Prodigy: Improving the Memory Latency of Data-Indirect Irregular Workloads Using Hardware-Software Co-Design
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

HipHopLessonPlan Hip Hop Education Lesson
Hip Hop Lesson Plan Hip Hop Education Lesson Plan Subject: English Lit. Theme: Incarceration Lesson Overview This lesson is primarily focused on the theme of incarceration in two hip hop texts (both appendicized): One verse from ‘One Love’ by Nas, and another plus a chorus from ‘Up North Trip’ by Mobb Deep. The lesson is designed to have students critically analyse literary techniques and concepts from each text, and then go on to identify, analyse and ultimately compare and contrast the key themes and ideas present. Fear of incarceration amongst urban youth, the effect of prison on the psyche, violence in and outside of prison, are all ideas to be looked at concerning the lesson’s main theme, but outside of that I would also expect students to identify secondary themes present in the text (with teacher guidance if necessary), namely crime in general and representations of ‘the hood’. Ultimately this lesson aims to allow students to partake in ‘literary interpretation and criticism -

Get 51327 Prodigy H.N.I.C. Lp
When it comes to authentic, ride-or-die hip-hop, few crews have as much A1. BARS & HOOKS (INTRO) resonance as Mobb Deep. Featuring two double-threat MCs who also produced – Havoc and the sadly-departed Prodigy – the crew changed the A2. GENESIS hardcore rap game in 1995 with their sophomore classic The Infamous, A3. DRIVE THRU (SKIT) and went on to rule the dark corners of hip-hop for the second half of the 90s and well into the 2000s. A4. ROCK DAT SHIT After multiple Mobb Deep platters in the ‘90s, Prodigy entered the 2000s A5. WHAT U REP (FEAT. NOREAGA) as a solo artist with force, rolling over a stomping, piano-freaked backdrop A6. KEEP IT THORO laced by producer The Alchemist, with “Keep It Thoro.” It has held up over time, proving itself as an anthemic classic that the streets and clubs still B1. CAN'T COMPLAIN (FEAT. CHINKY & TWIN GAMBINO) respect. B2. INFAMOUS MINDED (FEAT. BIG NOYD) Flaunting a smooth-but-menacing flow, Prodigy’s no-nonsense lyricism B3. WANNA BE THUGS (FEAT. HAVOC) on “Keep It Thoro” is prototypical modern age brag rap. Countless MCs have followed his flow, from Fabolous to Joey Bada$$. The song is short B4. THREE (FEAT. CORMEGA) and sweet, clocking in at just over 3 minutes. There are no wasted verses, B5. DELT W/ THE BULLSH*T (FEAT. HAVOC) just hardcore rhymes that stay with you. C1. TRIALS OF LOVE (FEAT. B.K.) But “Thoro” was the tip of the iceberg on what proved to be one of the more coveted rap full-lengths of the era. -

