Computational Lexical Semantics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
The Thesaurus Delineates the Standard Terminology Used to Index And
DOCUMENT RESUME EC 070 639 AUTHOR Oldsen, Carl F.; And Others TITLr Instructional Materials Thesaurus for Special Education, Second Edition. Special Education IMC/RMC Network. INSTITUTION Special Education IMC/RMC Network, Arlington, Va. SPONS AGENCY Bureau of Education for the Handicapped (DHEW/OE), Washington, D.C. PUB DATE Jul 74 NOTE 42p. EDRS PRICE MF-$0.76 HC-$1.95 PLUS POSTAGE DESCRIPTORS Exceptional Child Education; *Handicapped Children; *Information Retrieval; *Instructional Materials; Instructional Materials Centers; National Programs; *Reference Books; *Thesauri ABSTRACT The thesaurus delineates the standard terminology used to index and retrieve instructional materials for exceptional children in the Special Education Instructional Materials Center/Regional Media Centers Network. The thesaurus is presentedin three formats: an alphabetical listing (word by word rather than, letter by letter), a rotated index, and a listing by category.The alphabetical listing of descriptors provides definitions for all terms, and scope notes which indicate the scope or boundaries of the descriptor for selected terms. Numerous cross referencesare provided. In the rotated index format, all key words excluding prepositions and articles from single and multiword formlt, each descriptor has been placed in one or more of 19 categorical groupings. (GW) b4:1 R Special Education c. Network Instructional Materials Centers -7CEIMRegional Media Centers i$1s.\ INSTRUCTIONAL THESAURUS FOR SPECIAL EpucATIo SECOND EDITION July, 1974 Printed & Distributed by the CEC Information Center on Exceptional Children The Council for Exceptional Children 1920 Association Drive Reston, -Virginia 22091 Member of the Special Education IMC /RMC Network US Office of EducationBureau of Education for the Handicapped Special Education IMC/RMC Network Instructional Materials Thesaurus for Special Education Second Edition July,1974 Thesaurus Committee Joan Miller Virginia Woods Carl F. -

Thesaurus, Thesaural Relationships, Lexical Relations, Semantic Relations, Information Storage and Retrieval
International Journal of Information Science and Management The Study of Thesaural Relationships from a Semantic Point of View J. Mehrad, Ph.D. F. Ahmadinasab, Ph.D. President of Regional Information Center Regional Information Center for Science and Technology, I. R. of Iran for Science and Technology, I. R. of Iran email: [email protected] Corresponding author: [email protected] Abstract Thesaurus is one, out of many, precious tool in information technology by which information specialists can optimize storage and retrieval of documents in scientific databases and on the web. In recent years, there has been a shift from thesaurus to ontology by downgrading thesaurus in favor of ontology. It is because thesaurus cannot meet the needs of information management because it cannot create a rich knowledge-based description of documents. It is claimed that the thesaural relationships are restricted and insufficient. The writers in this paper show that thesaural relationships are not inadequate and restricted as they are said to be but quite the opposite they cover all semantic relations and can increase the possibility of successful storage and retrieval of documents. This study shows that thesauri are semantically optimal and they cover all lexical relations; therefore, thesauri can continue as suitable tools for knowledge management. Keywords : Thesaurus, Thesaural Relationships, Lexical Relations, Semantic Relations, Information Storage and Retrieval. Introduction In the era of information explosion with the emergence of computers and internet and their important role in the storage and retrieval of information, every researcher has to do her/his scientific queries through scientific databases or the web. There are two common ways of query, one is free search which is done by keywords and the other is applying controlled vocabularies. -

