LNAI 7250, Pp
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Namibia & the Okavango
Pel’s Fishing Owl - a pair was found on a wooded island south of Shakawe (Jan-Ake Alvarsson) NAMIBIA & THE OKAVANGO 21 SEPTEMBER – 8 OCTOBER 2017 LEADER: STEVE BRAINE For most of the country the previous three years drought had been broken and although too early for the mi- grants we did however do very well with birding generally. We searched and found all the near endemics as well as the endemic Dune Lark. Besides these we also had a new write-in for the trip! In the floodplains after observing a wonderful Pel’s Fishing Owl we travelled down a side channel of the Okavango River to look for Pygmy Geese, we were lucky and came across several pairs before reaching a dried-out floodplain. Four birds flew out of the reedbeds and looked rather different to the normal weavers of which there were many, a closer look at the two remaining birds revealed a beautiful pair of Cuckoo Finches. These we all enjoyed for a brief period before they followed the other birds which had now disappeared into the reedbeds. Very strong winds on three of the birding days made birding a huge challenge to say the least after not finding the rare and difficult Herero Chat we had to make alternate arrangements at another locality later in the trip. The entire tour from the Hosea Kutako International Airport outside the capital Windhoek and returning there nineteen days later delivered 375 species. Out of these, four birds were seen only by the leader, a further three species were heard but not seen. -

50 Common Birds of Jos and Central Nigeria the Year
This poster shows 50 of the most common species of bird found in Jos and the surrounding area, numbered roughly in order from the most common to the least common. It should be noted that populations of individual species can fluctuate from year to year and from place to place. Most of the species shown are regular visitors to urban gardens and can be seen without too much difficulty, although some of them can only be seen for part of 50 Common Birds of Jos and Central Nigeria the year. Hausa names are given, if known, although many species have several Hausa names. 1. Laughing Dove (Streptopelia senegalensis) 2. African Thrush (Turdus pelios) 3. Speckled Mousebird 4. Common Bulbul (Pycnonotus barbatus) 5. Red-cheeked Cordon-bleu 6. Scarlet-chested Sunbird (Chalcomitra 7. Village Weaver (Ploceus cucullatus) 8. Variable Sunbird 9. Yellow-billed Kite (Milvus aegyptius) Hausa: Kurciya Hausa: Tsebebe (Colius striatus) Hausa: Koje (Uraeginthus bengalus) Hausa: Asisita senegalensis) Hausa: Sha Kauci Hausa: Marai / Gado (Cinnyris venustus) Hausa: Shirwa 10. Western Grey Plantain-eater 11. Yellow-crowned Gonolek (Laniarius 12. Northern Black Flycatcher 13. African Paradise Flycatcher* 14. Grey-backed Camaroptera 15. Common Kestrel (Falco tinnunculus) 16. Pied Crow (Corvus albus) 17. Red-eyed Dove (Streptopelia 18. Snowy-crowned Robin-chat (Crinifer piscator) Hausa: Kulkulu barbarus) Hausa: Ɗan dufuwa (Melaenornis edolioides) (Terpsiphone viridis) (Camaroptera brevicaudata) Hausa: Karammata Hausa: Hankaka semitorquata) Hausa: Bolo / Kirkir / Wala (Cossypha niveicapilla) 19. Piapiac (Ptilostomus afer) 20. African Yellow White-eye (Zosterops 21. African Blue Flycatcher 22. Red-billed Firefinch Lagonosticta( 23. Adamawa Turtle Dove 24. Yellow-fronted Tinkerbird 25. -

