Towards Meaningful Software Metrics Aggregation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Working with Unreliable Observers Using Reactive Extensions
Master thesis WORKING WITH UNRELIABLE OBSERVERS USING REACTIVE EXTENSIONS November 10, 2016 Dorus Peelen (s4167821) Computing science Radboud University [email protected] — Supervisors: Radboud University: Rinus Plasmeijer Aia Software: Jeroen ter Hofstede Contents 1 Introduction 5 1.1 Overview of thesis . .7 2 Background 8 2.1 Aia Software . .8 2.2 Current situation . .8 2.3 The use case . .9 2.3.1 Technical details . 10 2.3.2 Potential problems . 11 2.4 Problem description . 11 2.5 Desired Properties of the new system . 11 3 Overview of Rx 13 3.1 Basic Ideas of Rx . 13 3.2 Observer and Observable . 15 3.3 Hot vs Cold observables . 15 3.4 Marble diagrams . 16 3.5 Transformations on Event Streams . 16 3.6 Schedulers . 16 3.7 Control process in Rx . 17 3.8 Interactive vs reactive . 18 3.9 Push-back and backpressure . 18 3.10 Operators with unbounded Queue . 19 3.11 Explanation and example of different operators in Rx . 19 3.11.1 Select .................................. 19 3.11.2 SelectMany ............................... 20 3.11.3 Where .................................. 20 3.11.4 Delay .................................. 20 3.11.5 Merge and Concat ........................... 21 3.11.6 Buffer and Window ........................... 21 3.11.7 GroupBy ................................. 21 3.11.8 Amb .................................... 21 3.11.9 Debounce, Sample and Throttle ................... 22 3.11.10 ObserveOn ................................ 22 3.12 Related work . 22 3.12.1 TPL . 23 3.12.2 iTasks . 23 4 The experiment 25 4.1 Important properties . 25 4.2 Test architecture . 26 4.2.1 Design . 26 2 4.2.2 Concepts . -
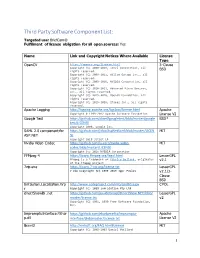
Third Party Software Component List: Targeted Use: Briefcam® Fulfillment of License Obligation for All Open Sources: Yes
Third Party Software Component List: Targeted use: BriefCam® Fulfillment of license obligation for all open sources: Yes Name Link and Copyright Notices Where Available License Type OpenCV https://opencv.org/license.html 3-Clause Copyright (C) 2000-2019, Intel Corporation, all BSD rights reserved. Copyright (C) 2009-2011, Willow Garage Inc., all rights reserved. Copyright (C) 2009-2016, NVIDIA Corporation, all rights reserved. Copyright (C) 2010-2013, Advanced Micro Devices, Inc., all rights reserved. Copyright (C) 2015-2016, OpenCV Foundation, all rights reserved. Copyright (C) 2015-2016, Itseez Inc., all rights reserved. Apache Logging http://logging.apache.org/log4cxx/license.html Apache Copyright © 1999-2012 Apache Software Foundation License V2 Google Test https://github.com/abseil/googletest/blob/master/google BSD* test/LICENSE Copyright 2008, Google Inc. SAML 2.0 component for https://github.com/jitbit/AspNetSaml/blob/master/LICEN MIT ASP.NET SE Copyright 2018 Jitbit LP Nvidia Video Codec https://github.com/lu-zero/nvidia-video- MIT codec/blob/master/LICENSE Copyright (c) 2016 NVIDIA Corporation FFMpeg 4 https://www.ffmpeg.org/legal.html LesserGPL FFmpeg is a trademark of Fabrice Bellard, originator v2.1 of the FFmpeg project 7zip.exe https://www.7-zip.org/license.txt LesserGPL 7-Zip Copyright (C) 1999-2019 Igor Pavlov v2.1/3- Clause BSD Infralution.Localization.Wp http://www.codeproject.com/info/cpol10.aspx CPOL f Copyright (C) 2018 Infralution Pty Ltd directShowlib .net https://github.com/pauldotknopf/DirectShow.NET/blob/ LesserGPL -

