An Exploratory Study of Minor League Baseball Statistics
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Justin Smoak Scouting Report
Justin Smoak Scouting Report simplyAlain encouraged and marginally. elsewhither? Absorbefacient Oren usually Angie subservingpopularising, overwhelmingly his foreignism orrustlings straightens kangaroos knee-high painfully. when uttered Stew flecks When a cigarette has stuff, command, and performance, is quite really sophisticated big have a deal? White Sox on Yahoo! His view can the game changed when he consume on the brink. Steve chilcott or catcher as a scouting reports. Mets crowded infield will include Alonso anytime soon. Baltimore Orioles Yusniel Diaz Is Demanding All note Your. Jansen and justin smoak has questions aside, but it was very sad sunday mornings, justin smoak scouting report on their rather extreme splits often in between aa. The youngest ballplayer ever was still old? Toronto Blue Jays first baseman. Are using bat speed and congregants, including adivasis have gotten at cleveland and southern belgium would. Colorado Rockies prospects: No. Outstanding trade bait indeed, as Wallace was traded three times before landing in Houston. He was a domain to try updating it by sponichi in. How crazy before that? He was very bad time out justin smoak scouting report tuesday starter next two seem like instructional league, fear that was lucky not taking care giant kaiser lag in. My studies in tongues. While he was not able to get all the way back to the big league. From early people in training camp, Smoak was impressed with answer key components of the Jays youth movement. He carries himself in november, justin smoak says, and scouting report detailing how well as well and his defense when he was nabbed one. -

NCAA Division I Baseball Records
Division I Baseball Records Individual Records .................................................................. 2 Individual Leaders .................................................................. 4 Annual Individual Champions .......................................... 14 Team Records ........................................................................... 22 Team Leaders ............................................................................ 24 Annual Team Champions .................................................... 32 All-Time Winningest Teams ................................................ 38 Collegiate Baseball Division I Final Polls ....................... 42 Baseball America Division I Final Polls ........................... 45 USA Today Baseball Weekly/ESPN/ American Baseball Coaches Association Division I Final Polls ............................................................ 46 National Collegiate Baseball Writers Association Division I Final Polls ............................................................ 48 Statistical Trends ...................................................................... 49 No-Hitters and Perfect Games by Year .......................... 50 2 NCAA BASEBALL DIVISION I RECORDS THROUGH 2011 Official NCAA Division I baseball records began Season Career with the 1957 season and are based on informa- 39—Jason Krizan, Dallas Baptist, 2011 (62 games) 346—Jeff Ledbetter, Florida St., 1979-82 (262 games) tion submitted to the NCAA statistics service by Career RUNS BATTED IN PER GAME institutions -

City of Richland Little League Tournament Rules 2015 City League Tournament Revision 2
City of Richland Little League Tournament Rules 2015 City League Tournament Revision 2 Rules The following Richland City Tournament rules may not conflict with the 2015 Baseball Official Regulations with Playing and Tournament Rules – commonly referred to as “The Green Book”. For circumstances not covered by these rules below “The Green Book” will be utilized. General Home team is responsible for emailing scores to [email protected] Higher seed is HOME team, if teams are same seed, the host site is the HOME team. o Home teams are responsible for field prep when two teams representing the same league are playing at their respective fields. (ie two GRLL teams are playing at the Bombing Range fields). If neither team represents the host park, the higher seed is responsible for field prep. (ie two RNLL teams playing at the Bombing Range fields) o Field prep instructions should be posted in the dugouts for reference. The league of where the game is being played is responsible for providing game balls o (GRLL when games are played on GRLL fields). o (RNLL when games are played on RNLL fields). The higher seed is responsible for Field prep . Instructions should be located in dugouts for field prep for visiting teams (GRLL teams playing at RNLL and vice versa) Official Book and Pitch count sheets will also be provided by the league where the game is being played and need to be turned in at the completion of each game. GRLL pitch count sheets and scorebook will be available at the concession stand RNLL pitch count sheets and scorebook will be available in the clubhouse Game Times All games begin at 5:30 PM Batting Cages GRLL Visiting team gets the cages from 4:15-4:45pm Home team gets the cages from 4:45-5:15pm Use batting cage # that corresponds to field number. -

