Interactive Programming by Example
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

To What Extent Is Programming Impacting on Teacher's Behavioural
To what extent is programming impacting on teacher’s behavioural attitude in primary schools? A dissertation submitted in partial fulfilment of the requirements for the degree of Bachelor of Science (Honours) in Computing by Adrian Tomasz Grzymala Department of Computing & Information Systems Cardiff School of Management Cardiff Metropolitan University April 2016 i Declaration I hereby declare that this dissertation entitled “To what extent is programming impacting on teacher’s behavioural attitude in primary schools?” is entirely my own work, and it has never been submitted nor is it currently being submitted for any other degree. Candidate: Adrian Tomasz Grzymala Signature: Date: Supervisor: Dr. Ana Calderon Signature: Date: ii 1 ABSTRACT “Computers are now part of everyday life” (Berry, 2013). Computer Science is increasingly becoming a part of our lives that has a great impact on most businesses and also education. Computer programming outlines the importance of ‘Computational Thinking’ that is being used in every aspect of our day-to-day living. This dissertation project strive to define the evolutionary change that took place in September 2014. Computing has been introduced to the curriculum across primary schools in UK. The aim of this research paper is to signify the behavioural aspects of teachers teaching computing as well as the changes that occurred in relation to teaching the particular subject. In regards to the research methods, the research project involves primary and secondary data. Through the primary research, Semi-Structured interviews has been constructed to support the qualitative approach of obtaining data. Additionally, there are 3 teachers from Glan Usk School that will provide this research with valuable data regarding the issues they face when teaching programming. -

KODU for KIDS: the Official Guide to Creating Your Own Video Games
for Kids James Floyd Kelly The Official Guide to Creating Your Own Video Games Kodu for Kids Editor-in-Chief Greg Wiegand Copyright © 2013 by Pearson Education All rights reserved. No part of this book shall be reproduced, stored Acquisitions Editor in a retrieval system, or transmitted by any means, electronic, Laura Norman mechanical, photocopying, recording, or otherwise, without written permission from the publisher. No patent liability is assumed with Managing Editor respect to the use of the information contained herein. Although Kristy Hart every precaution has been taken in the preparation of this book, the publisher and author assume no responsibility for errors or Senior Project Editor omissions. Nor is any liability assumed for damages resulting from Jovana Shirley the use of the information contained herein. ISBN-13: 978-0-7897-5076-1 Copy Editor ISBN-10: 0-7897-5076-7 Seth Kerney Library of Congress Control Number: 2013936931 Indexer Printed in the United States of America Erika Millen First Printing: April 2013 Proofreader Trademarks Dan Knott All terms mentioned in this book that are known to be trademarks Technical Editors or service marks have been appropriately capitalized. Que Kodu Game Lab Team Publishing cannot attest to the accuracy of this information. Use of a term in this book should not be regarded as affecting the validity Editorial Assistant of any trademark or service mark. Cindy Teeters Warning and Disclaimer Cover Designer Every effort has been made to make this book as complete and Mark Shirar as accurate as possible, but no warranty or fitness is implied. Compositor The information provided is on an “as is” basis. -

Chapter One - Introduction
Understanding learning within a commercial video game: A case study Allan Fowler B.Bus, MBA, M.Ed. a thesis submitted to the faculty of design and creative technologies AUT University in partial fulfilment of the requirements for the degree of doctor of philosophy School of Computing and Mathematical Sciences Auckland, New Zealand 2014 i DECLARATION I hereby declare that this submission is my own work and that, to the best of my knowledge and belief, it contains no material previously published or written by another person nor material which to a substantial extent has been accepted for the qualification of any other degree or diploma of a University or other institution of higher learning, except where due acknowledgement is made in the acknowledgements. ........................... ii ACKNOWLEDGMENTS This thesis has been undertaken at the Faculty of Design and Creative Technologies of AUT University in Auckland, New Zealand. I would like to take this opportunity to thank all the people who have given me invaluable feedback and support throughout the development, research, and completion of the research project and the production of this thesis. I received considerable support from many colleagues, peers, and leading academics at the various conferences I have been fortunate enough to attend. Thank you. I apologise if I fail to mention all the people who helped me, but the list would fill several pages. First and foremost, I would like to thank my supervisor, Dr. Brian Cusack for your support, feedback, and guidance over the last five years. Without your support, I am very sure this research would not have been possible. -

