Retrieval Effectiveness of an Ontology-Based Model for Information Selection
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Play Ball in Style
Manager: Scott Servais (9) NUMERICAL ROSTER 2 Tom Murphy C 3 J.P. Crawford INF 4 Shed Long Jr. INF 5 Jake Bauers INF 6 Perry Hill COACH 7 Marco Gonzales LHP 9 Scott Servais MANAGER 10 Jarred Kelenic OF 13 Abraham Toro INF 14 Manny Acta COACH 15 Kyle Seager INF 16 Drew Steckenrider RHP 17 Mitch Haniger OF 18 Yusei Kikuchi LHP 21 Tim Laker COACH 22 Luis Torrens C 23 Ty France INF 25 Dylan Moore INF 27 Matt Andriese RHP 28 Jake Fraley OF 29 Cal Raleigh C 31 Tyler Anderson LHP 32 Pete Woodworth COACH 33 Justus Sheffield LHP 36 Logan Gilbert RHP 37 Paul Sewald RHP 38 Anthony Misiewicz LHP 39 Carson Vitale COACH 40 Wyatt Mills RHP 43 Joe Smith RHP 48 Jared Sandberg COACH 50 Erik Swanson RHP 55 Yohan Ramirez RHP 63 Diego Castillo RHP 66 Fleming Baez COACH 77 Chris Flexen RHP 79 Trent Blank COACH 88 Jarret DeHart COACH 89 Nasusel Cabrera COACH 99 Keynan Middleton RHP SEATTLE MARINERS ROSTER NO. PITCHERS (14) B-T HT. WT. BORN BIRTHPLACE 31 Tyler Anderson L-L 6-2 213 12/30/89 Las Vegas, NV 27 Matt Andriese R-R 6-2 215 08/28/89 Redlands, CA 63 Diego Castillo (IL) R-R 6-3 250 01/18/94 Cabrera, DR 77 Chris Flexen R-R 6-3 230 07/01/94 Newark, CA PLAY BALL IN STYLE. 36 Logan Gilbert R-R 6-6 225 05/05/97 Apopka, FL MARINERS SUITES PROVIDE THE PERFECT 7 Marco Gonzales L-L 6-1 199 02/16/92 Fort Collins, CO 18 Yusei Kikuchi L-L 6-0 200 06/17/91 Morioka, Japan SETTING FOR YOUR NEXT EVENT. -

0908 Giants.Pdf
Manager: Scott Servais (29) NUMERICAL ROSTER 1 Kyle Lewis OF 3 J.P. Crawford INF 4 Shed Long Jr. INF 6 Yoshihisa Hirano RHP 7 Marco Gonzales LHP 9 Dee Strange-Gordon INF/OF 12 Evan White INF 13 Perry Hill COACH 14 Manny Acta COACH 15 Kyle Seager INF 18 Yusei Kikuchi LHP 20 Phillip Ervin OF 21 Tim Laker COACH 22 Luis Torrens C 23 Ty France INF 25 Dylan Moore INF/OF 26 José Marmolejos INF 27 Joe Thurston COACH 28 Sam Haggerty INF 29 Scott Servais MANAGER 32 Pete Woodworth COACH 33 Justus Sheffield LHP 35 Justin Dunn RHP 37 Casey Sadler RHP 38 Anthony Misiewicz LHP 39 Carson Vitale COACH 40 Brian DeLunas COACH 44 Jarret DeHart COACH 48 Jared Sandberg COACH 49 Kendall Graveman RHP 50 Erik Swanson RHP 52 Nick Margevicius LHP 54 Joseph Odom C 55 Yohan Ramirez RHP 59 Joey Gerber RHP 60 Seth Frankoff RHP 62 Brady Lail RHP 65 Brandon Brennan RHP 66 Fleming Báez COACH 73 Walker Lockett RHP 74 Ljay Newsome RHP 81 Aaron Fletcher LHP 89 Nasusel Cabrera COACH SEATTLE MARINERS ROSTER NO. PITCHERS (16) B-T HT. WT. BORN BIRTHPLACE 65 BRENNAN, Brandon (IL) R-R 6-4 220 07/26/91 Mission Viejo, CA 35 DUNN, Justin R-R 6-2 185 09/22/95 Freeport, NY 81 