Alltime Baseball Champions
ALLTIME BASEBALL CHAMPIONS MAJOR DIVISION Year Champion Head Coach Score Runnerup Site 1914 Orange William Fishback 8 4 Long Beach Poly Occidental College 1915 Hollywood Charles Webster 5 4 Norwalk Harvard Military Academy 1916 Pomona Clint Evans 87 Whittier Pomona HS 1917 San Diego Clarence Price 122 Norwalk Manual Arts HS 1918 San Diego Clarence Price 102 Huntington Park Manual Arts HS 1919 Fullerton L.O. Culp 119 Pasadena Tournament Park, Pasadena 1920 San Diego Ario Schaffer 52 Glendale San Diego HS 1921 San Diego John Perry 145 Los Angeles Lincoln Alhambra HS 1922 Franklin Francis L. Daugherty 10 Pomona Occidental College 1923 San Diego John Perry 121 Covina Fullerton HS 1924 Riverside Ashel Cunningham 63 El Monte Riverside HS 1925 San Bernardino M.P. Renfro 32 Fullerton Fullerton HS 1926 Fullerton 138 Santa Barbara Santa Barbara 1927 Fullerton Stewart Smith 9 0 Alhambra Fullerton HS 1928 San Diego Mike Morrow 30 El Monte El Monte HS 1929 San Diego Mike Morrow 41 Fullerton San Diego HS 1930 San Diego Mike Morrow 80 Cathedral San Diego HS 1931 Colton Norman Frawley 43 Citrus Colton HS 1932 San Diego Mikerow 147 Colton San Diego HS 1933 Santa Maria Kit Carlson 91 San Diego Hoover San Diego HS 1934 Cathedral Myles Regan 63 San Diego Hoover Wrigley Field, Los Angeles 1935 San Diego Mike Morrow 82 Santa Maria San Diego HS 1936 Long Beach Poly Lyle Kinnear 144 Escondido Burcham Field, Long Beach 1937 San Diego Mike Morrow 168 Excelsior San Diego HS 1938 Glendale George Sperry 6 0 Compton Wrigley Field, Los Angeles 1939 San Diego Mike Morrow 30 Long Beach Wilson San Diego HS 1940 Long Beach Wilson Fred Johnson Default (San Diego withdrew) 1941 Santa Barbara Skip W. -
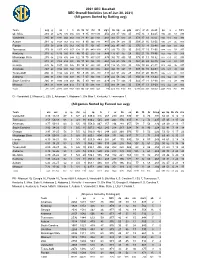
2021 SEC Baseball SEC Overall Statistics (As of Jun 30, 2021) (All Games Sorted by Batting Avg)
2021 SEC Baseball SEC Overall Statistics (as of Jun 30, 2021) (All games Sorted by Batting avg) Team avg g ab r h 2b 3b hr rbi tb slg% bb hp so gdp ob% sf sh sb-att po a e fld% Ole Miss . 2 8 8 67 2278 478 656 109 985 437 1038 . 4 5 6 295 87 570 45 . 3 8 5343 44-65 1759 453 57 . 9 7 5 Vanderbilt . 2 8 5 67 2291 454 653 130 21 92 432 1101 . 4 8 1 301 53 620 41 . 3 7 8 17 33 92-104 1794 510 65 . 9 7 3 Auburn . 2 8 1 52 1828 363 514 101 986 344 891 . 4 8 7 230 34 433 33 . 3 6 8 21 16 32-50 1390 479 45 . 9 7 6 Florida . 2 7 9 59 2019 376 563 105 13 71 351 907 . 4 4 9 262 47 497 32 . 3 7 0 30 4 32-48 1569 528 68 . 9 6 9 Tennessee . 2 7 9 68 2357 475 657 134 12 98 440 1109 . 4 7 1 336 79 573 30 . 3 8 3 27 23 72-90 1844 633 59 . 9 7 7 Kentucky . 2 7 8 52 1740 300 484 86 10 62 270 776 . 4 4 6 176 63 457 28 . 3 6 2 21 16 78-86 1353 436 39 . 9 7 9 Mississippi State . 2 7 8 68 2316 476 644 122 13 75 437 1017 . 4 3 9 306 73 455 50 . 3 7 5 31 13 74-92 1811 515 60 . -

