CA Spectrum Software Release Notice (CA Spectrum SRN) Is Included in the CA Spectrum Installation Package
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hieroglyphs for the Information Age: Images As a Replacement for Characters for Languages Not Written in the Latin-1 Alphabet Akira Hasegawa
Rochester Institute of Technology RIT Scholar Works Theses Thesis/Dissertation Collections 5-1-1999 Hieroglyphs for the information age: Images as a replacement for characters for languages not written in the Latin-1 alphabet Akira Hasegawa Follow this and additional works at: http://scholarworks.rit.edu/theses Recommended Citation Hasegawa, Akira, "Hieroglyphs for the information age: Images as a replacement for characters for languages not written in the Latin-1 alphabet" (1999). Thesis. Rochester Institute of Technology. Accessed from This Thesis is brought to you for free and open access by the Thesis/Dissertation Collections at RIT Scholar Works. It has been accepted for inclusion in Theses by an authorized administrator of RIT Scholar Works. For more information, please contact [email protected]. Hieroglyphs for the Information Age: Images as a Replacement for Characters for Languages not Written in the Latin- 1 Alphabet by Akira Hasegawa A thesis project submitted in partial fulfillment of the requirements for the degree of Master of Science in the School of Printing Management and Sciences in the College of Imaging Arts and Sciences of the Rochester Institute ofTechnology May, 1999 Thesis Advisor: Professor Frank Romano School of Printing Management and Sciences Rochester Institute ofTechnology Rochester, New York Certificate ofApproval Master's Thesis This is to certify that the Master's Thesis of Akira Hasegawa With a major in Graphic Arts Publishing has been approved by the Thesis Committee as satisfactory for the thesis requirement for the Master ofScience degree at the convocation of May 1999 Thesis Committee: Frank Romano Thesis Advisor Marie Freckleton Gr:lduate Program Coordinator C. -

Verity Locale Configuration Guide V5.0 for Peoplesoft
Verity® Locale Configuration Guide V 5.0 for PeopleSoft® November 15, 2003 Original Part Number DM0619 Verity, Incorporated 894 Ross Drive Sunnyvale, California 94089 (408) 541-1500 Verity Benelux BV Coltbaan 31 3439 NG Nieuwegein The Netherlands Copyright 2003 Verity, Inc. All rights reserved. No part of this publication may be reproduced, transmitted, stored in a retrieval system, nor translated into any human or computer language, in any form or by any means, electronic, mechanical, magnetic, optical, chemical, manual or otherwise, without the prior written permission of the copyright owner, Verity, Inc., 894 Ross Drive, Sunnyvale, California 94089. The copyrighted software that accompanies this manual is licensed to the End User for use only in strict accordance with the End User License Agreement, which the Licensee should read carefully before commencing use of the software. Verity®, Ultraseek®, TOPIC®, KeyView®, and Knowledge Organizer® are registered trademarks of Verity, Inc. in the United States and other countries. The Verity logo, Verity Portal One™, and Verity® Profiler™ are trademarks of Verity, Inc. Sun, Sun Microsystems, the Sun logo, Sun Workstation, Sun Operating Environment, and Java are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries. Xerces XML Parser Copyright 1999-2000 The Apache Software Foundation. All rights reserved. Microsoft is a registered trademark, and MS-DOS, Windows, Windows 95, Windows NT, and other Microsoft products referenced herein are trademarks of Microsoft Corporation. IBM is a registered trademark of International Business Machines Corporation. The American Heritage® Concise Dictionary, Third Edition Copyright 1994 by Houghton Mifflin Company. Electronic version licensed from Lernout & Hauspie Speech Products N.V. -

Configuration Control Document
Configuration Control Document CR8200 Firmware Version 1.12.2 CR950 Firmware Version 2.1.2 CR1500 Firmware Version 1.4.1 CR1100 Firmware Version 1.2.0 CR5200 Firmware Version 1.0.4 CR2700 Firmware Version 1.0.6 A271 Firmware Version 1.0.3 D027153 CR8200 CR950 CR1500 CR1100 CR2700 CRA-A271 Configuration Control Document CCD.Docx Page 1 of 89 © 2013-2019 The Code Corporation 12393 South Gateway Park Place Suite 600, Draper, UT 84020 (801) 495-2200 FAX (801) 495-0280 Configuration Control Document Table of Contents Keyword Table .................................................................................................................. 4 Scope ................................................................................................................................ 6 Notations .......................................................................................................................... 6 Reader Command Overview ............................................................................................. 6 4.1 Configuration Command Architecture ........................................................................................ 6 4.2 Command Format ....................................................................................................................... 7 4.3 Supported Commands ................................................................................................................. 8 4.3.1 <CF> – Configuration Manager ...................................................................................................... -

