Administrator Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Anonymity in a Time of Surveillance
LESSONS LEARNED TOO WELL: ANONYMITY IN A TIME OF SURVEILLANCE A. Michael Froomkin* It is no longer reasonable to assume that electronic communications can be kept private from governments or private-sector actors. In theory, encryption can protect the content of such communications, and anonymity can protect the communicator’s identity. But online anonymity—one of the two most important tools that protect online communicative freedom—is under practical and legal attack all over the world. Choke-point regulation, online identification requirements, and data-retention regulations combine to make anonymity very difficult as a practical matter and, in many countries, illegal. Moreover, key internet intermediaries further stifle anonymity by requiring users to disclose their real names. This Article traces the global development of technologies and regulations hostile to online anonymity, beginning with the early days of the Internet. Offering normative and pragmatic arguments for why communicative anonymity is important, this Article argues that anonymity is the bedrock of online freedom, and it must be preserved. U.S. anti-anonymity policies not only enable repressive policies abroad but also place at risk the safety of anonymous communications that Americans may someday need. This Article, in addition to providing suggestions on how to save electronic anonymity, calls for proponents of anti- anonymity policies to provide stronger justifications for such policies and to consider alternatives less likely to destroy individual liberties. In -

Not-Quite-So-Broken TLS Lessons in Re-Engineering a Security Protocol Specification and Implementation
Not-quite-so-broken TLS Lessons in re-engineering a security protocol specification and implementation David Kaloper Meršinjak Hannes Mehnert Peter Sewell Anil Madhavapeddy University of Cambridge, Computer Labs Usenix Security, Washington DC, 12 August 2015 INT SSL23_GET_CLIENT_HELLO(SSL *S) { CHAR BUF_SPACE[11]; /* REQUEST THIS MANY BYTES IN INITIAL READ. * WE CAN DETECT SSL 3.0/TLS 1.0 CLIENT HELLOS * ('TYPE == 3') CORRECTLY ONLY WHEN THE FOLLOWING * IS IN A SINGLE RECORD, WHICH IS NOT GUARANTEED BY * THE PROTOCOL SPECIFICATION: * BYTE CONTENT * 0 TYPE \ * 1/2 VERSION > RECORD HEADER * 3/4 LENGTH / * 5 MSG_TYPE \ * 6-8 LENGTH > CLIENT HELLO MESSAGE Common CVE sources in 2014 Class # Memory safety 15 State-machine errors 10 Certificate validation 5 ASN.1 parsing 3 (OpenSSL, GnuTLS, SecureTransport, Secure Channel, NSS, JSSE) Root causes Error-prone languages Lack of separation Ambiguous and untestable specification nqsb approach Choice of language and idioms Separation and modular structure A precise and testable specification of TLS Reuse between specification and implementation Choice of language and idioms OCaml: a memory-safe language with expressive static type system Well contained side-effects Explicit flows of data Value-based Explicit error handling We leverage it for abstraction and automated resource management. Formal approaches Either reason about a simplified model of the protocol; or reason about small parts of OpenSSL. In contrast, we are engineering a deployable implementation. nqsb-tls A TLS stack, developed from scratch, with dual goals: Executable specification Usable TLS implementation Structure nqsb-TLS ML module layout Core Is purely functional: VAL HANDLE_TLS : STATE -> BUFFER -> [ `OK OF STATE * BUFFER OPTION * BUFFER OPTION | `FAIL OF FAILURE ] Core OCaml helps to enforce state-machine invariants. -

