Lab #6, Homework #4 Parallel Processor Design 1. SIMD
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Review Memory Disambiguation Review Explicit Register Renaming
5HYLHZ5HRUGHU%XIIHU 52% &6 *UDGXDWH&RPSXWHU$UFKLWHFWXUH 8VHRIUHRUGHUEXIIHU /HFWXUH ² ,QRUGHULVVXH2XWRIRUGHUH[HFXWLRQ,QRUGHUFRPPLW ² +ROGVUHVXOWVXQWLOWKH\FDQEHFRPPLWWHGLQRUGHU ,QVWUXFWLRQ/HYHO3DUDOOHOLVP ª 6HUYHVDVVRXUFHRIYDOXHVXQWLOLQVWUXFWLRQVFRPPLWWHG ² 3URYLGHVVXSSRUWIRUSUHFLVHH[FHSWLRQV6SHFXODWLRQVLPSO\WKURZRXW *HWWLQJWKH&3, LQVWUXFWLRQVODWHUWKDQH[FHSWHGLQVWUXFWLRQ ² &RPPLWVXVHUYLVLEOHVWDWHLQLQVWUXFWLRQRUGHU ² 6WRUHVVHQWWRPHPRU\V\VWHPRQO\ZKHQWKH\UHDFKKHDGRIEXIIHU 6HSWHPEHU ,Q2UGHU&RPPLW LVLPSRUWDQWEHFDXVH 3URI-RKQ.XELDWRZLF] ² $OORZVWKHJHQHUDWLRQRISUHFLVHH[FHSWLRQV ² $OORZVVSHFXODWLRQDFURVVEUDQFKHV &6.XELDWRZLF] &6.XELDWRZLF] /HF /HF 5HYLHZ0HPRU\'LVDPELJXDWLRQ 5HYLHZ([SOLFLW5HJLVWHU5HQDPLQJ 4XHVWLRQ*LYHQDORDGWKDWIROORZVDVWRUHLQSURJUDP 0DNHXVHRIDSK\VLFDO UHJLVWHUILOHWKDWLVODUJHUWKDQ RUGHUDUHWKHWZRUHODWHG" QXPEHURIUHJLVWHUVVSHFLILHGE\,6$ ² 7U\LQJWRGHWHFW5$:KD]DUGVWKURXJKPHPRU\ .H\LQVLJKW$OORFDWHDQHZSK\VLFDOGHVWLQDWLRQUHJLVWHU ² 6WRUHVFRPPLWLQRUGHU 52% VRQR:$5:$:PHPRU\KD]DUGV IRUHYHU\LQVWUXFWLRQWKDWZULWHV ,PSOHPHQWDWLRQ ² 5HPRYHVDOOFKDQFHRI:$5RU:$:KD]DUGV ² .HHSTXHXHRIVWRUHVLQSURJRUGHU ² 6LPLODUWRFRPSLOHUWUDQVIRUPDWLRQFDOOHG6WDWLF6LQJOH$VVLJQPHQW ² :DWFKIRUSRVLWLRQRIQHZORDGVUHODWLYHWRH[LVWLQJVWRUHV ª /LNHKDUGZDUHEDVHGG\QDPLFFRPSLODWLRQ" :KHQKDYHDGGUHVVIRUORDGFKHFNVWRUHTXHXH 0HFKDQLVP".HHSDWUDQVODWLRQWDEOH ² ,IDQ\ VWRUHSULRUWRORDGLVZDLWLQJIRULWVDGGUHVVVWDOOORDG ² ,6$UHJLVWHU⇒ SK\VLFDOUHJLVWHUPDSSLQJ ² ,IORDGDGGUHVVPDWFKHVHDUOLHUVWRUHDGGUHVV DVVRFLDWLYHORRNXS ² :KHQUHJLVWHUZULWWHQUHSODFHHQWU\ZLWKQHZUHJLVWHUIURPIUHHOLVW WKHQZHKDYHDPHPRU\LQGXFHG -

Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and Power
Chapter 1: Computer Abstractions and Technology 1.6 – 1.7: Performance and power ITSC 3181 Introduction to Computer Architecture https://passlaB.githuB.io/ITSC3181/ Department of Computer Science Yonghong Yan [email protected] https://passlab.github.io/yanyh/ Lectures for Chapter 1 and C Basics Computer Abstractions and Technology • Lecture 01: Chapter 1 – 1.1 – 1.4: Introduction, great ideas, Moore’s law, aBstraction, computer components, and program execution • Lecture 02: C Basics; Memory and Binary Systems • Lecture 03: Number System, Compilation, Assembly, Linking and Program Execution ☛• Lecture 04: Chapter 1 – 1.6 – 1.7: Performance, power and technology trends • Lecture 05: – 1.8 - 1.9: Multiprocessing and Benchmarking 2 § 1.6 Performance 1.6 Defining Performance • Which airplane has the best performance? Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 100 200 300 400 500 0 2000 4000 6000 8000 10000 Passenger Capacity Cruising Range (miles) Boeing 777 Boeing 777 Boeing 747 Boeing 747 BAC/Sud BAC/Sud Concorde Concorde Douglas Douglas DC- DC-8-50 8-50 0 500 1000 1500 0 100000 200000 300000 400000 Cruising Speed (mph) Passengers x mph 3 Response Time and Throughput • Response time çè Latency – How long it takes to do a task • Throughput çè Bandwidth – Total work done per unit time • e.g., tasks/transactions/… per hour • How are response time and throughput affected by – Replacing the processor with a faster version? – Adding more processors? • We’ll focus on response time for now… 4 Relative Performance • Define Performance = 1/Execution Time • “X is n time faster than Y”, i.e. -

ARM Cortex-A* Brian Eccles, Riley Larkins, Kevin Mee, Fred Silberberg, Alex Solomon, Mitchell Wills
ARM Cortex-A* Brian Eccles, Riley Larkins, Kevin Mee, Fred Silberberg, Alex Solomon, Mitchell Wills The ARM CortexA product line has changed significantly since the introduction of the CortexA8 in 2005. ARM’s next major leap came with the CortexA9 which was the first design to incorporate multiple cores. The next advance was the development of the big.LITTLE architecture, which incorporates both high performance (A15) and high efficiency(A7) cores. Most recently the A57 and A53 have added 64bit support to the product line. The ARM Cortex series cores are all made up of the main processing unit, a L1 instruction cache, a L1 data cache, an advanced SIMD core and a floating point core. Each processor then has an additional L2 cache shared between all cores (if there are multiple), debug support and an interface bus for communicating with the rest of the system. Multicore processors (such as the A53 and A57) also include additional hardware to facilitate coherency between cores. The ARM CortexA57 is a 64bit processor that supports 1 to 4 cores. The instruction pipeline in each core supports fetching up to three instructions per cycle to send down the pipeline. The instruction pipeline is made up of a 12 stage in order pipeline and a collection of parallel pipelines that range in size from 3 to 15 stages as seen below. The ARM CortexA53 is similar to the A57, but is designed to be more power efficient at the cost of processing power. The A57 in order pipeline is made up of 5 stages of instruction fetch and 7 stages of instruction decode and register renaming. -
Clock Rate Improves Roughly Proportional to Improvement in L • Number of Transistors Improves Proportional to L2 (Or Faster)
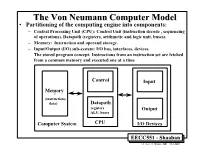
TheThe VonVon NeumannNeumann ComputerComputer ModelModel • Partitioning of the computing engine into components: – Central Processing Unit (CPU): Control Unit (instruction decode , sequencing of operations), Datapath (registers, arithmetic and logic unit, buses). – Memory: Instruction and operand storage. – Input/Output (I/O) sub-system: I/O bus, interfaces, devices. – The stored program concept: Instructions from an instruction set are fetched from a common memory and executed one at a time Control Input Memory - (instructions, data) Datapath registers Output ALU, buses Computer System CPU I/O Devices EECC551 - Shaaban #1 Lec # 1 Winter 2001 12-3-2001 Generic CPU Machine Instruction Execution Steps Instruction Obtain instruction from program storage Fetch Instruction Determine required actions and instruction size Decode Operand Locate and obtain operand data Fetch Execute Compute result value or status Result Deposit results in storage for later use Store Next Determine successor or next instruction Instruction EECC551 - Shaaban #2 Lec # 1 Winter 2001 12-3-2001 HardwareHardware ComponentsComponents ofof AnyAny ComputerComputer Five classic components of all computers: 1. Control Unit; 2. Datapath; 3. Memory; 4. Input; 5. Output } Processor Computer Keyboard, Mouse, etc. Processor Memory Devices (active) (passive) Control Input (where Unit programs, data Disk Datapath live when Output running) Display, Printer, etc. EECC551 - Shaaban #3 Lec # 1 Winter 2001 12-3-2001 CPUCPU OrganizationOrganization • Datapath Design: – Capabilities & performance characteristics of principal Functional Units (FUs): • (e.g., Registers, ALU, Shifters, Logic Units, ...) – Ways in which these components are interconnected (buses connections, multiplexors, etc.). – How information flows between components. • Control Unit Design: – Logic and means by which such information flow is controlled. – Control and coordination of FUs operation to realize the targeted Instruction Set Architecture to be implemented (can either be implemented using a finite state machine or a microprogram). -

