BIMM-143: INTRODUCTION to BIOINFORMATICS (Lecture 3)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Extracellular Neuroglobin As a Stress-Induced Factor Activating
cancers Article Extracellular Neuroglobin as a Stress-Induced Factor Activating Pre-Adaptation Mechanisms against Oxidative Stress and Chemotherapy-Induced Cell Death in Breast Cancer 1, , 1, 2 1 Marco Fiocchetti * y, Virginia Solar Fernandez y, Marco Segatto , Stefano Leone , Paolo Cercola 3, Annalisa Massari 3, Francesco Cavaliere 3 and Maria Marino 1,* 1 Department of Science, University Roma Tre, Viale Guglielmo Marconi 446, I-00146 Roma, Italy; [email protected] (V.S.F.); [email protected] (S.L.) 2 Department of Biosciences and Territory, University of Molise, Contrada Fonte Lappone, 86090 Pesche (IS), Italy; [email protected] 3 Division of Senology, Belcolle Hospital, Str. Sammartinese, 01100 Viterbo, Italy; [email protected] (P.C.); [email protected] (A.M.); [email protected] (F.C.) * Correspondence: marco.fi[email protected] (M.F.); [email protected] (M.M.); Tel.: +39-06-5733-6455 (M.F.); +39-06-5733-6320 (M.M.); Fax: +39-06-5733-6321 (M.F. & M.M.) These authors contributed equally to this work. y Received: 27 July 2020; Accepted: 26 August 2020; Published: 29 August 2020 Abstract: Components of tumor microenvironment, including tumor and/or stromal cells-derived factors, exert a critical role in breast cancer (BC) progression. Here we evaluated the possible role of neuroglobin (NGB), a monomeric globin that acts as a compensatory protein against oxidative and apoptotic processes, as part of BC microenvironment. The extracellular NGB levels were evaluated by immunofluorescence of BC tissue sections and by Western blot of the culture media of BC cell lines. -

Hemoglobin, Myoglobin and Neuroglobin in Endogenous Thiosulfate Production Processes
International Journal of Molecular Sciences Review The Role of Hemoproteins: Hemoglobin, Myoglobin and Neuroglobin in Endogenous Thiosulfate Production Processes Anna Bilska-Wilkosz *, Małgorzata Iciek, Magdalena Górny and Danuta Kowalczyk-Pachel Chair of Medical Biochemistry, Jagiellonian University Collegium Medicum ,7 Kopernika Street, Kraków 31-034, Poland; [email protected] (M.I.); [email protected] (M.G.); [email protected] (D.K.-P.) * Correspondence: [email protected]; Tel.: +48-12-4227-400; Fax: +48-12-4223-272 Received: 5 May 2017; Accepted: 16 June 2017; Published: 20 June 2017 Abstract: Thiosulfate formation and biodegradation processes link aerobic and anaerobic metabolism of cysteine. In these reactions, sulfite formed from thiosulfate is oxidized to sulfate while hydrogen sulfide is transformed into thiosulfate. These processes occurring mostly in mitochondria are described as a canonical hydrogen sulfide oxidation pathway. In this review, we discuss the current state of knowledge on the interactions between hydrogen sulfide and hemoglobin, myoglobin and neuroglobin and postulate that thiosulfate is a metabolically important product of this processes. Hydrogen sulfide oxidation by ferric hemoglobin, myoglobin and neuroglobin has been defined as a non-canonical hydrogen sulfide oxidation pathway. Until recently, it appeared that the goal of thiosulfate production was to delay irreversible oxidation of hydrogen sulfide to sulfate excreted in urine; while thiosulfate itself was only an intermediate, transient metabolite on the hydrogen sulfide oxidation pathway. In the light of data presented in this paper, it seems that thiosulfate is a molecule that plays a prominent role in the human body. Thus, we hope that all these findings will encourage further studies on the role of hemoproteins in the formation of this undoubtedly fascinating molecule and on the mechanisms responsible for its biological activity in the human body. -

