Merging Statistics and Geospatial Information EXPERIENCES and OBSERVATIONS from NATIONAL STATISTICAL AUTHORITIES, 2012-2015 PROJECTS 2019 Edition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

List of Participants
List of participants Conference of European Statisticians 69th Plenary Session, hybrid Wednesday, June 23 – Friday 25 June 2021 Registered participants Governments Albania Ms. Elsa DHULI Director General Institute of Statistics Ms. Vjollca SIMONI Head of International Cooperation and European Integration Sector Institute of Statistics Albania Argentina Sr. Joaquin MARCONI Advisor in International Relations, INDEC Mr. Nicolás PETRESKY International Relations Coordinator National Institute of Statistics and Censuses (INDEC) Elena HASAPOV ARAGONÉS National Institute of Statistics and Censuses (INDEC) Armenia Mr. Stepan MNATSAKANYAN President Statistical Committee of the Republic of Armenia Ms. Anahit SAFYAN Member of the State Council on Statistics Statistical Committee of RA Australia Mr. David GRUEN Australian Statistician Australian Bureau of Statistics 1 Ms. Teresa DICKINSON Deputy Australian Statistician Australian Bureau of Statistics Ms. Helen WILSON Deputy Australian Statistician Australian Bureau of Statistics Austria Mr. Tobias THOMAS Director General Statistics Austria Ms. Brigitte GRANDITS Head International Relation Statistics Austria Azerbaijan Mr. Farhad ALIYEV Deputy Head of Department State Statistical Committee Mr. Yusif YUSIFOV Deputy Chairman The State Statistical Committee Belarus Ms. Inna MEDVEDEVA Chairperson National Statistical Committee of the Republic of Belarus Ms. Irina MAZAISKAYA Head of International Cooperation and Statistical Information Dissemination Department National Statistical Committee of the Republic of Belarus Ms. Elena KUKHAREVICH First Deputy Chairperson National Statistical Committee of the Republic of Belarus Belgium Mr. Roeland BEERTEN Flanders Statistics Authority Mr. Olivier GODDEERIS Head of international Strategy and coordination Statistics Belgium 2 Bosnia and Herzegovina Ms. Vesna ĆUŽIĆ Director Agency for Statistics Brazil Mr. Eduardo RIOS NETO President Instituto Brasileiro de Geografia e Estatística - IBGE Sra. -

United Nations Fundamental Principles of Official Statistics
UNITED NATIONS United Nations Fundamental Principles of Official Statistics Implementation Guidelines United Nations Fundamental Principles of Official Statistics Implementation guidelines (Final draft, subject to editing) (January 2015) Table of contents Foreword 3 Introduction 4 PART I: Implementation guidelines for the Fundamental Principles 8 RELEVANCE, IMPARTIALITY AND EQUAL ACCESS 9 PROFESSIONAL STANDARDS, SCIENTIFIC PRINCIPLES, AND PROFESSIONAL ETHICS 22 ACCOUNTABILITY AND TRANSPARENCY 31 PREVENTION OF MISUSE 38 SOURCES OF OFFICIAL STATISTICS 43 CONFIDENTIALITY 51 LEGISLATION 62 NATIONAL COORDINATION 68 USE OF INTERNATIONAL STANDARDS 80 INTERNATIONAL COOPERATION 91 ANNEX 98 Part II: Implementation guidelines on how to ensure independence 99 HOW TO ENSURE INDEPENDENCE 100 UN Fundamental Principles of Official Statistics – Implementation guidelines, 2015 2 Foreword The Fundamental Principles of Official Statistics (FPOS) are a pillar of the Global Statistical System. By enshrining our profound conviction and commitment that offi- cial statistics have to adhere to well-defined professional and scientific standards, they define us as a professional community, reaching across political, economic and cultural borders. They have stood the test of time and remain as relevant today as they were when they were first adopted over twenty years ago. In an appropriate recognition of their significance for all societies, who aspire to shape their own fates in an informed manner, the Fundamental Principles of Official Statistics were adopted on 29 January 2014 at the highest political level as a General Assembly resolution (A/RES/68/261). This is, for us, a moment of great pride, but also of great responsibility and opportunity. In order for the Principles to be more than just a statement of noble intentions, we need to renew our efforts, individually and collectively, to make them the basis of our day-to-day statistical work. -

