A Tool for Expanding Biological Pathways Based on Co-Expression Across Thousands of Datasets
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Prediction of Meiosis-Essential Genes Based Upon the Dynamic Proteomes Responsive to Spermatogenesis
bioRxiv preprint doi: https://doi.org/10.1101/2020.02.05.936435; this version posted February 6, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. Prediction of meiosis-essential genes based upon the dynamic proteomes responsive to spermatogenesis Kailun Fang1,2,3,8, Qidan Li3,4,5,8, Yu Wei2,3,8, Jiaqi Shen6,8, Wenhui Guo3,4,5,7,8, Changyang Zhou2,3,8, Ruoxi Wu1, Wenqin Ying2, Lu Yu1,2, Jin Zi5, Yuxing Zhang3,4,5, Hui Yang2,3,9*, Siqi Liu3,4,5,9*, Charlie Degui Chen1,3,9* 1. State Key Laboratory of Molecular Biology, Shanghai Key Laboratory of Molecular Andrology, CAS Center for Excellence in Molecular Cell Science, Shanghai Institute of Biochemistry and Cell Biology, Chinese Academy of Sciences, Shanghai 200031, China. 2. State Key Laboratory of Neuroscience, Key Laboratory of Primate Neurobiology, CAS Center for Excellence in Brain Science and Intelligence Technology, Shanghai Research Center for Brain Science and Brain-Inspired Intelligence, Institute of Neuroscience, Shanghai Institutes for Biological Sciences, Chinese Academy of Sciences, Shanghai 200031, China. 3. University of the Chinese Academy of Sciences, Beijing 100049, China. 4. CAS Key Laboratory of Genome Sciences and Information, Beijing Institute of Genomics, Chinese Academy of Sciences, Beijing 100101, China. 5. BGI Genomics, BGI-Shenzhen, Shenzhen 518083, China. 6. United World College Changshu China, Jiangsu 215500, China. 7. Malvern College Qingdao, Shandong, 266109, China 8. -

Gene Expression Profiling of Corpus Luteum Reveals the Importance Of
bioRxiv preprint doi: https://doi.org/10.1101/673558; this version posted February 27, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Gene expression profiling of corpus luteum reveals the 2 importance of immune system during early pregnancy in 3 domestic sheep. 4 Kisun Pokharel1, Jaana Peippo2 Melak Weldenegodguad1, Mervi Honkatukia2, Meng-Hua Li3*, Juha 5 Kantanen1* 6 1 Natural Resources Institute Finland (Luke), Jokioinen, Finland 7 2 Nordgen – The Nordic Genetic Resources Center, Ås, Norway 8 3 College of Animal Science and Technology, China Agriculture University, Beijing, China 9 * Correspondence: MHL, [email protected]; JK, [email protected] 10 Abstract: The majority of pregnancy loss in ruminants occurs during the preimplantation stage, which is thus 11 the most critical period determining reproductive success. While ovulation rate is the major determinant of 12 litter size in sheep, interactions among the conceptus, corpus luteum and endometrium are essential for 13 pregnancy success. Here, we performed a comparative transcriptome study by sequencing total mRNA from 14 corpus luteum (CL) collected during the preimplantation stage of pregnancy in Finnsheep, Texel and F1 15 crosses, and mapping the RNA-Seq reads to the latest Rambouillet reference genome. A total of 21,287 genes 16 were expressed in our dataset. Highly expressed autosomal genes in the CL were associated with biological 17 processes such as progesterone formation (STAR, CYP11A1, and HSD3B1) and embryo implantation (eg. -

