ) is located on Mouse chromosome 2. 66 exons are identified, with the ATG start codon in exon 1 and the TAA stop codon in exon 66 (Transcript: ENSMUST00000156159). Exon 15~17 will be selected as conditional knockout region (cKO region). Deletion of this region should result in the loss of function of the Mouse Sptbn5 gene. To engineer the targeting vector, homologous arms and cKO region will be generated by PCR using BAC clone RP23-250P21 as template. Cas9, gRNA and targeting vector will be co-injected into fertilized eggs for cKO Mouse production. The pups will be genotyped by PCR followed by sequencing analysis. Note: Exon 15 starts from about 25.37% of the coding region. The knockout of Exon 15~17 will result in frameshift of the gene. The size of intron 14 for 5'-loxP site insertion: 1113 bp, and the size of intron 17 for 3'-loxP site insertion: 923 bp. The size of effective cKO region: ~1526 bp. The cKO region does not have any other known gene. Page 1 of 7 https://www.alphaknockout.com Overview of the Targeting Strategy Wildtype allele 5' gRNA region gRNA region 3' 1 13 14 15 16 17 18 19 66 Targeting vector Targeted allele Constitutive KO allele (After Cre recombination) Legends Exon of mouse Sptbn5 Homology arm cKO region loxP site Page 2 of 7 https://www.alphaknockout.com Overview of the Dot Plot Window size: 10 bp Forward Reverse Complement Sequence 12 Note: The sequence of homologous arms and cKO region is aligned with itself to determine if there are tandem repeats. -
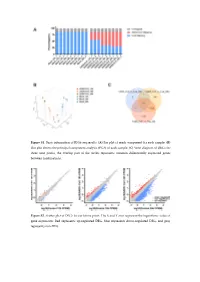
Figure S1. Basic Information of RNA-Seq Results. (A) Bar Plot of Reads Component for Each Sample
Figure S1. Basic information of RNA-seq results. (A) Bar plot of reads component for each sample. (B) Dot plot shows the principal component analysis (PCA) of each sample. (C) Venn diagram of DEGs for three time points, the overlap part of the circles represents common differentially expressed genes between combinations. Figure S2. Scatter plot of DEGs for each time point. The X and Y axes represent the logarithmic value of gene expression. Red represents up-regulated DEG, blue represents down-regulated DEG, and gray represents non-DEG. Table S1. Primers used for quantitative real-time PCR analysis of DEGs. Gene Primer Sequence Forward 5’-CTACGAGTGGATGGTCAAGAGC-3’ FOXO1 Reverse 5’-CCAGTTCCTTCATTCTGCACACG-3’ Forward 5’-GACGTCCGGCATCAGAGAAA-3’ IRS2 Reverse 5’-TCCACGGCTAATCGTCACAG-3’ Forward 5’-CACAACCAGGACCTCACACC-3’ IRS1 Reverse 5’-CTTGGCACGATAGAGAGCGT-3’ Forward 5’-AGGATACCACTCCCAACAGACCT-3’ IL6 Reverse 5’-CAAGTGCATCATCGTTGTTCATAC-3’ Forward 5’-TCACGTTGTACGCAGCTACC-3’ CCL5 Reverse 5’-CAGTCCTCTTACAGCCTTTGG-3’ Forward 5’-CTGTGCAGCCGCAGTGCCTACC-3’ BMP7 Reverse 5’-ATCCCTCCCCACCCCACCATCT-3’ Forward 5’-CTCTCCCCCTCGACTTCTGA-3’ BCL2 Reverse 5’-AGTCACGCGGAACACTTGAT-3’ Forward 5’-CTGTCGAACACAGTGGTACCTG-3’ FGF7 Reverse 5’-CCAACTGCCACTGTCCTGATTTC-3’ Forward 5’-GGGAGCCAAAAGGGTCATCA-3’ GAPDH Reverse 5’-CGTGGACTGTGGTCATGAGT-3’ Supplementary material: Differentially expressed genes log2(SADS-CoV_12h/ Qvalue (SADS-CoV _12h/ Gene Symbol Control_12h) Control_12h) PTGER4 -1.03693 6.79E-04 TMEM72 -3.08132 3.66E-04 IFIT2 -1.02918 2.11E-07 FRAT2 -1.09282 4.66E-05 -

Αii-Spectrin and Βii-Spectrin Do Not Affect Tgfβ1-Induced Myofibroblast Differentiation
Cell and Tissue Research https://doi.org/10.1007/s00441-018-2842-x REGULAR ARTICLE αII-spectrin and βII-spectrin do not affect TGFβ1-induced myofibroblast differentiation Bram Piersma1 & Olaf Y. Wouters1 & Ruud A. Bank1 Received: 16 May 2017 /Accepted: 10 April 2018 # The Author(s) 2018 Abstract Mechanosensing of fibroblasts plays a key role in the development of fibrosis. So far, no effective treatments are available to treat this devastating disorder. Spectrins regulate cell morphology and are potential mechanosensors in a variety of non-erythroid cells, but little is known about the role of spectrins in fibroblasts. We investigate whether αII- and βII-spectrin are required for the phenotypic properties of adult human dermal (myo)fibroblasts. Knockdown of αII- or βII-spectrin in fibroblasts did not affect cell adhesion, cell size and YAP nuclear/cytosolic localization. We further investigated whether αII- and βII-spectrin play a role in the phenotypical switch from fibroblasts to myofibroblasts under the influence of the pro-fibrotic cytokine TGFβ1. Knockdown of spectrins did not affect myofibroblast formation, nor did we observe changes in the organization of αSMA stress fibers. Focal adhesion assembly was unaffected by spectrin deficiency, as was collagen type I mRNA expression and protein deposition. Wound closure was unaffected as well, showing that important functional properties of myofibroblasts are unchanged without αII- or βII-spectrin. In fact, fibroblasts stimulated with TGFβ1 demonstrated significantly lower endogenous mRNA levels of αII- and βII-spectrin. Taken together, despite the diverse roles of spectrins in a variety of other cells, αII- and βII-spectrin do not regulate cell adhesion, cell size and YAP localization in human dermal fibroblasts and are not required for the dermal myofibroblast phenotypical switch.