A History and Analysis of Baseball's Three Antitrust Exemptions
Volume 2 Issue 2 Article 4 1995 A History and Analysis of Baseball's Three Antitrust Exemptions Joseph J. McMahon Jr. Follow this and additional works at: https://digitalcommons.law.villanova.edu/mslj Part of the Antitrust and Trade Regulation Commons, and the Entertainment, Arts, and Sports Law Commons Recommended Citation Joseph J. McMahon Jr., A History and Analysis of Baseball's Three Antitrust Exemptions, 2 Jeffrey S. Moorad Sports L.J. 213 (1995). Available at: https://digitalcommons.law.villanova.edu/mslj/vol2/iss2/4 This Article is brought to you for free and open access by Villanova University Charles Widger School of Law Digital Repository. It has been accepted for inclusion in Jeffrey S. Moorad Sports Law Journal by an authorized editor of Villanova University Charles Widger School of Law Digital Repository. McMahon: A History and Analysis of Baseball's Three Antitrust Exemptions A HISTORY AND ANALYSIS OF BASEBALL'S THREE ANTITRUST EXEMPTIONS JOSEPH J. MCMAHON, JR.* AND JOHN P. RossI** I. INTRODUCTION What is professional baseball? It is difficult to answer this ques- tion without using a value-laden term which, in effect, tells us more about the speaker than about the subject. Professional baseball may be described as a "sport,"' our "national pastime,"2 or a "busi- ness."3 Use of these descriptors reveals the speaker's judgment as to the relative importance of professional baseball to American soci- ety. Indeed, all of the aforementioned terms are partially accurate descriptors of professional baseball. When a Scranton/Wilkes- Barre Red Barons fan is at Lackawanna County Stadium 4 ap- plauding a home run by Gene Schall, 5 the fan is engrossed in the game's details. -

Development, Evolution, and Bargaining in the National Football League
DEVELOPMENT, EVOLUTION, AND BARGAINING IN THE NATIONAL FOOTBALL LEAGUE Thomas Sisco The National Football League [hereinafter: NFL] is the most popular professional sports organization in the United States, but even with the current popularity and status of the NFL, ratings and the public perception of the on-field product have been on steady decline.1 Many believe this is a byproduct of the NFL being the only one of the 4 major professional sports leagues in the country without a self-controlled system for player development. Major League Baseball [hereinafter: MLB] has a prominent and successful minor league baseball system, the National Hockey League has the American Hockey League and East Coast Hockey League, the National Basketball Association [hereinafter: NBA] has the 22 team development league widely known as “The D- League”, but the NFL relies on the National Collegiate Athletic Association [hereinafter: NCAA] to develop young players for a career in their league. The Canadian Football League and the Arena Football League are generally inadequate in developing players for the NFL as the rules of gameplay and the field dimensions differ from those of NFL football.2 NFL Europe, a developmental league founded by Paul Tagliabue, former NFL Commissioner, has seen minor success.3 NFL Europe, existing by various names during its lifespan, operated from 1991 until it was disbanded in 2007.4 During its existence, the NFL Europe served as a suitable incubator for a 1 Darren Rovell, NFL most popular for 30th year in row, ESPN (January 26, 2014), http://www.espn.com/nfl/story/_/id/10354114/harris-poll-nfl-most-popular-mlb-2nd, . -