1 Mucosal Effects of Tenofovir 1% Gel 1 Florian Hladik1,2,5*, Adam
1 Mucosal effects of tenofovir 1% gel 2 Florian Hladik1,2,5*, Adam Burgener8,9, Lamar Ballweber5, Raphael Gottardo4,5,6, Lucia Vojtech1, 3 Slim Fourati7, James Y. Dai4,6, Mark J. Cameron7, Johanna Strobl5, Sean M. Hughes1, Craig 4 Hoesley10, Philip Andrew12, Sherri Johnson12, Jeanna Piper13, David R. Friend14, T. Blake Ball8,9, 5 Ross D. Cranston11,16, Kenneth H. Mayer15, M. Juliana McElrath2,3,5 & Ian McGowan11,16 6 Departments of 1Obstetrics and Gynecology, 2Medicine, 3Global Health, 4Biostatistics, University 7 of Washington, Seattle, USA; 5Vaccine and Infectious Disease Division, 6Public Health Sciences 8 Division, Fred Hutchinson Cancer Research Center, Seattle, USA; 7Vaccine and Gene Therapy 9 Institute-Florida, Port St. Lucie, USA; 8Department of Medical Microbiology, University of 10 Manitoba, Winnipeg, Canada; 9National HIV and Retrovirology Laboratories, Public Health 11 Agency of Canada; 10University of Alabama, Birmingham, USA; 11University of Pittsburgh 12 School of Medicine, Pittsburgh, USA; 12FHI 360, Durham, USA; 13Division of AIDS, NIAID, NIH, 13 Bethesda, USA; 14CONRAD, Eastern Virginia Medical School, Arlington, USA; 15Fenway Health, 14 Beth Israel Deaconess Hospital and Harvard Medical School, Boston, USA; 16Microbicide Trials 15 Network, Magee-Women’s Research Institute, Pittsburgh, USA. 16 Adam Burgener and Lamar Ballweber contributed equally to this work. 17 *Corresponding author E-mail: [email protected] 18 Address reprint requests to Florian Hladik at [email protected] or Ian McGowan at 19 [email protected]. 20 Abstract: 150 words. Main text (without Methods): 2,603 words. Methods: 3,953 words 1 21 ABSTRACT 22 Tenofovir gel is being evaluated for vaginal and rectal pre-exposure prophylaxis against HIV 23 transmission. -

Proteomic Shifts in Embryonic Stem Cells with Gene Dose Modifications Suggest the Presence of Balancer Proteins in Protein Regulatory Networks
Proteomic shifts in embryonic stem cells with gene dose modifications suggest the presence of balancer proteins in protein regulatory networks. Lei Mao, Claus Zabel, Marion Herrmann, Tobias Nolden, Florian Mertes, Laetitia Magnol, Caroline Chabert, Daniela Hartl, Yann Herault, Jean Maurice Delabar, et al. To cite this version: Lei Mao, Claus Zabel, Marion Herrmann, Tobias Nolden, Florian Mertes, et al.. Proteomic shifts in embryonic stem cells with gene dose modifications suggest the presence of balancer proteins in protein regulatory networks.. PLoS ONE, Public Library of Science, 2007, 2 (11), pp.e1218. 10.1371/jour- nal.pone.0001218. hal-00408296 HAL Id: hal-00408296 https://hal.archives-ouvertes.fr/hal-00408296 Submitted on 31 May 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Proteomic Shifts in Embryonic Stem Cells with Gene Dose Modifications Suggest the Presence of Balancer Proteins in Protein Regulatory Networks Lei Mao1,2*, Claus Zabel1, Marion Herrmann1, Tobias Nolden2, Florian Mertes2, Laetitia Magnol3, Caroline Chabert4, Daniela -

Dysregulation of Post-Transcriptional Modification by Copy Number
Yoshikawa et al. Translational Psychiatry (2021) 11:331 https://doi.org/10.1038/s41398-021-01460-1 Translational Psychiatry ARTICLE Open Access Dysregulation of post-transcriptional modification by copy number variable microRNAs in schizophrenia with enhanced glycation stress Akane Yoshikawa1,2,ItaruKushima 3,4, Mitsuhiro Miyashita 1,5,6,KazuyaToriumi 1, Kazuhiro Suzuki 1,5, Yasue Horiuchi 1, Hideya Kawaji 7, Shunya Takizawa8,NorioOzaki 3, Masanari Itokawa1 and Makoto Arai 1 Abstract Previously, we identified a subpopulation of schizophrenia (SCZ) showing increased levels of plasma pentosidine, a marker of glycation and oxidative stress. However, its causative genetic factors remain largely unknown. Recently, it has been suggested that dysregulated posttranslational modification by copy number variable microRNAs (CNV-miRNAs) may contribute to the etiology of SCZ. Here, an integrative genome-wide CNV-miRNA analysis was performed to investigate the etiology of SCZ with accumulated plasma pentosidine (PEN-SCZ). The number of CNV-miRNAs and the gene ontology (GO) in the context of miRNAs within CNVs were compared between PEN-SCZ and non-PEN-SCZ groups. Gene set enrichment analysis of miRNA target genes was further performed to evaluate the pathways affected in PEN-SCZ. We show that miRNAs were significantly enriched within CNVs in the PEN-SCZ versus non-PEN-SCZ groups (p = 0.032). Of note, as per GO analysis, the dysregulated neurodevelopmental events in the two groups may have different origins. Additionally, gene set enrichment analysis of miRNA target genes revealed that miRNAs involved in glycation/oxidative stress and synaptic neurotransmission, especially glutamate/GABA receptor signaling, fi 1234567890():,; 1234567890():,; 1234567890():,; 1234567890():,; were possibly affected in PEN-SCZ. -