FLETCHER, Aaron L-L 6-0 220 02/26/96 Geneseo, IL 60 FRANKOFF, Seth R-R 6-5 215 08/27/88 Raleigh, NC 59 GERBER, Joey R-R 6-4 215 05/03/97 Maple Grove, MN 7 GONZALES, Marco L-L 6-1 199 02/16/92 Fort Collins, CO 49 GRAVEMAN, Kendall R-R 6-2 200 12/21/90 Alexander City, AL 6 HIRANO, Yoshihisa R-R 6-1 185 03/08/84 Kyoto, Japan 18 KIKUCHI, Yusei L-L 6-0 200 06/17/91 Iwate, Japan 62 LAIL, Brady R-R 6-2 200 08/09/93 South Jordan, UT 73 LOCKETT, Walker R-R 6-5 225 05/03/94 Jacksonville, FL 52 MARGEVICIUS, Nick L-L 6-5 220 06/18/96 Cleveland, OH 38 MISIEWICZ, Anthony R-L 6-1 200 11/01/94 Detroit, MI 74 NEWSOME, Ljay R-R 5-11 210 11/08/96 La Plata, MD 55 RAMIREZ, Yohan R-R 6-4 190 05/06/95 Villa Mella, DR 37 SADLER, Casey R-R 6-3 205 07/13/90 Stillwater, OK 33 SHEFFIELD, Justus L-L 6-0 200 05/13/96 Tullahoma, TN 50 SWANSON, Erik (IL) R-R 6-3 220 09/04/93 Fargo, ND NO. -

Full Schedule
SCHEDULE OF EVENTS WEEK #1 SUBJECT TO CHANGE 10:30-11am Preview Show 10-11am Coffee ‘Servais’ Q&A 10-11am Coffee ‘Servais’ Q&A Join Aaron Goldsmith to hear what the pres. by Caffe Vita pres. by Caffe Vita Mariners Virtual Baseball Bash is all about! Grab a cup of coffee and join the Grab a cup of coffee and join the Mariners Skipper for Q&A. Mariners Skipper for Q&A. Scott Servais (Manager) Scott Servais (Manager) 11am-12pm Media Session Jerry Dipoto (General Manager) 11am-12pm Media Session 2-2:30pm Instagram Takeover J.P. Crawford (SS), Marco Gonzales (LHP), Justus Sheffield (LHP) 1-1:30pm Virtual Clubhouse Chat Kyle Seager (3B) Nick Margevicius (LHP), Justus Sheffield (LHP) 3-3:30pm Twitter Takeover 1-2pm Virtual Clubhouse Chat Joey Gerber (RHP) 3-3:30pm Twitter Takeover The Mariners Director of Player Development Taylor Trammell (OF) shares his collection of motivational books. Andy McKay (Director of Player Development) 4-4:30pm Instagram Takeover Join Mitch for Q&A as he mans the grill 4-5pm Virtual Clubhouse Chat for dinner! Jerry Dipoto (General Manager) 2-2:30pm Twitter Takeover Mitch Haniger (OF) Shed Long Jr. (INF) 5-6pm Mariners Care Virtual Community Tour 5-6pm Mariners Care Virtual Community Tour pres. by ROOT SPORTS 3-3:30pm TikTok Takeover pres. by ROOT SPORTS Tune is as we virtually visit the northwest Sam Carlson (RHP) We’re virtually headed to SW Washington corner of the state and B.C. and Oregon. Braden Bishop (OF), Ty France (INF) Justin Dunn (RHP), Keynan Middleton (RHP) 3-4pm Spanish Media Session José Marmolejos (INF), Rafael Montero (RHP), 7-9pm Hot Stove Report @LosMarineros Andres Munoz (RHP), Julio Rodriguez (OF), WHERE TO Luis Torrens (C) 6:30-8pm Mariners Virtual Bingo TUNE-IN It’s bingo.. -

Today's Starting Lineups