RSA BSAFE Crypto-C 5.21 FIPS 140-1 Security Policy2.…
RSA Security, Inc. RSA™ BSAFE® Crypto-C Crypto-C Version 5.2.1 FIPS 140-1 Non-Proprietary Security Policy Level 1 Validation Revision 1.0, May 2001 © Copyright 2001 RSA Security, Inc. This document may be freely reproduced and distributed whole and intact including this Copyright Notice. Table of Contents 1 INTRODUCTION.................................................................................................................. 3 1.1 PURPOSE ............................................................................................................................. 3 1.2 REFERENCES ....................................................................................................................... 3 1.3 DOCUMENT ORGANIZATION ............................................................................................... 3 2 THE RSA BSAFE PRODUCTS............................................................................................ 5 2.1 THE RSA BSAFE CRYPTO-C TOOLKIT MODULE .............................................................. 5 2.2 MODULE INTERFACES ......................................................................................................... 5 2.3 ROLES AND SERVICES ......................................................................................................... 6 2.4 CRYPTOGRAPHIC KEY MANAGEMENT ................................................................................ 7 2.4.1 Protocol Support........................................................................................................ -
![Arxiv:1911.09312V2 [Cs.CR] 12 Dec 2019](https://docslib.b-cdn.net/cover/5245/arxiv-1911-09312v2-cs-cr-12-dec-2019-485245.webp)
Arxiv:1911.09312V2 [Cs.CR] 12 Dec 2019
Revisiting and Evaluating Software Side-channel Vulnerabilities and Countermeasures in Cryptographic Applications Tianwei Zhang Jun Jiang Yinqian Zhang Nanyang Technological University Two Sigma Investments, LP The Ohio State University [email protected] [email protected] [email protected] Abstract—We systematize software side-channel attacks with three questions: (1) What are the common and distinct a focus on vulnerabilities and countermeasures in the cryp- features of various vulnerabilities? (2) What are common tographic implementations. Particularly, we survey past re- mitigation strategies? (3) What is the status quo of cryp- search literature to categorize vulnerable implementations, tographic applications regarding side-channel vulnerabili- and identify common strategies to eliminate them. We then ties? Past work only surveyed attack techniques and media evaluate popular libraries and applications, quantitatively [20–31], without offering unified summaries for software measuring and comparing the vulnerability severity, re- vulnerabilities and countermeasures that are more useful. sponse time and coverage. Based on these characterizations This paper provides a comprehensive characterization and evaluations, we offer some insights for side-channel of side-channel vulnerabilities and countermeasures, as researchers, cryptographic software developers and users. well as evaluations of cryptographic applications related We hope our study can inspire the side-channel research to side-channel attacks. We present this study in three di- community to discover new vulnerabilities, and more im- rections. (1) Systematization of literature: we characterize portantly, to fortify applications against them. the vulnerabilities from past work with regard to the im- plementations; for each vulnerability, we describe the root cause and the technique required to launch a successful 1. -

Black-Box Security Analysis of State Machine Implementations Joeri De Ruiter
Black-box security analysis of state machine implementations Joeri de Ruiter 18-03-2019 Agenda 1. Why are state machines interesting? 2. How do we know that the state machine is implemented correctly? 3. What can go wrong if the implementation is incorrect? What are state machines? • Almost every protocol includes some kind of state • State machine is a model of the different states and the transitions between them • When receiving a messages, given the current state: • Decide what action to perform • Which message to respond with • Which state to go the next Why are state machines interesting? • State machines play a very important role in security protocols • For example: • Is the user authenticated? • Did we agree on keys? And if so, which keys? • Are we encrypting our traffic? • Every implementation of a protocol has to include the corresponding state machine • Mistakes can lead to serious security issues! State machine example Confirm transaction Verify PIN 0000 Failed Init Failed Verify PIN 1234 OK Verified Confirm transaction OK State machines in specifications • Often specifications do not explicitly contain a state machine • Mainly explained in lots of prose • Focus usually on happy flow • What to do if protocol flow deviates from this? Client Server ClientHello --------> ServerHello Certificate* ServerKeyExchange* CertificateRequest* <-------- ServerHelloDone Certificate* ClientKeyExchange CertificateVerify* [ChangeCipherSpec] Finished --------> [ChangeCipherSpec] <-------- Finished Application Data <-------> Application Data -

1 Term of Reference Reference Number TOR-VNM-2021-21
Term of Reference Reference number TOR-VNM-2021-21 (Please refer to this number in the application) Assignment title International Gender Consultant Purpose to develop a technical paper comparing legal frameworks and setting out good practices for legal recognition of gender identity/protection of the human rights of trans persons in other countries/regions. Location Home-based Contract duration 1 June 2021 – 31 August 2021 (32 working days) Contract supervision UN Women Programme Specialist UN Women Viet Nam Country Office I. Background UN Women Grounded in the vision of equality enshrined in the Charter of the United Nations, the United Nations Entity for Gender Equality and the Empowerment of Women (UN Women) works for the elimination of discrimination against women and girls; the empowerment of women; and the achievement of substantive equality between women and men. The fundamental objective of UN Women is to enhance national capacity and ownership to enable national partners to formulate gender responsive laws, policies and upscale successful strategies to deliver on national and international commitments to gender equality. UN Women Viet Nam Country Office is the chair of the UN Gender Theme Group and has been an active member of the UN Human Rights Thematic Group (HRTG) and Viet Nam UN HIV Thematic Group and acts as a leading agency in related to promoting gender equality in the national HIV response. The result under this LOA will contribute to the achievements of the following outcome and output of UN Women Viet Nam’s Annual Work Plan. - VCO Impact 3 (SP outcome 4): Women and girls live a life free from violence. -