South Africa Mega Birding III 5Th to 27Th October 2019 (23 Days) Trip Report
South Africa Mega Birding III 5th to 27th October 2019 (23 days) Trip Report The near-endemic Gorgeous Bushshrike by Daniel Keith Danckwerts Tour leader: Daniel Keith Danckwerts Trip Report – RBT South Africa – Mega Birding III 2019 2 Tour Summary South Africa supports the highest number of endemic species of any African country and is therefore of obvious appeal to birders. This South Africa mega tour covered virtually the entire country in little over a month – amounting to an estimated 10 000km – and targeted every single endemic and near-endemic species! We were successful in finding virtually all of the targets and some of our highlights included a pair of mythical Hottentot Buttonquails, the critically endangered Rudd’s Lark, both Cape, and Drakensburg Rockjumpers, Orange-breasted Sunbird, Pink-throated Twinspot, Southern Tchagra, the scarce Knysna Woodpecker, both Northern and Southern Black Korhaans, and Bush Blackcap. We additionally enjoyed better-than-ever sightings of the tricky Barratt’s Warbler, aptly named Gorgeous Bushshrike, Crested Guineafowl, and Eastern Nicator to just name a few. Any trip to South Africa would be incomplete without mammals and our tally of 60 species included such difficult animals as the Aardvark, Aardwolf, Southern African Hedgehog, Bat-eared Fox, Smith’s Red Rock Hare and both Sable and Roan Antelopes. This really was a trip like no other! ____________________________________________________________________________________ Tour in Detail Our first full day of the tour began with a short walk through the gardens of our quaint guesthouse in Johannesburg. Here we enjoyed sightings of the delightful Red-headed Finch, small numbers of Southern Red Bishops including several males that were busy moulting into their summer breeding plumage, the near-endemic Karoo Thrush, Cape White-eye, Grey-headed Gull, Hadada Ibis, Southern Masked Weaver, Speckled Mousebird, African Palm Swift and the Laughing, Ring-necked and Red-eyed Doves. -
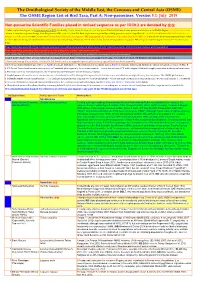
ORL 5.1 Non-Passerines Final Draft01a.Xlsx
The Ornithological Society of the Middle East, the Caucasus and Central Asia (OSME) The OSME Region List of Bird Taxa, Part A: Non-passerines. Version 5.1: July 2019 Non-passerine Scientific Families placed in revised sequence as per IOC9.2 are denoted by ֍֍ A fuller explanation is given in Explanation of the ORL, but briefly, Bright green shading of a row (eg Syrian Ostrich) indicates former presence of a taxon in the OSME Region. Light gold shading in column A indicates sequence change from the previous ORL issue. For taxa that have unproven and probably unlikely presence, see the Hypothetical List. Red font indicates added information since the previous ORL version or the Conservation Threat Status (Critically Endangered = CE, Endangered = E, Vulnerable = V and Data Deficient = DD only). Not all synonyms have been examined. Serial numbers (SN) are merely an administrative convenience and may change. Please do not cite them in any formal correspondence or papers. NB: Compass cardinals (eg N = north, SE = southeast) are used. Rows shaded thus and with yellow text denote summaries of problem taxon groups in which some closely-related taxa may be of indeterminate status or are being studied. Rows shaded thus and with yellow text indicate recent or data-driven major conservation concerns. Rows shaded thus and with white text contain additional explanatory information on problem taxon groups as and when necessary. English names shaded thus are taxa on BirdLife Tracking Database, http://seabirdtracking.org/mapper/index.php. Nos tracked are small. NB BirdLife still lump many seabird taxa. A broad dark orange line, as below, indicates the last taxon in a new or suggested species split, or where sspp are best considered separately. -