An Opinionated Guide to Technology Frontiers
TECHNOLOGY RADAR An opinionated guide to technology frontiers Volume 24 #TWTechRadar thoughtworks.com/radar The Technology Advisory Board (TAB) is a group of 20 senior technologists at Thoughtworks. The TAB meets twice a year face-to-face and biweekly by phone. Its primary role is to be an advisory group for Thoughtworks CTO, Contributors Rebecca Parsons. The Technology Radar is prepared by the The TAB acts as a broad body that can look at topics that affect technology and technologists at Thoughtworks. With the ongoing global pandemic, we Thoughtworks Technology Advisory Board once again created this volume of the Technology Radar via a virtual event. Rebecca Martin Fowler Bharani Birgitta Brandon Camilla Cassie Parsons (CTO) (Chief Scientist) Subramaniam Böckeler Byars Crispim Shum Erik Evan Fausto Hao Ian James Lakshminarasimhan Dörnenburg Bottcher de la Torre Xu Cartwright Lewis Sudarshan Mike Neal Perla Rachel Scott Shangqi Zhamak Mason Ford Villarreal Laycock Shaw Liu Dehghani TECHNOLOGY RADAR | 2 © Thoughtworks, Inc. All Rights Reserved. About the Radar Thoughtworkers are passionate about technology. We build it, research it, test it, open source it, write about it and constantly aim to improve it — for everyone. Our mission is to champion software excellence and revolutionize IT. We create and share the Thoughtworks Technology Radar in support of that mission. The Thoughtworks Technology Advisory Board, a group of senior technology leaders at Thoughtworks, creates the Radar. They meet regularly to discuss the global technology strategy for Thoughtworks and the technology trends that significantly impact our industry. The Radar captures the output of the Technology Advisory Board’s discussions in a format that provides value to a wide range of stakeholders, from developers to CTOs. -

Front-End Development with ASP.NET Core, Angular, And
Table of Contents COVER TITLE PAGE FOREWORD INTRODUCTION WHY WEB DEVELOPMENT REQUIRES POLYGLOT DEVELOPERS WHO THIS BOOK IS FOR WHAT THIS BOOK COVERS HOW THIS BOOK IS STRUCTURED WHAT YOU NEED TO USE THIS BOOK CONVENTIONS SOURCE CODE ERRATA 1 What’s New in ASP.NET Core MVC GETTING THE NAMES RIGHT A BRIEF HISTORY OF THE MICROSOFT .NET WEB STACK .NET CORE INTRODUCING ASP.NET CORE NEW FUNDAMENTAL FEATURES OF ASP.NET CORE AN OVERVIEW OF SOME ASP.NET CORE MIDDLEWARE ASP.NET CORE MVC SUMMARY 2 The Front‐End Developer Toolset ADDITIONAL LANGUAGES YOU HAVE TO KNOW JAVASCRIPT FRAMEWORKS CSS FRAMEWORKS PACKAGE MANAGERS TASK RUNNERS SUMMARY 3 Angular in a Nutshell ANGULAR CONCEPTS THE LANGUAGE OF ANGULAR SETTING UP AN ANGULAR PROJECT THE STRUCTURE OF AN ANGULAR APP DATA BINDING DIRECTIVES SERVICES AND DEPENDECY INJECTION MULTIPLE COMPONENTS INPUT AND OUTPUT PROPERTIES TALKING TO THE BACK END USING ANGULAR WITH ASP.NET MVC VISUAL STUDIO 2017 SUPPORT FOR ANGULAR SUMMARY 4 Bootstrap in a Nutshell INTRODUCTION TO BOOTSTRAP BOOTSTRAP STYLES COMPONENTS JAVASCRIPT CUSTOMIZING BOOTSTRAP WITH LESS BOOTSTRAP SUPPORT IN VISUAL STUDIO 2017 AND ASP.NET CORE SUMMARY 5 Managing Dependencies with NuGet and Bower GENERAL CONCEPTS NUGET NPM (NODE.JS PACKAGE MANAGER) BOWER SUMMARY 6 Building Your Application with Gulp and webpack WHAT FRONT‐END BUILD SYSTEMS ARE FOR A DEEPER LOOK AT GULP INTRODUCTION TO WEBPACK VISUAL STUDIO 2017 AND BUILD SYSTEMS SUMMARY 7 Deploying ASP.NET Core THE NEW HOSTING MODEL OF ASP.NET CORE INSTALLING ON INTERNET INFORMATION SERVICES ON PREMISE -