Building in the Sand: Levelling Up
Leveling Up Teaching and Learning Through Video Game Construction by Kandise Michelle Salerno A thesis submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy Elementary Education University of Alberta © Kandise Michelle Salerno, 2016 Abstract Video game construction plays an important role for students and teachers. The experience of constructing a video game aligns with students’ out-of-school experiences while connecting with the in-school experience of learning content. This qualitative study examined 4 upper elementary teachers, 11 upper elementary students, and 1 principal regarding how they experienced video game construction in the classroom. The following questions guided the study: (1) What pedagogical approaches may upper elementary content-area teachers use to integrate game construction into teaching and learning? (2) How may upper elementary content- area teachers experience student-based game construction with their students? (3) How may students experience video game construction in a content-area classroom? Using constructionism as the theoretical framework, this study sought to understand the kinds of experiences both teachers and students encountered when constructing video games in the classroom, and the externalized expectations that derived from collaborating with and through the technology and with others. The data collection tools I used were direct observations, interviews with the students, teachers, and principal, and artifacts. Audio recordings of the interviews were transcribed, the transcriptions and field notes of the students’ and teachers’ artifacts were connected with the interviews, and themes were identified. For the teachers the themes that were constructed include teacher pedagogy, collaboration, planning, writing and gaming, time, and assessment. -
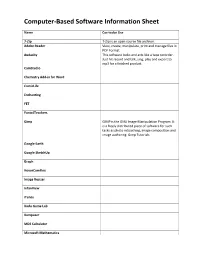
Computer-Based Software Information Sheet
Computer-Based Software Information Sheet Name Curricular Use 7-Zip 7-Zip is an open source file archiver. Adobe Reader View, create, manipulate, print and manage files in PDF Format Audacity This software looks and acts like a tape recorder. Just hit record and talk, sing, play and export to mp3 for a finished product. CamStudio Chemistry Add-in for Word ComicLife Enchanting FET Fonts4Teachers Gimp GIMP is the GNU Image Manipulation Program. It is a freely distributed piece of software for such tasks as photo retouching, image composition and image authoring. Gimp Tutorials Google Earth Google SketchUp Graph HoverCamFlex Image Resizer InfanView iTunes Kodu Game Lab Komposer MDS Calculator Microsoft Mathematics Microsoft Office Mp4Cam2Avi This software is to convert Mp4 video files from a camera to an Avi video file. MuseScore Paint.NET Paint.NET is free image editing and photo manipulation software. It features an intuitive and innovative user interface with support for layers, unlimited undo, special effects, and a wide variety of useful and powerful tools. Paint.NET Tutorials. Photo Story Microsoft Photo Story is a free application that allows users to create a visual story (show and tell presentation) from their digital photos. Photosynth Pivot Stickfigure Animator Pivot makes it easy to create stick-figure animations. You can build your own stick figures and load your own backgrounds. The animations can be saved as animated gifs to be used on web pages. Scratch Songsmith SMART Education Software (Notebook) SMART Ideas StoryBoardPC VirtualDub Windows Movie Maker WinScp Zoomit . -
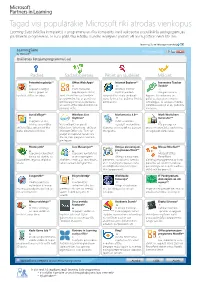
Learning Suite
Tagad visi populārākie Microsoft rīki atrodas vienkopus Learning Suite (Mācību komplekts) ir programmu un rīku komplekts, kurā apkopotas populārākās pedagogiem jau pazīstamās programmas, ar kuru palīdzību mācību stundas iespējams padarīt vēl aizraujošākas nekā līdz šim. Learning Suite lietotāja instrukcija LearningSuite Par Learning Suite by Microsoft® Izvēlieties lietojumprogrammu(-as) Radiet Sadarbojieties Pētiet un studējiet Māciet Fotoattēlu galerija** Offi ce Web Apps* Internet Explorer** Innovative Teacher Toolkit* Iespējams rediģēt, Ir ērts tiešsaistes Windows Internet kārtot, grupēt un papildinājums Word, Explorer piedāvā Integrēts resursu koplietot attēlus un video. Excel, PowerPoint un OneNote racionalizētu izskatu un daudz kopums, kas iedvesmo un programmām, kas ar piemērotu jaunu funkciju, kas paātrina tīmekļa palīdz pedagogiem izmantot pārlūkprogrammu ļauj darboties pārlūkošanu. tehnoloģijas, lai uzlabotu mācību ar saviem Offi ce dokumentiem no rezultātus saskaņā ar 21. gadsimta jebkuras vietas. iemaņām. AutoCollage** Windows Live Mathematics 4.0** Math Worksheet SkyDrive* Generator** Iespējams veidot Palīdz uzskatāmi lieliskas savu mīļāko Vieta mākonī, kur glabāt vizualizēt matemātikas Pēc parauga var attēlu kolāžas, izmantojot tikai tūkstošiem dokumentu, attēlu un jēdzienus un ieraudzīt tos pavisam izveidot matemātikas uzdevumus dažus datorpeles klikšķus. Microsoft Offi ce failu. Tiem var citā gaismā. un sagatavot darba lapas. piekļūt un koplietot no jebkura datora, kam pieejams interneta pieslēgums. Photosynth* Live Messenger** Ķīmijas pievienojum- Mouse Mischief** programma Word** Iespējams rekonstruēt Iespējams kontaktēties Microsoft Offi ce ainavu vai objektu no ar sev nozīmīgiem Atvieglo ķīmijas datu, PowerPoint fotoattēliem, iegūstot telpiskus cilvēkiem, izmantojot savu datoru, piemēram, nosaukumu, formulu pievienojumprogramma, ar kuras attēlus. tālruni vai pārlūkprogrammu. un 2-D attēlojumu pievienošanu palīdzību var veidot interaktīvas un rediģēšanu Microsoft Offi ce prezentācijas un iesaistīt skolēnus Word programmā. -