A Plant Ecological Study and Management Plan for Mogale's Gate Biodiversity Centre, Gauteng
A PLANT ECOLOGICAL STUDY AND MANAGEMENT PLAN FOR MOGALE’S GATE BIODIVERSITY CENTRE, GAUTENG By Alistair Sean Tuckett submitted in accordance with the requirements for the degree of MASTER OF SCIENCE in the subject ENVIRONMENTAL MANAGEMENT at the UNIVERSITY OF SOUTH AFRICA SUPERVISOR: PROF. L.R. BROWN DECEMBER 2013 “Like winds and sunsets, wild things were taken for granted until progress began to do away with them. Now we face the question whether a still higher 'standard of living' is worth its cost in things natural, wild and free. For us of the minority, the opportunity to see geese is more important that television.” Aldo Leopold 2 Abstract The Mogale’s Gate Biodiversity Centre is a 3 060 ha reserve located within the Gauteng province. The area comprises grassland with woodland patches in valleys and lower-lying areas. To develop a scientifically based management plan a detailed vegetation study was undertaken to identify and describe the different ecosystems present. From a TWINSPAN classification twelve plant communities, which can be grouped into nine major communities, were identified. A classification and description of the plant communities, as well as, a management plan are presented. The area comprises 80% grassland and 20% woodland with 109 different plant families. The centre has a grazing capacity of 5.7 ha/LSU with a moderate to good veld condition. From the results of this study it is clear that the area makes a significant contribution towards carbon storage with a total of 0.520 tC/ha/yr stored in all the plant communities. KEYWORDS Mogale’s Gate Biodiversity Centre, Braun-Blanquet, TWINSPAN, JUICE, GRAZE, floristic composition, carbon storage 3 Declaration I, Alistair Sean Tuckett, declare that “A PLANT ECOLOGICAL STUDY AND MANAGEMENT PLAN FOR MOGALE’S GATE BIODIVERSITY CENTRE, GAUTENG” is my own work and that all sources that I have used or quoted have been indicated and acknowledged by means of complete references. -

Project Name
SYRAH RESOURCES GRAPHITE PROJECT, CABO DELGADO, MOZAMBIQUE TERRESTRIAL FAUNAL IMPACT ASSESSMENT Prepared by: Prepared for: Syrah Resources Limited Coastal and Environmental Services Mozambique, Limitada 356 Collins Street Rua da Frente de Libertação de Melbourne Moçambique, Nº 324 3000 Maputo- Moçambique Australia Tel: (+258) 21 243500 • Fax: (+258) 21 243550 Website: www.cesnet.co.za December 2013 Syrah Final Faunal Impact Assessment – December 2013 AUTHOR Bill Branch, Terrestrial Vertebrate Faunal Consultant Bill Branch obtained B.Sc. and Ph.D. degrees at Southampton University, UK. He was employed for 31 years as the herpetologist at the Port Elizabeth Museum, and now retired holds the honorary post of Curator Emeritus. He has published over 260 scientific articles, as well as numerous popular articles and books. The latter include the Red Data Book for endangered South African reptiles and amphibians (1988), and co-editing its most recent upgrade – the Atlas and Red Data Book of the Reptiles of South Africa, Lesotho and Swaziland (2013). He has also published guides to the reptiles of both Southern and Eastern Africa. He has chaired the IUCN SSC African Reptile Group. He has served as an Honorary Research Professor at the University of Witwatersrand (Johannesburg), and has recently been appointed as a Research Associate at the Nelson Mandela Metropolitan University, Port Elizabeth. His research concentrates on the taxonomy, biogeography and conservation of African reptiles, and he has described over 30 new species and many other higher taxa. He has extensive field work experience, having worked in over 16 African countries, including Gabon, Ivory Coast, DRC, Zambia, Mozambique, Malawi, Madagascar, Namibia, Angola and Tanzania. -

Consequences of Female Nest Confinement in Yellow Billed Hornbills
Conflict & Communication: Consequences Of Female Nest Confinement In Yellow Billed Hornbills Michael Joseph Finnie This dissertation is submitted for the degree of Doctor of Philosophy Clare College September 2012 Michael Joseph Finnie i Preface This dissertation is my own work and contains nothing which is the outcome of work done in collaboration with others, except as specified in the text and acknowledgements. The total length of the text does not exceed 60,000 words, including the bibliography and appendices. No part of this dissertation has been submitted to any other university in application for a higher degree. ii Conflict & Communication: Consequences Of Female Nest Confinement In Yellow-Billed Hornbills Summary The most striking feature of hornbills (Bucerotiformes) is their unusual nesting behaviour. Before laying, a female hornbill enters the nest in a tree cavity. Uniquely among birds, she then seals the nest entrance using her faeces and locally available materials, leaving a narrow gap only 1 cm wide. Through this tiny slit, the female is totally dependent on her mate for between 40 days in the smallest hornbills and up to 130 days in the largest. Once walled in the nest, the female will lay her eggs and shed all of her wing and tail feathers. The male then becomes completely responsible for provisioning his mate and a few weeks later, the chicks. When her feathers have regrown, the female breaks out of the nest, often before the chicks are fully grown. The chicks then reseal the entrance until they too are ready to fledge. This thesis describes attempts to better understand the nesting behaviour of hornbills. -