Low Fertility in Austria and the Czech Republic: Gradual Policy Adjustments
A Service of Leibniz-Informationszentrum econstor Wirtschaft Leibniz Information Centre Make Your Publications Visible. zbw for Economics Sobotka, Tomáš Working Paper Low fertility in Austria and the Czech Republic: Gradual policy adjustments Vienna Institute of Demography Working Papers, No. 2/2015 Provided in Cooperation with: Vienna Institute of Demography (VID), Austrian Academy of Sciences Suggested Citation: Sobotka, Tomáš (2015) : Low fertility in Austria and the Czech Republic: Gradual policy adjustments, Vienna Institute of Demography Working Papers, No. 2/2015, Austrian Academy of Sciences (ÖAW), Vienna Institute of Demography (VID), Vienna This Version is available at: http://hdl.handle.net/10419/110987 Standard-Nutzungsbedingungen: Terms of use: Die Dokumente auf EconStor dürfen zu eigenen wissenschaftlichen Documents in EconStor may be saved and copied for your Zwecken und zum Privatgebrauch gespeichert und kopiert werden. personal and scholarly purposes. Sie dürfen die Dokumente nicht für öffentliche oder kommerzielle You are not to copy documents for public or commercial Zwecke vervielfältigen, öffentlich ausstellen, öffentlich zugänglich purposes, to exhibit the documents publicly, to make them machen, vertreiben oder anderweitig nutzen. publicly available on the internet, or to distribute or otherwise use the documents in public. Sofern die Verfasser die Dokumente unter Open-Content-Lizenzen (insbesondere CC-Lizenzen) zur Verfügung gestellt haben sollten, If the documents have been made available under an Open gelten -

Poland in the European Union. a Statistical Portrait”
POLSKA W UNII EUROPEJSKIEJ Poland in the European Union PORTRET STATYSTYCZNY A statistical portrait 2019 Warsaw Warszawa Warszawa POLSKA W UNII EUROPEJSKIEJ Poland in the European Union PORTRET STATYSTYCZNY A statistical portrait Warszawa Warsaw 2019 Opracowanie publikacji Content-related works Główny Urząd Statystyczny, Departament Opracowań Statystycznych Statistics Poland, Statistical Products Department Zespół autorski Editorial team Dominika Borek, Ewa Morytz-Balska, Justyna Gustyn, Anna Kozera, Joanna Kozłowska, Marcin Marikin, Marcin Safader, Anna Zielkowska, Maciej Żelechowski Kierujący Supervisor Magdalena Ambroch, Renata Bielak Skład i opracowanie graficzne Typesetting and graphics Marek Wilczyński Opracowanie map Map preparation Katarzyna Medolińska, Maciej Zych ISBN 978-83-7027-716-1 Publikacja dostępna na stronie Publication available on website http:/stat.gov.pl 00-925 WARSZAWA, AL. NIEPODLEGŁOŚCI 208. Informacje w sprawach sprzedaży publikacji — tel. (22) 608 32 10, 608 38 10 Zam. 10/2019/ nakł. Szanowni Państwo, W dniu 1 maja 2019 r. minęło 15 lat od przystąpienia Polski do Unii Europejskiej. Z tej okazji mam przyjemność przekazać Państwu publikację pt. „Polska w Unii Europejskiej. Portret statystyczny”. Lata obecności Polski w Unii Europejskiej to czas wielu przemian gospodarczych i społecznych, do których przyczyniło się otwarcie granic, uczestnictwo w jednolitym rynku europejskim oraz możliwość wykorzystania funduszy unijnych. To również okres rozwoju polskiej statystyki publicznej jako członka Europejskiego Systemu Statystycznego – czas doskonalenia metodologii i technik badawczych, podejmowania nowych tematów i eksploracji innowacyjnych źródeł danych. Zasoby informacji gromadzone w ramach Europejskiego Systemu Statystycznego zostały wykorzystane w niniejszej publikacji do zaprezentowania przemian, jakie od 2004 r. zaszły zarówno w Polsce, jak i w całej Unii Europejskiej. Oddanie pełnego spektrum tych zmian w zwięzłej formie jest zadaniem niemożliwym. -
European Big Data Hackathon
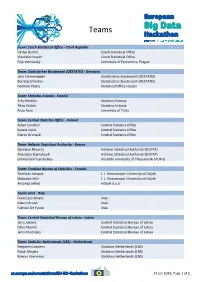
Teams Team: Czech Statistical Office - Czech Republic Václav Bartoš Czech Statistical Office Vlastislav Novák Czech Statistical Office Filip Vencovský University of Economics, Prague Team: Statistisches Bundesamt (DESTATIS) - Germany Jana Emmenegger Statistisches Bundesamt (DESTATIS) Bernhard Fischer Statistisches Bundesamt (DESTATIS) Normen Peters Statistical Office Hessen Team: Statistics Estonia - Estonia Arko Kesküla Statistics Estonia Tõnu Raitviir Statistics Estonia Anto Aasa University of Tartu Team: Central Statistics Office - Ireland Aidan Condron Central Statistics Office Sanela Jojkic Central Statistics Office Marco Grimaldi Central Statistics Office Team: Hellenic Statistical Authority - Greece Georgios Ntouros Hellenic Statistical Authority (ELSTAT) Anastasia Stamatoudi Hellenic Statistical Authority (ELSTAT) Emmanouil Tsardoulias Aristotle University of Thessaloniki (AUTH) Team: Croatian Bureau of Statistics - Croatia Tomislav Jakopec J. J. Strossmayer University of Osijek Slobodan Jelić J. J. Strossmayer University of Osijek Antonija Jelinić mStart d.o.o Team: Istat - Italy Francesco Amato Istat Mauro Bruno Istat Fabrizio De Fausti Istat Team: Central Statistical Bureau of Latvia - Latvia Janis Jukams Central Statistical Bureau of Latvia Dāvis Kļaviņš Central Statistical Bureau of Latvia Jānis Muižnieks Central Statistical Bureau of Latvia Team: Statistics Netherlands (CBS) - Netherlands Benjamin Laevens Statistics Netherlands (CBS) Ralph Meijers Statistics Netherlands (CBS) Rowan Voermans Statistics Netherlands (CBS) 31 -