Adult, Embryonic and Fetal Hemoglobin Are Expressed in Human Glioblastoma Cells
514 INTERNATIONAL JOURNAL OF ONCOLOGY 44: 514-520, 2014 Adult, embryonic and fetal hemoglobin are expressed in human glioblastoma cells MARWAN EMARA1,2, A. ROBERT TURNER1 and JOAN ALLALUNIS-TURNER1 1Department of Oncology, University of Alberta and Alberta Health Services, Cross Cancer Institute, Edmonton, AB T6G 1Z2, Canada; 2Center for Aging and Associated Diseases, Zewail City of Science and Technology, Cairo, Egypt Received September 7, 2013; Accepted October 7, 2013 DOI: 10.3892/ijo.2013.2186 Abstract. Hemoglobin is a hemoprotein, produced mainly in Introduction erythrocytes circulating in the blood. However, non-erythroid hemoglobins have been previously reported in other cell Globins are hemo-containing proteins, have the ability to types including human and rodent neurons of embryonic bind gaseous ligands [oxygen (O2), nitric oxide (NO) and and adult brain, but not astrocytes and oligodendrocytes. carbon monoxide (CO)] reversibly. They have been described Human glioblastoma multiforme (GBM) is the most aggres- in prokaryotes, fungi, plants and animals with an enormous sive tumor among gliomas. However, despite extensive basic diversity of structure and function (1). To date, hemoglobin, and clinical research studies on GBM cells, little is known myoglobin, neuroglobin (Ngb) and cytoglobin (Cygb) repre- about glial defence mechanisms that allow these cells to sent the vertebrate globin family with distinct function and survive and resist various types of treatment. We have tissue distributions (2). During ontogeny, developing erythro- shown previously that the newest members of vertebrate blasts sequentially express embryonic {[Gower 1 (ζ2ε2), globin family, neuroglobin (Ngb) and cytoglobin (Cygb), are Gower 2 (α2ε2), and Portland 1 (ζ2γ2)] to fetal [Hb F(α2γ2)] expressed in human GBM cells. -

Neuroglobin and Cytoglobin Fresh Blood for the Vertebrate Globin Family
EMBO reports Neuroglobin and cytoglobin Fresh blood for the vertebrate globin family Alessandra Pesce, Martino Bolognesi+, Alessio Bocedi1, Paolo Ascenzi1, Sylvia Dewilde2, Luc Moens2, Thomas Hankeln3 & Thorsten Burmester4 Department of Physics–INFM and Center for Excellence in Biomedical Research, University of Genova, Via Dodecaneso 33, I-16146 Genova, 1Department of Biology, University ‘Roma Tre’, Viale Guglielmo Marconi 446, I-00146 Roma, Italy, 2Department of Biochemistry, University of Antwerp, Universiteitsplein 1, B-2610 Antwerp, Belgium, 3Institute of Molecular Genetics, Johannes Gutenberg University of Mainz, Becherweg 32, D-55099 Mainz and 4Institute of Zoology, Johannes Gutenberg University of Mainz, Müllerweg 6, D-55099 Mainz, Germany Received August 7, 2002; revised October 8, 2002; accepted October 18, 2002 Neuroglobin and cytoglobin are two recently discovered (Wittenberg, 1970, 1992; Antonini and Brunori, 1971; Perutz, members of the vertebrate globin family. Both are intracellular 1979, 1990; Dickerson and Geis, 1983; Bunn and Forget, 1986; proteins endowed with hexacoordinated heme-Fe atoms, in Brunori, 1999; Weber and Vinogradov, 2001; Merx et al., 2002), their ferrous and ferric forms, and display O2 affinities comparable although they can also carry out enzymatic functions (Minning with that of myoglobin. Neuroglobin, which is predominantly et al., 1999; Ascenzi et al., 2001). expressed in nerve cells, is thought to protect neurons from Four types of globin, differing in structure, tissue distribution hypoxic–ischemic injury. It is of ancient evolutionary origin, and likely in function, have been discovered in man and other and is homologous to nerve globins of invertebrates. vertebrates: hemoglobin, myoglobin, neuroglobin and cyto- Cytoglobin is expressed in many different tissues, although at globin. -