Not-Quite-So-Broken TLS: Lessons in Re-Engineering a Security Protocol Specification and Implementation
Not-Quite-So-Broken TLS: Lessons in Re-Engineering a Security Protocol Specification and Implementation David Kaloper-Meršinjak, Hannes Mehnert, Anil Madhavapeddy, and Peter Sewell, University of Cambridge https://www.usenix.org/conference/usenixsecurity15/technical-sessions/presentation/kaloper-mersinjak This paper is included in the Proceedings of the 24th USENIX Security Symposium August 12–14, 2015 • Washington, D.C. ISBN 978-1-939133-11-3 Open access to the Proceedings of the 24th USENIX Security Symposium is sponsored by USENIX Not-quite-so-broken TLS: lessons in re-engineering a security protocol specification and implementation David Kaloper-Mersinjakˇ †, Hannes Mehnert†, Anil Madhavapeddy and Peter Sewell University of Cambridge Computer Laboratory [email protected] † These authors contributed equally to this work Abstract sensitive services, they are not providing the security we need. Transport Layer Security (TLS) is the most widely Transport Layer Security (TLS) implementations have a deployed security protocol on the Internet, used for au- history of security flaws. The immediate causes of these thentication and confidentiality, but a long history of ex- are often programming errors, e.g. in memory manage- ploits shows that its implementations have failed to guar- ment, but the root causes are more fundamental: the chal- antee either property. Analysis of these exploits typically lenges of interpreting the ambiguous prose specification, focusses on their immediate causes, e.g. errors in mem- the complexities inherent in large APIs and code bases, ory management or control flow, but we believe their root inherently unsafe programming choices, and the impos- causes are more fundamental: sibility of directly testing conformance between imple- mentations and the specification. -

Policy and Procedures for Contracting Individual Consultants
UNFPA Policies and Procedures Manual: Human Resources: Policy and Procedures for Contracting Individual Consultants Policy Title Policy and Procedures for Contracting Individual Consultants Previous title (if any) Individual Consultants Policy objective The purpose of this policy is to set out how Hiring Offices can contract the temporary services of individuals as consultants. Target audience Hiring Offices Risk control matrix Control activities that are part of the process are detailed in the Risk Control Matrix Checklist N/A Effective date 1 June 2019 Revision History Issued: 1 September 2015 Rev 1: August 2017 Mandatory revision 1 June 2022 date Policy owner unit Division for Human Resources Approval Signed approval UNFPA Policies and Procedures Manual: Human Resources: Policy and Procedures for Contracting Individual Consultants POLICY AND PROCEDURES FOR CONTRACTING INDIVIDUAL CONSULTANTS TABLE OF CONTENTS I. PURPOSE ....................................................................................................................... 1 II. POLICY ........................................................................................................................... 1 III. PROCEDURES ............................................................................................................... 2 Initiating request for individual consultant ............................................................................ 2 Verifying availability of funds .............................................................................................. -

A Technical Comparison of Ipsec and SSL
A Technical Comparison of IPSec and SSL y Ab delNasir Alshamsi Takamichi Saito Tokyo University of Technology Abstract p osed but the most famous secure and widely de ployed are IPSec IP Security and SSL Secure So cket Layer IPSec IP Security and SSL SecureSocket Layer In this pap er we will provide a technical comparison have been the most robust and most potential tools of IPSec and SSL the similarities and the dierences available for securing communications over the Inter of the cryptographic prop erties The results of per net Both IPSec and SSL have advantages and short formance are based on comparing FreeSWAN as comings Yet no paper has been found comparing the IPSec and Stunnel as SSL two protocols in terms of characteristic and functional ity Our objective is to present an analysis of security and performancepr operties for IPSec and SSL IPSec IPSec is an IP layer proto col that enables the Intro duction sending and receiving of cryptographically protected packets of any kind TCPUDPICMPetc without any provides two kinds of crypto mo dication IPSec Securing data over the network is hard and compli graphic services Based on necessity IPSec can provide cated issue while the threat of data mo dication and condentiality and authenticity or it can provide data interruption is rising The goal of network security authenticity only is to provide condentiality integrity and authenticity Condentiality is keeping the data secret from the ESP Encapsulated SecurityPayload unintended listeners on the network Integrity is en suring -
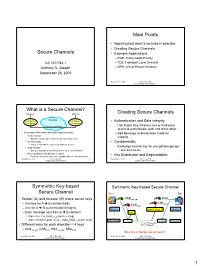
Secure Channels Secure Channels • Example Applications – PGP: Pretty Good Privacy CS 161/194-1 – TLS: Transport Layer Security Anthony D
Main Points • Applying last week’s lectures in practice • Creating Secure Channels Secure Channels • Example Applications – PGP: Pretty Good Privacy CS 161/194-1 – TLS: Transport Layer Security Anthony D. Joseph – VPN: Virtual Private Network September 26, 2005 September 26, 2005 CS161 Fall 2005 2 Joseph/Tygar/Vazirani/Wagner What is a Secure Channel? Plaintext Plaintext Creating Secure Channels Encryption / Internet Encryption / • Authentication and Data Integrity Decryption Decryption Ciphertext and MAC – Use Public Key Infrastructure or third-party server to authenticate each end to the other • A stream with these security requirements: – Add Message Authentication Code for – Authentication integrity • Ensures sender and receiver are who they claim to be – Confidentiality • Confidentiality • Ensures that data is read only by authorized users – Data integrity – Exchange session key for encrypt/decrypt ops • Ensures that data is not changed from source to destination • Bulk data transfer – Non-repudiation (not discussed today) • Ensures that sender can’t deny message and rcvr can’t deny msg • Key Distribution and Segmentation September 26, 2005 CS161 Fall 2005 3 September 26, 2005 CS161 Fall 2005 4 Joseph/Tygar/Vazirani/Wagner Joseph/Tygar/Vazirani/Wagner Symmetric Key-based Symmetric Key-based Secure Channel Secure Channel Alice Bob • Sender (A) and receiver (B) share secret keys KABencrypt KABencrypt – One key for A è B confidentiality KABauth KABauth – One for A è B authentication/integrity Message MAC Compare? Message – Each message -

