Identi Cation of Key Genes Involved in Colorectal Cancer
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model
Downloaded from http://www.jimmunol.org/ by guest on September 25, 2021 T + is online at: average * The Journal of Immunology , 34 of which you can access for free at: 2016; 197:1477-1488; Prepublished online 1 July from submission to initial decision 4 weeks from acceptance to publication 2016; doi: 10.4049/jimmunol.1600589 http://www.jimmunol.org/content/197/4/1477 Molecular Profile of Tumor-Specific CD8 Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. Waugh, Sonia M. Leach, Brandon L. Moore, Tullia C. Bruno, Jonathan D. Buhrman and Jill E. Slansky J Immunol cites 95 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2016/07/01/jimmunol.160058 9.DCSupplemental This article http://www.jimmunol.org/content/197/4/1477.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 25, 2021. The Journal of Immunology Molecular Profile of Tumor-Specific CD8+ T Cell Hypofunction in a Transplantable Murine Cancer Model Katherine A. -

Minichromosome Maintenance Proteins Are Direct Targets of the ATM and ATR Checkpoint Kinases
Minichromosome maintenance proteins are direct targets of the ATM and ATR checkpoint kinases David Cortez*†, Gloria Glick*, and Stephen J. Elledge‡§ *Department of Biochemistry, Vanderbilt University, Nashville, TN 37232; and ‡Department of Genetics, Center for Genetics and Genomics, and Howard Hughes Medical Institute, Harvard University Medical School, Boston, MA 02115 Contributed by Stephen J. Elledge, May 13, 2004 The minichromosome maintenance (MCM) 2-7 helicase complex unclear how they could be reassembled because replication functions to initiate and elongate replication forks. Cell cycle licensing is not allowed once S phase has begun (26). Continued checkpoint signaling pathways regulate DNA replication to main- MCM activity at a stalled replication fork may also be delete- tain genomic stability. We describe four lines of evidence that rious because it would expose extensive regions of single- ATM/ATR-dependent (ataxia-telangiectasia-mutated͞ATM- and stranded DNA, precisely the phenotype observed in S. cerevisiae Rad3-related) checkpoint pathways are directly linked to three checkpoint mutants treated with hydroxyurea (HU) (9). Fur- members of the MCM complex. First, ATM phosphorylates MCM3 thermore, short stretches of single-stranded DNA that might on S535 in response to ionizing radiation. Second, ATR phosphor- accumulate at stalled forks because of MCM action may be ylates MCM2 on S108 in response to multiple forms of DNA damage essential to recruiting the ATR-ATRIP complex and activating and stalling of replication forks. Third, ATR-interacting protein the S-phase checkpoint. In this study, we found four direct (ATRIP)-ATR interacts with MCM7. Fourth, reducing the amount of connections between the ATR͞ATM checkpoint pathways and MCM7 in cells disrupts checkpoint signaling and causes an intra- the MCM proteins. -

Identification of Conserved Genes Triggering Puberty in European Sea
Blázquez et al. BMC Genomics (2017) 18:441 DOI 10.1186/s12864-017-3823-2 RESEARCHARTICLE Open Access Identification of conserved genes triggering puberty in European sea bass males (Dicentrarchus labrax) by microarray expression profiling Mercedes Blázquez1,2* , Paula Medina1,2,3, Berta Crespo1,4, Ana Gómez1 and Silvia Zanuy1* Abstract Background: Spermatogenesisisacomplexprocesscharacterized by the activation and/or repression of a number of genes in a spatio-temporal manner. Pubertal development in males starts with the onset of the first spermatogenesis and implies the division of primary spermatogonia and their subsequent entry into meiosis. This study is aimed at the characterization of genes involved in the onset of puberty in European sea bass, and constitutes the first transcriptomic approach focused on meiosis in this species. Results: European sea bass testes collected at the onset of puberty (first successful reproduction) were grouped in stage I (resting stage), and stage II (proliferative stage). Transition from stage I to stage II was marked by an increase of 11ketotestosterone (11KT), the main fish androgen, whereas the transcriptomic study resulted in 315 genes differentially expressed between the two stages. The onset of puberty induced 1) an up-regulation of genes involved in cell proliferation, cell cycle and meiosis progression, 2) changes in genes related with reproduction and growth, and 3) a down-regulation of genes included in the retinoic acid (RA) signalling pathway. The analysis of GO-terms and biological pathways showed that cell cycle, cell division, cellular metabolic processes, and reproduction were affected, consistent with the early events that occur during the onset of puberty. -
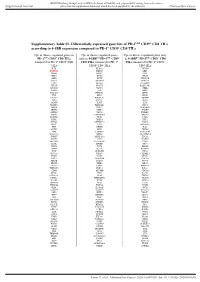
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