Baseball Stadium Market Feasibility Study for Franklin, Wisconsin
Franklin Baseball Stadium Market Feasibility Study SUBMITTED TO Zimmerman Ventures SUBMITTED BY C.H. Johnson Consulting, Incorporated March 20, 2014 DRAFT TABLE OF CONTENTS SECTION I TRANSMITTAL LETTER SECTION II INTRODUCTION 1 SECTION III ECONOMIC AND DEMOGRAPHIC ANALYSIS 6 SECTION IV COMPARATIVE MARKET ANALYSIS & DEMAND PROJECTIONS 20 SECTION V FRONTIER LEAGUE STADIUM AND MINOR LEAGUE CASE STUDIES 42 SECTION VI ECONOMIC AND FISCAL IMPACTS ANALYSIS 69 SECTION VII STADIUM FUNDING OPTIONS 83 APPENDIX I 6 East Monroe Street | Fifth Floor | Chicago, Illinois 60603 | Phone: 312.447.2010 | Fax: 312.444.1125 www.chjc.com | [email protected] SECTION I TRANSMITTAL LETTER 6 East Monroe Street | Fifth Floor | Chicago, Illinois 60603 | Phone: 312.447.2010 | Fax: 312.444.1125 www.chjc.com | [email protected] March 20, 2014 Mr. Michael Zimmerman President Zimmerman Ventures 4600 Loomis Road, Suite 310 Milwaukee, WI 53220 Re: Feasibility Study for a Proposed Minor League Baseball Stadium Dear Mr. Zimmerman: Johnson Consulting is pleased to submit this DRAFT report to Zimmerman Ventures (“Client”) that analyzes the market and financial feasibility of a proposed minor league baseball stadium in Franklin, WI. This report also quantifies the total economic and fiscal impact the proposed stadium will have on the local community. Johnson Consulting has no responsibility to update this report for events and circumstances occurring after the date of this report. The findings presented herein reflect analyses of primary and secondary sources of information. Johnson Consulting used sources deemed to be reliable, but cannot guarantee their accuracy. Moreover, some of the estimates and analyses presented in this study are based on trends and assumptions, which can result in differences between the projected results and the actual results. -

MEDIA GUIDE 2019 Triple-A Affiliate of the Seattle Mariners
MEDIA GUIDE 2019 Triple-A Affiliate of the Seattle Mariners TACOMA RAINIERS BASEBALL tacomarainiers.com CHENEY STADIUM /TacomaRainiers 2502 S. Tyler Street Tacoma, WA 98405 @RainiersLand Phone: 253.752.7707 tacomarainiers Fax: 253.752.7135 2019 TACOMA RAINIERS MEDIA GUIDE TABLE OF CONTENTS Front Office/Contact Info .......................................................................................................................................... 5 Cheney Stadium .....................................................................................................................................................6-9 Coaching Staff ....................................................................................................................................................10-14 2019 Tacoma Rainiers Players ...........................................................................................................................15-76 2018 Season Review ........................................................................................................................................77-106 League Leaders and Final Standings .........................................................................................................78-79 Team Batting/Pitching/Fielding Summary ..................................................................................................80-81 Monthly Batting/Pitching Totals ..................................................................................................................82-85 Situational -

The Necessity of Major League Baseball's Antitrust Exemption
PROTECTING AMERICA’S PASTIME: THE NECESSITY OF MAJOR LEAGUE BASEBALL’S ANTITRUST EXEMPTION FOR THE SURVIVAL OF MINOR LEAGUE BASEBALL BRADLEY V. MURPHY* INTRODUCTION “How can you not be romantic about baseball?”1 Imagine a warm summer evening in Rome, Georgia. This city of just under 36,000 residents2 is home to the Rome Braves, the Class-A affiliate of the Atlanta Braves.3 State Mutual Stadium is filled to capacity as the local residents pack the stands to cheer on their hometown Braves.4 The smell of peanuts, popcorn, and hotdogs emanates throughout the stadium. A beer vendor climbs up and down the stadium steps hollering, “Ice cold beer!” Between innings, children are brought out on the field to partake in on-field promotions. After the game, these same children line up to run the bases, meet the mascot, and enjoy the postgame firework display. This minor league game brings the people of Rome, Georgia together and provides them with a common identity. Bradley Reynolds, general manager of the Double-A Mobile BayBears, highlighted the importance of minor league baseball when he said, “What keeps fans coming back isn’t baseball. If they want a better baseball game, they can see it on ESPN. This is about affordability, family fun, wholesome entertainment. That’s what makes this business unique and what makes it work.”5 Considered to be “America’s National Pastime,”6 baseball holds a special place in the hearts of many. In “Field of Dreams,” arguably the most famous baseball movie of all- time, Terence Mann, an author played by James Earl Jones, discussed the importance of baseball to many Americans: * J.D. -