Download Article
Advances in Social Science, Education and Humanities Research (ASSEHR), volume 312 International Conference "Topical Problems of Philology and Didactics: Interdisciplinary Approach in Humanities and Social Sciences" (TPHD 2018) On Some Basic Methods of Analysis of Content and Structure of Lexical-Semantic Fields Alexander Zhouravlev Victoria Dobrova Department of Foreign Languages Department of Foreign Languages Samara State Technical University Samara State Technical University Samara, Russia Samara, Russia [email protected] [email protected] Lilia Nurtdinova Department of Foreign Languages Samara State Technical University Samara, Russia [email protected] Abstract—In the paper, two basic methods of analysis of the meaning of lexical units and a general structure of lexical- II. COMPONENTIAL ANALYSIS semantic fields are considered. The main subject is to understand the essence of the componential analysis method and the field A. Introduction of the method approach. The analysis of their definitions provided by various One can hardly overestimate the importance of the researchers, their main terms and notions, as well as prospects of componential analysis method for semantics research. In I. these methods are presented. The methodology of the research is Kobozeva’s opinion, a “method of componential analysis is the analysis of various types of scientific papers dealing with one of basic methods for description of lexical meaning” [1]. history, theoretical basis and practical application of the One of the reasons for this is that a meaning as a collection of componential analysis method and the field approach. The authors also present the evolution of the point of view on the role semes possesses a certain hierarchy instead of being an of these methods in the study of the meaning of lexical items, unorganized array. -

Georgia Performance Standards K-3 ELA Kindergarten 1St Grade 2Nd Grade 3Rd Grade
Georgia Performance Standards K-3 ELA Kindergarten 1st Grade 2nd Grade 3rd Grade Reading CONCEPTS OF PRINT CONCEPTS OF PRINT ELAKR1 The student demonstrates ELA1R1 The student demonstrates knowledge of concepts of print. knowledge of concepts of print. The student The student a. Recognizes that print and a. Understands that there are pictures (signs and labels, correct spellings for words. newspapers, and informational books) can inform, entertain, and b. Identifies the beginning and end persuade. of a paragraph. b. Demonstrates that print has c. Demonstrates an understanding meaning and represents spoken that punctuation and capitalization language in written form. are used in all written sentences. c. Tracks text read from left to right and top to bottom. d. Distinguishes among written letters, words, and sentences. e. Recognizes that sentences in print are made up of separate words. f. Begins to understand that punctuation and capitalization are used in all written sentences. PHONOLOGICAL AWARENESS PHONOLOGICAL AWARENESS ELAKR2 The student demonstrates ELA1R2 The student demonstrates the ability to identify and orally the ability to identify and orally manipulate words and manipulate words and individual sounds within those individual sounds within those spoken words. The student spoken words. The student a. Identifies and produces rhyming a. Isolates beginning, middle, and words in response to an oral ending sounds in single-syllable prompt and distinguishes rhyming words. and non-rhyming words. Page 1 of 11 Georgia Performance Standards K-3 ELA Kindergarten 1st Grade 2nd Grade 3rd Grade b. Identifies onsets and rhymes in b. Identifies component sounds spoken one-syllable words. (phonemes and combinations of phonemes) in spoken words. -

Introduction to Wordnet: an On-Line Lexical Database
Introduction to WordNet: An On-line Lexical Database George A. Miller, Richard Beckwith, Christiane Fellbaum, Derek Gross, and Katherine Miller (Revised August 1993) WordNet is an on-line lexical reference system whose design is inspired by current psycholinguistic theories of human lexical memory. English nouns, verbs, and adjectives are organized into synonym sets, each representing one underlying lexical concept. Different relations link the synonym sets. Standard alphabetical procedures for organizing lexical information put together words that are spelled alike and scatter words with similar or related meanings haphazardly through the list. Unfortunately, there is no obvious alternative, no other simple way for lexicographers to keep track of what has been done or for readers to ®nd the word they are looking for. But a frequent objection to this solution is that ®nding things on an alphabetical list can be tedious and time-consuming. Many people who would like to refer to a dictionary decide not to bother with it because ®nding the information would interrupt their work and break their train of thought. In this age of computers, however, there is an answer to that complaint. One obvious reason to resort to on-line dictionariesÐlexical databases that can be read by computersÐis that computers can search such alphabetical lists much faster than people can. A dictionary entry can be available as soon as the target word is selected or typed into the keyboard. Moreover, since dictionaries are printed from tapes that are read by computers, it is a relatively simple matter to convert those tapes into the appropriate kind of lexical database. -