Rxada: an Ada Implementation of the Reactivex API - 1 PREVIOUSLY, in ADA-EUROPE 2007
RxAda: An Ada implementation of the ReactiveX API Alejandro R. Mosteo 2017-jun-13 2017-jun-13 - RxAda: An Ada implementation of the ReactiveX API - 1 PREVIOUSLY, IN ADA-EUROPE 2007... SANCTA: An Ada 2005 General-Purpose Architecture for Mobile Robotics Research 2017-jun-13 - RxAda: An Ada implementation of the ReactiveX API - 2 ABOUT ME Robotics, Perception, and Real-Time group (RoPeRT) http://robots.unizar.es/ Universidad de Zaragoza, Spain 2017-jun-13 - RxAda: An Ada implementation of the ReactiveX API - 3 CONTENTS • Motivation • What is ReactiveX – Language agnostic – Java – Ada • RxAda – Design challenges/decisions – Current implementation status – Future steps 2017-jun-13 - RxAda: An Ada implementation of the ReactiveX API - 4 PERSONAL MOTIVATION • Android development – Questionable design decisions for background tasks that interact with the GUI • Found RxJava – Simpler, saner way of doing multitasking – Documented comprehensively – Very active community in the Rx world • Achievable in Ada? – Aiming for the RxJava simplicity of use 2017-jun-13 - RxAda: An Ada implementation of the ReactiveX API - 5 EVENT-DRIVEN / ASYNCHRONOUS SYSTEMS <User drags map> ↓ Find nearby items ↓⌛ Request images ↓⌛↓⌛↓⌛↓⌛ Crop/Process image ↓⌛ Update GUI markers 2017-jun-13 - RxAda: An Ada implementation of the ReactiveX API - 6 OVERVIEW Event-driven systems ↓ Reactive Programming (philosophy) ↓ ReactiveX / Rx (specification) ↓ Rx.Net, RxJava, RxJS, RxC++, … ↓ RxAda 2017-jun-13 - RxAda: An Ada implementation of the ReactiveX API - 7 REACTIVE MANIFESTO (2014-sep-16 -

Coverity Static Analysis
Coverity Static Analysis Quickly find and fix Overview critical security and Coverity® gives you the speed, ease of use, accuracy, industry standards compliance, and quality issues as you scalability that you need to develop high-quality, secure applications. Coverity identifies code critical software quality defects and security vulnerabilities in code as it’s written, early in the development process when it’s least costly and easiest to fix. Precise actionable remediation advice and context-specific eLearning help your developers understand how to fix their prioritized issues quickly, without having to become security experts. Coverity Benefits seamlessly integrates automated security testing into your CI/CD pipelines and supports your existing development tools and workflows. Choose where and how to do your • Get improved visibility into development: on-premises or in the cloud with the Polaris Software Integrity Platform™ security risk. Cross-product (SaaS), a highly scalable, cloud-based application security platform. Coverity supports 22 reporting provides a holistic, more languages and over 70 frameworks and templates. complete view of a project’s risk using best-in-class AppSec tools. Coverity includes Rapid Scan, a fast, lightweight static analysis engine optimized • Deployment flexibility. You for cloud-native applications and Infrastructure-as-Code (IaC). Rapid Scan runs decide which set of projects to do automatically, without additional configuration, with every Coverity scan and can also AppSec testing for: on-premises be run as part of full CI builds with conventional scan completion times. Rapid Scan can or in the cloud. also be deployed as a standalone scan engine in Code Sight™ or via the command line • Shift security testing left. -