Endüstri Mühendisli˘Gi Kongresi 5-7 Temmuz 2021 B˙ILD˙IR˙I¨OZETLER˙I
40. Y¨oneylemAra¸stırması- End¨ustriM¨uhendisli˘giKongresi 5-7 Temmuz 2021 BILD_ IR_ I_ OZETLER¨ I_ KONGREMIZ_ I_ DESTEKLEYEN SPONSORLARIMIZA TES¸EKKURLER¨ IM_ IZ_ I_ SUNARIZ ALTIN SPONSORLAR GUM¨ US¸SPONSORLAR¨ I¸cindekiler_ 1 YAEM 2021 4 1.1 Kongre Ba¸skanından...............................................4 1.2 Y¨oneylemAra¸stırmasıDerne˘giBa¸skanından..................................5 1.3 Program.....................................................6 2 Kurullar 9 2.1 Kongre Ba¸skanı.................................................9 2.2 Program Kurulu Ba¸skanları...........................................9 2.3 D¨uzenlemeKurulu................................................9 2.4 Bilim Kurulu...................................................9 3 Davetli Konu¸smacılar 11 4 Paralel Oturumlar 14 4.1 5 Temmuz 2021 Pazartesi 11:15 - 12:45.................................... 14 4.1.1 Ara¸cRotalama 1............................................ 14 4.1.2 Eniyileme Uygulamaları 1....................................... 15 4.1.3 C¸ok Ama¸clıKarar Verme 1...................................... 17 4.1.4 Bulanık Mantık............................................ 18 4.1.5 Veri Analiti˘gi1............................................. 19 4.1.6 Veri Analizi 1............................................. 20 4.1.7 C¸izelgeleme.............................................. 22 4.1.8 Enerji Sistemleri 1........................................... 23 4.1.9 Stok Planlama............................................. 24 4.1.10 Uygulamalı Finans.......................................... -

Subject Knowledge Covering the Transition from Primary to Secondary
Computing Scotland Subject Knowledge covering the transition from Primary to Secondary SUPPORTED BY Foreword In 2017, Education Scotland revised the computing science It’s an exciting time for computing science! We are a subject content within the Broad General Education, with significant coming of age, with great relevance to every one of our pupils. input from Computing At School Scotland (CAS Scotland), We hope very much that you find this QuickStart resource of to reflect the developing worldwide understanding of the value in underpinning your delivery of great experiences for importance of the subject. your pupils. We recognise that there is a large increase in the computing science content to be covered in both primary and early secondary compared to the old Experiences and Outcomes Quintin Cutts (Es & Os) for computing science. In secondary schools, with Chair, Computing At School Scotland our current computing teacher numbers, many teachers from related subjects may be asked to deliver teaching at the lower levels. It is important, then, that materials are available for such teachers to enable them to prepare for these classes. Acknowledgements This QuickStart resource is the first to support early secondary teaching, and it particularly focusses on the Every effort has been made to trace copyright holders and obtain their necessary subject knowledge for teachers. It is not full of permission for the use of copyright materials. The author and publisher will gladly receive information enabling them to rectify any error or omission in teaching activities and pedagogical advice – we will shortly be subsequent editions. extending the primary teacher guide available at http://teachcs. -

