The Libx Edition Builder
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

1. the ZK User Interface Markup Language
1. The ZK User Interface Markup Language The ZK User Interface Markup Language (ZUML) is based on XML. Each XML element describes what component to create. XML This section provides the most basic concepts of XML to work with ZK. If you are familiar with XML, you could skip this section. If you want to learn more, there are a lot of resources on Internet, such as http://www.w3schools.com/xml/xml_whatis.asp and http://www.xml.com/pub/a/98/10/guide0.html. XML is a markup language much like HTML but with stricter and cleaner syntax. It has several characteristics worth to notice. Elements Must Be Well-formed First, each element must be closed. They are two ways to close an element as depicted below. They are equivalent. Close by an end tag: <window></window> Close without an end tag: <window/> Second, elements must be properly nested. Correct: <window> <groupbox> Hello World! </groupbox> </window> Wrong: <window> <groupbox> Hello World! </window> </groupbox> Special Character Must Be Replaced XML uses <element-name> to denote an element, so you have to replace special characters. For example, you have to use < to represent the < character. ZK: Developer's Guide Page 1 of 92 Potix Corporation Special Character Replaced With < < > > & & " " ' ' It is interesting to notice that backslash (\) is not a special character, so you don't need to escape it at all. Attribute Values Must Be Specified and Quoted Correct: width="100%" checked="true" Wrong: width=100% checked Comments A comment is used to leave a note or to temporarily edit out a portion of XML code. -

The Libx Libapp Builder
The LibX LibApp Builder Sony Vijay Thesis submitted to the Faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Master of Science in Computer Science and Applications Godmar Back, Chair Eli Tilevich Stephen H. Edwards September 20, 2013 Blacksburg, Virginia Keywords: LibX, Browser Plugin, Digital Library, End-User Programming, LibApp Language Model, LibApp, LibX Feed, AJAX, XML Database c Copyright 2013, Sony Vijay The LibX LibApp Builder Sony Vijay ABSTRACT LibX is a browser extension that provides direct access to library resources. LibX enables users to add additional features to a webpage, such as placing a tutorial video on a digital library homepage. LibX achieves this ability of enhancing web pages through library appli- cations, called LibApps. A LibApp examines a webpage, extracts and processes information of the page, and modifies the web content. It is possible to build an unlimited number of LibApps and enhance web pages in numerous ways. The developers of LibX team can- not build all possible LibApps by themselves. Hence, we decided to create an environment that allows users to create and share LibApps, thereby creating an eco-system of library applications. We developed the LibApp Builder, a cloud-based end-user programming tool that assists users in creating customized library applications with minimal effort. We designed an easy- to-understand meta-design language model with modularized, reusable components. The LibApp language model is designed to hide the complex programming details from the target audiences who are mostly non-technical users, primarily librarians. The LibApp Builder is a web-based editor that allows users to build and test LibApps in an executable environment. -

ZKTM Mobile for Android the Quick Start Guide
ppoottiixx SIMPLY REACH ZKTM Mobile for Android The Quick Start Guide Version 0.8.1 Feburary 2008 Potix Corporation ZK Mobile for Android for Android: Quick Start Guide Page 1 of 14 Potix Corporation Copyright © Potix Corporation. All rights reserved. The material in this document is for information only and is subject to change without notice. While reasonable efforts have been made to assure its accuracy, Potix Corporation assumes no liability resulting from errors or omissions in this document, or from the use of the information contained herein. Potix Corporation may have patents, patent applications, copyright or other intellectual property rights covering the subject matter of this document. The furnishing of this document does not give you any license to these patents, copyrights or other intellectual property. Potix Corporation reserves the right to make changes in the product design without reservation and without notification to its users. The Potix logo and ZK are trademarks of Potix Corporation. All other product names are trademarks, registered trademarks, or trade names of their respective owners. ZK Mobile for Android for Android: Quick Start Guide Page 2 of 14 Potix Corporation Table of Contents Before You Start.............................................................................................................. 4 New to ZK Framework.....................................................................................................4 New to Google Android....................................................................................................4 -

Dictionary Software Based on Ajax Frameworks
Seminar Paper Dictionary Software based on Ajax Frameworks Matthias Kerstner Institute for Information Systems and Computer Media Graz University of Technology Head: Herman Maurer O.Univ.-Prof. Dr.Dr.h.c.mult. Supervisor: Denis Helic Dipl.-Ing. Dr.techn. September 2007 Seminar Paper Abstract Abstract The necessity for dictionaries cannot be disputed. Although there are a vast variety of them they all follow a basic schema a key-value combination. It is interesting to see that many of the well known dictionary producers recently also provide electronic versions of their products, ranging from CDROMs over USB media to online databases. With the event of Ajax, web-based applications can be turned into desktop-like environments. It provides developers with an effective way to build web-applications using existing facilities (browsers, etc.), while still profiting from the latest technology. Seminar Paper Contents Contents Abstract ............................................................................................................3 Contents ...........................................................................................................4 List of Figures...................................................................................................5 1. Introduction ...............................................................................................6 2. Dictionaries ...............................................................................................8 3. Ajax Frameworks ......................................................................................9 -