Semantic Typology and Efficient Communication
To appear in the Annual Review of Linguistics. Semantic typology and efficient communication Charles Kemp∗1, Yang Xu2, and Terry Regier∗3 1Department of Psychology, Carnegie Mellon University, Pittsburgh, PA, USA, 15213 2 Department of Computer Science, Cognitive Science Program, University of Toronto, Toronto, Ontario M5S 3G8, Canada 3 Department of Linguistics, Cognitive Science Program, University of California, Berkeley, CA, USA, 94707; email: [email protected] Abstract Cross-linguistic work on domains including kinship, color, folk biology, number, and spatial rela- tions has documented the different ways in which languages carve up the world into named categories. Although word meanings vary widely across languages, unrelated languages often have words with sim- ilar or identical meanings, and many logically possible meanings are never observed. We review work suggesting that this pattern of constrained variation is explained in part by the need for words to sup- port efficient communication. This work includes several recent studies that have formalized efficient communication in computational terms, and a larger set of studies, both classic and recent, that do not explicitly appeal to efficient communication but are nevertheless consistent with this notion. The effi- cient communication framework has implications for the relationship between language and culture and for theories of language change, and we draw out some of these connections. Keywords: lexicon, word meaning, categorization, culture, cognitive anthropology, information theory 1 INTRODUCTION The study of word meanings across languages has traditionally served as an arena for exploring the inter- play of language, culture, and cognition, and as a bridge between linguistics and neighboring disciplines such as anthropology and psychology. -

Roget's Thesaurus Ordered by Class Number % of H
Roget’s Thesaurus: a Lexical Resource to Treasure Mario JARMASZ, Stan SZPAKOWICZ School of Information Technology and Engineering University of Ottawa Ottawa, Canada, K1N 6N5 {mjarmasz,szpak}@site.uottawa.ca know, we are the first to implement an electronic Abstract lexical knowledge base (ELKB) using an entire current edition. This paper presents the steps involved in Simply deciding what version of the creating an electronic lexical knowledge Thesaurus to use as the source for the ELKB is base from the 1987 Penguin edition of not simple. There exist hundreds of reference Roget’s Thesaurus. Semantic relations are manuals with the name Roget’s Thesaurus in the labelled with the help of WordNet. The two title, yet only various editions of Roget’s resources are compared in a qualitative and International Thesaurus (Chapman, 1977), quantitative manner. Differences in the Penguin’s Roget’s Thesaurus of English words organization of the lexical material are and phrases (Kirkpatrick, 1998) as well as the discussed, as well as the possibility of 1911 edition have actually been used for NLP. merging both resources. We want to use a thesaurus that has a structure very similar to the original and an extensive up- Introduction to-date vocabulary. The 1911 and Penguin Peter Mark Roget published his first Thesaurus editions use a taxonomy like the one devised by (Roget, 1852) over 150 years ago. Countless Roget. The categories of the 1911 version can be writers, orators and students of the English viewed at Thesaurus.com. It contains 1,000 language have used it. Masterman (1957) was concepts. -

