Towards an Intelligent Multilingual Keyboard System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

DEC Text Processing Utility Reference Manual
DEC Text Processing Utility Reference Manual Order Number: AA–PWCCD–TE April 2001 This manual describes the elements of the DEC Text Processing Utility (DECTPU). It is intended as a reference manual for experienced programmers. Revision/Update Information: This manual supersedes the DEC Text Processing Utility Reference Manual, Version 3.1 for OpenVMS Version 7.2. Software Version: DEC Text Processing Utility Version 3.1 for OpenVMS Alpha Version 7.3 and OpenVMS VAX Version 7.3 The content of this document has not changed since OpenVMS Version 7.1. Compaq Computer Corporation Houston, Texas © 2001 Compaq Computer Corporation COMPAQ, VAX, VMS, and the Compaq logo Registered in U.S. Patent and Trademark Office. OpenVMS is a trademark of Compaq Information Technologies Group, L.P. Motif is a trademark of The Open Group. PostScript is a registered trademark of Adobe Systems Incorporated. All other product names mentioned herein may be the trademarks or registered trademarks of their respective companies. Confidential computer software. Valid license from Compaq or authorized sublicensor required for possession, use, or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor’s standard commercial license. Compaq shall not be liable for technical or editorial errors or omissions contained herein. The information in this document is provided "as is" without warranty of any kind and is subject to change without notice. The warranties for Compaq products are set forth in the express limited warranty statements accompanying such products. -
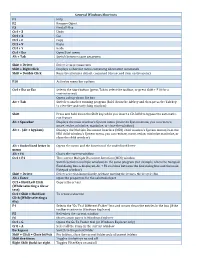
General Windows Shortcuts
General Windows Shortcuts F1 Help F2 Rename Object F3 Find all files Ctrl + Z Undo Ctrl + X Cut Ctrl + C Copy Ctrl + V Paste Ctrl + Y Redo Ctrl + Esc Open Start menu Alt + Tab Switch between open programs Alt + F4 Quit program Shift + Delete Delete item permanently Shift + Right Click Displays a shortcut menu containing alternative commands Shift + Double Click Runs the alternate default command ( the second item on the menu) Alt + Double Click Displays properties F10 Activates menu bar options Shift + F10 Opens a contex t menu ( same as righ t click) Ctrl + Esc or Esc Selects the Start button (press Tab to select the taskbar, or press Shift + F10 for a context menu) Alt + Down Arrow Opens a drop‐down list box Alt + Tab Switch to another running program (hold down the Alt key and then press the Tab key to view the task‐switching window) Alt + Shift + Tab Swit ch b ackward s b etween open appli cati ons Shift Press and hold down the Shift key while you insert a CD‐ROM to bypass the automatic‐ run feature Alt + Spacebar Displays the main window's System menu (from the System menu, you can restore, move, resize, minimize, maximize, or close the window) Alt + (Alt + hyphen) Displays the Multiple Document Interface (MDI) child window's System menu (from the MDI child window's System menu, you can restore, move, resize, minimize maximize, or close the child window) Ctrl + Tab Switch to t h e next child window o f a Multi ple D ocument Interf ace (MDI) pr ogram Alt + Underlined letter in Opens the menu and the function of the underlined letter -

Guide to the DEC Text Processing Utility
Guide to the DEC Text Processing Utility Order Number: AA–PWCBD–TE April 2001 This manual introduces the DEC Text Processing Utility (DECTPU). It is for experienced programmers as well as new users of DECTPU. Revision/Update Information: This manual supersedes the Guide to the DEC Text Processing Utility, Version 3.1 Software Version: OpenVMS Alpha Version 7.3 OpenVMS VAX Version 7.3 The content of this manual has not changed sinced OpenVMS Version 7.1 Compaq Computer Corporation Houston, Texas © 2001 Compaq Computer Corporation Compaq, VAX, VMS and the Compaq logo Registered in U.S. Patent and Trademark Office. OpenVMS is a trademark of Compaq Information Technologies Group, L.P. in the United States and other countries. PostScript is a registered trademark of Adobe Systems Incorporated. Motif is a registered trademark of the The Open Group. All other product names mentioned herein may be the trademarks or registered trademarks of their respective companies. Confidential computer software. Valid license from Compaq or authorized sublicensor required for possession, use, or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor’s standard commercial license. Compaq shall not be liable for technical or editorial errors or omissions contained herein. The information in this document is provided "as is" without warranty of any kind and is subject to change without notice. The warranties for Compaq products are set forth in the express limited warranty statements accompanying such products. Nothing herein should be construed as constituting an additional warranty. -

