Architectural Styles of Extensible REST-Based Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
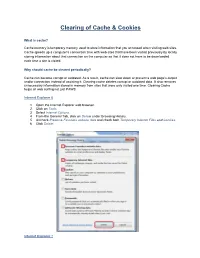
Clearing of Cache & Cookies
Clearing of Cache & Cookies What is cache? Cache memory is temporary memory used to store information that you accessed when visiting web sites. Cache speeds up a computer’s connection time with web sites that have been visited previously by locally storing information about that connection on the computer so that it does not have to be downloaded each time a site is visited. Why should cache be cleared periodically? Cache can become corrupt or outdated. As a result, cache can slow down or prevent a web page’s output and/or connection instead of assisting it. Clearing cache deletes corrupt or outdated data. It also removes unnecessary information stored in memory from sites that were only visited one time. Clearing Cache helps all web surfing not just PAWS. Internet Explorer 8 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Select Internet Options. 4. From the General Tab, click on Delete under Browsing History. 5. Uncheck Preserve Favorites website data and check both Temporary Internet Files and Cookies. 6. Click Delete. Internet Explorer 7 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Click on Internet Options. 4. Click on Delete under Browsing History. 5. Click Delete cookies. 6. When prompted, click Yes. 7. Click on Delete Internet Files. 8. When prompted, click Yes. 9. Click Close. 10. Click OK. 11. Close and reopen the browser for the changes to go into effect. Internet Explorer 6 1. Open the Internet Explorer web browser. 2. Click on Tools. 3. Click on Internet Options. 4. -

Browser Wars
Uppsala universitet Inst. för informationsvetenskap Browser Wars Kampen om webbläsarmarknaden Andreas Högström, Emil Pettersson Kurs: Examensarbete Nivå: C Termin: VT-10 Datum: 2010-06-07 Handledare: Anneli Edman "Anyone who slaps a 'this page is best viewed with Browser X' label on a Web page appears to be yearning for the bad old days, before the Web, when you had very little chance of read- ing a document written on another computer, another word processor, or another network" - Sir Timothy John Berners-Lee, grundare av World Wide Web Consortium, Technology Review juli 1996 Innehållsförteckning Abstract ...................................................................................................................................... 1 Sammanfattning ......................................................................................................................... 2 1 Inledning .................................................................................................................................. 3 1.1 Bakgrund .............................................................................................................................. 3 1.2 Syfte ..................................................................................................................................... 3 1.3 Frågeställningar .................................................................................................................... 3 1.4 Avgränsningar ..................................................................................................................... -

GNU Emacs Manual
GNU Emacs Manual GNU Emacs Manual Sixteenth Edition, Updated for Emacs Version 22.1. Richard Stallman This is the Sixteenth edition of the GNU Emacs Manual, updated for Emacs version 22.1. Copyright c 1985, 1986, 1987, 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007 Free Software Foundation, Inc. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with the Invariant Sections being \The GNU Manifesto," \Distribution" and \GNU GENERAL PUBLIC LICENSE," with the Front-Cover texts being \A GNU Manual," and with the Back-Cover Texts as in (a) below. A copy of the license is included in the section entitled \GNU Free Documentation License." (a) The FSF's Back-Cover Text is: \You have freedom to copy and modify this GNU Manual, like GNU software. Copies published by the Free Software Foundation raise funds for GNU development." Published by the Free Software Foundation 51 Franklin Street, Fifth Floor Boston, MA 02110-1301 USA ISBN 1-882114-86-8 Cover art by Etienne Suvasa. i Short Contents Preface ::::::::::::::::::::::::::::::::::::::::::::::::: 1 Distribution ::::::::::::::::::::::::::::::::::::::::::::: 2 Introduction ::::::::::::::::::::::::::::::::::::::::::::: 5 1 The Organization of the Screen :::::::::::::::::::::::::: 6 2 Characters, Keys and Commands ::::::::::::::::::::::: 11 3 Entering and Exiting Emacs ::::::::::::::::::::::::::: 15 4 Basic Editing -