Comparing Javascript Libraries
www.XenCraft.com Comparing JavaScript Libraries Craig Cummings, Tex Texin October 27, 2015 Abstract Which JavaScript library is best for international deployment? This session presents the results of several years of investigation of features of JavaScript libraries and their suitability for international markets. We will show how the libraries were evaluated and compare the results for ECMA, Dojo, jQuery Globalize, Closure, iLib, ibm-js and intl.js. The results may surprise you and will be useful to anyone designing new international or multilingual JavaScript applications or supporting existing ones. 2 Agenda • Background • Evaluation Criteria • Libraries • Results • Q&A 3 Origins • Project to extend globalization - Complex e-Commerce Software - Multiple subsystems - Different development teams - Different libraries already in use • Should we standardize? Which one? - Reduce maintenance - Increase competence 4 Evaluation Criteria • Support for target and future markets • Number of internationalization features • Quality of internationalization features • Maintained? • Widely used? • Ease of migration from existing libraries • Browser compatibility 5 Internationalization Feature Requirements • Encoding Support • Text Support -Unicode -Case, Accent Mapping -Supplementary Chars -Boundary detection -Bidi algorithm, shaping -Character Properties -Transliteration -Charset detection • Message Formatting -Conversion -IDN/IRI -Resource/properties files -Normalization -Collation -Plurals, Gender, et al 6 Internationalization Feature Requirements -

RIA Mit ZK Boost Your Productivity
RIA mit ZK Boost your productivity Daniel Seiler, AIA 2008, Mainz Agenda Introduction ZK basics ZK component library We build an application ZK advanced concepts Custom component example Integration example, Gmaps Summary Goals of this session Infect you with the ZK virus You are able to explain the position of ZK in the current RIA Landscape You know the main features, concepts and principles of ZK Daniel Seiler, Processwide AG 3 The problem to solve To build rich, interactive, fast and scalable, distributed business applications ... ... we need a framework and technology that ... ... maximizes our productivity by abstracting and hiding much of the complexity ... provides a rich set of prebuilt components and features ... is easy to extend Daniel Seiler, Processwide AG 4 The big picture Local offline Trad. Distributed Rich (Asynchronous update, sorting, drag & drop, ...) Trad. Web- tools applications applications I nternet (Communication with Webserver) (Standalone, not ('Fat client', corba, RMI, (Page reloading, distributed, ...) local installation, ...) Application (User interactions, data storage, ...) simple controls) Office tools Eclipse RCP Runs in an external Runs directly in a runtime environment browser (No plugin, (plugin or standalone) Ajax) Applets (Java) Javascript Framework Flex (flash) library Laszlo (flash) Curl Captain Casa jQuery Echo2 (Swing, JSF) Prototype GWT Script.aculo.us ICE Faces DWR ZK Daniel Seiler, Processwide AG 5 The right tool for your job R ichness + Rich UI Local offline - Local, no central access -