Neuroglobin Expression in the Brain: a Story of Tissue Homeostasis Preservation
Molecular Neurobiology (2019) 56:2101–2122 https://doi.org/10.1007/s12035-018-1212-8 Neuroglobin Expression in the Brain: a Story of Tissue Homeostasis Preservation Zoë P. Van Acker1 & Evi Luyckx1 & Sylvia Dewilde1 Received: 22 November 2017 /Accepted: 26 June 2018 /Published online: 10 July 2018 # Springer Science+Business Media, LLC, part of Springer Nature 2018 Abstract After its discovery in 2000, the notion grew that neuroglobin, a neuronal specific heme protein, is involved in cytoprotection. To date, neuroglobin levels have been positively correlated with a beneficial outcome in a plethora of neurotoxic insults, e.g., ischemic and traumatic brain injuries and Alzheimer’s disease. The first part of this review goes further into these changes of neuroglobin expression upon different neuronal insults as well as the underlying regulation. In the second part, we shed light on the mechanisms by which neuroglobin contributes to neuroprotection, being (i) the scavenging and detoxification of reactive oxygen/nitrogen species, (ii) the augmentation of the threshold for apoptosis initiation, (iii) its contribution to an anti-inflammatory milieu, and (iv) tissue regeneration. We also consider different neuroglobin models to address as yet unanswered questions. Based on the recent findings and progress in the field, we invigorate the avenues of neuroglobin in neurological ailments to increase in the coming years. Keywords Neuroglobin . Expression . Neuroprotection . Apoptosis . Inflammation . Neurogenesis Introduction system [4, 5]. Highest expression levels are detected in the mammalian hypothalamus, which shows 100-fold higher tran- Sustainment of homeostasis in the central nervous system scription rates than other key Ngb expression regions as the is essential to support vital physiological functions. -
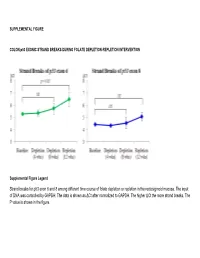
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

Mechanism of Globin X Interactions with Exogenous Ligands and Ligand Accessiblity in Cytoglobin and Neuroglobin
Florida International University FIU Digital Commons FIU Electronic Theses and Dissertations University Graduate School 7-2-2020 Structure Function Relationship in Hexacoordinate Heme Proteins: Mechanism of Globin X Interactions with Exogenous Ligands and Ligand Accessiblity in Cytoglobin and Neuroglobin Ruipeng Lei [email protected] Follow this and additional works at: https://digitalcommons.fiu.edu/etd Part of the Biochemistry Commons, and the Biophysics Commons Recommended Citation Lei, Ruipeng, "Structure Function Relationship in Hexacoordinate Heme Proteins: Mechanism of Globin X Interactions with Exogenous Ligands and Ligand Accessiblity in Cytoglobin and Neuroglobin" (2020). FIU Electronic Theses and Dissertations. 4470. https://digitalcommons.fiu.edu/etd/4470 This work is brought to you for free and open access by the University Graduate School at FIU Digital Commons. It has been accepted for inclusion in FIU Electronic Theses and Dissertations by an authorized administrator of FIU Digital Commons. For more information, please contact [email protected]. FLORIDA INTERNATIONAL UNIVERSITY Miami, Florida STRUCTURE-FUNCTION RELATIONSHIPS IN HEXACOORDINATE HEME PROTEINS: MECHANISM OF GLOBIN X INTERACTIONS WITH EXOGENOUS LIGANDS AND LIGAND ACCESSIBILITY IN CYTOGLOBIN AND NEUROGLOBIN A dissertation submitted in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY in BIOCHEMISTRY by Ruipeng Lei 2020 To: Dean Michael R. Heithaus College of Arts, Sciences and Education This dissertation, written by Ruipeng Lei, and entitled Structure-Function Relationships in Hexacoordinate Heme Proteins: Mechanism of Globin X Interactions with Exogenous Ligands and Ligand Accessibility in Cytoglobin and Neuroglobin, having been approved in respect to style and intellectual content, is referred to you for your judgement. We have read this dissertation and recommend that it be approved. -