HTTP2 Explained
HTTP2 Explained Daniel Stenberg Mozilla Corporation [email protected] ABSTRACT credits to everyone who helps out! I hope to make this document A detailed description explaining the background and problems better over time. with current HTTP that has lead to the development of the next This document is available at http://daniel.haxx.se/http2. generation HTTP protocol: HTTP 2. It also describes and elaborates around the new protocol design and functionality, 1.3 License including some implementation specifics and a few words about This document is licensed under the the future. Creative Commons Attribution 4.0 This article is an editorial note submitted to CCR. It has NOT license: been peer reviewed. The author takes full responsibility for this http://creativecommons.org/licenses/by/4.0/ article’s technical content. Comments can be posted through CCR Online. 2. HTTP Today Keywords HTTP 1.1 has turned into a protocol used for virtually everything HTTP 2.0, security, protocol on the Internet. Huge investments have been done on protocols and infrastructure that takes advantage of this. This is taken to the 1. Background extent that it is often easier today to make things run on top of HTTP rather than building something new on its own. This is a document describing http2 from a technical and protocol level. It started out as a presentation I did in Stockholm in April 2014. I've since gotten a lot of questions about the contents of 2.1 HTTP 1.1 is Huge that presentation from people who couldn't attend, so I decided to When HTTP was created and thrown out into the world it was convert it into a full-blown document with all details and proper probably perceived as a rather simple and straight-forward explanations. -

Analisi Del Progetto Mozilla
Università degli studi di Padova Facoltà di Scienze Matematiche, Fisiche e Naturali Corso di Laurea in Informatica Relazione per il corso di Tecnologie Open Source Analisi del progetto Mozilla Autore: Marco Teoli A.A 2008/09 Consegnato: 30/06/2009 “ Open source does work, but it is most definitely not a panacea. If there's a cautionary tale here, it is that you can't take a dying project, sprinkle it with the magic pixie dust of "open source", and have everything magically work out. Software is hard. The issues aren't that simple. ” Jamie Zawinski Indice Introduzione................................................................................................................................3 Vision .........................................................................................................................................4 Mozilla Labs...........................................................................................................................5 Storia...........................................................................................................................................6 Mozilla Labs e i progetti di R&D...........................................................................................8 Mercato.......................................................................................................................................9 Tipologia di mercato e di utenti..............................................................................................9 Quote di mercato (Firefox).....................................................................................................9 -

Improving Packet Caching Scalability Through the Concept Of
IMPROVING PACKET CACHING SCALABILITY THROUGH THE CONCEPT OF AN EXPLICIT END OF DATA MARKER A Thesis Submitted to the Graduate School of the University of Notre Dame in Partial Fulfillment of the Requirements for the Degree of Master of Science in Computer Science and Engineering by Xiaolong Li, B.S., M.S. ________________________________ Aaron Striegel, Director Graduate Program in Computer Science and Engineering Notre Dame, Indiana July 2006 c Copyright by Xiaolong Li 2006 All Rights Reserved Improving Packet Caching Scalability Through the Concept of an Explicit End of Data Marker Abstract by Xiaolong Li The web has witnessed an explosion of dynamic content generation to provide web users with an interactive and personalized experience. While traditional web caching techniques work well when redundancy occurs on an object-level basis (page, image, etc.), the use of dynamic content presents unique challenges. Although past work has addressed mechanisms for detecting redundancy despite dynamic content, the scalability of such techniques is limited. In this thesis, an effective and highly scalable approach, Explicit End of Data (EEOD) is presented, which allows the content designer to easily signal bound- aries between cacheable and non-cacheable content. EEOD provides application- to-stack mechanisms to guarantee separation of packets with the end goal of sim- plifying packet-level caching mechanisms. Most importantly, EEOD does not re- quire client-side modifications and can function in a variety of server-side/network deployment modes. Additionally, experimental studies are presented, showing EEOD offers 25% and 30% relative improvements in terms of bandwidth efficiency and retrieval time over current approaches in the literature. -

Answering the Diagnostic Questions
Answering This Incident Report Guide is to help users answer the questions found on the Incident Report Form. the Diagnostic Questions The user may wish to provide the Incident Report form to the IT or CIO at their location to gather this information. In the case where they are not available, or the user is using a private laptop, we have provided this guide as means to help the user find the answers needed to best diagnose the issue at hand. If the user doesn’t already know how to take a screen shot of the issue, they can learn how here. CTRL+Click the Questions you wish to learn about: 1. How often does the issue occur? 2. What is your current operating system? 3. What internet browser were you using? 4. Is “compatibility mode” enabled in your internet browser? 5. What was your location when the issue occurred? 6. What type of internet connection were you using? 7. Are you not able to submit the review because of this issue? 8. What is the name of your antivirus software? 1. HowOnce often: The doesissue only the occurred issue occur? once. If this is the case, please try closing the portal and internet explorer completely and try again. Sporadic: The issue happens at random times. If this is the case, we will ask you to notice when it happens vs. when it doesn’t. Common patterns to look for are: “The issue only happens when I am on-site” or “I only get an error when I click “Store closed” Many: Issue reoccurs continually under certain circumstances. -