RIA with ZK Boost Your Productivity
RIA with ZK Boost your productivity Daniel Seiler AdNovum Informatik AG Submission Id: 7960 2 AGENDA > Introduction > ZK basics > Lets build an application > Advanced topics > Custom components > Some more examples > ZK and the others > What's coming next? > Summary > Q & A Goals Infect you with the ZK virus You are able to explain the position of ZK in the current RIA Landscape You know the main features, concepts and principles of ZK The problem to solve To build rich, interactive, fast and scalable, distributed business applications ... ... we need a framework and technology that ... ... maximizes our productivity by abstracting and hiding much of the complexity ... provides a rich set of prebuilt components and features ... is easy to extend The big picture Local offline “Fat Client” Rich (Async. update, sorting, drag & drop) Trad. web tools Distributed I nternet (Communication with Webserver) applications (Standalone, not applications (Page reloading, distributed, ...) (Corba, RMI, WS , ...) Application (User interactions, data storage) simple controls) Office tools Eclipse RCP Runs in an external Runs directly in a runtime environment browser (No plugin, Ajax) (plugin or standalone) Java FX Flex (flash) Javascript Frameworks Laszlo (flash) libraries Curl Echo2 Captain Casa jQuery GWT (Swing, JSF) Prototype ICE Faces Script.aculo.us IT Mill vaadin DWR ZK What is ZK? From Wikipedia: http://en.wikipedia.org/wiki/ZK_Framework ZK is an open-source Ajax web application framework, written in Java, that enables creation of rich graphical user interfaces for web applications with no JavaScript and little programming knowledge. The core of ZK consists of an Ajax-based event-driven mechanism, over 123 XUL and 83 XHTML-based components, and a markup language for designing user interfaces. -
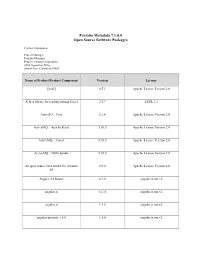
Pentaho Metadata 7.1.0.0 Open Source Software Packages
Pentaho Metadata 7.1.0.0 Open Source Software Packages Contact Information: Project Manager Pentaho Metadata Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Component Version License [ini4j] 0.5.1 Apache License Version 2.0 A Java library for reading/writing Excel 2.5.7 LGPL 2.1 ActiveIO :: Core 3.1.4 Apache License Version 2.0 ActiveMQ :: Apache Karaf 5.10.0 Apache License Version 2.0 ActiveMQ :: Camel 5.10.0 Apache License Version 2.0 ActiveMQ :: OSGi bundle 5.10.0 Apache License Version 2.0 An open source Java toolkit for Amazon 0.9.0 Apache License Version 2.0 S3 Angular UI Router 0.3.0 angular.js.mit.v2 angular.js 1.2.15 angular.js.mit.v2 angular.js 1.5.8 angular.js.mit.v2 angular-animate-1.5.6 1.5.6 angular.js.mit.v2 Name of Product/Product Component Version License angular-route 1.5.6 angular.js.mit.v2 angular-sanitize-1.5.6 1.5.6 angular.js.mit.v2 angular-translate 2.3.0 angular.js.mit.v2 angular-translate-2.12.1 2.12.1 angular.bootstrap.mit.v2 angular-translate-2.12.1 2.12.1 angular.js.mit.v2 AngularUI Bootstrap 0.6.0 angular.bootstrap.mit.v2 AngularUI Bootstrap 1.3.3 angular.bootstrap.mit.v2 Annotation 1.0 1.1.1 Apache License Version 2.0 Annotation 1.1 1.0.1 Apache License Version 2.0 ANTLR 3 Complete 3.5.2 ANTLR License Antlr 3.4 Runtime 3.4 ANTLR License ANTLR, ANother Tool for Language 2.7.7 ANTLR License Recognition AOP Alliance (Java/J2EE AOP standard) 1.0 Public Domain Apache Ant Core 1.9.1 Apache License Version 2.0 Name of Product/Product Component Version License -

The Future of Openurl Linking Adaptation and Expansion
Chapter 4 The Future of OpenURL Linking Adaptation and Expansion Abstract effectiveness, libraries and vendors will approach OpenURL with renewed interest and vigor. Previous chapters in this report have addressed the In this chapter, we present an overview of the emerg- continuing importance of OpenURL linking in librar- ing trends and technologies that may guide the ongo- ies and presented interface-based and data-based ways ing development of OpenURL resolvers as they adapt to to improve local OpenURL link resolver systems. This changes in the research environment and expand to serve chapter explores issues pertinent to the continued and the wider Web. expanded adoption of OpenURL and other linking tech- nologies, with an eye toward incorporating the shift in library collections from ownership to access and our users’ growing desire for instant access to online full text. Adapting to Changes in the Research Environment penURL link resolvers are a staple service of Access versus Ownership ReportsLibrary Technology academic and other libraries. In 2009, approxi- Omately 100,000 SFX menus were presented to Online accessibility of metadata and full text content has EKU users. Of these, approximately 62,000 (62 percent) resulted in a fundamental change in user expectations included full text targets, about 50,000 (80 percent) of and a concomitant adjustment in library collection-build- which were clicked. These statistics reflect the fact that ing principles.1 As users discover globally distributed con- EKU relies heavily on native full text on the EBSCOhost tent and grow to expect instantaneous access, libraries platform to satisfy the majority of user needs. -