Santiago Quintero Pabón –
LIX - École Polytechnique Palaiseau Santiago Quintero France Æ +33 (0) 7 67 39 73 30 Pabón Q [email protected] Contact Information Last Name: Quintero Pabón Given Name: Santiago Birth Date: 21-oct-1994 Nationality: Colombian Education Pontificia Universidad Javeriana Cali, CO + Five years B.Sc. Degree in Computer Science and Engineering, (equivalent to a master degree) 2012-2017 École Polytechnique Palaiseau, FR + PhD in Computer Sciences, Thesis: "Foundational approach to computation in today’s systems" 2018-Current Supervisors: Catuscia Palamidessi, Frank Valencia. Work Experience COMETE at LIX, École Polytechnique Palaiseau, FR + PhD Student 2018-Current AVISPA research group at Pontificia Universidad Javeriana Cali, CO + Research Assistant 2018 PORTAL ACTUALICESE.COM S.A.S. Cali, CO + Development Analyst 2017-2018 COMETE research group at Inria-Saclay Palaiseau, FR + Research Intern November 2017 Pontificia Universidad Javeriana Cali, CO + Teaching Assistant 2014-2016 Teaching Assistant....................................................................................................... Courses: Introduction to Programming, Programming Fundamentals and Structures, Logic in Computer Science, Computability and Formal Languages, Introduction to Systems Modeling. Major Projects............................................................................................................. + October 2015 - June 2016: ’Financial inclusion for the emerging middle class in Colombia’ Designed, prototyped and developed a financial -

Rxpy Documentation Release 3.1.1
RxPY Documentation Release 3.1.1 Dag Brattli Jul 16, 2020 CONTENTS 1 Installation 3 2 Rationale 5 3 Get Started 7 3.1 Operators and Chaining.........................................8 3.2 Custom operator.............................................9 3.3 Concurrency............................................... 10 4 Migration 15 4.1 Pipe Based Operator Chaining...................................... 15 4.2 Removal Of The Result Mapper..................................... 16 4.3 Scheduler Parameter In Create Operator................................. 16 4.4 Removal Of List Of Observables.................................... 17 4.5 Blocking Observable........................................... 17 4.6 Back-Pressure.............................................. 18 4.7 Time Is In Seconds............................................ 18 4.8 Packages Renamed............................................ 18 5 Operators 19 5.1 Creating Observables........................................... 19 5.2 Transforming Observables........................................ 19 5.3 Filtering Observables........................................... 20 5.4 Combining Observables......................................... 20 5.5 Error Handling.............................................. 20 5.6 Utility Operators............................................. 21 5.7 Conditional and Boolean Operators................................... 21 5.8 Mathematical and Aggregate Operators................................. 21 5.9 Connectable Observable Operators.................................. -

ASP.NET Core 2 and Angular 5
www.EBooksWorld.ir ASP.NET Core 2 and Angular 5 Full-stack web development with .NET Core and Angular Valerio De Sanctis BIRMINGHAM - MUMBAI ASP.NET Core 2 and Angular 5 Copyright © 2017 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: November 2017 Production reference: 1221117 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78829-360-0 www.packtpub.com Credits Author Copy Editor Valerio De Sanctis Shaila Kusanale Reviewers Project Coordinator Ramchandra Vellanki Devanshi Doshi Juergen Gutsch Commissioning Editor Proofreader Ashwin Nair Safis Editing Acquisition Editor Indexer Reshma Raman Rekha Nair Content Development Editor Graphics Onkar Wani Jason Monteiro Technical Editor Production Coordinator Akhil Nair Aparna Bhagat About the Author Valerio De Sanctis is a skilled IT professional with over 12 years of experience in lead programming, web-based development, and project management using ASP.NET, PHP, and Java. -