The Reconstruction of Proto-Burmish: a Case Study in the Computational Implementation of the Comparative Method
The reconstruction of proto-Burmish: a case study in the computational implementation of the comparative method The use of computational methods in comparative linguistics increases ever in popularity. Nonetheless, the fruits of such methods have so far been meagre when compared to the results the traditional comparative method. This paper explores a dataset of Burmish languages as a case study in improving the methodology of computational reconstruction. In particular are aim is not replace or modify the comparative method, but rather to implement the traditional method using computational tools. Our database comprises 400 concepts and their translational counterparts in a dozen Burmish langauges. Concepts are linked to the Concepticon (List et al. 2016), languages are linked to Glottolog. The primary data comes from Huáng et al. (1992.), as digitized by STEDT (Matisoff 2011), but we supplement this with other sources. We employ an iterative workflow combining the absolute rigor of a computer with the insightful intuitions of trained historical linguists. After providing all of the data with unambiguous phonetic interpretations, including the explicit encoding of underdetermined segments, the computer provides a preliminary alignment and reconstruction. These reconstructions are then adjusted with an eye to the relevant literature on proto-Burmish. The adjustments are made inside of the workflow system so that the algorithm and general methodology will be enhanced and made more robust. References Hammarström, Harald & Forkel, Robert & Haspelmath, Martin & Bank, Sebastian (2015): Glottolog. Leipzig: Max Planck Institute of Evolutionary Anthropology (Available onlie at http://glottolog.org. Accessed on 2016-03-15). Huáng Bùfán et al. eds. (1992). Zàng-Miǎn yǔzú yǔyán cíhuì . -

Reference Resources Are Print, and Some Are Online
By Mrs. Paula McMullen Library Teacher Norwood Public Schools • A reference resource helps us to find answers to information questions. • These questions may be about words, subjects, places in the world, or current topics. • Some reference resources are print, and some are online. • The most common reference resources are the: dictionary, thesaurus, encyclopedia, atlas and almanac. Mrs. Paula McMullen, library teacher, 11/24/2009 2 Norwood Public Schools • Dictionaries give us information about words. • Dictionaries tell how to spell and pronounce a word. • Dictionaries give the word’s part of speech (noun, verb, adjective, adverb). • Dictionaries give us brief definitions of words – in a sentence or two. • Dictionaries give us synonyms – or other words that mean the same thing. • The bolded words – and their information – are called entries. Mrs. Paula McMullen, library teacher, 11/24/2009 3 Norwood Public Schools Mrs. Paula McMullen, library teacher, 11/24/2009 4 Norwood Public Schools An Overview at the beginning of this print dictionary explains how to use it. Mrs. Paula McMullen, library teacher, 11/24/2009 5 Norwood Public Schools This page in the Overview explains what kind of information we find at each entry. Mrs. Paula McMullen, library teacher, 11/24/2009 6 Norwood Public Schools Then, use Guide Words at top of pages to see if the word is on that page. First, use Thumb Find bolded Tabs to guide you word “lion,” to the letter that listed starts the word. alphabetically. Mrs. Paula McMullen, library teacher, 11/24/2009 7 Norwood Public Schools This entry includes the bolded word lion, its syllables, its pronunciation, part of speech (noun) and a brief definition. -