Startup Keyboard Shortcuts Press the Key Or Key Combination Until The
Startup keyboard shortcuts Press the key or key combination until the expected function occurs/appears (for example, hold Option during startup until Startup Manager appears, or Shift until "Safe Boot" appears). Tip: If a startup function doesn't work and you use a third-party keyboard, connect an Apple keyboard and try again. Key or key combination What it does Option Display all bootable volumes (Startup Manager) Shift Perform Safe Boot (start up in Safe Mode) C Start from a bootable disc (DVD, CD) T Start in FireWire target disk mode N Start from NetBoot server X Force Mac OS X startup (if non-Mac OS X startup volumes are present) Command-V Start in Verbose Mode Command-S Start in Single User Mode To use a keyboard shortcut, or key combination, you press a modifier key with a character key. For example, pressing the Command key (the key with a symbol) and the "c" key at the same time copies whatever is currently selected (text, graphics, and so forth) into the Clipboard. This is also known as the Command-C key combination (or keyboard shortcut). A modifier key is a part of many key combinations. A modifier key alters the way other keystrokes or mouse clicks are interpreted by Mac OS X. Modifier keys include: Command, Control, Option, Shift, Caps Lock, and the fn key (if your keyboard has a fn key). Here are the modifier key symbols you can see in Mac OS X menus: (Command key) - On some Apple keyboards, this key also has an Apple logo ( ) (Control key) (Option key) - "Alt" may also appear on this key (Shift key) (Caps Lock) - Toggles Caps Lock on or off fn (Function key) Startup keyboard shortcuts Press the key or key combination until the expected function occurs/appears (for example, hold Option during startup until Startup Manager appears, or Shift until "Safe Boot" appears). -

Keyboard Scan Code Specification
Windows Platform Design Notes Designing Hardware for the Microsoft® Windows® Family of Operating Systems Keyboard Scan Code Specification Abstract: This specification details the PS/2 Scan Codes and USB Usage Tables that are validated for compliance to the Microsoft® Windows® Logo Program testing standard. This document details the alternative make and break PS/2 scan code and USB code response for the Windows Logo Key and Application Keys, plus Advanced Configuration and Power Interface (ACPI) power controls. This specification was previous published, with the same content, as “Windows Hardware Quality Labs Keyboard Specification” and also referred to as “Windows Keys Specification” and “New Keys Specification.” Revision 1.3a — March 16, 2000 Disclaimer: The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented. This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT. Microsoft Corporation may have patents or pending patent applications, trademarks, copyrights, or other intellectual property rights covering subject matter in this document. The furnishing of this document does not give you any license to the patents, trademarks, copyrights, or other intellectual property rights except as expressly provided in any written license agreement from Microsoft Corporation. Microsoft does not make any representation or warranty regarding specifications in this document or any product or item developed based on these specifications. -

MACBOOK Keyboard Shortcuts
MACBOOK Keyboard Shortcuts Learn about common OS X keyboard shortcuts. A keyboard shortcut is a way to invoke a function in OS X by pressing a combination of keys on your keyboard. To use a keyboard shortcut, or key combination, you press a modifier key with a character key. For example, pressing the Command key (the key that has a symbol) and the "c" key at the same time copies whatever is currently selected (text, graphics, and so forth) into the Clipboard. This is also known as the Command-C key combination (or keyboard shortcut). A modifier key is a part of many key combinations. A modifier key alters the way other keystrokes or mouse/trackpad clicks are interpreted by OS X. Modifier keys include: Command, Shift, Option, Control, Caps Lock, and the Fn key. If your keyboard has an Fn key, you may need to use it in some of the key combinations listed below. For example, if the keyboard shortcut is Control-F2, press Fn-Control-F2. Here are the modifier key symbols you may see in OS X menus: ⌘ Command key ⌃ Control key ⌥ Option key ⇧ Shift Key ⇪ Caps Lock Fn Function Key Startup shortcuts Press the key or key combination until the expected function occurs/appears (for example, hold Option during startup until Startup Manager appears, or Shift until "Safe Boot" appears). Tip: If a startup function doesn't work and you use a third-party keyboard, try again with an Apple keyboard. Key or key combination What it does Display all bootable volumes (Startup Option Manager) Shift Perform a Safe Boot (start up in Safe Mode) Left Shift Prevent -