Human Brain Neuroglobin Structure Reveals a Distinct Mode of Controlling Oxygen Affinity
Structure, Vol. 11, 1087–1095, September, 2003, 2003 Elsevier Science Ltd. All rights reserved. DOI 10.1016/S0969-2126(03)00166-7 Human Brain Neuroglobin Structure Reveals a Distinct Mode of Controlling Oxygen Affinity Alessandra Pesce,1 Sylvia Dewilde,2 a wide and functionally diversified protein homology Marco Nardini,1 Luc Moens,2 superfamily. Paolo Ascenzi,3 Thomas Hankeln,4 Thorsten Burmester,5 and Martino Bolognesi1,6,* 1Department of Physics—INFM Introduction and Centre for Excellence in Biomedical Research Globins are small respiratory proteins that reversibly University of Genova bind O2 by means of an iron-containing porphyrin ring. Via Dodecaneso 33 Globin-like proteins have been identified in bacteria, I-16146 Genova plants, fungi, and animals (Hardison, 1996, 1998). Most Italy globins are held to sustain O2 supply to the aerobic 2 Department of Biomedical Sciences metabolism of the respiratory chain (Wittenberg, 1992; University of Antwerp Brunori, 1999; Weber and Vinogradov, 2001; Merx et al., Universiteitsplein 1 2002), although they have also been ascribed enzymatic B-2610 Antwerp functions (Minning et al., 1999; Brunori, 2001; Flo¨ gel et Belgium al., 2001). In man and other vertebrates, red blood cell 3 Department of Biology hemoglobin (Hb) transports O2 in the circulatory system. University ‘Roma Tre’ Myoglobin (Mb), typically found in the cardiac and stri- Viale Guglielmo Marconi 446 ated muscles, facilitates O2 diffusion and NO detoxifica- I-00146 Roma tion (Wittenberg, 1970; Perutz, 1979, 1990; Wittenberg Italy and Wittenberg, 1989; Hardison, 1996, 1998; Brunori, 4 Institute of Molecular Genetics 1999; 2001; Flo¨ gel et al., 2001). Neuroglobin (Ngb) has Johannes Gutenberg University of Mainz recently been identified in the vertebrate nervous sys- Becherweg 32 tem (Burmester et al., 2000; Trent et al., 2001). -

Significance of Heme and Heme Degradation in the Pathogenesis Of
International Journal of Molecular Sciences Review Significance of Heme and Heme Degradation in the Pathogenesis of Acute Lung and Inflammatory Disorders Stefan W. Ryter Proterris, Inc., Boston, MA 02118, USA; [email protected] Abstract: The heme molecule serves as an essential prosthetic group for oxygen transport and storage proteins, as well for cellular metabolic enzyme activities, including those involved in mitochondrial respiration, xenobiotic metabolism, and antioxidant responses. Dysfunction in both heme synthesis and degradation pathways can promote human disease. Heme is a pro-oxidant via iron catalysis that can induce cytotoxicity and injury to the vascular endothelium. Additionally, heme can modulate inflammatory and immune system functions. Thus, the synthesis, utilization and turnover of heme are by necessity tightly regulated. The microsomal heme oxygenase (HO) system degrades heme to carbon monoxide (CO), iron, and biliverdin-IXα, that latter which is converted to bilirubin-IXα by biliverdin reductase. Heme degradation by heme oxygenase-1 (HO-1) is linked to cytoprotection via heme removal, as well as by activity-dependent end-product generation (i.e., bile pigments and CO), and other potential mechanisms. Therapeutic strategies targeting the heme/HO-1 pathway, including therapeutic modulation of heme levels, elevation (or inhibition) of HO-1 protein and activity, and application of CO donor compounds or gas show potential in inflammatory conditions including sepsis and pulmonary diseases. Keywords: acute lung injury; carbon monoxide; heme; heme oxygenase; inflammation; lung dis- ease; sepsis Citation: Ryter, S.W. Significance of Heme and Heme Degradation in the Pathogenesis of Acute Lung and Inflammatory Disorders. Int. J. Mol. 1. Introduction Sci. -

Neuroglobin, Cytoglobin, and Myoglobin Contribute to Hypoxia Adaptation of the Subterranean Mole Rat Spalax
Neuroglobin, cytoglobin, and myoglobin contribute to hypoxia adaptation of the subterranean mole rat Spalax Aaron Avivia,1,2, Frank Gerlachb,1, Alma Joela, Stefan Reussc, Thorsten Burmesterd, Eviatar Nevoa,2, and Thomas Hankelnb,2 aInstitute of Evolution, University of Haifa, Mount Carmel, Haifa 31905, Israel; bInstitute of Molecular Genetics, Johannes Gutenberg-University Mainz, D-55099 Mainz, Germany; cInstitute of Microanatomy and Neurobiology, School of Medicine, Johannes Gutenberg-University Mainz, D-55131 Mainz, Germany; and dZoological Institute and Museum, Biocenter Grindel, University of Hamburg, D-20146 Hamburg, Germany Contributed by Eviatar Nevo, November 1, 2010 (sent for review July 2, 2010) The subterranean mole rat Spalax is an excellent model for studying with the hypoxia-sensitive rodent Rattus norvegicus, Spalax survives adaptation of a mammal toward chronic environmental hypoxia. substantially longer at low ambient O2 levels and high CO2 without Neuroglobin (Ngb) and cytoglobin (Cygb) are O2-binding respiratory serious deleterious effects or behavioral changes (6). proteins and thus candidates for being involved in molecular hyp- Hypoxia tolerance mechanisms identified in Spalax as com- oxia adaptations of Spalax. Ngb is expressed primarily in vertebrate pared with R. norvegicus include blood properties, anatomical nerves, whereas Cygb is found in extracellular matrix-producing and biochemical changes in respiratory organs (2, 4), and dif- cells and in some neurons. The physiological functions of both pro- ferences in the structure and function of a growing list of gene products (7–10). Transcription patterns of genes related to hyp- teins are not fully understood but discussed with regard to O2 sup- fi ply, the detoxification of reactive oxygen or nitrogen species, and oxic stress differ interspeci cally in Spalax (5, 11) and between Spalax and rat, involving key players such as erythropoietin (Epo) apoptosis protection. -