Bioinformatics-Based Screening of Key Genes for Transformation of Liver
Jiang et al. J Transl Med (2020) 18:40 https://doi.org/10.1186/s12967-020-02229-8 Journal of Translational Medicine RESEARCH Open Access Bioinformatics-based screening of key genes for transformation of liver cirrhosis to hepatocellular carcinoma Chen Hao Jiang1,2, Xin Yuan1,2, Jiang Fen Li1,2, Yu Fang Xie1,2, An Zhi Zhang1,2, Xue Li Wang1,2, Lan Yang1,2, Chun Xia Liu1,2, Wei Hua Liang1,2, Li Juan Pang1,2, Hong Zou1,2, Xiao Bin Cui1,2, Xi Hua Shen1,2, Yan Qi1,2, Jin Fang Jiang1,2, Wen Yi Gu4, Feng Li1,2,3 and Jian Ming Hu1,2* Abstract Background: Hepatocellular carcinoma (HCC) is the most common type of liver tumour, and is closely related to liver cirrhosis. Previous studies have focussed on the pathogenesis of liver cirrhosis developing into HCC, but the molecular mechanism remains unclear. The aims of the present study were to identify key genes related to the transformation of cirrhosis into HCC, and explore the associated molecular mechanisms. Methods: GSE89377, GSE17548, GSE63898 and GSE54236 mRNA microarray datasets from Gene Expression Omni- bus (GEO) were analysed to obtain diferentially expressed genes (DEGs) between HCC and liver cirrhosis tissues, and network analysis of protein–protein interactions (PPIs) was carried out. String and Cytoscape were used to analyse modules and identify hub genes, Kaplan–Meier Plotter and Oncomine databases were used to explore relationships between hub genes and disease occurrence, development and prognosis of HCC, and the molecular mechanism of the main hub gene was probed using Kyoto Encyclopedia of Genes and Genomes(KEGG) pathway analysis. -

Supplementary Table S1. Correlation Between the Mutant P53-Interacting Partners and PTTG3P, PTTG1 and PTTG2, Based on Data from Starbase V3.0 Database
Supplementary Table S1. Correlation between the mutant p53-interacting partners and PTTG3P, PTTG1 and PTTG2, based on data from StarBase v3.0 database. PTTG3P PTTG1 PTTG2 Gene ID Coefficient-R p-value Coefficient-R p-value Coefficient-R p-value NF-YA ENSG00000001167 −0.077 8.59e-2 −0.210 2.09e-6 −0.122 6.23e-3 NF-YB ENSG00000120837 0.176 7.12e-5 0.227 2.82e-7 0.094 3.59e-2 NF-YC ENSG00000066136 0.124 5.45e-3 0.124 5.40e-3 0.051 2.51e-1 Sp1 ENSG00000185591 −0.014 7.50e-1 −0.201 5.82e-6 −0.072 1.07e-1 Ets-1 ENSG00000134954 −0.096 3.14e-2 −0.257 4.83e-9 0.034 4.46e-1 VDR ENSG00000111424 −0.091 4.10e-2 −0.216 1.03e-6 0.014 7.48e-1 SREBP-2 ENSG00000198911 −0.064 1.53e-1 −0.147 9.27e-4 −0.073 1.01e-1 TopBP1 ENSG00000163781 0.067 1.36e-1 0.051 2.57e-1 −0.020 6.57e-1 Pin1 ENSG00000127445 0.250 1.40e-8 0.571 9.56e-45 0.187 2.52e-5 MRE11 ENSG00000020922 0.063 1.56e-1 −0.007 8.81e-1 −0.024 5.93e-1 PML ENSG00000140464 0.072 1.05e-1 0.217 9.36e-7 0.166 1.85e-4 p63 ENSG00000073282 −0.120 7.04e-3 −0.283 1.08e-10 −0.198 7.71e-6 p73 ENSG00000078900 0.104 2.03e-2 0.258 4.67e-9 0.097 3.02e-2 Supplementary Table S2. -