454 Keystrokes in Silverfast
Keystrokes in SilverFast Action Macintosh Windows Description of keyboard shortcuts and their respective counterparts Command . Command-/Apple-Key . – Alt . Opion-/Alt-Key . Alt-Key Shift . Shift-Key . Shift-Key Ctrl . Control-/Ctrl-Key . Control-/Ctrl-Key Return . Return-/Enter-Key . Return-/Enter-Key Esc . Escape-/Esc-Key . Escape-/Esc-Key ScanPilot / ImagePilot Apply / Execute current tool . Return . Return Scroll / Next action . Up and Down arrow . Up and Down arrow Prescan, scan / Preview, process Stop prescan / stop scan . Command+Period . Strg+Period Switch to other colour space . Ctrl+Click on . Right mouse button+Click on Scan-/Process-button . Scan-/Process-button Zoom Ctrl+Click&Drag . Ctrl+Click&Drag Image frames Duplicate frame . Alt+Click&Drag . Alt+Click&Drag Entire Window in one frame . Command+A . Ctrl+A Delete frame (extended keyboard) . Delete . Delete Delete frame (normal keyboard) . Alt+Backspace . Delete Frame reset . Reset-button . Reset-button Copy settings of one frame . Alt+Click on active frame, . Alt+Click into inactive into an other frame click then into target frame . target frame 454 7.3 • Addendum SilverFast® Manual Action Macintosh Windows Auto-adjust Resetting auto-adjust . Alt+click on . Alt+Click on Auto-adjust button . Auto-adjust button Highlight / shadow / midtone tool (HSM-tool) Set highlight . Click on white triangle of HSM-tool Set midtone . Click on pipette of HSM-tool Set shadow . Click on black triangle of HSM-tool Multiple attempts with pipette Hold down pipette for multiple . hold down Alt . hold down Alt attempts (only highlight, shadow) Reset highlight / shadow . Alt+Pippette of HSM-tool Display brightest point . Click on white square . -

Use the Keyboard with the Ipad (PDF)
Computers for Beginners 2: Use the Keyboard Mar 2020 YG/ DC Learning Outcomes In this class you will: 1. Familiarize yourself with alphabet keys, number keys and symbol keys. 2. Practice typing using an iPad App. 3. Review where to get more typing practice. 2 What is a Keyboard? The keyboard is a piece of equipment used to communicate with a computer. It allows you to enter data into a computer. iPads come with a “virtual keyboard” which appears whenever you open an app which requires typing. Tap once on suggested words to autofill To use numbers and To hide the symbols tap here keyboard tap here To return to the letter keyboard tap here 3 Exercise 1: Tour the keyboard Typing Touch typing is the ability to use muscle memory to find keys quickly using all fingers. Touch typing is an acquired skill that takes practice. Touch typing is not the goal of this class. For now, don’t worry if you use only a few fingers. You will get more comfortable with practice. Accuracy, not speed, is the goal. In North America we call this a QWERTY keyboard. Can anyone tell me why? This diagram depicts the “classic” layout of the keys in rows. Most practice lessons use the terms: Home Row, Top Row, Bottom Row. Backspace Key Top Row Home Row Bottom Row Spacebar Shift Keys 4 In addition to the letter keys, you will use the Spacebar to create spaces between words. Use the Return Key (or Enter Key) to move your cursor (a vertical line which indicates where you can type) to the next line and begin typing a new sentence. -
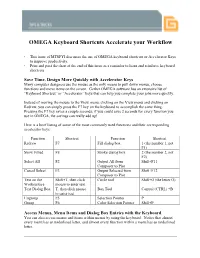
OMEGA Keyboard Shortcuts Accelerate Your Workflow
. OMEGA Keyboard Shortcuts Accelerate your Workflow • This issue of MTSFYI discusses the use of OMEGA keyboard shortcuts or Accelerator Keys to improve productivity. • Print and post the chart at the end of this issue as a reminder to learn and reinforce keyboard shortcuts. Save Time, Design More Quickly with Accelerator Keys Many computer designers use the mouse as the only means to pull down menus, choose functions and move items on the screen. Gerber OMEGA software has an extensive list of “Keyboard Shortcut” or “Accelerator” keys that can help you complete your jobs more quickly. Instead of moving the mouse to the View menu, clicking on the View menu and clicking on Redraw, you can simply press the F7 key on the keyboard to accomplish the same thing. Pressing the F7 key saves a couple seconds; if you could save 2 seconds for every function you use in OMEGA, the savings can really add up! Here is a brief listing of some of the most commonly used functions and their corresponding accelerator keys: Function Shortcut Function Shortcut Redraw F7 Fill dialog box 1 (the number 1, not F1) Show Filled F8 Stroke dialog box 2 (the number 2, not F2) Select All F2 Output All from Shift+F11 Composer to Plot Cancel Select F3 Output Selected from Shift+F12 Composer to Plot Text on the Shift+T, then click Circle tool Shift+O (the letter O) Worksurface mouse to enter text Text Dialog Box T, then click mouse Box Tool Control (CTRL) +B to enter text Ungroup F5 Selection Pointer P Group F6 Color Selection Pointer Shift+P Access Menus, Menu Items and Dialog Box Entries with the Keyboard You can also access menus and items within menus by using the keyboard. -