BOSTON RED SOX (13-9) vs. SEATTLE MARINERS (13-8) Sunday, April 25, 2021 ● Fenway Park, Boston, MA SEATTLE MARINERS AVG HR RBI PLAYER POS 1 2 3 4 5 6 7 8 9 10 11 12 AB R H RBI .291 5 17 17-Mitch Haniger DH .320 3 12 23-Ty France 2B .247 3 19 15-Kyle Seager L 3B .167 0 0 1-Kyle Lewis CF .200 1 6 12-Evan White 1B .107 1 6 25-Dylan Moore RF .265 2 5 0-Sam Haggerty S LF .111 1 1 2-Tom Murphy C .235 0 4 3-J.P. Crawford L SS R H E LOB PITCHERS DEC IP H R ER BB SO HR WP HB P/S GAME DATA 52-Nick Margevicius, LHP (0-1, 5.40) Official Scorer: Chaz Scoggins 1st Pitch: Temp: Gam e Time: Attendance: 0-Sam Haggerty, INF (S) 17-Mitch Haniger, OF 38-Anthony Misiewicz, LHP 74-Ljay Newsome, RHP SEA Bench SEA Bullpen 1-Kyle Lewis, OF 18-Yusei Kikuchi, LHP 39-Carson Vitale (Field Coord.) 77-Chris Flexen, RHP 2-Tom Murphy, C 20-Taylor Trammell, OF (L) 44-James Paxton, LHP^ 79-Trent Blank (Bullpen) Left Left 3-J.P. Crawford, INF (L) 21-Tim Laker (Hitting) 44-Jarret DeHart (Asst. Hitting) 99-Keynan Middleton, RHP 20-Taylor Trammell 38-Anthony Misiewicz 4-Shed Long Jr., INF (L)* 22-Luis Torrens, C 47-Rafael Montero, RHP 26-José Marmolejos 7-Marco Gonzales, LHP 23-Ty France, INF 48-Jared Sandberg (Bench) * 10-day IL Right 9-Scott Servais (Manager) 25-Dylan Moore, INF 49-Kendall Graveman, RHP ^ 60-day IL Right 16-Drew Steckenrider 12-Evan White, 1B 26-José Marmolejos, INF (L) 52-Nick Margevicius, LHP #COVID-19 Related IL 22-Luis Torrens 47-Rafael Montero 13-Perry Hill (First Base) 28-Jake Fraley, OF (L)* 53-Will Vest, RHP 49-Kendall Graveman 14-Manny Acta (Third Base) 32-Pete Woodworth (Pitching) 54-Andrés Muñoz, RHP^ Switch 53-Will Vest 15-Kyle Seager, INF (L) 33-Justus Sheffield, LHP 58-Ken Giles, RHP^ None 65-Casey Sadler 16-Drew Steckenrider, RHP 35-Justin Dunn, RHP 65-Casey Sadler, RHP 74-Ljay Newsome 99-Keynan Middleton BOSTON RED SOX AVG HR RBI PLAYER POS 1 2 3 4 5 6 7 8 9 10 11 12 AB R H RBI .247 3 8 5-Kiké Hernández CF .325 3 13 11-Rafael Devers L 3B .359 7 21 28-J.D. -

0807 Rockies.Pdf
Manager: Scott Servais (29) NUMERICAL ROSTER 0 Mallex Smith OF 1 Kyle Lewis OF 2 Tom Murphy C 3 J.P. Crawford INF 4 Shed Long Jr. INF 7 Marco Gonzales LHP 9 Dee Gordon INF/OF 10 Tim Lopes INF/OF 12 Evan White INF 13 Perry Hill COACH 14 Manny Acta COACH 15 Kyle Seager INF 16 Carl Edwards Jr. RHP 18 Yusei Kikuchi LHP 20 Daniel Vogelbach INF 21 Tim Laker COACH 23 Austin Nola C 25 Dylan Moore INF/OF 27 Joe Thurston COACH 29 Scott Servais MANAGER 30 Nestor Cortes LHP 32 Pete Woodworth COACH 33 Justus Sheffield LHP 35 Justin Dunn RHP 38 Anthony Misiewicz LHP 39 Carson Vitale COACH 40 Brian DeLunas COACH 44 Jarret DeHart COACH 45 Taylor Guilbeau LHP 47 Taylor Williams RHP 48 Jared Sandberg COACH 49 Kendall Graveman RHP 50 Erik Swanson RHP 52 Nick