Plaintext-Recovery Attacks Against Datagram TLS
Plaintext-Recovery Attacks Against Datagram TLS Nadhem J. AlFardan and Kenneth G. Paterson∗ Information Security Group Royal Holloway, University of London, Egham, Surrey TW20 0EX, UK fNadhem.Alfardan.2009, [email protected] Abstract GnuTLS2. Both of these provide source toolkits that imple- ment TLS and DTLS as well as being general purpose cryp- The Datagram Transport Layer Security (DTLS) proto- tographic libraries that software developers can use. The col provides confidentiality and integrity of data exchanged first release of OpenSSL to implement DTLS was 0.9.8. between a client and a server. We describe an efficient and Since its release, DTLS has become a mainstream proto- full plaintext recovery attack against the OpenSSL imple- col in OpenSSL. There are also a number of commercial mentation of DTLS, and a partial plaintext recovery attack products that have taken advantage of DTLS. For example, against the GnuTLS implementation of DTLS. The attack DTLS is used to secure Virtual Private Networks (VPNs)3;4 against the OpenSSL implementation is a variant of Vaude- and wireless traffic5. Platforms such as Microsoft Windows, nay’s padding oracle attack and exploits small timing differ- Microsoft .NET and Linux can also make use of DTLS6. ences arising during the cryptographic processing of DTLS In addition, the number of RFC documents that are be- packets. It would have been prevented if the OpenSSL im- ing published on DTLS is increasing. Recent examples in- plementation had been in accordance with the DTLS RFC. clude RFC 5415 [1], RFC 5953 [8] and RFC 6012 [13]. A In contrast, the GnuTLS implementation does follow the new version of DTLS is currently under development in the DTLS RFC closely, but is still vulnerable to attack. -

Chapter 11: Building Secure Software Lars-Helge Netland [email protected] 10.10.2005 INF329: Utvikling Av Sikre Applikasjoner Overview
Programming with cryptography Chapter 11: Building Secure Software Lars-Helge Netland [email protected] 10.10.2005 INF329: Utvikling av sikre applikasjoner Overview Intro: The importance of cryptography The fundamental theorem of cryptography Available cryptographic libraries Java code examples One-time pads Summary 2 Intro Cryptography ‘kryptos’(=hidden) ‘graphein’ (=to write) Layman description: the science of encrypting and decrypting text 3 The Code Book Simon Singh Highly accessible introduction to cryptography Retails at $10 (free at public libraries) Includes crypto challenges 4 Crypto: Why is it important?(I) Basic services: confidentiality encrypted text only viewable by the intended recipient integrity assurance to the involved parties that the text was not tampered with in transit authentication proof of a binding of an identity to an identification tag (often involves trusted third parties) 5 Crypto: Why is it important?(II) Basic services (continued) authorization restricting access to resources (often involves authentication) digital signatures electronic equivalent of hand-written signatures non-repudiation 6 The fundamental theorem of cryptography Do NOT develop your own cryptographic primitives or protocols The history of cryptography repeatedly shows how “secure” systems have been broken due to unknown vulnerabilities in the design If you really have to: PUBLISH the algorithm 7 Examples on how ciphers have been broken Early substitution ciphers broken by exploiting the relative frequency of letters WW2: The enigma machine