Assignment 4 Resources for POWER KEYS.Pdf
Resource Page for Assignment #4 in Computer Literacy – Dr. Phoenix – 109 – 4-11-20 POWER KEYS We have studied “power-keys” in class. They are also known as short-cuts, or keyboard short- cuts. They let users to execute complicated actions with simple commands using the keyboard. Shortcut keys make for an easier and faster way of getting around a program (navigating) and executing commands in computer software (getting the computer software to do things!) Shortcut keys are most often use the Alt key (on Dell compatible computers), Command key (on Apple computers), Ctrl key, or Shift key along with another key. The standard for noting a shortcut is using the modifier key, a plus symbol, and another key. For example: “Ctrl+O” means to press and hold down the Ctrl key, and then press the O key too. Because Power Keys save so much time, it is useful to memorize them. The more you use them, the more you will begin to see that they will work in many programs. If you look at the icons in the Microsoft “Ribbon” at the top of your page, and hover your mouse pointer over an icon, often times the program will name the icon and provide the control key and letter combination. For instance, on the “HOME” tab in Microsoft Word, if you hover your mouse pointer over the underlined U on the left side of the ribbon, a little message box will pop-up with the following message: “Underline (Ctrl+U) Underline your text.” When using Power keys, just remember that sometimes you have to SELECT SOMETHING before the Power Key will do what you want it to do. -

Title Keyboard : All Special Keys : Enter, Del, Shift, Backspace ,Tab … Contributors Dhanya.P Std II Reviewers Submission Approval Date Date Ref No
Title Keyboard : All special keys : Enter, Del, Shift, Backspace ,Tab ¼ Contributors Dhanya.P Std II Reviewers Submission Approval Date Date Ref No: This topic describes the special keys on the keyboard of a computer Brief Description and their functionalities . Goal To familiarize the special keys on the keyboard of a computer. Pre-requisites Familiarity with computer. Learning Concepts that special keys on a keyboard has special functionalities. Outcome One Period Duration http://www.ckls.org/~crippel/computerlab/tutorials/keyboard/ References http://computer.howstuffworks.com/ Page Nos: 2,3,4,5,6 Detailed Description Page No: 7 Lesson Plan Page No: 7 Worksheet Page No: 8 Evaluation Page No: 8 Other Notes Detailed Description A computer keyboard is a peripheral , partially modeled after the typewriter keyboard. Keyboards are designed for the input of text and characters. Special Keys Function Keys Cursor Control Keys Esc Key Control Key Shift Key Enter Key Tab Key Insert Key Delete Key ScrollLock Key NumLock Key CapsLock Key Pasue/Break Key PrtScr Key Function Keys F1 through F12 are the function keys. They have special purposes. The following are mainly the purpose of the function keys. But it may vary according to the software currently running. # F1 - Help # F2 - Renames selected file # F3 - Opens the file search box # F4 - Opens the address bar in Windows Explorer # F5 - Refreshes the screen in Windows Explorer # F6 - Navigates between different sections of a Windows Explorer window # F8 - Opens the start-up menu when booting Windows # F11 - Opens full screen mode in Explorer Function Keys F1 through F12 are the function keys. -

E1115F PS2 Keyboard to ASCII Converter Datasheet
Locus Engineering Inc E1115F PS/2 Keyboard to ASCII Converter E1115F Host PS/2 Keyboard PS/2 to ACII Microcontroller Converter FEATURES Decodes PS/2 Scanset 2 keystrokes to a single ASCII byte on make Offload process intensive PS/2 keyboard decoding Unique single byte codes for non-ASCII keys including multi-media keys Simple interface between PS/2 keyboard and any host microcontroller Selectable 57.6 & 115.2 KBaud serial data output 100 KHz clocked serial data output Ctrl-Alt-Del reset & Escape key reset outputs APPLICATIONS Interrupt and LED flash output ● Enhance microcontroller applications with keyboard data 3.3V 120mA regulated output ● Process control Low cost ● Robotics control Upgrade from E1115B/D versions DESCRIPTION the task and provides a single decoded byte The E1115F PS/2 Keyboard to ASCII Converter corresponding to the keystroke, the host can module allows a microcontroller application to be concentrate on its own application while being enhanced with keyboard numeric and text data interrupted only when necessary. Non-ASCII keys without having to handle the tedious scancode are also decoded to a unique code. The E1115F detection and decoding process. This module module provides both serial data and clocked serial receives the complex scancode sequence for data at ~100 KHz. An interrupt signal and a LED each keystroke on the “make”, and decodes it flash output are also provided. Pressing Ctrl-Alt- to a unique ASCII byte which is easier to use Del generates a one second reset output while by a host application. This frees up the host pressing the Escape key generates a separate 8msec microcontroller considerably since it does not reset output.