Windows NLS Considerations Version 2.1
Windows NLS Considerations version 2.1 Radoslav Rusinov [email protected] Windows NLS Considerations Contents 1. Introduction ............................................................................................................................................... 3 1.1. Windows and Code Pages .................................................................................................................... 3 1.2. CharacterSet ........................................................................................................................................ 3 1.3. Encoding Scheme ................................................................................................................................ 3 1.4. Fonts ................................................................................................................................................... 4 1.5. So Why Are There Different Charactersets? ........................................................................................ 4 1.6. What are the Difference Between 7 bit, 8 bit and Unicode Charactersets? ........................................... 4 2. NLS_LANG .............................................................................................................................................. 4 2.1. Setting the Character Set in NLS_LANG ............................................................................................ 4 2.2. Where is the Character Conversion Done? ......................................................................................... -

NAME DESCRIPTION Supported Encodings
Perl version 5.8.6 documentation - Encode::Supported NAME Encode::Supported -- Encodings supported by Encode DESCRIPTION Encoding Names Encoding names are case insensitive. White space in names is ignored. In addition, an encoding may have aliases. Each encoding has one "canonical" name. The "canonical" name is chosen from the names of the encoding by picking the first in the following sequence (with a few exceptions). The name used by the Perl community. That includes 'utf8' and 'ascii'. Unlike aliases, canonical names directly reach the method so such frequently used words like 'utf8' don't need to do alias lookups. The MIME name as defined in IETF RFCs. This includes all "iso-"s. The name in the IANA registry. The name used by the organization that defined it. In case de jure canonical names differ from that of the Encode module, they are always aliased if it ever be implemented. So you can safely tell if a given encoding is implemented or not just by passing the canonical name. Because of all the alias issues, and because in the general case encodings have state, "Encode" uses an encoding object internally once an operation is in progress. Supported Encodings As of Perl 5.8.0, at least the following encodings are recognized. Note that unless otherwise specified, they are all case insensitive (via alias) and all occurrence of spaces are replaced with '-'. In other words, "ISO 8859 1" and "iso-8859-1" are identical. Encodings are categorized and implemented in several different modules but you don't have to use Encode::XX to make them available for most cases. -

Iso/Iec 16022:2006(E)
This preview is downloaded from www.sis.se. Buy the entire standard via https://www.sis.se/std-907850 INTERNATIONAL ISO/IEC STANDARD 16022 Second edition 2006-09-15 Information technology — Automatic identification and data capture techniques — Data Matrix bar code symbology specification Technologies de l'information — Techniques d'identification automatique et de capture des données — Spécification de symbologie de code à barres Data Matrix Reference number ISO/IEC 16022:2006(E) © ISO/IEC 2006 This preview is downloaded from www.sis.se. Buy the entire standard via https://www.sis.se/std-907850 ISO/IEC 16022:2006(E) PDF disclaimer This PDF file may contain embedded typefaces. In accordance with Adobe's licensing policy, this file may be printed or viewed but shall not be edited unless the typefaces which are embedded are licensed to and installed on the computer performing the editing. In downloading this file, parties accept therein the responsibility of not infringing Adobe's licensing policy. The ISO Central Secretariat accepts no liability in this area. Adobe is a trademark of Adobe Systems Incorporated. Details of the software products used to create this PDF file can be found in the General Info relative to the file; the PDF-creation parameters were optimized for printing. Every care has been taken to ensure that the file is suitable for use by ISO member bodies. In the unlikely event that a problem relating to it is found, please inform the Central Secretariat at the address given below. © ISO/IEC 2006 All rights reserved. Unless otherwise specified, no part of this publication may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying and microfilm, without permission in writing from either ISO at the address below or ISO's member body in the country of the requester. -

Unicode Translate — Translate files to Unicode
Title stata.com unicode translate — Translate files to Unicode Description Syntax Options Remarks and examples Also see Description unicode translate translates files containing extended ASCII to Unicode (UTF-8). Extended ASCII is how people got accented Latin characters such as “a”´ and “a”` and got characters from other languages such as “ ”, “Θ”, and “ ” before the advent of Unicode or, in this context, before Stata became Unicode aware. £ If you have do-files, ado-files, .dta files, etc., from Stata 13 or earlier—and those files contain extended ASCII—you need to use the unicode translate command to translate the files from extended ASCII to Unicode. ¢ ¡ The unicode translate command is also useful if you have text files containing extended ASCII that you wish to read into Stata. Syntax Analyze files to be translated unicode analyze filespec , redo nodata Set encoding to be used during translation unicode encoding set " encoding " Translate or retranslate files unicode translate filespec , invalid (escape j mark j ignore) transutf8 nodata unicode retranslate filespec , invalid (escape j mark j ignore) transutf8 replace nodata Restore backups of translated files unicode restore filespec , replace Delete backups of translated files unicode erasebackups, badidea 1 2 unicode translate — Translate files to Unicode filespec is a single filename or a file specification containing * and ? specifying one or more files, such as *.dta *.do *.* * myfile.* year??data.dta unicode analyzes and translates .dta files and text files. It assumes that filenames with suffix .dta contain Stata datasets and that all other suffixes contain text. Those other suffixes are .ado, .do, .mata, .txt, .csv, .sthlp, .class, .dlg, .idlg, .ihlp, .smcl, and .stbcal. -