Namibia Birding and Nature Tour September 13-25, 2014 Tour Species List
P.O. Box 16545 Portal, AZ. 85632 PH: (866) 900-1146 www.caligo.com [email protected] [email protected] www.naturalistjourneys.com Naturalist Journeys: Namibia Birding and Nature Tour September 13-25, 2014 Tour Species List Dalton Gibbs of Birding Africa and Peg Abbott of Naturalist Journeys, with five participants: Andrea, Alex, Ty, Mimi, and Penny BIRDS Common Ostrich – Seen regularly in the first days of the trip in open terrain, strutting through just amazing landscapes with colorful escarpments amid seas of arid grassland. Numerous at Etosha, we could view their dominance behaviors and also some courting display, some of the males were starting to get very red necks and legs as they came into prime condition. Helmeted Guineafowl – Widespread and regularly seen throughout the journeys. The most tame were at Weltevrede where they posed on the gate, strutted about the farm and serenaded us at the end of each day. They came into the waterholes of Etosha in large groups, 20-50 at a time, vocal and jumpy, always alert. One by the roadside on the last day made this an everyday species for the trip. Red-billed Spurfowl – first seen in a wash as we approached Remhoogte Pass, coming off the escarpment onto the coastal plain on the first day from Windhoek. Widespread – seen on seven days of the trip, in all but our most arid locations. Saw some on the Dik Dik Drive of Etosha. And at the Waterberg they were abundant, at dawn their calls were deafening! Swainson’s Spurfowl – recognized by different calling, Peg spotted a family group as we entered the fort area of Namutoni in Etosha, active at the road margin. -

Biodiversity
Annual Camp BIODIVERSITY Name:___________________________________________ 1 2 MY ARTWORK 3 Welcome to the Children in the Wilderness E c o - C l u b C a m p We want you to have fun, b u t there are some rules you need to follow to make sure that you stay safe . Remember there are lots of wild animals around so take care and be aware of your surroundings. 4 I DREAM… I WISH… One thing I would like to be really good at is: When I grow up I want to be: My favourite place is: My favourite subject at school is: 5 RESPECT Outside everyone is different Inside we’re just the same. Everyone has feelings. The way that you treat others Is the way that they’ll treat you. So, respect each other’s differences And they’ll respect yours too. The planet is also a living thing And this too needs respect It is our only home! Respect is a way of life 6 LEADERSHIP AND VALUES What makes a good leader? A good leader listens A good leader makes decisions A good leader can admit mistakes A good leader takes responsibility A good leader remains calm under pressure A good leader inspires others to follow A good leader is willing to do the right thing, even if it makes him/her unpopular. What are Values? Values are the beliefs, feelings and skills that guide a good leader. Here are a few important leadership values: Awareness – knowing and understanding yourself, other people and the environment. Creativity – seeing and coming up with solutions, ideas and plans. -