Anti-Spam Software
СПАМ и системи за защита от спам Стефка Великова Маринова ф.н. 43217 Иглика Валентинова Мишева ф.н. 43175 - 0 - Всички потребители на Internet навярно някога в своя живот са се сблъсквали с понятие като СПАМ. То може да се определи не само като “нежелана поща”, но и като генериране на никому ненужен трафик. Любопитно е от къде произлиза думичката "spam" . За първи път подобен термин се е появил преди години в скеч на Monty Python (група актьори от Великобритания), когато викинги нападнали някаква гостилница, чието меню се състояло единствено от "spam" (Spiced Pork and hAM), и келнерът започнал ентусиазирано да обяснява: "имаме спам, спам и яйца, яйца и спам, спам-спам и яйца, спам спам и спам...” и нищо не можело да се яде поотделно без спам. Има няколко вида спам, според това каква услуга е решил да използва спамера, като всеки вид създава различни проблеми на потребителите на Интернет или просто на локалната мрежа. Услугите използвани от спамерите са mail, Usenet, IRC даже и FTP . Общоизвестно е, че протокола FTP осигурява предаването на двоични и текстови файлове от и на FTP-сървъри. FTP-сървър може да бъде както компютър с Unix (Linux), така и компютър под Windows NT, на който работи FTP-сървър. Няма се предвид взлом на FTP-сървъри и всичко по-долу казано е в следствие на работа на възможностите на протокола FTP за предаване на файлове непряко между сървъри. Давайки на анонмни потребители на сървъра правото за запис ние правим своя сървър потенциално уязвим. В такава ситуация е напълно възможно някакъв шегаджия от мрежата да генерира значителен трафик от някакъв достатъчно мощен сървър към нашия злочест FTP-сървър. -

SPF, MTA-K És SRS
Szaktekintély SPF, MTA-k és SRS Az elõzõ cikkben áttekintettük, hogy DNS segítségével hogyan jelölhetjük meg eredetiként kimenõ elektronikus leveleinket. Most eljött az ideje annak, hogy a bejövõ levelek ellenõrzésérõl is gondoskodjunk, és megvédjük felhasználóinkat a hamisított, kéretlen levelektõl és a férgektõl. © Kiskapu Kft. Minden jog fenntartva Sender Policy Framework (SPF, küldõ házirend-ke- Ha kissé mértéktartóbbak akarunk lenni, akkor elutasítás he- retrendszer) a válaszútvonal hamisítása ellen segít lyett a Received-SPF: fail sorral is bõvíthetjük a fejlécet. Ezt A védekezni – amit általában férgek, vírusok és le- a lehetõséget a beépülõ modulok leírása ismerteti bõvebben. vélszemét terjesztõk alkalmaznak. Az SPF életre hívása két szakaszból áll. Elõször a rendszergazdák SPF-bejegyzéseket Sendmail tesznek közzé a DNS-ben. Ezek a bejegyzések az egyes tar- A Sendmail beépülõ modulok fogadására szolgáló felületét tományok által a kimenõ levelek kezelésére használt kiszol- Milternek nevezzük. (Lásd az internetes forrásokat.) Az gálókat adják meg. Az SPFre képes MTA-k (mail transport újabb Sendmail-változatok alapesetben is támogatják a agent, levéltovábbító ügynök) késõbb ellenõrzik a bejegyzé- Milter használatát. A Sendmail foglalat alapú felületen ke- seket. Ha egy levél nem az SPF-ben megadott kiszolgálóról resztül tartja a kapcsolatot a Milterrel. Értesíti azt a befelé érkezik, akkor bátran hamisnak nyilváníthatjuk. irányuló SMTP-tranzakciókról, a Milter pedig megmondja A továbbiakban – kapcsolódva elõzõ írásomhoz – felvázolom, a Sendmailnek, hogy mit kell tennie. A Milter démonként hogyan ruházhatjuk fel SPF képességekkel a levélkiszolgálón- fut, indítása is külön történik. Az SPF weboldalon két Milter kat. Szó lesz arról is, hogy az elektronikus leveleket továbbító, érhetõ el, egy Perl és egy C alapú. A Perl alapú változat kifi- vagy weben elõállító szolgáltatások a küldõ módosításával nomultabb, ha viszont gyorsabb mûködést szeretnénk, ak- hogyan mûködtethetõk tovább az SPF bevezetése után is. -