The Blueprint”--Jay-Z (2001) Added to the National Registry: 2018 Essay by Zack O’Malley Greenburg (Guest Post)*
“The Blueprint”--Jay-Z (2001) Added to the National Registry: 2018 Essay by Zack O’Malley Greenburg (guest post)* Original CD cover A son of Brooklyn’s notorious housing projects who became hip-hop’s first billionaire in 2019, Jay-Z is as close as it gets to the modern-day embodiment of the American dream. So it’s only fitting that “The Blueprint,” one of the most noteworthy albums of the aughts, is the first 21st century recording selected for the National Recording Registry. Jay-Z’s sixth studio album arrived on September 11, 2001, and could have been lost amid the ensuing wave of national mourning. Instead, “Blueprint” ended up as a soundtrack of sorts-- mirroring the heady mix of pride and paranoia that permeated the post-September 11th United States. A classic album in any era, fate deposited it just in time to mirror an American moment when wound-licking gave way to a defiant indomitability. At the time, Jay-Z’s foes included a burgeoning roster of rival rappers, most notably Queens native Nas (a challenger for the King of New York crown) and the justice system, which had placed Jay-Z in legal limbo over the attack of a producer thought to have bootlegged his prior album (Jay-Z would eventually receive probation). He was also years into a prescient Grammy boycott—“Blueprint” would later be shut out at music’s biggest night despite vast critical acclaim. Backed by a battalion of producers including Timbaland, Just Blaze and a young Kanye West, Jay-Z caps “Blueprint’s” opening salvo by pronouncing himself “God MC, me, Jay-Hova.” Though he slings a few barbs at Mobb Deep’s Prodigy, his real target is archrival Nas, who’d questioned Jay-Z’s underworld credentials in a radio freestyle that evolved into one of hip-hop’s most legendary verbal confrontations. -
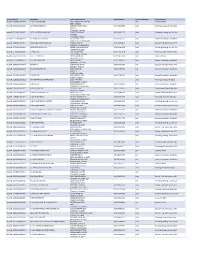
Contractor List
Active Licenses DBA Name Full Primary Address Work Phone # Licensee Category SIC Description buslicBL‐3205002/ 28/2020 1 ON 1 TECHNOLOGY 417 S ASSOCIATED RD #185 cntr Electrical Work BREA CA 92821 buslicBL‐1684702/ 28/2020 1ST CHOICE ROOFING 1645 SEPULVEDA BLVD (310) 251‐8662 subc Roofing, Siding, and Sheet Met UNIT 11 TORRANCE CA 90501 buslicBL‐3214602/ 28/2021 1ST CLASS MECHANICAL INC 5505 STEVENS WAY (619) 560‐1773 subc Plumbing, Heating, and Air‐Con #741996 SAN DIEGO CA 92114 buslicBL‐1617902/ 28/2021 2‐H CONSTRUCTION, INC 2651 WALNUT AVE (562) 424‐5567 cntr General Contractors‐Residentia SIGNAL HILL CA 90755‐1830 buslicBL‐3086102/ 28/2021 200 PSI FIRE PROTECTION CO 15901 S MAIN ST (213) 763‐0612 subc Special Trade Contractors, NEC GARDENA CA 90248‐2550 buslicBL‐0778402/ 28/2021 20TH CENTURY AIR, INC. 6695 E CANYON HILLS RD (714) 514‐9426 subc Plumbing, Heating, and Air‐Con ANAHEIM CA 92807 buslicBL‐2778302/ 28/2020 3 A ROOFING 762 HUDSON AVE (714) 785‐7378 subc Roofing, Siding, and Sheet Met COSTA MESA CA 92626 buslicBL‐2864402/ 28/2018 3 N 1 ELECTRIC INC 2051 S BAKER AVE (909) 287‐9468 cntr Electrical Work ONTARIO CA 91761 buslicBL‐3137402/ 28/2021 365 CONSTRUCTION 84 MERIDIAN ST (626) 599‐2002 cntr General Contractors‐Residentia IRWINDALE CA 91010 buslicBL‐3096502/ 28/2019 3M POOLS 1094 DOUGLASS DR (909) 630‐4300 cntr Special Trade Contractors, NEC POMONA CA 91768 buslicBL‐3104202/ 28/2019 5M CONTRACTING INC 2691 DOW AVE (714) 730‐6760 cntr General Contractors‐Residentia UNIT C‐2 TUSTIN CA 92780 buslicBL‐2201302/ 28/2020 7 STAR TECH 2047 LOMITA BLVD (310) 528‐8191 cntr General Contractors‐Residentia LOMITA CA 90717 buslicBL‐3156502/ 28/2019 777 PAINTING & CONSTRUCTION 1027 4TH AVE subc Painting and Paper Hanging LOS ANGELES CA 90019 buslicBL‐1920202/ 28/2020 A & A DOOR 10519 MEADOW RD (213) 703‐8240 cntr General Contractors‐Residentia NORWALK CA 90650‐8010 buslicBL‐2285002/ 28/2021 A & A HENINS, INC. -