Primary Energy Consumption in Selected EU Countries Compared to Global Trends
Open Chemistry 2021; 19: 503–510 Review Article Tadeusz Olkuski*, Wojciech Suwała, Artur Wyrwa, Janusz Zyśk, Barbara Tora Primary energy consumption in selected EU Countries compared to global trends https://doi.org/10.1515/chem-2021-0046 received February 3, 2021; accepted March 15, 2021 1 Introduction Abstract: The article shows the consumption of primary Primary energy consumption was once perceived as an energy carriers in selected European Union (EU) countries, indicator of the civilization development. The economic including Poland. The trend of consumption of primary progress of individual countries was measured by the energy carriers was compared with the global trend, which consumption of both primary and secondary energy, is different from that observed in the EU. The consumption the use of coal and steel, and electricity. In later years, of primary energy sources has been increasing steadily for it was realized that such a constant drive for development many decades, due to the growth of the world population through the unlimited increase in the use of natural resources and the aspirations of developing countries to raise the is ineffective and harmful to the natural environment. standard of living of their citizens. In the EU, the opposite Therefore, measures are taken to protect the natural trend, i.e., a decrease in primary energy consumption, has resources by making efficient use of them. The consumption been observed since 2007. This article presents tables and of primary energy carriers in selected European Union graphs showing these phenomena. The authors tried to (EU) countries, including Poland, is discussed further in answer the following questions: (a) What influences the this article. -