The Consequences of Differential Origin Licensing Dynamics in Distinct Chromatin Environments
bioRxiv preprint doi: https://doi.org/10.1101/2021.06.28.450210; this version posted July 10, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. The consequences of differential origin licensing dynamics in distinct chromatin environments Liu Mei1, Katarzyna M. Kedziora2, Eun-Ah Song2, Jeremy E. Purvis2, and Jeanette Gowen Cook1,* 1 Department of Biochemistry & Biophysics 2 Department of Genetics 3 Bioinformatics and Analytics Research Collaborative (BARC) University of North Carolina at Chapel Hill, NC 27599 * To whom correspondence should be addressed. Tel: 1-919-843-3867 Email: [email protected] ABSTRACT MCM complexes are loaded onto chromosomes to license DNA replication origins in G1 phase of the cell cycle, but it is not yet known how mammalian MCM complexes are adequately distributed to both euchromatin and heterochromatin. To address this question, we combined time-lapse live-cell imaging with fixed cell immunofluorescence imaging of single human cells to quantify the relative rates of MCM loading in heterochromatin and euchromatin at different times within G1. We report here that MCM loading in euchromatin is faster than in heterochromatin in very early G1, but surprisingly, heterochromatin loading accelerates relative to euchromatin loading in middle and late G1. These different loading dynamics require ORCA-dependent differences in ORC distribution during G1. A consequence of heterochromatin origin licensing dynamics is that cells experiencing a truncated G1 phase from premature cyclin E expression enter S phase with under-licensed heterochromatin, and DNA damage accumulates preferentially in heterochromatin in the subsequent S/G2 phase. -

Cdna Library Screening Identifies Protein Interactors Potentially
ORIGINAL RESEARCH published: 12 November 2015 doi: 10.3389/fpls.2015.00985 cDNA Library Screening Identifies Protein Interactors Potentially Involved in Non-Telomeric Roles of Arabidopsis Telomerase Ladislav Dokládal1,2,DavidHonys3, Rajiv Rana3, Lan-Ying Lee4, Stanton B. Gelvin4 and Eva Sýkorová1,2* 1 Mendel Centre for Plant Genomics and Proteomics, Central European Institute of Technology and Faculty of Science, Masaryk University, Brno, Czech Republic, 2 Institute of Biophysics – Academy of Sciences of the Czech Republic v.v.i., Brno, Czech Republic, 3 Institute of Experimental Botany – Academy of Sciences of the Czech Republic v.v.i., Prague, Czech Republic, 4 Department of Biological Sciences, Purdue University, West Lafayette, IN, USA Telomerase-reverse transcriptase (TERT) plays an essential catalytic role in maintaining telomeres. However, in animal systems telomerase plays additional non-telomeric functional roles. We previously screened an Arabidopsis cDNA library for proteins that interact with the C-terminal extension (CTE) TERT domain and identified a nuclear- localized protein that contains an RNA recognition motif (RRM). This RRM-protein forms homodimers in both plants and yeast. Mutation of the gene encoding the RRM-protein Edited by: Inna Lermontova, had no detectable effect on plant growth and development, nor did it affect telomerase Leibniz Institute of Plant Genetics activity or telomere length in vivo, suggesting a non-telomeric role for TERT/RRM- and Crop Plant Research, Germany protein complexes. The gene encoding the RRM-protein is highly expressed in leaf Reviewed by: and reproductive tissues. We further screened an Arabidopsis cDNA library for proteins Biswapriya Biswavas Misra, University of Florida, USA that interact with the RRM-protein and identified five interactors. -

Gene Expression Changes in Cervical Squamous Cancers Following Neoadjuvant Interventional Chemoembolization
Clinica Chimica Acta 493 (2019) 79–86 Contents lists available at ScienceDirect Clinica Chimica Acta journal homepage: www.elsevier.com/locate/cca Gene expression changes in cervical squamous cancers following T neoadjuvant interventional chemoembolization Yonghua Chena,1, Yuanyuan Houa,1, Ying Yanga,1, Meixia Panb, Jing Wanga, Wenshuang Wanga, Ying Zuoa, Jianglin Conga, Xiaojie Wanga, Nan Mua, Chenglin Zhangc, Benjiao Gongc, ⁎ ⁎ Jianqing Houa, , Shaoguang Wanga, , Liping Xud a Department of Obstetrics and Gynecology, the Affiliated Yantai Yuhuangding Hospital of Medical College, Qingdao University, Yantai 264000, Shandong, China b Yantai Yuhuangding Hospital LaiShan Division of Medical College, Qingdao University, China c Central Laboratory, the Affiliated Yantai Yuhuangding Hospital of Medical College, Qingdao University, Yantai 264000, Shandong, China d Medical College, Qingdao University, Qingdao 266021, Shandong, China ARTICLE INFO ABSTRACT Keywords: Background: The efficacy of therapy for cervical cancer is related to the alteration of multiple molecular events Cervical cancer and signaling networks during treatment. The aim of this study was to evaluate gene expression alterations in Chemoembolization advanced cervical cancers before- and after-trans-uterine arterial chemoembolization- (TUACE). Microarray Methods: Gene expression patterns in three squamous cell cervical cancers before- and after-TUACE were de- AKAP12 termined using microarray technique. Changes in AKAP12 and CA9 genes following TUACE were validated by CA9 quantitative real-time PCR. Results: Unsupervised cluster analysis revealed that the after-TUACE samples clustered together, which were separated from the before-TUACE samples. Using a 2-fold threshold, we identified 1131 differentially expressed genes that clearly discriminate after-TUACE tumors from before-TUACE tumors, including 209 up-regulated genes and 922 down-regulated genes. -