EAZA Best Practice Guidelines for Turacos (Musophagidae)
EAZA BEST PRACTICE GUIDELINES EAZA Toucan & Turaco TAG TURACOS Musophagidae 1st Edition Compiled by Louise Peat 2017 1 | P a g e Front cover; Lady Ross’s chick. Photograph copyright of Eric Isselée-Life on White, taken at Mulhouse zoo. http://www.lifeonwhite.com/ http://www.zoo-mulhouse.com/ Author: Louise Peat. Cotswold Wildlife Park Email: [email protected] Name of TAG: Toucan & Turaco TAG TAG Chair: Laura Gardner E-mail: [email protected] 2 | P a g e EAZA Best Practice Guidelines disclaimer Copyright 2017 by EAZA Executive Office, Amsterdam. All rights reserved. No part of this publication may be reproduced in hard copy, machine-readable or other forms without advance written permission from the European Association of Zoos and Aquaria (EAZA). Members of the European Association of Zoos and Aquaria (EAZA) may copy this information for their own use as needed. The information contained in these EAZA Best Practice Guidelines has been obtained from numerous sources believed to be reliable. EAZA and the EAZA Toucan & Turaco TAG make a diligent effort to provide a complete and accurate representation of the data in its reports, publications, and services. However, EAZA does not guarantee the accuracy, adequacy, or completeness of any information. EAZA disclaims all liability for errors or omissions that may exist and shall not be liable for any incidental, consequential, or other damages (whether resulting from negligence or otherwise) including, without limitation, exemplary damages or lost profits arising out of or in connection with the use of this publication. Because the technical information provided in the EAZA Best Practice Guidelines can easily be misread or misinterpreted unless properly analysed, EAZA strongly recommends that users of this information consult with the editors in all matters related to data analysis and interpretation. -

Mammals, Birds, Herps
Zambezi Basin Wetlands Volume II : Chapters 3 - 6 - Contents i Back to links page CONTENTS VOLUME II Technical Reviews Page CHAPTER 3 : REDUNCINE ANTELOPE ........................ 145 3.1 Introduction ................................................................. 145 3.2 Phylogenetic origins and palaeontological background 146 3.3 Social organisation and behaviour .............................. 150 3.4 Population status and historical declines ................... 151 3.5 Taxonomy and status of Reduncine populations ......... 159 3.6 What are the species of Reduncine antelopes? ............ 168 3.7 Evolution of Reduncine antelopes in the Zambezi Basin ....................................................................... 177 3.8 Conservation ................................................................ 190 3.9 Conclusions and recommendations ............................. 192 3.10 References .................................................................... 194 TABLE 3.4 : Checklist of wetland antelopes occurring in the principal Zambezi Basin wetlands .................. 181 CHAPTER 4 : SMALL MAMMALS ................................. 201 4.1 Introduction ..................................................... .......... 201 4.2 Barotseland small mammals survey ........................... 201 4.3 Zambezi Delta small mammal survey ....................... 204 4.4 References .................................................................. 210 CHAPTER 5 : WETLAND BIRDS ...................................... 213 5.1 Introduction .................................................................. -

Namibia & Botswana
Namibia & Botswana Custom tour 31st July – 16th August, 2010 Tour leaders: Josh Engel & Charley Hesse Report by Charley Hesse. Photos by Josh Engel & Charley Hesse. This trip produced highlights too numerous to list. We saw virtually all of the specialties we sought, including escarpment specialties like Rockrunner, White-tailed Shrike, Hartlaub‟s Francolin, Herero Chat and Violet Wood-hoopoe and desert specialties like Dune and Gray‟s Larks and Rueppell‟s Korhaan. We cleaned up on Kalahari specialties, and added bonuses like Bare-cheeked and Black-faced Babblers, while also virtually cleaning up on swamp specialties, like Pel‟s Fishing-Owl and Rufous-bellied Heron and Slaty Egret. Of course, with over 40 species seen, mammals provided many memorable experiences as well, including a lioness catching a warthog at one of Etosha‟s waterholes, only to have it stolen away by a male. Elsewhere, we saw a herd of Hartmann‟s Mountain Zebras in the rocky highlands Bat-eared Foxes in the flat Namib desert on the way to the coast; otters feeding in front of our lodge in Botswana; a herd of Sable Antelope racing in front of the car in Mahango Game Reserve. This trip is also among the best for non- animal highlights, and we stayed at varied and wonderful lodges, eating delicious local food and meeting many interesting people along the way. Tropical Birding www.tropicalbirding.com 1 The rarely seen arboreal Acacia Rat (Thallomys) gnaws on the bark of Acacia trees (Charley Hesse). 31st July After meeting our group at the airport, we drove into Nambia‟s capital, Windhoek, seeing several interesting birds and mammals along the way.