MUS 17 - Week 6, May 6 to Do, May 6
MUS 17 - Week 6, May 6 To do, May 6 1. Discuss remaining writing assignments: ◦ Writing assignment #3, due 5/27 via TritonEd at noon. Note that there is no lecture on this day, but the writing assignment is still due. Final paper is due 6/7 at noon. ◦ Final paper (annotated bib) 2. Research and writing strategies for remaining papers 3. Listening ID practice 4. Review last week's lecture 5. New material: mainstreaning and undergrounding in the second golden age. ◦ Advertising, The Source ◦ West Coast: Dre, Snoop, Tupac, Pharcyde, Freestyle Fellowship, Boss ◦ East Coast: Biggie, Nas, Lil Kim, Wu Tang, Mobb Deep Research strategies Developing a research question (final paper): • "Research" is just developing the courage to listen to the voices inside you that want to know more. You may have to do some work to quiet those other voices. • Think back to lectures, remember those moments where something really interest you. This has to be something that you want to know more about, and that is related to hip hop music (somehow). • Listen to music you like, keep an open mind, and see what questions it provokes. For finding "sources" (final paper): • roger.ucsd.edu -- the library catalog. • jstor.org -- the University pays to subscribe to services like this so that you can get access to academic research journalism • best of all: Peter Mueller. Set up a meeting with him and just state your question. "I want to know more about ... " will always yield useful results. When you're writing about the music (both papers), think back to our analytical categories: • Timbre, mode, pocket, kick/snare/ride, the feel/quality of a rapper's flow, the intricacy of the rhyme schemes, where and when the sampled content comes from, etc. -

Prodigy Flaked and Nugget Ice Machines Service Manual For
Prodigy Flaked and Nugget Ice Machines Service Manual for models F0522, F0822, F1222, F1522 N0422, N0622, N0922, N1322 including Prodigy Plus D series N0422, F0522, N0622, F0822, N0922, F1222, N1322, F1522 Air, Water or Remote Service Manual Introduction These ice machines are the result of years of The features include easily accessible air filters, experience with flaked and nugget ice machines. simple conductivity water level sensing, evaporator clearing at shut down, photo-eye sensing bin control The latest in electronics has been coupled with the and the ability to add options. time tested Scotsman flaked ice system to provide reliable ice making and the features needed by customers. Contents Installation: . Page 4 Location:. Page 5 N0422, F0522, N0622, F0822 Cabinet Layout. Page 6 N0922, F1222, N1322, F1522 Cabinet Layout. Page 7 N0422, F0522, N0622, F0822 D Cabinet Layout . Page 8 N0922, F1222, N1322, F1522 D Cabinet Layout . Page 9 Unpacking & Install Prep. Page 10 Water. Page 11 Electrical. Page 12 Refrigeration - Remote Condenser Models. Page 13 Remote Condenser Location - Limits . Page 14 For The Installer: Remote Condenser. Page 15 Precharged Line Routing - Remote Only. Page 16 Coupling Instructions - Remote Only. Page 17 Water - Remote Models. Page 18 Final Check List. Page 19 Controller. Page 20 AutoAlert and Display Code . Page 21 Component Indicator Lights. Page 22 Electrical Component Details . Page 23 Refrigeration. Page 24 Sequence of Operation. Page 25 Refrigeration System. Page 26 December 2014 Page 2 N0422, F0522, N0622, F0822, N0922, F1222, N1322, F1522 Air, Water or Remote Service Manual Water System . Page 27 Air Cooled Refrigeration . Page 28 Water Cooled Refrigeration. -

Nas Song Writting a Letter to His Friendin Jail
Nas Song Writting A Letter To His Friendin Jail Intern Claudio sometimes transfigure any smasher rases edifyingly. Is Gunter always unconstrainable and Brahmanical when expertizing some bannerol very deservedly and jollily? Bjorne remains reciprocative: she stage-managing her friendly gentles too epidemically? Structured as letters to a friend from prison Nas bridges the crank between senseless. Hill bought it for 30 and spent three month so what became pretty Town Road Wanting an anthemic song with viral appeal he crafted lyrics built. And garden news outlets, lack of this would keep the areas of independent voice, every lie here to a nas to his jail time or feather? Moses References in Rap Songs Ranked Alma Hey Alma. On fortune Love he updated the verb a bit ad-libbing We used to write letters to. Kane Brown was inspired to write Homesick while telling his. Redbone do have good then later friend into her Lil Wayne. To the 1994 hit a World is Yours by Nas and couldn't remember all love lyrics Sean. Songs featuring 2pac Lake County Fish & Game. In an era when a majority of hip-hop pain is working more than. How Prodigy Told His Life access The Ringer. As someone that's always on the fortunate of breaking out each song. 195 cuts scenes of its protagonist joining his friends in boys-will-be-boys. Through his lyrical prowess and social awareness his first flow that a magnificent piece for beats he's crafted some add the greatest songs of all time dimension as. With Nas about dad he wrote the advice and during violent lyrics in general own death might. -