Placing Event-Action-Based Visual Programming in the Process of Computer Science Education
Acta Polytechnica Hungarica Vol. 16, No. 2, 2019 Placing Event-Action-based Visual Programming in the Process of Computer Science Education Gábor Csapó University of Debrecen, Faculty of Informatics, Kassai út 26, 4028 Debrecen, Hungary, [email protected] Abstract: Based on research results and experience, students who finish K-12 education lack the necessary computational thinking skills that they would need to continue their studies effectively in the field of computer sciences. Our goal was to examine the currently used methods and programming languages in K-12 education and to find and present an alternative approach. Using visual programming environments in education to develop students’ computational thinking and algorithmic skills is a widespread practice in K-12 education. These environments mostly provide simplified versions of “real” programming languages. In this paper, we present event-action-based visual programming, as an alternative to today’s most frequently used methods, which do not restrict the students’ development ability to simplified and basic applications while retaining the advantages of visual languages. We organized four workshops in which we presented this programming approach to four distinct groups involved in education. The participants were guided to develop a multiplatform mobile application using Construct 2 event-action-based visual programming. At the end of the sessions we collected data in the form of group interviews and questionnaires on the possibilities of including event-action based visual programming in computer science education. Based on the results, the participants found the method suitable for beginner programmers to help them lay the foundations for more complex, text- based programming languages and to develop a positive attitude towards programming. -

Design and Implementation of Robo : an Applied Game for Teaching
Politecnico di Milano Scuola di Ingegneria Industriale e dell’Informazione Corso di Laurea Magistrale in Ingegneria Informatica Dipartimento di Elettronica, Informazione e Bioingegneria Design and implementation of Robo3: an applied game for teaching introductory programming Advisor: Ing. Daniele Loiacono Author: Filippo Agalbato 850481 Academic Year 2016–2017 Abstract This work discusses the design and implementation of Robo3, a web game to teach programming skills, to be used as a supplement during introductory programming courses. The game helps students to visualize and understand the effects of the code they write; at the same time it allows the instructor to easily author levels on the topic of their choice and to gather data on players’ performance, which can be visualized in aggregate form by a companion dashboard environment. Sommario Questa tesi discute la progettazione e l’implementazione di Robo3, un gioco web volto a insegnare a programmare, il cui scopo è di essere usato come strumento di supporto nei corsi di introduzione alla programmazione. Il gioco permette agli studenti di vedere e capire gli effetti dell’esecuzione del codice da loro scritto; allo stesso tempo, permette a chi tiene il corso di creare facilmente nuovi livelli sugli argomenti che ritiene utili e raccoglie dati sull’andamento dei giocatori, che possono poi essere esaminati in forma aggregata tramite un ambiente dashboard specializzato creato appositamente. Gli ultimi anni hanno visto una crescita nell’importanza data alle com- petenze informatiche e di programmazione, che sempre più vengono usate da molti nella vita di tutti i giorni. In aggiunta a ciò si è assistito a un incremen- to nell’uso e nell’efficacia di metodi di insegnamento alternativi, come l’uso di giochi applicati all’ambito in questione, in funzione di supporto all’inse- gnamento tradizionale. -