UTF What? a Guide for Handling SAS Transcoding Errors with UTF-8 Encoded Data Michael Stackhouse, Lavanya Pogula, Covance, Inc
PharmaSUG 2018 - Paper BB-08 UTF What? A Guide for Handling SAS Transcoding Errors with UTF-8 Encoded Data Michael Stackhouse, Lavanya Pogula, Covance, Inc. ABSTRACT The acronyms SBCS, DBCS, or MBCS (i.e. single, double, and multi-byte character sets) mean nothing to most statistical programmers. Many do not concern themselves with the encoding of their data, but what happens when data encoding causes SAS to error? The errors produced by SAS and some common workarounds for the issue may not answer important questions about what the issue was or how it was handled. Though encoding issues can apply to any set of data, this presentation will be geared towards an SDTM submission. Additionally, a common origin of the transcoding error is UTF-8 encoded source data, whose use is rising in popularity by database providers, making it likely that this error will continue to appear with greater frequency. Therefore, the ultimate goal of this paper will be to provide guidance on how to obtain fully compliant SDTM data with the intent of submission to the FDA from source datasets provided natively in UTF-8 encoding. Among other topics, in this paper we first explore UTF-8 encoding, explaining what it is and why it is. Furthermore, we demonstrate how to identify the issues not explained by SAS, and recommend best practices dependent on the situation at hand. Lastly, we review some preventative checks that may be added into SAS code to identify downstream impacts early on. By the end of this paper, the audience should have a clear vision of how to proceed when their clinical database is using separate encoding from their native system. -

ASCII, Unicode, and in Between Douglas A. Kerr Issue 3 June 15, 2010 ABSTRACT the Standard Coded Character Set ASCII Was Formall
ASCII, Unicode, and In Between Douglas A. Kerr Issue 3 June 15, 2010 ABSTRACT The standard coded character set ASCII was formally standardized in 1963 and, in its “complete” form, in 1967. It is a 7-bit character set, including 95 graphic characters. As personal computers emerged, they typically had an 8-bit architecture. To exploit that, they typically came to use character sets that were “8-bit extensions of ASCII”, providing numerous additional graphic characters. One family of these became common in computers using the MS-DOS operating system. Another similar but distinct family later became common in computers operating with the Windows operating system. In the late 1980s, a true second-generation coded character set, called Unicode, was developed, and was standardized in 1991. Its structure provides an ultimate capacity of about a million graphic characters, catering thoroughly to the needs of hundreds of languages and many specialized and parochial uses. Various encoding techniques are used to represent characters from this set in 8- and 16-bit computer environments. In this article, we will describe and discuss these coded character sets, their development, their status, the relationships between them, and practical implications of their use. Information is included on the entry, in Windows computer systems, of characters not directly accessible from the keyboard. BEFORE ASCII As of 1960, the interchange of data within and between information communication and processing systems was made difficult by the lack of a uniform coded character set. Information communication in the traditional “teletypewriter” sense generally used a 5-bit coded character set, best described as the “Murray code” (although as a result of historical misunderstandings it is often called the “Baudot code”). -