Out-Of-Order Execution & Register Renaming
Asanovic/Devadas Spring 2002 6.823 Out-of-Order Execution & Register Renaming Krste Asanovic Laboratory for Computer Science Massachusetts Institute of Technology Asanovic/Devadas Spring 2002 6.823 Scoreboard for In-order Issue Busy[unit#] : a bit-vector to indicate unit’s availability. (unit = Int, Add, Mult, Div) These bits are hardwired to FU's. WP[reg#] : a bit-vector to record the registers for which writes are pending Issue checks the instruction (opcode dest src1 src2) against the scoreboard (Busy & WP) to dispatch FU available? not Busy[FU#] RAW? WP[src1] or WP[src2] WAR? cannot arise WAW? WP[dest] Asanovic/Devadas Spring 2002 Out-of-Order Dispatch 6.823 ALU Mem IF ID Issue WB Fadd Fmul • Issue stage buffer holds multiple instructions waiting to issue. • Decode adds next instruction to buffer if there is space and the instruction does not cause a WAR or WAW hazard. • Any instruction in buffer whose RAW hazards are satisfied can be dispatched (for now, at most one dispatch per cycle). On a write back (WB), new instructions may get enabled. Asanovic/Devadas Spring 2002 6.823 Out-of-Order Issue: an example latency 1 LD F2, 34(R2) 1 1 2 2 LD F4, 45(R3) long 3 MULTD F6, F4, F2 3 4 3 4 SUBD F8, F2, F2 1 5 5 DIVD F4, F2, F8 4 6 ADDD F10, F6, F4 1 6 In-order: 1 (2,1) . 2 3 4 4 3 5 . 5 6 6 Out-of-order: 1 (2,1) 4 4 . 2 3 . 3 5 . -

Atmega165p Datasheet
Features • High Performance, Low Power Atmel® AVR® 8-Bit Microcontroller • Advanced RISC Architecture – 130 Powerful Instructions – Most Single Clock Cycle Execution – 32 × 8 General Purpose Working Registers – Fully Static Operation – Up to 16 MIPS Throughput at 16 MHz – On-Chip 2-cycle Multiplier • High Endurance Non-volatile Memory segments – 16 Kbytes of In-System Self-programmable Flash program memory – 512 Bytes EEPROM – 1 Kbytes Internal SRAM 8-bit – Write/Erase cyles: 10,000 Flash/100,000 EEPROM(1)(3) – Data retention: 20 years at 85°C/100 years at 25°C(2)(3) Microcontroller – Optional Boot Code Section with Independent Lock Bits In-System Programming by On-chip Boot Program with 16K Bytes True Read-While-Write Operation – Programming Lock for Software Security In-System • JTAG (IEEE std. 1149.1 compliant) Interface – Boundary-scan Capabilities According to the JTAG Standard Programmable – Extensive On-chip Debug Support – Programming of Flash, EEPROM, Fuses, and Lock Bits through the JTAG Interface Flash • Peripheral Features – Two 8-bit Timer/Counters with Separate Prescaler and Compare Mode – One 16-bit Timer/Counter with Separate Prescaler, Compare Mode, and Capture Mode – Real Time Counter with Separate Oscillator –Four PWM Channels ATmega165P – 8-channel, 10-bit ADC – Programmable Serial USART ATmega165PV – Master/Slave SPI Serial Interface – Universal Serial Interface with Start Condition Detector – Programmable Watchdog Timer with Separate On-chip Oscillator – On-chip Analog Comparator Preliminary – Interrupt and Wake-up -