Learning Objectives in This Part of the Module
Applying Key Methods in the Single Class (Part 3) Douglas C. Schmidt [email protected] www.dre.vanderbilt.edu/~schmidt Professor of Computer Science Institute for Software Integrated Systems Vanderbilt University Nashville, Tennessee, USA Learning Objectives in this Part of the Lesson • Recognize key methods in the Random random = new Random(); Single class & how they are applied in the case studies Single<BigFraction> m1 = makeBigFraction(random); • Case study ex1 Single<BigFraction> m2 = • Case study ex2 makeBigFraction(random); • Case study ex3 return m1 .zipWith(m2, return Single BigFraction::add) .just(BigFractionUtils .makeBigFraction(...) .doOnSuccess .multiply(sBigReducedFrac)) (mixedFractionPrinter) .subscribeOn .then(); (Schedulers.parallel()); See github.com/douglascraigschmidt/LiveLessons/tree/master/Reactive/Single/ex32 Applying Key Methods in the Single Class in ex3 3 Applying Key Methods in the Single Class in ex3 • ex3 shows how to apply RxJava Random random = new Random(); features asynchronously to perform various Single operations Single<BigFraction> m1 = makeBigFraction(random); • e.g., subscribeOn(), doOnSuccess(), Single<BigFraction> m2 = ignoreElement(), just(), zipWith(), & makeBigFraction(random); Schedulers.computation() return m1 return Single .zipWith(m2, .just(BigFractionUtils BigFraction::add) .makeBigFraction(...) .multiply(sReducedFrac)) .doOnSuccess .doOnSuccess(fractionPrinter) (mixedFractionPrinter) .subscribeOn (Schedulers.computation()); .ignoreElement(); See github.com/douglascraigschmidt/LiveLessons/tree/master/Reactive/Single/ex34 -

Interactive Development Environment for Probabilistic Programming
Maria I. Gorinova Interactive Development Environment for Probabilistic Programming Computer Science Tripos, Part II Clare College May 14, 2015 Proforma Name and College: Maria I. Gorinova, Clare College Project Title: Interactive Development Environment for Probabilistic Programming Examination: Computer Science Tripos Part II, 2015 Word Count: 119021 Project Originator: Alan Blackwell and Advait Sarkar Supervisor: Advait Sarkar Original Aims of the Project To implement an interactive development environment, which allows the pro- grammer to use the probabilistic programming framework Infer.NET. The en- vironment must support visualisations of the graphical models described by the source code, as well as of the probability density functions of random variables that have been declared. In addition, the environment must be live, meaning it provides run-time feedback about the execution of the source code. Update must be edit-triggered, meaning that re-compilation occurs when the code is changed, without the compiler having to be explicitly invoked by the user. Work Completed The work outlined in the original project proposal was successfully implemented, resulting in an IDE which meets all success criteria. In addition, several small features such as text highlighting and code navigation were added to the user interface. A user study was conducted to evaluate the usability of the software. The environment proves to significantly improve users' experience by reducing the probabilistic programming tasks completion time and the level of confusion -

Reactive Stream Processing for Data-Centric Publish/Subscribe
Reactive Stream Processing for Data-centric Publish/Subscribe Shweta Khare, Kyoungho An, Aniruddha Gokhale Sumant Tambe, Ashish Meena Dept of EECS, Vanderbilt University Real-Time Innovations Nashville, TN 37212, USA Sunnyvale, CA 94089, USA {shweta.p.khare,kyoungho.an,a.gokhale}@vanderbilt.edu {sumant,ashish}@rti.com ABSTRACT 1. INTRODUCTION The Internet of Things (IoT) paradigm has given rise to The Internet of Things (IoT) is a significant expansion of a new class of applications wherein complex data analytics the Internet to include physical devices; thereby bridging the must be performed in real-time on large volumes of fast- divide between the physical world and cyberspace. These moving and heterogeneous sensor-generated data. Such data devices or \things" are uniquely identifiable, fitted with sen- streams are often unbounded and must be processed in a sors and actuators, which enable them to gather informa- distributed and parallel manner to ensure timely process- tion about their environment and respond intelligently [8]. ing and delivery to interested subscribers. Dataflow archi- The Industrial IoT (IIoT){distinct from consumer IoT{will tectures based on event-based design have served well in help realize critical infrastructures, such as smart-grids, in- such applications because events support asynchrony, loose telligent transportation systems, advanced manufacturing, coupling, and helps build resilient, responsive and scalable health-care tele-monitoring, etc. Industrial IoT are also applications. However, a unified programming model for called Cyber-Physical Systems (CPSs). They share sev- event processing and distribution that can naturally com- eral key cross-cutting aspects. First, they are often large- pose the processing stages in a dataflow while exploiting the scale, distributed systems comprising several, potentially inherent parallelism available in the environment and com- mobile, publishers of information that produce large volumes putation is still lacking.