Margevicius LHP 53 Dan Altavilla RHP 55 Yohan Ramirez RHP 57 Joe Hudson C 59 Joey Gerber RHP 61 Matt Magill RHP 65 Brandon Brennan RHP 66 Fleming Báez COACH 89 Nasusel Cabrera COACH 99 Taijuan Walker RHP SEATTLE MARINERS ROSTER NO. PITCHERS (16) B-T HT. WT. BORN BIRTHPLACE 53 ALTAVILLA, Dan R-R 5-11 200 09/08/92 McKeesport, PA 65 BRENNAN, Brandon (IL) R-R 6-4 220 07/26/91 Mission Viejo, CA 30 CORTES, Nestor R-L 5-11 210 12/10/94 Surgidero de 35 DUNN, Justin R-R 6-2 185 09/22/95 Freeport, NY 16 EDWARDS JR., Carl R-R 6-3 170 09/03/91 Newberry, SC 59 GERBER, Joey R-R 6-4 215 05/03/97 Maple Grove, MN 7 GONZALES, Marco L-L 6-1 199 02/16/92 Fort Collins, CO 49 GRAVEMAN, Kendall (IL) R-R 6-2 200 12/21/90 Alexander City, AL 45 GUILBEAU, Taylor L-L 6-4 190 05/12/93 Baton Rouge, LA 18 KIKUCHI, Yusei L-L 6-0 200 06/17/91 Iwate, Japan 61 MAGILL, Matt R-R 6-3 210 11/10/89 Simi Valley, CA 52 MARGEVICIUS, Nick L-L 6-5 220 06/18/96 Cleveland, OH 38 MISIEWICZ, Anthony R-L 6-1 200 11/01/94 Detroit, MI 55 RAMIREZ, Yohan R-R 6-4 190 05/06/95 Villa Mella, DR 33 SHEFFIELD, Justus L-L 6-0 200 05/13/96 Tullahoma, TN 50 SWANSON, Erik R-R 6-3 220 09/04/93 Fargo, ND 99 WALKER, Taijuan R-R 6-4 235 08/13/92 Shreveport, LA 47 WILLIAMS, Taylor L-R 5-11 185 07/21/91 Vancouver, WA NO. -

Minor Coaches.Indd
FRONT OFFICE FIELD STAFF PLAYERS OPPONENTS 2015 REVIEW HISTORY RECORDS MINOR LEAGUES MEDIA/MISC. 295 295 as the 2016 MEDIA GUIDE 2016 MEDIA GUIDE Baseball America Baseball No. 2 Prospect in the organization entering the 2016 season. out of Vanderbilt University, is ranked by University, out of Vanderbilt MINOR LEAGUES Carson Fulmer, the White Sox fi rst-round selection (eighth overall) in the 2015 draft the White Sox fi Carson Fulmer, ICE SCOUTING OFF FRONT FRONT FF FIELD STA S Nick Hostetler Nathan Durst Ed Pebley Director of Amateur Scouting National Crosschecker National Crosschecker PLAYER S ONENT OPP EVIEW R 2015 Derek Valenzuela Mike Shirley Joe Siers West Coast Crosschecker Midwest Crosschecker East Coast Crosschecker PROFESSIONAL SCOUTS FULL-TIME SCOUTING AREAS Bruce Benedict, Kevin Bootay, Joe Butler, Chris Lein, Alan Southern California, Southern Nevada TORY Mike Baker — S Regier, Daraka Shaheed, Keith Staab, John Tumminia, Bill Kevin Burrell — Georgia, South Carolina HI Young. Robbie Cummings — Idaho, Montana, Oregon, Washington, Wyoming INTERNATIONAL SCOUTING Ryan Dorsey — Texas Marco Paddy — Special Assistant to the General Manager, Abraham Fernandez — North Carolina, Virginia S International Operations Joel Grampietro — Connecticut, Delaware, Eastern Pennsyl- Amador Arias — Supervisor, Venezuela vania, Maine, Maryland, Massachusetts, New Hampshire, New Marino DeLeon — Dominican