Dynamic Register Renaming Through Virtual-Physical Registers
Dynamic Register Renaming Through Virtual-Physical Registers † Teresa Monreal [email protected] Antonio González* [email protected] Mateo Valero* [email protected] †† José González [email protected] † Víctor Viñals [email protected] †Departamento de Informática e Ing. de Sistemas. Centro Politécnico Superior - Univ. de Zaragoza, Zaragoza, Spain. *Departament d’ Arquitectura de Computadors. Universitat Politècnica de Catalunya, Barcelona, Spain. ††Departamento de Ingeniería y Tecnología de Computadores. Universidad de Murcia, Murcia, Spain. Abstract Register file access time represents one of the critical delays of current microprocessors, and it is expected to become more critical as future processors increase the instruction window size and the issue width. This paper present a novel dynamic register renaming scheme that delays the allocation of physical registers until a late stage in the pipeline. We show that it can provide important savings in number of physical registers so it can significantly shorter the register file access time. Delaying the allocation of physical registers requires some artifact to keep track of dependences. This is achieved by introducing the concept of virtual-physical registers, which are tags that do not require any storage location. The proposed renaming scheme shortens the average number of cycles that each physical register is allocated, and allows for an early execution of instructions since they can obtain a physical register for its destination earlier than with the conventional scheme. Early execution is especially beneficial for branches and memory operations, since the former can be resolved earlier and the latter can prefetch their data in advance. 1. Introduction Dynamically-scheduled superscalar processors exploit instruction-level parallelism (ILP) by overlapping the execution of instructions in an instruction window. -

Computer Architecture Out-Of-Order Execution
Computer Architecture Out-of-order Execution By Yoav Etsion With acknowledgement to Dan Tsafrir, Avi Mendelson, Lihu Rappoport, and Adi Yoaz 1 Computer Architecture 2013– Out-of-Order Execution The need for speed: Superscalar • Remember our goal: minimize CPU Time CPU Time = duration of clock cycle × CPI × IC • So far we have learned that in order to Minimize clock cycle ⇒ add more pipe stages Minimize CPI ⇒ utilize pipeline Minimize IC ⇒ change/improve the architecture • Why not make the pipeline deeper and deeper? Beyond some point, adding more pipe stages doesn’t help, because Control/data hazards increase, and become costlier • (Recall that in a pipelined CPU, CPI=1 only w/o hazards) • So what can we do next? Reduce the CPI by utilizing ILP (instruction level parallelism) We will need to duplicate HW for this purpose… 2 Computer Architecture 2013– Out-of-Order Execution A simple superscalar CPU • Duplicates the pipeline to accommodate ILP (IPC > 1) ILP=instruction-level parallelism • Note that duplicating HW in just one pipe stage doesn’t help e.g., when having 2 ALUs, the bottleneck moves to other stages IF ID EXE MEM WB • Conclusion: Getting IPC > 1 requires to fetch/decode/exe/retire >1 instruction per clock: IF ID EXE MEM WB 3 Computer Architecture 2013– Out-of-Order Execution Example: Pentium Processor • Pentium fetches & decodes 2 instructions per cycle • Before register file read, decide on pairing Can the two instructions be executed in parallel? (yes/no) u-pipe IF ID v-pipe • Pairing decision is based… On data -

Performance of a Computer (Chapter 4) Vishwani D
ELEC 5200-001/6200-001 Computer Architecture and Design Fall 2013 Performance of a Computer (Chapter 4) Vishwani D. Agrawal & Victor P. Nelson epartment of Electrical and Computer Engineering Auburn University, Auburn, AL 36849 ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 1 What is Performance? Response time: the time between the start and completion of a task. Throughput: the total amount of work done in a given time. Some performance measures: MIPS (million instructions per second). MFLOPS (million floating point operations per second), also GFLOPS, TFLOPS (1012), etc. SPEC (System Performance Evaluation Corporation) benchmarks. LINPACK benchmarks, floating point computing, used for supercomputers. Synthetic benchmarks. ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 2 Small and Large Numbers Small Large 10-3 milli m 103 kilo k 10-6 micro μ 106 mega M 10-9 nano n 109 giga G 10-12 pico p 1012 tera T 10-15 femto f 1015 peta P 10-18 atto 1018 exa 10-21 zepto 1021 zetta 10-24 yocto 1024 yotta ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 3 Computer Memory Size Number bits bytes 210 1,024 K Kb KB 220 1,048,576 M Mb MB 230 1,073,741,824 G Gb GB 240 1,099,511,627,776 T Tb TB ELEC 5200-001/6200-001 Performance Fall 2013 . Lecture 4 Units for Measuring Performance Time in seconds (s), microseconds (μs), nanoseconds (ns), or picoseconds (ps). Clock cycle Period of the hardware clock Example: one clock cycle means 1 nanosecond for a 1GHz clock frequency (or 1GHz clock rate) CPU time = (CPU clock cycles)/(clock rate) Cycles per instruction (CPI): average number of clock cycles used to execute a computer instruction. -