Chromosome 18 Gene Dosage Map 2.0
Human Genetics (2018) 137:961–970 https://doi.org/10.1007/s00439-018-1960-6 ORIGINAL INVESTIGATION Chromosome 18 gene dosage map 2.0 Jannine D. Cody1,2 · Patricia Heard1 · David Rupert1 · Minire Hasi‑Zogaj1 · Annice Hill1 · Courtney Sebold1 · Daniel E. Hale1,3 Received: 9 August 2018 / Accepted: 14 November 2018 / Published online: 17 November 2018 © Springer-Verlag GmbH Germany, part of Springer Nature 2018 Abstract In 2009, we described the first generation of the chromosome 18 gene dosage maps. This tool included the annotation of each gene as well as each phenotype associated region. The goal of these annotated genetic maps is to provide clinicians with a tool to appreciate the potential clinical impact of a chromosome 18 deletion or duplication. These maps are continually updated with the most recent and relevant data regarding chromosome 18. Over the course of the past decade, there have also been advances in our understanding of the molecular mechanisms underpinning genetic disease. Therefore, we have updated the maps to more accurately reflect this knowledge. Our Gene Dosage Map 2.0 has expanded from the gene and phenotype maps to also include a pair of maps specific to hemizygosity and suprazygosity. Moreover, we have revamped our classification from mechanistic definitions (e.g., haplosufficient, haploinsufficient) to clinically oriented classifications (e.g., risk factor, conditional, low penetrance, causal). This creates a map with gradient of classifications that more accurately represents the spectrum between the two poles of pathogenic and benign. While the data included in this manuscript are specific to chro- mosome 18, they may serve as a clinically relevant model that can be applied to the rest of the genome. -
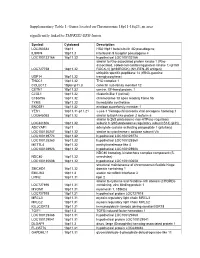
Supplementary Table 1: Genes Located on Chromosome 18P11-18Q23, an Area Significantly Linked to TMPRSS2-ERG Fusion
Supplementary Table 1: Genes located on Chromosome 18p11-18q23, an area significantly linked to TMPRSS2-ERG fusion Symbol Cytoband Description LOC260334 18p11 HSA18p11 beta-tubulin 4Q pseudogene IL9RP4 18p11.3 interleukin 9 receptor pseudogene 4 LOC100132166 18p11.32 hypothetical LOC100132166 similar to Rho-associated protein kinase 1 (Rho- associated, coiled-coil-containing protein kinase 1) (p160 LOC727758 18p11.32 ROCK-1) (p160ROCK) (NY-REN-35 antigen) ubiquitin specific peptidase 14 (tRNA-guanine USP14 18p11.32 transglycosylase) THOC1 18p11.32 THO complex 1 COLEC12 18pter-p11.3 collectin sub-family member 12 CETN1 18p11.32 centrin, EF-hand protein, 1 CLUL1 18p11.32 clusterin-like 1 (retinal) C18orf56 18p11.32 chromosome 18 open reading frame 56 TYMS 18p11.32 thymidylate synthetase ENOSF1 18p11.32 enolase superfamily member 1 YES1 18p11.31-p11.21 v-yes-1 Yamaguchi sarcoma viral oncogene homolog 1 LOC645053 18p11.32 similar to BolA-like protein 2 isoform a similar to 26S proteasome non-ATPase regulatory LOC441806 18p11.32 subunit 8 (26S proteasome regulatory subunit S14) (p31) ADCYAP1 18p11 adenylate cyclase activating polypeptide 1 (pituitary) LOC100130247 18p11.32 similar to cytochrome c oxidase subunit VIc LOC100129774 18p11.32 hypothetical LOC100129774 LOC100128360 18p11.32 hypothetical LOC100128360 METTL4 18p11.32 methyltransferase like 4 LOC100128926 18p11.32 hypothetical LOC100128926 NDC80 homolog, kinetochore complex component (S. NDC80 18p11.32 cerevisiae) LOC100130608 18p11.32 hypothetical LOC100130608 structural maintenance -