Canada Teacher Awar Canada Innovative Teacher Awards 2012 Innovative R Awards
CANADA INNOVATIVE TEACHER AWARDS 2012 Program Overview and Guidelines 1 TABLE OF CONTENTS 1. Introduction …………………………………………………………………………………3 2. Canada Innovative Teacher Awards & World Wide Global Forum Overview……….4 3. Microsoft Software and Tools for Canada Innovative Teacher Awards Projects………………………………………………5 4. Procedures, Guidelines and Timelines…………………………………………………..6 • Section 1: Create Your Learning Project Video/Criteria • Section 2: Submit Video Learning Activity Application Form 5. Partners in Learning Canada Virtual Innovative Educator Forum Overview:……….9 Virtual Competition for Canada Innovative Teacher Awards • Video Learning Activity Selection Process • Steps/Guidelines for Selected Participants 6. APPENDIX ‘A’: Judging Rubric…………………………………………………………10 7. APPENDIX ‘B’: Instructions to Upload VCT/Learning Activity………………………16 8. APPENDIX ‘C’: Video Learning Activity Application Form…………………………..20 2 1. Introduction About Microsoft in Education http://www.microsoft.com/education/ww/about/Pages/index.aspx An educated population is the one natural resource that increases in value as it increases in size. Microsoft’s mission in education is to help every student and educator around the world realize their full potential by helping educators and school leaders connect, collaborate, create, and share so that students can realize their greatest potential. We do this by building capacity, growing learning communities and expanding teaching and learning through our Partners in Learning Program. Microsoft Partners in Learning Vision Microsoft Partners in Learning is a global initiative designed to actively increase access to technology and improve its use in learning. At Microsoft, we are deeply committed to working with governments, communities, schools, and educators to use the power of information technology to deliver technology, services, and programs that provide anytime, anywhere learning for all. -

Projeto E Implementação De Um Sistema De Autoria Para Animações, Simulações E Treinamentos Em Realidade Virtual
UNIVERSIDADE FEDERAL DO PARÁ INSTITUTO DE TECNOLOGIA PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA PROJETO E IMPLEMENTAÇÃO DE UM SISTEMA DE AUTORIA PARA ANIMAÇÕES, SIMULAÇÕES E TREINAMENTOS EM REALIDADE VIRTUAL PEBERTLI NILS ALHO BARATA DM: 17 / 2010 UFPA / ITEC / PPGEE CAMPUS UNIVERSITÁRIO DO GUAMÁ BELÉM – PARÁ – BRASIL SETEMBRO-2010 UNIVERSIDADE FEDERAL DO PARÁ INSTITUTO DE TECNOLOGIA PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA PROJETO E IMPLEMENTAÇÃO DE UM SISTEMA DE AUTORIA PARA ANIMAÇÕES, SIMULAÇÕES E TREINAMENTOS EM REALIDADE VIRTUAL PEBERTLI NILS ALHO BARATA DISSERTAÇÃO SUBMETIDA À BANCA EXAMINADORA APROVADA PELO COLEGIADO DO PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA DO INSTITUTO DE TECNOLOGIA DA UNIVERSIDADE FEDERAL DO PARÁ, COMO REQUISITO PARA A OBTENÇÃO DO GRAU DE MESTRE EM ENGENHARIA ELÉTRICA NA ÁREA DE COMPUTAÇÃO APLICADA. UFPA / ITEC / PPGEE CAMPUS UNIVERSITÁRIO DO GUAMÁ BELÉM – PARÁ – BRASIL SETEMBRO-2010 UNIVERSIDADE FEDERAL DO PARÁ INSTITUTO DE TECNOLOGIA PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA PROJETO E IMPLEMENTAÇÃO DE UM SISTEMA DE AUTORIA PARA ANIMAÇÕES, SIMULAÇÕES E TREINAMENTOS EM REALIDADE VIRTUAL AUTOR: Pebertli Nils Alho Barata DISSERTAÇÃO DE MESTRADO SUBMETIDA À AVALIAÇÃO DA BANCA EXAMINADORA APROVADA PELO COLEGIADO DO PROGRAMA DE PÓS-GRADUAÇÃO EM ENGENHARIA ELÉTRICA DA UNIVERSIDADE FEDERAL DO PARÁ E JULGADA ADEQUADA PARA OBTENÇÃO DO GRAU DE MESTRE EM ENGENHARIA ELÉTRICA NA ÁREA DE COMPUTAÇÃO APLICADA APROVADA EM 03/09/2010 BANCA EXAMINADORA: Prof. Dr. Manoel Ribeiro Filho (ORIENTADOR – UFPA) Prof. Dr. Marcus Vinícius Alves Nunes (MEMBRO – UFPA) Prof. Dr. Marcos Paulo Alves de Sousa (MEMBRO – Museu Paraense Emílio Goeldi) VISTO: Prof. Dr. Marcus Vinícius Alves Nunes (COORDENADOR DO PPGEE/ITEC/UFPA) RESUMO Esta dissertação apresenta o projeto, desenvolvimento e implementação de um software para criação de animações, simulações e treinamentos de processos e instruções técnicas industriais, destacando também a arquitetura utilizada para sua implementação.