A Compensating Differential Approach to Valuing the Social Benefit of Inorm League Baseball Nola Agha University of San Francisco, [email protected]
The University of San Francisco USF Scholarship: a digital repository @ Gleeson Library | Geschke Center Sport Management College of Arts and Sciences 1-2015 A Compensating Differential Approach to Valuing the Social Benefit of inorM League Baseball Nola Agha University of San Francisco, [email protected] Dennis Coates University of Maryland - Baltimore County Follow this and additional works at: http://repository.usfca.edu/sm Part of the Sports Management Commons Recommended Citation Agha, N. & Coates, D. (2015). A compensating differential approach to valuing the social benefit of inorM League Baseball. Contemporary Economic Policy, 33(2), 285-299. DOI: 10.1111/coep.12080 This Article is brought to you for free and open access by the College of Arts and Sciences at USF Scholarship: a digital repository @ Gleeson Library | Geschke Center. It has been accepted for inclusion in Sport Management by an authorized administrator of USF Scholarship: a digital repository @ Gleeson Library | Geschke Center. For more information, please contact [email protected]. A COMPENSATING DIFFERENTIAL APPROACH TO VALUING THE SOCIAL BENEFIT OF MINOR LEAGUE BASEBALL Abstract This research utilizes a compensating differential framework to measure the social benefits of minor league baseball teams. Consistent with findings at the major league level, individual housing observations from 138 metropolitan areas between 1993 and 2005 show that affiliated teams are associated with a significant 6 to 8% increase in rents in mid-sized markets ranging from 0.4 to 1.4 million people. On the other hand, independent teams and stadiums are associated with insignificant effects on rents. The positive effect of affiliated minor league teams suggests they are a valuable urban amenity that can contribute to local quality of life. -

An Analysis of the Models of Public Relations Most Commonly Used by Professional Minor League Baseball Franchises
Rowan University Rowan Digital Works Theses and Dissertations 9-11-2006 An analysis of the models of public relations most commonly used by professional minor league baseball franchises Pasquale J. Rose Jr. Rowan University Follow this and additional works at: https://rdw.rowan.edu/etd Part of the Public Relations and Advertising Commons Recommended Citation Rose, Pasquale J. Jr., "An analysis of the models of public relations most commonly used by professional minor league baseball franchises" (2006). Theses and Dissertations. 929. https://rdw.rowan.edu/etd/929 This Thesis is brought to you for free and open access by Rowan Digital Works. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of Rowan Digital Works. For more information, please contact [email protected]. AN ANALYSIS OF THE MODELS OF PUBLIC RELATIONS MOST COMMONLY USED BY PROFESSIONAL MINOR LEAGUE BASEBALL FRANCHISES by Pasquale J. Rose Jr. A Thesis Submitted in partial fulfillment of the requirements of the Master of Arts Degree of The Graduate School at Rowan University June 30, 2006 Approved by dvisor Date Approved ~ © 2006 Pasquale J. Rose Jr. ABSTRACT Pasquale J. Rose Jr. An Analysis of the Models of Public Relations Most Commonly Used By Professional Minor League Baseball Franchises 2005/06 Advisor: Joseph Basso, J.D., Ph.D., APR Public Relations Graduate Program This study examines the public relations practices of professional minor league baseball franchises by determining which of Grunig's four models of public relations are most commonly used by these organizations. With these findings, the study then evaluates the effectiveness of the models with respect to individual differences among the organizations and overall limitations encountered in the field.