Questfields EXTRACT
QuestFields EXTRACT: Full-Page Web Applications and the MO Framework (Section 3 of the QuestFields Client Administration Guide) Legal Notices Copyright © 2009 by MasterObjects, Inc. All rights reserved. U.S. and international patents pending. MasterObjects, QuestObjects, QuestField, Questlet, QOP, and the Q Arrow logo are trademarks or registered trademarks of MasterObjects, Inc. (http://www.masterobjects.com) in the United States and other countries. Other trademarks used in this document are the property of their respective owners. Screen shots were used to the benefit of their respective copyright owners, for informational purposes only. Use of trademarks or screen shots is not intended to convey endorsement or other affiliation with MasterObjects. No part of this publication may be reproduced, stored in a retrieval system, or transmitted, in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of the publisher or copyright owner. MasterObjects has tried to make the information contained in this publication as accurate and reliable as possible, but assumes no responsibility for errors or omissions. MasterObjects disclaims any warranty of any kind, whether express or implied, as to any matter whatsoever relating to this publication, including without limitation the merchantability or fitness for any particular purpose. In no event shall MasterObjects be liable for any indirect, special, incidental, or consequential damages arising out of purchase or use of this -

Encouragez Les Framabooks !
Encouragez les Framabooks ! You can use Unglue.it to help to thank the creators for making Histoires et cultures du Libre. Des logiciels partagés aux licences échangées free. The amount is up to you. Click here to thank the creators Sous la direction de : Camille Paloque-Berges, Christophe Masutti Histoires et cultures du Libre Des logiciels partagés aux licences échangées II Framasoft a été créé en novembre 2001 par Alexis Kauffmann. En janvier 2004 une asso- ciation éponyme a vu le jour pour soutenir le développement du réseau. Pour plus d’infor- mation sur Framasoft, consulter http://www.framasoft.org. Se démarquant de l’édition classique, les Framabooks sont dits « livres libres » parce qu’ils sont placés sous une licence qui permet au lecteur de disposer des mêmes libertés qu’un utilisateur de logiciels libres. Les Framabooks s’inscrivent dans cette culture des biens communs qui, à l’instar de Wikipédia, favorise la création, le partage, la diffusion et l’ap- propriation collective de la connaissance. Le projet Framabook est coordonné par Christophe Masutti. Pour plus d’information, consultez http://framabook.org. Copyright 2013 : Camille Paloque-Berges, Christophe Masutti, Framasoft (coll. Framabook) Histoires et cultures du Libre. Des logiciels partagés aux licences échangées est placé sous licence Creative Commons -By (3.0). Édité avec le concours de l’INRIA et Inno3. ISBN : 978-2-9539187-9-3 Prix : 25 euros Dépôt légal : mai 2013, Framasoft (impr. lulu.com, Raleigh, USA) Pingouins : LL de Mars, Licence Art Libre Couverture : création par Nadège Dauvergne, Licence CC-By Mise en page avec LATEX Cette œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution 2.0 France. -

Internet Explorer 11 Settings for Web Client
Internet Explorer 11 Settings for Web Client. Summary of Changes being performed: Change Compatibility View 1. Click on Tools, then Compatibility View Settings a. 2. Click Add and the web address will move down to the Websites box 3. Click Close 4. If the page does not refresh, close the tab and then reopen. Internet Explorer 11 Settings 1. Adding the site to the Trusted sites zone 2. Change the Security settings for the Trusted Sites. 1. To add the site to the Trusted Sites list. a. Click on Tools then Internet Options. Explorer 11 Settings Page 1 of 12 Joe Arcara b. c. Click on the Security tab. Explorer 11 Settings Page 2 of 12 Joe Arcara d. e. Select (click on) the Trusted Sites Zone f. Click on the Sites box. Explorer 11 Settings Page 3 of 12 Joe Arcara g. h. If the website https://direct.imagedepositgateway.com is not already in the Websites box, click on Add button to put the site on the list. If it is already in the Websites box, you do not need to do anything, just click Close. i. Explorer 11 Settings Page 4 of 12 Joe Arcara j. Click Close to return to the Security Tab. Explorer 11 Settings Page 5 of 12 Joe Arcara 2. Set Security for the Trusted Sites Zone. a. b. Click on Custom Level c. Set the Reset To: drop down list to Medium-low Explorer 11 Settings Page 6 of 12 Joe Arcara d. e. Click on Reset to set the level. f. g.