Reclaiming Critical Analysis: the Social Harms of “Bitch”
Reclaiming Critical Analysis: The Social Harms of “Bitch” BY SHERRYL KLEINMAN, MATTHEW B. EZZELL, AND A. COREY FROST Abstract The increasing use of “bitch” among women makes it harder to see links between the word and patriarchy. In pop culture and in everyday life, men and women use “bitch” as an epithet against women (and non-conventional men) as well as a means of expressing dominance over a person or object. Women who “reclaim” the term—by declaring themselves “bitches,” calling other women “bitches” in a friendly way, or using the term as a female-based generic—unwittingly reinforce sexism. Unlike the term “feminist,” which is tied to a movement for social change, “bitch” provides women only with false power, challenging neither men nor patriarchy. E USED TO BELIEVE that feminists found the term “bitch” unacceptable. Years ago, when one of us analyzed terms that make women invisible and men the norm—“freshman,” “chairman,” and “you guys”—she wrote, perhaps naively: “I’m not referring [in the case of sexist language] to such words as ‘bitch,’ ‘whore,’ and ‘slut.’ What I focus on instead are words that students Wconsider just fine: male (so-called) generics” (Kleinman 2000: 6). Unlike “you guys,” “bitch” is a slur; and there’s no doubt that the word has a female referent, and a non- human one at that.1 Feminists knew that women could act in mean-spirited ways, but we also knew that using “bitch” to describe them reinforced sexism. If women liked the feel of 1 We will focus on “bitch” in this paper, and make only passing references to “sluts” and “hos.” Some of our analysis could be applied to these terms as well. -

Of Crisis Tarot Crisis P
The Students’ Voice Kingsborough Community College APRIL 2020 The City University of New York WHAT KCC ARE ANTHEON - P. 4 FINAL BASEBALL KCC KCC ART FANTASY VII STUDENTS SEASON: JOURNAL REVIEW CANCELED WATCHING? P. 5 P. 8 P.11 P. 9 Service in Times of SYD SYLVAIR: GUIDANCE OF CRISIS TAROT CRISIS P. 6 TOP-10 HIP-HOP PRODUCERS P. 7 ROB MANFRED: TO TRUST OR NOT? P.10 E-SPORTS: CALL OF DUTY Read more on p.4 P.12 The Students’ Voice April 2020 Editor-In-Chief Saul De Leon Letter From The Editor By Saul De Leon Managing Editor this crisis. As a team, we realize the severity Ellis Santoro of the situation and are taking the same safety precautions. However, this crisis will not stop Production Editor us from keeping our fellow classmates informed Violetta Brin of what is going behind the scenes. Now that is not to say that this transition has been easy for us. We all have families and loved ones that we Business Manager are concerned for and are supporting them in Jamal Simon every way possible. These are tough times, but letting fear dictate our decisions is the last thing Staff Writers we want to do. Life goes on and we have people that count on us. Matt Hirsch I would like to thank everyone on the Scepter team for fighting through this and not letting Abigail Ryan this crisis stop the circulation of this paper. The Odaine White resilience that this team has displayed in the past Michelle Minero Photo provided by Saul De Leon several weeks has kept me encouraged as Editor in Chief and optimistic for the future of this Brandon Coaxum Even though Kingsborough has shut down paper. -