Annex 3: Sources, Methods and Technical Notes
Annex 3 EAG 2007 Education at a Glance OECD Indicators 2007 Annex 3: Sources 1 Annex 3 EAG 2007 SOURCES IN UOE DATA COLLECTION 2006 UNESCO/OECD/EUROSTAT (UOE) data collection on education statistics. National sources are: Australia: - Department of Education, Science and Training, Higher Education Group, Canberra; - Australian Bureau of Statistics (data on Finance; data on class size from a survey on Public and Private institutions from all states and territories). Austria: - Statistics Austria, Vienna; - Federal Ministry for Education, Science and Culture, Vienna (data on Graduates); (As from 03/2007: Federal Ministry for Education, the Arts and Culture; Federal Ministry for Science and Research) - The Austrian Federal Economic Chamber, Vienna (data on Graduates). Belgium: - Flemish Community: Flemish Ministry of Education and Training, Brussels; - French Community: Ministry of the French Community, Education, Research and Training Department, Brussels; - German-speaking Community: Ministry of the German-speaking Community, Eupen. Brazil: - Ministry of Education (MEC) - Brazilian Institute of Geography and Statistics (IBGE) Canada: - Statistics Canada, Ottawa. Chile: - Ministry of Education, Santiago. Czech Republic: - Institute for Information on Education, Prague; - Czech Statistical Office Denmark: - Ministry of Education, Budget Division, Copenhagen; - Statistics Denmark, Copenhagen. 2 Annex 3 EAG 2007 Estonia - Statistics office, Tallinn. Finland: - Statistics Finland, Helsinki; - National Board of Education, Helsinki (data on Finance). France: - Ministry of National Education, Higher Education and Research, Directorate of Evaluation and Planning, Paris. Germany: - Federal Statistical Office, Wiesbaden. Greece: - Ministry of National Education and Religious Affairs, Directorate of Investment Planning and Operational Research, Athens. Hungary: - Ministry of Education, Budapest; - Ministry of Finance, Budapest (data on Finance); Iceland: - Statistics Iceland, Reykjavik. -

Assessing Quality of Admin Data for Use in Censuses
UNITED NATIONS ECONOMIC COMMISSION FOR EUROPE Guidelines for Assessing the Quality of Administrative Sources for Use in Censuses Prepared by the Conference of European Statisticians Task Force on Assessing the Quality of Administrative Sources for Use in Censuses United Nations Geneva, 2021 Preface The main purpose of this publication is to provide the producers of population and housing censuses with guidance on how to assess the quality of administrative data for use in the census. The Guidelines cover the practical stages of assessment, from working with an administrative data supplier to understand a source, its strengths and limitations, all the way to the receipt and analysis of the actual data. The Guidelines cover key quality dimensions on which an assessment is made, using various tools and indicators. For completeness the Guidelines also include information about the processing and output stages of the census, with respect to the use of administrative sources. The publication was prepared by a Task Force established by the Conference of European Statisticians (CES), composed of experts from national statistics offices, and coordinated by the United Nations Economic Commission for Europe (UNECE). ii Acknowledgements These Guidelines were prepared by the UNECE Task Force on Assessing the Quality of Administrative Sources for Use in Censuses, consisting of the following individuals: Steven Dunstan (Chair), United Kingdom Paula Paulino, Portugal Katrin Tschoner, Austria Dmitrii Calincu, Republic of Moldova Christoph Waldner, Austria -

AGRICULTURAL SECTOR in ECONOMY of POLAND in 1950-2020. Stanisław Kowalczyk1, Mariola Kwasek2 Abstract Agriculture Constitutes O
doi: 10.5937/WBJAE2002077K WBJAERD, Vol. 2, No. 2 (69-152), July - December, 2020 AGRICULTURAL SECTOR IN ECONOMY OF POLAND IN 1950-2020. Stanisław Kowalczyk1, Mariola Kwasek2 Abstract Agriculture constitutes one of the first and foremost forms of conscious and organised human activity. Its importance for the society and for the economy stems from its main purpose, namely to meet one of the basic human needs – to satisfy hunger. The period of almost 70 years under consideration brought about exceptional change in the case of Polish agriculture. It consisted of a systematic decline in the potential of agriculture in the economy. The factor that is specific to agriculture - land, evolved relatively the least. Land allocated for agricultural purposes reduced for about one quarter. Much deeper changes have taken place in the other two factors, universal from the point of view of the sectoral application, namely work (human resources) and capital. In the post-war period, trade in agri-food products, albeit small, remained of great importance for the development of Polish agriculture and the entire economy. The nature of the links in this area has also undergone significant changes. Since Poland’s accession to the European Union, the balance in foreign trade in agri-food products has been positive and has been growing steadily. This means that foreign customers are becoming increasingly interested in agricultural and food products from Poland. The strategic directions of development for Polish agriculture are the production of bovine meat, poultry meat, eggs, milk and milk products, butter, sugar, fruits, vegetables, pulses, potatoes and cereals. Food consumption has also undergone dynamic changes. -