Bilingual Indexing for Information Retrieval with AUTINDEX
Bilingual Indexing for Information Retrieval with AUTINDEX Nübel, Rita1; Pease, Catherine 1; Schmidt, Paul2; Maas, Dieter1 IAI1 Martin-Luther Str. 14, D-66111 Saarbrücken, Germany {rita,cath,dieter}@iai.uni-sb,de} FASK Universität Mainz2 An der Hochschule 2, Germersheim, Germany [email protected] Abstract AUTINDEX is a bilingual automatic indexing system for the two languages German and English. It is being developed within the EU-funded BINDEX project. The aim of the system is to automatic ally index large quantities of abstracts of scientific and technical papers from several areas of engineering. Automatic indexing takes place using a controlled vocabulary provided in monolingual and bilingual thesauri. AUTINDEX produces for a given abstract a list of descriptors as well as a list of classification codes using these thesauri. It also allows for free indexing - indexing with an unrestricted vocabulary (delivering so called 'free descriptors´). These free descriptors are used to enhance and extend the thesauri. The bilingual AUTINDEX module indexes German abstracts in English and vice versa. considerably according to the user requirements. In this 1. Introduction paper, stress is put on the development and integration of The paper describes the AUTINDEX system which linguistic resources that are used in the indexing and automatically indexes and classifies German and English classification procedure. Furthermore, the evaluation texts. The AUTINDEX prototype has been further strategy for AUTINDEX and its results are described. enhanced and adapted within the BINDEX1 project with The remainder of this paper is organised as follows: the goal of having a near-to-market system that can be Section 2 describes the NLP components of AUTINDEX. -
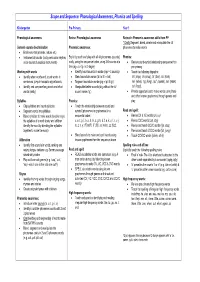
Scope and Sequence: Phonological Awareness, Phonics and Spelling
Scope and Sequence: Phonological Awareness, Phonics and Spelling Kindergarten Pre-Primary Year 1 Phonological awareness: Revise: Phonological awareness Re-teach: Phonemic awareness skills from PP * Orally Segment, blend, delete and manipulate the 44 General sounds discrimination Phonemic awareness: phonemes to make words • Environmental (animals, nature etc) • Instrumental sounds (body percussion rhythm, Explicitly teach and play with all 44 phonemes (sounds) Phonics: voice sounds & musical instruments) orally, using the sequence below, using 3-6 sounds at a • Revise sound-symbol relationship sequence from time (eg. s a t p i n to begin) pre-primary Working with words • Identify/count sounds in words (nap = 3 sounds) • Teach the following digraphs: • Identify when words end, count words in • Blend sounds in words (/b/ /a/ /t/ = bat) ‘sh’ (ship), ‘ch’(chop), ’th’ (thin), ‘ck’ (kick), sentences, jump in hoops to signal words, • Segment sounds in words (pig = /p/ /i/ /g/) ‘wh’ (what), ‘ng’ (king), ‘qu’* (queen), ‘ee’ (week) • Identify and compare long words and short • Manipulate/delete sounds (dig without the /d/ ‘oo’ (food), words (orally) sound makes ‘ig’) • Provide opportunities to make words using these and other known graphemes through games and Syllables Phonics: play • Clap syllables and count syllables • Teach the relationship between sound and • Segment words into syllables symbol (phonemes to graphemes) in a Read and spell: • Blend syllables to make words (teacher says sequential order: • Revise CV & VC words ( on, us) the syllables -

Towards a History of Concept List Compilation in Historical Linguistics
Towards a history of concept list compilation in historical linguistics Johann-Mattis List Max Planck Institute for the Science of Human History, Jena A large proportion of lexical data of the world’s languages is presented in form of word lists in which a set of concepts was translated into the language varieties of a specific language family or geographic region. The basis of these word lists are concept lists, that is, questionnaires of comparative concepts (in the sense of Haspelmath 2010), which scholars used to elicit the respective translations in their field work. Thus, a concept list is in the end not much more than a bunch of elicitation glosses, often (but not necessarily) based on English as an elicitation language, and a typical concept list may look like the following one, quoted from Swadesh (1950: 161): I, thou, he, we, ye, one, two, three, four, five, six, seven, eight, nine, ten, hundred, all, animal, ashes, back, bad, bark, belly, big, […] this, tongue, tooth, tree, warm, water, what, where, white, who, wife, wind, woman, year, yellow. But scholars may also present their concept list in tabular form, adding additional information in additional columns, numbering and ranking items, providing exemplary translations into other languages, or marking specific items as obsolete. The compilation of concept lists for the purpose of historical language comparison has a long tradition in historical linguistics, dating back at least to the 18th century (Leibniz 1768, Pallas 1786), if not even earlier (see Kaplan 2017). But concept lists were not solely compiled for the purpose of historical language comparison.