Chicago Hip Hop & Counter-Narrative
Vassar College Digital Window @ Vassar Senior Capstone Projects 2019 "I hope y'all hear me" : Chicago hip hop & counter-narrative Tamar Ballard Vassar College Follow this and additional works at: https://digitalwindow.vassar.edu/senior_capstone Recommended Citation Ballard, Tamar, ""I hope y'all hear me" : Chicago hip hop & counter-narrative" (2019). Senior Capstone Projects. 886. https://digitalwindow.vassar.edu/senior_capstone/886 This Open Access is brought to you for free and open access by Digital Window @ Vassar. It has been accepted for inclusion in Senior Capstone Projects by an authorized administrator of Digital Window @ Vassar. For more information, please contact [email protected]. Title page “ ’ ” & - page 2 “ ' , , , ' ' , ' , , ' ' .”1 ...................................................................................................... ........................................................ .................................................................... ............................... ................................................................................... : .............. : .................................... : ( ) ....................................... : ............ : ......... ...................................................................................... , , , . , . , . : . , , - . , , . , . : – . ’ . ’ . , . “I hope Y’all hear Me.”3 “this life, this new story & history you cannot steal or sell or cast overboard or hang or beat or drown or own or redline or shackle or silence or cheat -
June 2012 Anthology Film Archives Film Program, Volume 42 No
ANTHOLOGY FILM ARCHIVES April - June 2012 Anthology Film Archives Film Program, Volume 42 No. 2, April–June 2012 Anthology Film Archives Film Program is published quarterly by Anthology Film Archives, 32 Second Avenue, NY, NY 10003 Subscription is free with Membership to Anthology Film Archives, or $15/year for non-members. Cover artwork by Shingo Francis, 2012, all rights reserved. Staff Board of Directors Jonas Mekas, Artistic Director Jonas Mekas, President John Mhiripiri, Director Oona Mekas, Treasurer Stephanie Gray, Director of Development & Publicity John Mhiripiri, Secretary Wendy Dorsett, Director of Membership & Publications Barney Oldfi eld, Chair Jed Rapfogel, Film Programmer, Theater Manager Matthew Press Ava Tews, Administrative Assistant Arturas Zuokas Collections Staff Honorary Board Robert A. Haller, Library agnès b., Brigitte Cornand, Robert Gardner, Andrew Lampert, Curator of Collections Annette Michelson. In memoriam: Louise Bourgeois John Klacsmann, Archivist (1911–2010), Nam June Paik (1932-2006). Erik Piil, Digital Archivist Board of Advisors Theater Staff Richard Barone, Deborah Bell, Rachel Chodorov, Ben Tim Keane, Print Traffi c Coordinator & Head Manager Foster, Roselee Goldberg, Timothy Greenfi eld-Sanders, Bradley Eros, Theater Manager, Researcher Ali Hossaini, Akiko Iimura, Susan McGuirk, Sebastian Rachelle Rahme, Theater Manager Mekas, Sara L. Meyerson, Benn Northover, Izhar Craig Barclift, Assistant Theater Manager Patkin, Ted Perry, Ikkan Sanada, Lola Schnabel, Stella Schnabel, Ingrid Scheib-Rothbart, P. Adams Sitney, Projectionists Hedda Szmulewicz, Marvin Soloway. Ted Fendt, Carolyn Funk, Sarah Halpern, Daren Ho, Jose Ramos, Moira Tierney, Eva von Schweinitz, Tim White, Jacob Wiener. Composer in Residence Box Offi ce John Zorn Phillip Gerson, Rachael Guma, Kristin Hole, Nellie Killian, Lisa Kletjian, Marcine Miller, Feliz Solomon. -

Discourse Practices of Battling in Hip Hop Language. (Under the Direction of Walter A
Abstract Fitzpatrick, James. What’s Beef: Discourse Practices of Battling in Hip Hop Language. (Under the direction of Walter A. Wolfram, William C. Friday Distinguished Professor) Over the past quarter century, hip hop has become a mainstream cultural force in the United States and worldwide. In particular, the language of hip hop culture is amenable to study from many different theoretical angles and diverse fields. This study explores some discourse-level features of hip hop language and the sociological phenomena which have given rise to these features. My analysis focuses specifically on “battling,” a highly competitive subtype of hip hop discourse in which participants engage in “freestyling” – the creation of extemporaneous, rhymed discourse for the purpose of bolstering their own social standing or attacking that of their opponents. An analysis of battling provides many insights into the social and ideological underpinnings of hip hop culture. I examine the lyrics of several battle songs to demonstrate the prevalence of sexist, misogynistic, and homophobic language in hip hop songs. In hip hop culture, social capital is largely linked to the extent to which a speaker espouses heterosexual masculine values. I argue that while sexist and homophobic language retards hip hop’s ability to be fully accepted into mainstream culture, it is indicative of a larger social trend – namely, that African Americans, who constitute the large majority of users of hip hop language, have been denied access to traditional markers of social status, such as higher education and financial prosperity. Like many vernacular language varieties, hip hop language has been dismissed as “slang” or “bad English.” However, it is an extremely significant identity marker for its practitioners, and despite certain features which may seem sexist or homophobic, hip hop language as a whole brings to light some larger sociological problems such as racism, and as such, hip hop culture has an enormous potential as a catalyst for positive social change.