Neuroglobin and Cytoglobin: O ATP
Mainz 12/2006 Neuroglobin and Cytoglobin: “Fresh blood“ for the vertebrate globin gene family Thomas Hankeln & Thorsten Burmester Institut für Molekulargenetik, Institut für Zoologie Johannes Gutenberg Universität Mainz Uni Hamburg The task… O2 ATP H2O mitochondrium The problem… large cell, e.g. small cell, e.g. Protozoa e.g. flatworms e.g. insects alveoles erythrocytes O2 capillary 10 x distance > 100 x time One solution (among others)… Respiratory proteins Hemoglobin Hemerythrin Hemocyanin in bacteria, protists, fungi, plants, invertebrates, vertebrates The Respiratory Proteins of Vertebrates (until 2000) Tissue Globin Function Hemoglobin O2-transport CO2-transport NO-detoxification blood NO-transport (???) Myoglobin O2-storage + supply Intracellular O2- diffusion (?) muscle NO detoxification The power of NO inhalation NO treatment of against high Angina pectoris blood pressure Signal molecule in neurons "It sounds like the irony of fate that I have been prescribed nitroglycerine internally. They have named it Trinitrin in order Your affectionate friend, A. Nobel" Antibacterial defense in makrophages Hb functions in NO homeostasis Sickle cell disease physiological vasoconstriction NO is normally produced by controlled endothelial NO- vasodilation synthase (eNOS) PNAS 98 (2001) 735-740 See: Burmester & Hankeln 1999 BLAST: Drosophila-Hb vs. Mouse ESTs Database: GenBank Mouse EST entries 1,758,095 sequences; 629,105,611 total letters Database: GenBank Mouse EST entries 1,758,095 sequences; 629,105,611 total letters Score E Score E Sequences producing significant alignments: (bits) Value Sequences producing significant alignments: (bits) Value dbj|AU036042.1|AU036042 AU036042 Sugano mouse brain mncb Mu... 41 0.003 dbj|AU036042.1|AU036042 AU036042 Sugano mouse brain mncb Mu.. -

Evolution of Hemoglobin and Its Genes
Downloaded from http://perspectivesinmedicine.cshlp.org/ on October 2, 2021 - Published by Cold Spring Harbor Laboratory Press Evolution of Hemoglobin and Its Genes Ross C. Hardison Center for Comparative Genomics and Bioinformatics, Huck Institute of Genome Sciences, Department of Biochemistry and Molecular Biology, The Pennsylvania State University, University Park, Pennsylvania 16802 Correspondence: [email protected] Insights into the evolution of hemoglobins and their genes are an abundant source of ideas regarding hemoglobin function and regulation of globin gene expression. This article pre- sents the multiple genes and gene families encoding human globins, summarizes major events in the evolution of the hemoglobin gene clusters, and discusses how these studies provide insights into regulation of globin genes. Although the genes in and around the a-like globin gene complex are relatively stable, the b-like globin gene clusters are more dynamic, showing evidence of transposition to a new locus and frequent lineage-specific expansions and deletions. The cis-regulatory modules controlling levels and timing of gene expression are a mix of conserved and lineage-specific DNA, perhaps reflecting evolutionary constraint on core regulatory functions shared broadly in mammals and adaptive fine-tuning in different orders of mammals. wide range of animals, vertebrate and inver- globin genes, and attempts to modulate globin Atebrate, use hemoglobins to transport oxy- gene expression are a fundamental approach to gen, carrying it from lungs, gills, or