EUROPEAN COMMISSION Luxembourg Statistics Poland
Ref. Ares(2020)1735701 - 24/03/2020 EUROPEAN COMMISSION EUROSTAT Directorate D Government Finance Statistics (GFS) Luxembourg ESTAT/D1/LA/RJ/MSz/at Statistics Poland National Accounts Department Ms Anita Perzyna Director Al. Niepodległości 208 PL - 00925 Warsaw Subject: Consultation on the statistical recording of the PPP project concerning the expressway section of the bypass of the Tri-City Metropolis Ref.: Your letter of 30 August 2019 Eurostat letter of 24 September 2019 Discussion held during the EDP visit on 11-12 February 2020 Dear Ms Perzyna, Following the discussions held during the EDP dialogue visit of 11-12 February 2020, Eurostat would like to re-visit your request for consultation on the statistical recording of the PPP project concerning the expressway section of the bypass of the Tri-City Metropolis (Gdańsk, Sopot, Gdynia). Description of the case The Polish authorities are in the process of preparation of the Tri-City Metropolis bypass project to be delivered on a public-private partnership basis. The project comprises the completion of the design works, the construction works, the provision of financing, the maintenance and ensuring the availability of the expressway along the section of the Tri-City Metropolis bypass. In exchange, a public partner is foreseen to pay regular remuneration. At present, the project is not yet finalised and no contract with a private partner has been signed. The accounting issue In view of the advanced stage of the draft PPP contract, the Polish authorities asked Eurostat on 30 August 2019, for an opinion concerning the appropriate statistical recording of the project in national accounts and in the EDP statistics. -

Annex 1. Use Cases – Final Report from the GEOSTAT 2 Project
Annex 1. Use cases Final report from the GEOSTAT 2 project A Point-based Foundation for Statistics – Final Report from the GEOSTAT 2 Project – Annex 1. Use cases Content 1. Specify needs ....................................................................................................................................... 5 1.1 User councils in Statistics Sweden................................................................................................. 5 1.2 Formalised user dialogue in Portugal ............................................................................................ 5 1.3 Formalised user dialogue in Austria .............................................................................................. 7 1.4 Active promotion of geospatial data and statistics in Norway ..................................................... 7 2. Design .................................................................................................................................................. 9 2.1 The Swedish National Geodata Cooperation ................................................................................ 9 2.2 Data access through Norway Digital ........................................................................................... 10 2.3 Legal basis for data and geospatial data access in Portugal ....................................................... 11 2.4 Legal basis for geospatial data access for Statistics Austria ........................................................ 12 2.5 Acquisition and processing of -

RURAL Neets in POLAND
RURAL NEETs IN POLAND 2009/2019 OVERVIEW AUTHORS Mateusz Smoter - [email protected] Institute for Structural Research - IBS Image by studioyayo from Pixabay This document is published by COST Action CA 18213: Rural NEET Youth Network: Modeling the risks underlying rural NEETs social exclusion. ©️ COST CA18213, December 2020. Reproduction is authorized provided the source is acknowledged. Please cite this publication as “COST CA18213 Rural NEETs in Poland: 2009/2019 Overview. OVERVIEW IN POLAND: 2009/2019 RURAL NEETs ISBN: 978-989-781-424-2 Visit: www.rnyobservatory.eu INDEX 1. CONTEXTUALIZATION 6 2. METHODOLOGICAL NOTE 8 3. DATA ANALYSIS 9 3. 1. Population and youth population 9 3. 2. Employment and unemployment 11 • Youth employment 11 • Youth unemployment 14 3. 3. Education 17 • Young people by educational attainment level 17 • Early School Leavers from Education and Training 19 3. 4. NEETs 20 • NEET rate 20 4. CONCLUSIONS 23 5. REFERENCES 25 6. IMPORTANT LINKS 26 RURAL NEETs IN POLAND: 2009/2019 OVERVIEW IN POLAND: 2009/2019 RURAL NEETs SUMMARY The report outlines the evolution of the labour market situation of young people in Poland between 2009 and 2019. Particular attention was paid to describe how the situation has changed across different age subgroups and degree of urbanization. The analysis includes descriptive statistics of the selected labour market indicators (employment and unem- ployment rate, NEET rate) along with educational and population data extracted from the Eurostat public datasets. The report shows that youth population in Poland has been declining over the past decade, especially in cities and rural areas.