Republic Jersey, Eastern New York, Rhode Island, Vermont ECORD Robinson Garces — Venezuela Garrett Guest — Illinois, Indiana R Oliver Dominguez — Dominican Republic Phil Gulley — Kentucky, Southern Ohio, Tennessee, West Reydel Hernandez — Venezuela Virginia S Tomas Herrera — Mexico Warren Hughes — Alabama, Florida Panhandle, Louisiana, Miguel Peguero — Dominican Republic Mississippi Guillermo Peralto — Dominican Republic George Kachigian — San Diego Venezuela John Kazanas — Arizona, Colorado, New Mexico, Utah EAGUE Omar Sanchez — L Fermin Ubri — Dominican Republic J.J. -

Mariners Roster
2020 SEATTLE MARINERS ACTIVE ROSTER Manager – Scott Servais (29) Coaches – 3B Coach: Manny Acta (14), Acting Bullpen Coach: Trent Blank (79), Asst. Hitting Coach: Jarret DeHart (44), Acting Hitting Coach: Hugh Quattlebaum (90), Bench Coach: Jared Sandberg (48), Acting 1B Coach: Joe Thurston (27), Major League Field Coord.: Carson Vitale (39), Pitching Coach: Pete Woodworth (32), Bullpen Catcher: Fleming Báez (66), Batting Practice Pitcher: Nasusel Cabrera (89) Coaches (working remotely) – Bullpen Coach: Brian De Lunas (40), 1B/Infield Coach: Perry Hill (13), Hitting Coach: Tim Laker (21) DIRECTOR, STRENGTH AND CONDITIONING: James Clifford; ATHLETIC TRAINERS: Kyle Torgerson, Rob Nodine, Matt Toth; ATHLETIC TRAINER EMERITUS: Rick Griffin MEDICAL DIRECTOR: Dr. Edward Khalfayan; TEAM PHYSICIAN: Dr. Timothy Johnson No. PITCHERS (16+4) B-T Ht. Wt. Born Birthplace Residence 63 ADAMS, Austin ^ R-R 6-3 220 05/05/1991 Tampa, FL Tampa, FL Alphabetical Numerical 53 ALTAVILLA, Dan R-R 5-11 200 09/08/1992 McKeesport, PA Marigold, CT 14 ACTA, Manny, 3B Coach 0 SMITH, Mallex, OF 46 BAUTISTA, Gerson $ ^ R-R 6-3 200 05/31/1995 San Juan, DR San Juan, DR 63 ADAMS, Austin, RHP ^ 1 LEWIS, Kyle, OF $ 65 BRENNAN, Brandon # R-R 6-4 220 07/26/1991 Mission Viejo, CA San Juan Capistrano, CA 53 ALTAVILLA, Dan, RHP 2 MURPHY, Tom, C # 30 CORTES, Nestor R-L 5-11 210 12/10/1994 Surgidero de Batabanó, Cuba Hialeah, FL 66 BÁEZ, Fleming, Bullpen Catcher 3 CRAWFORD, J.P., INF 35 DUNN, Justin $ R-R 6-2 185 09/22/1995 Freeport, NY Freeport, NY 46 BAUTISTA, Gerson, RHP ^ $ -

Play Ball in Style
Manager: Scott Servais (9) NUMERICAL ROSTER 0 Sam Haggerty INF 1 Kyle Lewis OF 2 Tom Murphy C 3 J.P. Crawford INF 7 Marco Gonzales LHP 9 Scott Servais MANAGER 12 Evan White INF 13 Perry Hill COACH 14 Manny Acta COACH 15 Kyle Seager INF 16 Drew Steckenrider RHP 17 Mitch Haniger OF 18 Yusei Kikuchi LHP 20 Taylor Trammell OF 21 Tim Laker COACH 22 Luis Torrens C 23 Ty France INF 25 Dylan Moore INF 26 José Marmolejos INF 28 Jake Fraley OF 30 Robert Dugger RHP 32 Pete Woodworth COACH 33 Justus Sheffield LHP 35 Justin Dunn RHP 38 Anthony