Accurate Prediction of Kinase-Substrate Networks Using
bioRxiv preprint doi: https://doi.org/10.1101/865055; this version posted December 4, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Accurate Prediction of Kinase-Substrate Networks Using Knowledge Graphs V´ıtNov´aˇcek1∗+, Gavin McGauran3, David Matallanas3, Adri´anVallejo Blanco3,4, Piero Conca2, Emir Mu~noz1,2, Luca Costabello2, Kamalesh Kanakaraj1, Zeeshan Nawaz1, Sameh K. Mohamed1, Pierre-Yves Vandenbussche2, Colm Ryan3, Walter Kolch3,5,6, Dirk Fey3,6∗ 1Data Science Institute, National University of Ireland Galway, Ireland 2Fujitsu Ireland Ltd., Co. Dublin, Ireland 3Systems Biology Ireland, University College Dublin, Belfield, Dublin 4, Ireland 4Department of Oncology, Universidad de Navarra, Pamplona, Spain 5Conway Institute of Biomolecular & Biomedical Research, University College Dublin, Belfield, Dublin 4, Ireland 6School of Medicine, University College Dublin, Belfield, Dublin 4, Ireland ∗ Corresponding authors ([email protected], [email protected]). + Lead author. 1 bioRxiv preprint doi: https://doi.org/10.1101/865055; this version posted December 4, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. Abstract Phosphorylation of specific substrates by protein kinases is a key control mechanism for vital cell-fate decisions and other cellular pro- cesses. However, discovering specific kinase-substrate relationships is time-consuming and often rather serendipitous. -

Content Based Search in Gene Expression Databases and a Meta-Analysis of Host Responses to Infection
Content Based Search in Gene Expression Databases and a Meta-analysis of Host Responses to Infection A Thesis Submitted to the Faculty of Drexel University by Francis X. Bell in partial fulfillment of the requirements for the degree of Doctor of Philosophy November 2015 c Copyright 2015 Francis X. Bell. All Rights Reserved. ii Acknowledgments I would like to acknowledge and thank my advisor, Dr. Ahmet Sacan. Without his advice, support, and patience I would not have been able to accomplish all that I have. I would also like to thank my committee members and the Biomed Faculty that have guided me. I would like to give a special thanks for the members of the bioinformatics lab, in particular the members of the Sacan lab: Rehman Qureshi, Daisy Heng Yang, April Chunyu Zhao, and Yiqian Zhou. Thank you for creating a pleasant and friendly environment in the lab. I give the members of my family my sincerest gratitude for all that they have done for me. I cannot begin to repay my parents for their sacrifices. I am eternally grateful for everything they have done. The support of my sisters and their encouragement gave me the strength to persevere to the end. iii Table of Contents LIST OF TABLES.......................................................................... vii LIST OF FIGURES ........................................................................ xiv ABSTRACT ................................................................................ xvii 1. A BRIEF INTRODUCTION TO GENE EXPRESSION............................. 1 1.1 Central Dogma of Molecular Biology........................................... 1 1.1.1 Basic Transfers .......................................................... 1 1.1.2 Uncommon Transfers ................................................... 3 1.2 Gene Expression ................................................................. 4 1.2.1 Estimating Gene Expression ............................................ 4 1.2.2 DNA Microarrays ...................................................... -