Chap01: Computer Abstractions and Technology
CHAPTER 1 Computer Abstractions and Technology 1.1 Introduction 3 1.2 Eight Great Ideas in Computer Architecture 11 1.3 Below Your Program 13 1.4 Under the Covers 16 1.5 Technologies for Building Processors and Memory 24 1.6 Performance 28 1.7 The Power Wall 40 1.8 The Sea Change: The Switch from Uniprocessors to Multiprocessors 43 1.9 Real Stuff: Benchmarking the Intel Core i7 46 1.10 Fallacies and Pitfalls 49 1.11 Concluding Remarks 52 1.12 Historical Perspective and Further Reading 54 1.13 Exercises 54 CMPS290 Class Notes (Chap01) Page 1 / 24 by Kuo-pao Yang 1.1 Introduction 3 Modern computer technology requires professionals of every computing specialty to understand both hardware and software. Classes of Computing Applications and Their Characteristics Personal computers o A computer designed for use by an individual, usually incorporating a graphics display, a keyboard, and a mouse. o Personal computers emphasize delivery of good performance to single users at low cost and usually execute third-party software. o This class of computing drove the evolution of many computing technologies, which is only about 35 years old! Server computers o A computer used for running larger programs for multiple users, often simultaneously, and typically accessed only via a network. o Servers are built from the same basic technology as desktop computers, but provide for greater computing, storage, and input/output capacity. Supercomputers o A class of computers with the highest performance and cost o Supercomputers consist of tens of thousands of processors and many terabytes of memory, and cost tens to hundreds of millions of dollars. -

Hardware-Sensitive Database Operations - II
Faculty of Computer Science Database and Software Engineering Group Hardware-Sensitive Database Operations - II Balasubramanian (Bala) Gurumurthy Advanced Topics in Databases, 2019/May/17 Otto-von-Guericke University of Magdeburg So Far... ● Hardware evolution and current challenges ● Hardware-oblivious vs. hardware-sensitive programming ● Pipelining in RISC computing ● Pipeline Hazards ○ Structural hazard ○ Data hazard ○ Control hazard ● Resolving hazards ○ Loop-Unrolling ○ Predication Bala Gurumurthy | Hardware-Sensitive Database Operations Part II We will see ● Vectorization ○ SIMD Execution ○ SIMD in DBMS Operation ● GPUs in DBMSs ○ Processing Model ○ Handling Synchronization Bala Gurumurthy | Hardware-Sensitive Database Operations Vectorization Leveraging Modern Processing Capabilities Hardware Parallelism One we know already: Pipelining ● Separate chip regions for individual tasks to execute independently ● Advantage: parallelism + sequential execution semantics ● We discussed problems of hazards ● VLSI tech. limits degree up to which pipelining is feasible [Kaeslin, 2008] Bala Gurumurthy | Hardware-Sensitive Database Operations Hardware Parallelism Chip area can be used for other types of parallelism: Computer systems typically use identical hardware circuits, but their function may be controlled by different instruction stream Si: Bala Gurumurthy | Hardware-Sensitive Database Operations Special instances Example of this architecture? Bala Gurumurthy | Hardware-Sensitive Database Operations Special instances Example of this architecture? -

RAMP: Research Accelerator for Multiple Processors
Technical Report UCB//CSD-05-1412, September 2005 RAMP: Research Accelerator for Multiple Processors - A Community Vision for a Shared Experimental Parallel HW/SW Platform Arvind (MIT), Krste Asanovic´ (MIT), Derek Chiou (UT Austin), James C. Hoe (CMU), Christoforos Kozyrakis (Stanford), Shih-Lien Lu (Intel), Mark Oskin (U Washington), David Patterson (UC Berkeley), Jan Rabaey (UC Berkeley), and John Wawrzynek (UC Berkeley) Project Summary Desktop processor architectures have crossed a critical threshold. Manufactures have given up attempting to extract ever more performance from a single core and instead have turned to multi-core designs. While straightforward approaches to the architecture of multi-core processors are sufficient for small designs (2–4 cores), little is really known how to build, program, or manage systems of 64 to 1024 processors. Unfortunately, the computer architecture community lacks the basic infrastructure tools required to carry out this research. While simulation has been adequate for single-processor research, significant use of simplified modeling and statistical sampling is required to work in the 2–16 processing core space. Invention is required for architecture research at the level of 64–1024 cores. Fortunately, Moore’s law has not only enabled these dense multi-core chips, it has also enabled extremely dense FPGAs. Today, for a few hundred dollars, undergraduates can work with an FPGA prototype board with almost as many gates as a Pentium. Given the right support, the research community can capitalize on this opportunity too. Today, one to two dozen cores can be programmed into a single FPGA. With multiple FPGAs on a board and multiple boards in a system, large complex architectures can be explored.