Misiewicz LHP 39 Carson Vitale COACH 40 Wyatt Mills RHP 41 Aaron Fletcher LHP 47 Rafael Montero RHP 48 Jared Sandberg COACH 49 Kendall Graveman RHP 50 Erik Swanson RHP 52 Nick Margevicius LHP 53 Will Vest RHP 65 Casey Sadler RHP 66 Fleming Baez COACH 74 Ljay Newsome RHP 77 Chris Flexen RHP 79 Trent Blank COACH 84 JT Chargois RHP 88 Jarret DeHart COACH 89 Nasusel Cabrera COACH 99 Keynan Middleton RHP SEATTLE MARINERS ROSTER NO. PITCHERS (14) B-T HT. WT. BORN BIRTHPLACE 84 JT Chargois S-R 6-3 200 12/03/90 Sulphur, LA 30 Robert Dugger R-R 6-0 198 07/03/95 Tucson, AZ 35 Justin Dunn R-R 6-2 185 09/22/95 Freeport, NY 41 Aaron Fletcher L-L 6-0 220 02/25/96 Geneseo, IL PLAY BALL IN STYLE. 77 Chris Flexen R-R 6-3 230 07/01/94 Newark, CA 7 Marco Gonzales (IL) L-L 6-1 199 02/16/92 Fort Collins, CO MARINERS SUITES PROVIDE THE PERFECT 49 Kendall Graveman R-R 6-2 200 12/21/90 Alexander City, AL SETTING FOR YOUR NEXT EVENT. -

Minor Leagues
MINOR LEAGUES Zack Collins, the White Sox first-round selection (10th overall) in the 2016 First-Year Player Draft, is ranked by Baseball America as the No. 4 Prospect in the organization entering the 2017 season. SCOUTING FRONT OFFICE FRONT FIELD STAFF Nick Hostetler Nathan Durst Mike Shirley Ed Pebley Director of Amateur Scouting National Crosschecker National Crosschecker National Hitting Crosschecker PLAYERS OPPONENTS 2016 REVIEW Derek Valenzuela Joe Siers Garrett Guest Mike Ledna West Coast Crosschecker East Coast Crosschecker Midwest Crosschecker College Relief Pitcher Crosschecker PROFESSIONAL SCOUTS FULL-TIME SCOUTING AREAS Bruce Benedict, Kevin Bootay, Joe Butler, Tony Howell, Chris Mike Baker — Southern California, Southern Nevada HISTORY Lein, Alan Regier, Daraka Shaheed, Keith Staab, John Tum- Kevin Burrell — Georgia, South Carolina minia, Bill Young. Robbie Cummings — Idaho, Montana, Oregon, Washington, Wyoming INTERNATIONAL SCOUTING Ryan Dorsey — Texas Marco Paddy — Special Assistant to the General Manager, Abraham Fernandez — North Carolina, Virginia International Operations Joel Grampietro — Connecticut, Delaware, Eastern Pennsyl- Amador Arias — Supervisor, Venezuela vania, Maine, Maryland, Massachusetts, New Hampshire, New Marino DeLeon — Dominican Republic Jersey, Eastern New York, Rhode Island, Vermont RECORDS Robinson Garces — Venezuela Phil Gulley — Kentucky, Southern Ohio, Tennessee, West Oliver Dominguez — Dominican Republic Virginia Reydel Hernandez — Venezuela Warren Hughes — Alabama, Florida Panhandle, Louisiana, Tomas Herrera — Mexico Mississippi Miguel Peguero — Dominican Republic George Kachigian — San Diego Guillermo Peralto — Dominican Republic John Kazanas — Arizona, Colorado, New Mexico, Utah Omar Sanchez — Venezuela J.J. Lally — Illinois, Iowa, Michigan Panhandle, Minnesota, Fermin Ubri — Dominican Republic Nebraska, North and South Dakota, Wisconsin, Canada Steve Nichols — Northern Florida Jose Ortega — Puerto Rico, Southern Florida MINOR LEAGUES Clay Overcash — Arkansas, Kansas, Missouri, Oklahoma Noah St. -