The Role and Robustness of the Gini Coefficient As an Unbiased Tool For
www.nature.com/scientificreports OPEN The role and robustness of the Gini coefcient as an unbiased tool for the selection of Gini genes for normalising expression profling data Marina Wright Muelas 1*, Farah Mughal1, Steve O’Hagan2,3, Philip J. Day3,4* & Douglas B. Kell 1,5* We recently introduced the Gini coefcient (GC) for assessing the expression variation of a particular gene in a dataset, as a means of selecting improved reference genes over the cohort (‘housekeeping genes’) typically used for normalisation in expression profling studies. Those genes (transcripts) that we determined to be useable as reference genes difered greatly from previous suggestions based on hypothesis-driven approaches. A limitation of this initial study is that a single (albeit large) dataset was employed for both tissues and cell lines. We here extend this analysis to encompass seven other large datasets. Although their absolute values difer a little, the Gini values and median expression levels of the various genes are well correlated with each other between the various cell line datasets, implying that our original choice of the more ubiquitously expressed low-Gini-coefcient genes was indeed sound. In tissues, the Gini values and median expression levels of genes showed a greater variation, with the GC of genes changing with the number and types of tissues in the data sets. In all data sets, regardless of whether this was derived from tissues or cell lines, we also show that the GC is a robust measure of gene expression stability. Using the GC as a measure of expression stability we illustrate its utility to fnd tissue- and cell line-optimised housekeeping genes without any prior bias, that again include only a small number of previously reported housekeeping genes. -

Multiscale Genomic Analysis of The
University of Tennessee Health Science Center UTHSC Digital Commons Theses and Dissertations (ETD) College of Graduate Health Sciences 5-2009 Multiscale Genomic Analysis of the Corticolimbic System: Uncovering the Molecular and Anatomic Substrates of Anxiety-Related Behavior Khyobeni Mozhui University of Tennessee Health Science Center Follow this and additional works at: https://dc.uthsc.edu/dissertations Part of the Mental and Social Health Commons, Nervous System Commons, and the Neurosciences Commons Recommended Citation Mozhui, Khyobeni , "Multiscale Genomic Analysis of the Corticolimbic System: Uncovering the Molecular and Anatomic Substrates of Anxiety-Related Behavior" (2009). Theses and Dissertations (ETD). Paper 180. http://dx.doi.org/10.21007/etd.cghs.2009.0219. This Dissertation is brought to you for free and open access by the College of Graduate Health Sciences at UTHSC Digital Commons. It has been accepted for inclusion in Theses and Dissertations (ETD) by an authorized administrator of UTHSC Digital Commons. For more information, please contact [email protected]. Multiscale Genomic Analysis of the Corticolimbic System: Uncovering the Molecular and Anatomic Substrates of Anxiety-Related Behavior Document Type Dissertation Degree Name Doctor of Philosophy (PhD) Program Anatomy and Neurobiology Research Advisor Robert W. Williams, Ph.D. Committee John D. Boughter, Ph.D. Eldon E. Geisert, Ph.D. Kristin M. Hamre, Ph.D. Jeffery D. Steketee, Ph.D. DOI 10.21007/etd.cghs.2009.0219 This dissertation is available at UTHSC Digital -

Prediction of Meiosis-Essential Genes Based on Dynamic Proteomes Responsive to Spermatogenesis
bioRxiv preprint doi: https://doi.org/10.1101/2020.02.05.936435; this version posted February 16, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC 4.0 International license. Prediction of meiosis-essential genes based on dynamic proteomes responsive to spermatogenesis Kailun Fang1,2,3,8, Qidan Li3,4,5,8, Yu Wei2,3,8, Jiaqi Shen6,8, Wenhui Guo3,4,5,7,8, Changyang Zhou2,3,8, Ruoxi Wu1, Wenqin Ying2, Lu Yu1,2, Jin Zi5, Yuxing Zhang4,5, Hui Yang2,3,9*, Siqi Liu3,4,5,9*, Charlie Degui Chen1,3,9* 1. State Key Laboratory of Molecular Biology, Shanghai Key Laboratory of Molecular Andrology, CAS Center for Excellence in Molecular Cell Science, Shanghai Institute of Biochemistry and Cell Biology, Chinese Academy of Sciences, Shanghai 200031, China. 2. Institute of Neuroscience, State Key Laboratory of Neuroscience, Key Laboratory of Primate Neurobiology, CAS Center for Excellence in Brain Science and Intelligence Technology, Shanghai Research Center for Brain Science and Brain-Inspired Intelligence, Shanghai Institutes for Biological Sciences, Chinese Academy of Sciences, Shanghai 200031, China. 3. University of the Chinese Academy of Sciences, Beijing 100049, China. 4. CAS Key Laboratory of Genome Sciences and Information, Beijing Institute of Genomics, Chinese Academy of Sciences, Beijing 100101, China. 5. BGI Genomics, BGI-Shenzhen, Shenzhen 518083, China. 6. United World College Changshu China, Jiangsu 215500, China. 7. Malvern College Qingdao, Shandong, 266109, China 8.