Ajax and Web 2.0 Related Frameworks and Toolkits Dennis Chen Director of Product Engineering / Potix Corporation [email protected]
Ajax and Web 2.0 Related Frameworks and Toolkits Dennis Chen Director of Product Engineering / Potix Corporation [email protected] 1 Agenda • Ajax Introduction • Access Server Side (Java) API/Data/Service > jQuery + DWR > GWT > ZK • Summary 2 AJAX INTRODUCTION 3 What is Ajax • Asynchronous JavaScript and XML • Browser asynchronously get data from a server and update page dynamically without refreshing(reloading) the whole page • Web Application Development Techniques > DHTML, CSS (Cascade Style Sheet) > Javascript and HTML DOM > Asynchronous XMLHttpRequest 4 Traditional Web Application vs. Ajax within a browser, there is AJAX engine 5 Ajax Interaction Example Demo 6 Challenge of Providing Ajax • Technique Issue > JavaScript , DHTML and CSS • Cross Browser Issue > IE 6,7,8 , Firefox 2,3 , Safari 3, Opera 9, Google Chrome… • Asynchronous Event and Data • Business Logic and Security • Maintenance 7 Solutions : Ajax Frameworks / Toolkits • Client Side Toolkit > jQuery, Prototype , … • Client Side Framework > GWT ,YUI, Ext-JS, Dojo … • Server Side Toolkit (Java) > DWR… • Server Side Framwork > ZK, ECHO2, ICEface .. 8 JQUERY + DWR 9 What is jQuery • http://jquery.com/ • A JavaScript toolkit that simplifies the interaction between HTML and JavaScript. • Lightweight and Client only • Provides high level function to > Simplify DOM access and alternation > Enable multiple handlers per event > Add effects/animations > Asynchronous interactions with server • Solve browser incompatibilities 10 Powerful Selector / Traversing API • Powerful Selector -

Virginia Libraries Journal
STAFF Coeditors Cy Dillon Ferrum College Virginia P.O. Box 1000 Ferrum, Virginia 24088 (540) 365-4428 [email protected] Libraries C. A. Gardner Hampton Public Library July/August/September, 2007, Vol. 53, No. 3 4207 Victoria Blvd. Hampton, Virginia 23669 (757) 727-1218 COLUMNS (757) 727-1151 (fax) [email protected] Cy Dillon and 3 Openers C. A. Gardner Editorial Board Pat Howe 5 President’s Column Lydia C. Williams Sara B. Bearss, Ed. 35 Virginia Reviews Longwood University Library Farmville, Virginia 23909 (434) 395-2432 [email protected] FEATURES Alex Reczkowski 7 VLA Paraprofessional Forum Ed Lener College Librarian for the Sciences 2007 Conference Virginia Tech University Libraries Kyrille Goldbeck, 19 Telling the Tale: Creating a Successful P.O. Box 90001 Michelle L. Young, and Library In-Service Day Blacksburg, Virginia 24062-9001 Annette Bailey (540) 231-9249 [email protected] Jessica Zellers 23 In Blog Heaven: A Painless New Approach to Readers’ Advisory Karen Dillon Manager, Library Services Andrew Smith 25 The Gift of Gab Carilion Health System Sylvia Rortvedt 27 Text, Image, and Form: P.O. Box 13367 The Altered Book Project Roanoke, Virginia 24033 (540) 981-7258 Otis D. Alexander 29 Fabric Arts Classes at the (540) 981-8666 (fax) Danville Public Library [email protected] Julie Ramsay 31 The Power of Libraries Douglas Perry Director Hampton Public Library Virginia Libraries is a quarterly journal published by the Virginia Library Association whose 4207 Victoria Blvd. purpose is to develop, promote, and improve library and information services and the profes- Hampton, Virginia 23669 sion of librarianship in order to advance literacy and learning and to ensure access to infor (757) 727-1153 (extension 104) mation in the Commonwealth of Virginia. -

ZKTM the Quick Start Guide
ppoottiixx SIMPLY RICH ZKTM The Quick Start Guide Version 3.0.4 March 2008 Potix Corporation ZK: Quick Start Guide Page 1 of 16 Potix Corporation Copyright © Potix Corporation. All rights reserved. The material in this document is for information only and is subject to change without notice. While reasonable efforts have been made to assure its accuracy, Potix Corporation assumes no liability resulting from errors or omissions in this document, or from the use of the information contained herein. Potix Corporation may have patents, patent applications, copyright or other intellectual property rights covering the subject matter of this document. The furnishing of this document does not give you any license to these patents, copyrights or other intellectual property. Potix Corporation reserves the right to make changes in the product design without reservation and without notification to its users. The Potix logo and ZK are trademarks of Potix Corporation. All other product names are trademarks, registered trademarks, or trade names of their respective owners. ZK: Quick Start Guide Page 2 of 16 Potix Corporation Table of Contents Before You Start.............................................................................................................. 4 New to the Servlet Container (aka., Java Web Server)........................................................ 4 New to Java Language.................................................................................................... 4 New to Java Integrated Development Environment (IDE)...................................................