Play Ball in Style
Manager: Scott Servais (9) NUMERICAL ROSTER 0 Sam Haggerty INF 1 Kyle Lewis OF 2 Tom Murphy C 3 J.P. Crawford INF 4 Shed Long Jr. INF 7 Marco Gonzales LHP 9 Scott Servais MANAGER 12 Evan White INF 13 Perry Hill COACH 14 Manny Acta COACH 15 Kyle Seager INF 17 Mitch Haniger OF 18 Yusei Kikuchi LHP 20 Taylor Trammell OF 21 Tim Laker COACH 22 Luis Torrens C 23 Ty France INF 25 Dylan Moore INF 26 José Marmolejos INF 28 Jake Fraley OF 32 Pete Woodworth COACH 33 Justus Sheffield LHP 35 Justin Dunn RHP 38 Anthony Misiewicz LHP 39 Carson Vitale COACH 44 James Paxton LHP 45 Domingo Tapia RHP 47 Rafael Montero RHP 48 Jared Sandberg COACH 49 Kendall Graveman RHP 51 Andres Muñoz RHP 52 Nick Margevicius LHP 53 Will Vest RHP 58 Ken Giles RHP 65 Casey Sadler RHP 66 Fleming Baez COACH 77 Chris Flexen RHP 79 Trent Blank COACH 88 Jarret DeHart COACH 89 Nasusel Cabrera COACH 99 Keynan Middleton RHP SEATTLE MARINERS ROSTER NO. PITCHERS (15) B-T HT. WT. BORN BIRTHPLACE 35 DUNN, Justin R-R 6-2 185 09/22/95 Freeport, NY 77 FLEXEN, Chris R-R 6-3 230 07/01/94 Newark, CA 58 GILES, Ken R-R 6-3 210 09/20/90 Albuquerque, NM 7 GONZALES, Marco L-L 6-1 199 02/16/92 Fort Collins, CO PLAY BALL IN STYLE. 49 GRAVEMAN, Kendall R-R 6-2 200 12/21/90 Alexander City, AL MARINERS SUITES PROVIDE THE PERFECT 18 KIKUCHI, Yusei L-L 6-0 200 06/17/91 Morioka, Japan 52 MARGEVICIUS, Nick L-L 6-5 220 06/18/96 Cleveland, OH SETTING FOR YOUR NEXT EVENT. -

Baseball) Лице ÑÐ ¿Ð¸ÑÑ ŠÐº
Coach (baseball) Лице ÑÐ ¿Ð¸ÑÑ ŠÐº Lee Kang-chul https://bg.listvote.com/lists/person/lee-kang-chul-12610856 Torey Lovullo https://bg.listvote.com/lists/person/torey-lovullo-7825680 Smoky Burgess https://bg.listvote.com/lists/person/smoky-burgess-7546134 Maje McDonnell https://bg.listvote.com/lists/person/maje-mcdonnell-6737615 Kim Gyeong-tae https://bg.listvote.com/lists/person/kim-gyeong-tae-16080149 Yoon Yo-seop https://bg.listvote.com/lists/person/yoon-yo-seop-11264989 Kim Yeon-hoon https://bg.listvote.com/lists/person/kim-yeon-hoon-16079876 Sam Narron https://bg.listvote.com/lists/person/sam-narron-7407955 Den Yamada https://bg.listvote.com/lists/person/den-yamada-11470163 Humberto Quintero https://bg.listvote.com/lists/person/humberto-quintero-3143215 Sheng Yi https://bg.listvote.com/lists/person/sheng-yi-7494253 José Castro https://bg.listvote.com/lists/person/jos%C3%A9-castro-6291888 Eric Langill