Chardet Documentation Release 5.0.0Dev0
chardet Documentation Release 5.0.0dev0 Mark Pilgrim, Dan Blanchard, Ian Cordasco Sep 06, 2021 Contents 1 Documentation 3 1.1 Frequently asked questions........................................3 1.2 Supported encodings...........................................4 1.3 Usage...................................................5 1.4 How it works...............................................6 1.5 chardet..................................................8 2 Indices and tables 19 Python Module Index 21 Index 23 i ii chardet Documentation, Release 5.0.0dev0 Character encoding auto-detection in Python. As smart as your browser. Open source. Contents 1 chardet Documentation, Release 5.0.0dev0 2 Contents CHAPTER 1 Documentation 1.1 Frequently asked questions 1.1.1 What is character encoding? When you think of “text”, you probably think of “characters and symbols I see on my computer screen”. But com- puters don’t deal in characters and symbols; they deal in bits and bytes. Every piece of text you’ve ever seen on a computer screen is actually stored in a particular character encoding. There are many different character encodings, some optimized for particular languages like Russian or Chinese or English, and others that can be used for multiple languages. Very roughly speaking, the character encoding provides a mapping between the stuff you see on your screen and the stuff your computer actually stores in memory and on disk. In reality, it’s more complicated than that. Many characters are common to multiple encodings, but each encoding may use a different sequence of bytes to actually store those characters in memory or on disk. So you can think of the character encoding as a kind of decryption key for the text. -
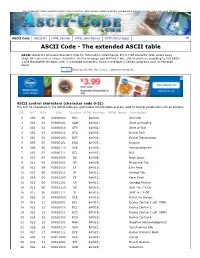
ASCII Code the Extended ASCII Table
The following ASCII table contains both ASCII control characters, ASCII printable characters and the extended ASCII character set ISO 88591, also called ISO Latin1 ASCII Code ASCII Art HTML Symbol HTML Color Names HTTP status codes 941 ASCII Code The extended ASCII table ASCII stands for American Standard Code for Information Interchange. It's a 7bit character code where every single bit represents a unique character. On this webpage you will find 8 bits, 256 characters, according to ISO 8859 1 and Microsoft® Windows Latin1 increased characters, which is available in certain programs such as Microsoft Word. Like 2K people like this. Sign Up to see what your friends like. ASCII control characters (character code 031) The first 32 characters in the ASCIItable are unprintable control codes and are used to control peripherals such as printers. DEC OCT HEX BIN Symbol HTML Number HTML Name Description 0 000 00 00000000 NUL � Null char 1 001 01 00000001 SOH  Start of Heading 2 002 02 00000010 STX  Start of Text 3 003 03 00000011 ETX  End of Text 4 004 04 00000100 EOT  End of Transmission 5 005 05 00000101 ENQ  Enquiry 6 006 06 00000110 ACK  Acknowledgment 7 007 07 00000111 BEL  Bell 8 010 08 00001000 BS  Back Space 9 011 09 00001001 HT 	 Horizontal Tab 10 012 0A 00001010 LF 
 Line Feed 11 013 0B 00001011 VT  Vertical Tab 12 014 0C 00001100 FF  Form Feed 13 015 0D 00001101 CR 
 Carriage Return 14 016 0E 00001110 SO  Shift Out / XOn 15 017 0F 00001111 SI  Shift In / XOff 16 020 10 00010000 DLE  Data Line Escape 17 021 11 00010001 DC1  Device Control 1 (oft. -
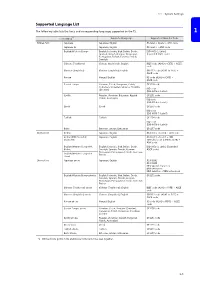
TS2060/TS1000 Smart Reference Manual
1.1 System Settings Supported Language List The following table lists the fonts and corresponding languages supported by the TS. 1 Font Setting *1 Supported Language Supported Character Code Bitmap font Japanese Japanese, English JIS level 1, level 2 + ANK code Japanese 32 Japanese, English JIS level 1 + ANK code English/Western Europe English, Icelandic, Irish, Italian, Dutch, ISO-8859-1: Latin1 Spanish, Danish, German, Norwegian, (Extended ASCII code) Portuguese, Finnish, Faroese, French, 2 Swedish Chinese (Traditional) Chinese (traditional), English BIG5 code (A141 to C67E) + ASCII code Chinese (Simplified) Chinese (simplified), English GB2312 code (A1A1 to FEFE) + ASCII code Korean Hangul, English KS code (A1A2 to C8FE) + ASCII code 3 Central Europe Croatian, Czech, Hungarian, Polish, CP1250 code Romanian, Slovakian, Slovene, Hrvatska ISO code (Croatian) (ISO-8859-2: Latin2) Cyrillic Russian, Ukrainian, Bulgarian, Kazakh, CP1251 code Uzbek, Azerbaijani ISO code (ISO-8859-5: Latin5) Greek Greek CP1253 code 4 ISO code (ISO-8859-7: Latin7) Turkish Turkish CP1254 code ISO code (ISO-8859-9: Latin9) Baltic Estonian, Latvian, Lithuanian CP1257 code Gothic font Gothic Japanese, English JIS level 1 + level 2 + ANK code 5 Gothic (IBM Extended Japanese, English JIS level 1 + level 2 + IBM Character) extended code (FA40 to FC4B) + ANK code English/Western Europe HK English, Icelandic, Irish, Italian, Dutch, ISO-8859-1: Latin1 (Expanded Gothic Swedish, Spanish, Danish, German, ASCII code) Norwegian, Portuguese, Finnish, Faeroese, English/Western