https://bg.listvote.com/lists/person/eric-langill-23883319 José Alguacil https://bg.listvote.com/lists/person/jos%C3%A9-alguacil-27805430 Michio Okamoto https://bg.listvote.com/lists/person/michio-okamoto-11473233 Wendell Kim https://bg.listvote.com/lists/person/wendell-kim-7982442 Spin Williams https://bg.listvote.com/lists/person/spin-williams-7577392 Kevin McMullan https://bg.listvote.com/lists/person/kevin-mcmullan-6396974 Hap Spuhler https://bg.listvote.com/lists/person/hap-spuhler-23988368 Walt Dixon https://bg.listvote.com/lists/person/walt-dixon-7963957 Liam Bowen https://bg.listvote.com/lists/person/liam-bowen-64745690 Dean Treanor https://bg.listvote.com/lists/person/dean-treanor-18350816 Takahiro Akagawa https://bg.listvote.com/lists/person/takahiro-akagawa-11635583 ShÅj i SaitÅ https://bg.listvote.com/lists/person/sh%C5%8Dji-sait%C5%8D-11500643 Don Colpoys https://bg.listvote.com/lists/person/don-colpoys-27980108 Gary Hughes https://bg.listvote.com/lists/person/gary-hughes-5525276 Kimio GomyÅ https://bg.listvote.com/lists/person/kimio-gomy%C5%8D-62474551 J. -
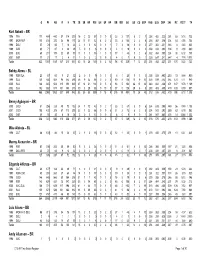
C12 Batter Register03
GPA AB R H TB 2B 3B HR RBI SH SF HP BB IBB SO SB CS GDP AVG SLG OBP 2AV RC RC27 TA Kurt Abbott – BR 1996 TAY 117 484 442 57 114 200 16 2 22 57 0 0 9 33 2 127 5 2 7 .258 .452 .322 .281 65 5.18 .733 1997 MOR-FER 113 416 375 34 96 175 24 11 11 52 4 2 2 33 4 120 2 4 6 .256 .467 .318 .304 54 4.98 .734 1998 DOU 57 74 65 7 18 23 3 1 0 12 0 1 1 7 3 18 0 0 2 .277 .354 .351 .185 8 4.35 .633 1999 AVD 60 71 67 4 24 29 5 0 0 6000 4 01904 3.358 .433 .394 .134 9 4.80 .660 2000 EVE 69 201 183 22 59 83 13 1 3 16 1 0 0 17 1 48 0 2 6 .322 .454 .380 .224 30 6.02 .758 2001 SKR 17 21 17 3 4 11 1 0 2 2000 4 0 7 00 1.235 .647 .381 .647 4 7.74 1.071 Totals 433 1267 1149 127 315 521 62 15 38 145 5 3 12 98 10 339 7 12 25 .274 .453 .337 .271 170 5.22 .732 Bobby Abreu – BL 1998 FER-SLA 25 67 60 9 21 32 2 0 3 9010 6 12001 0.350 .533 .403 .283 13 8.64 .950 1999 SLA 145 660 568 96 182 295 29 9 22 96 0 2 0 90 8 156 15 9 13 .320 .519 .412 .384 123 8.11 .980 2000 SLA 146 665 563 115 193 339 27 13 31 116 0 5 4 93 5 102 26 10 22 .343 .602 .436 .471 147 9.76 1.149 2002 SLA 152 668 571 101 153 276 30 3 29 88 0 10 0 87 0 126 29 6 8 .268 .483 .359 .419 108 6.59 .907 Totals 468 2060 1762 321 549 942 88 25 85 309 0 18 4 276 14 404 70 26 43 .312 .535 .402 .419 390 8.10 1.008 Benny Agbayani – BR 2000 COO 81 256 225 45 73 138 24 1 13 42 0 2 1 28 3 67 8 0 6 .324 .613 .398 .449 56 9.49 1.108 2001 COO 108 435 378 67 115 205 22 1 22 68 0 0 6 51 2 73 6 2 8 .304 .542 .395 .389 83 8.19 .982 2002 SKR 45 50 42 6 16 28 3 0 3 10 0 0 0 8 0 9 0 0 1 .381 .667 .480 .476 14 13.84 1.333 Totals 234