ATM Requirement in Gene Expression Responses to Ionizing Radiation in Human Lymphoblasts and Fibroblasts
ATM Requirement in Gene Expression Responses to Ionizing Radiation in Human Lymphoblasts and Fibroblasts Cynthia L. Innes,1 Alexandra N. Heinloth,2 Kristina G. Flores,1 Stella O. Sieber,2 Paula B. Deming,3 Pierre R. Bushel,2 William K. Kaufmann,3 and Richard S. Paules1,2 1Growth Control and Cancer Group, and 2National Institute of Environmental Health Sciences Microarray Group, National Institute of Environmental Health Sciences, Research Triangle Park, North Carolina; 3Department of Pathology and Laboratory Medicine, University of North Carolina at Chapel Hill School of Medicine, Chapel Hill, North Carolina Abstract sensitivity to DNA-damaging agents (6-8). The human genome The heritable disorder ataxia telangiectasia (AT) is is exposed to many forms of DNA damage and it is critical for caused by mutations in the AT-mutated (ATM) gene with health to maintain signaling pathways that repair such damage. manifestations that include predisposition to IR damages DNA, eliciting cell cycle checkpoint responses to lymphoproliferative cancers and hypersensitivity to discontinue proliferation until damage is repaired. It is known ionizing radiation (IR). We investigated gene expression that in different types of cells, different signaling pathways are changes in response to IR in human lymphoblasts and activated in response to stress (9). Therefore, we compared the fibroblasts from seven normal and seven AT-affected role of ATM signaling in response to DNA damage in human individuals. Both cell types displayed ATM-dependent lymphoblasts and human fibroblasts using microarray technol- gene expression changes after IR, with some responses ogy to examine gene expression responses to exposure to IR. shared and some responses varying with cell type and dose. -

Oxidized Phospholipids Regulate Amino Acid Metabolism Through MTHFD2 to Facilitate Nucleotide Release in Endothelial Cells
ARTICLE DOI: 10.1038/s41467-018-04602-0 OPEN Oxidized phospholipids regulate amino acid metabolism through MTHFD2 to facilitate nucleotide release in endothelial cells Juliane Hitzel1,2, Eunjee Lee3,4, Yi Zhang 3,5,Sofia Iris Bibli2,6, Xiaogang Li7, Sven Zukunft 2,6, Beatrice Pflüger1,2, Jiong Hu2,6, Christoph Schürmann1,2, Andrea Estefania Vasconez1,2, James A. Oo1,2, Adelheid Kratzer8,9, Sandeep Kumar 10, Flávia Rezende1,2, Ivana Josipovic1,2, Dominique Thomas11, Hector Giral8,9, Yannick Schreiber12, Gerd Geisslinger11,12, Christian Fork1,2, Xia Yang13, Fragiska Sigala14, Casey E. Romanoski15, Jens Kroll7, Hanjoong Jo 10, Ulf Landmesser8,9,16, Aldons J. Lusis17, 1234567890():,; Dmitry Namgaladze18, Ingrid Fleming2,6, Matthias S. Leisegang1,2, Jun Zhu 3,4 & Ralf P. Brandes1,2 Oxidized phospholipids (oxPAPC) induce endothelial dysfunction and atherosclerosis. Here we show that oxPAPC induce a gene network regulating serine-glycine metabolism with the mitochondrial methylenetetrahydrofolate dehydrogenase/cyclohydrolase (MTHFD2) as a cau- sal regulator using integrative network modeling and Bayesian network analysis in human aortic endothelial cells. The cluster is activated in human plaque material and by atherogenic lipo- proteins isolated from plasma of patients with coronary artery disease (CAD). Single nucleotide polymorphisms (SNPs) within the MTHFD2-controlled cluster associate with CAD. The MTHFD2-controlled cluster redirects metabolism to glycine synthesis to replenish purine nucleotides. Since endothelial cells secrete purines in response to oxPAPC, the MTHFD2- controlled response maintains endothelial ATP. Accordingly, MTHFD2-dependent glycine synthesis is a prerequisite for angiogenesis. Thus, we propose that endothelial cells undergo MTHFD2-mediated reprogramming toward serine-glycine and mitochondrial one-carbon metabolism to compensate for the loss of ATP in response to oxPAPC during atherosclerosis. -

Original Article Expression and Prognostic Significance of MCM-3 and MCM-7 in Salivary Adenoid Cystic Carcinoma
Int J Clin Exp Pathol 2018;11(11):5359-5369 www.ijcep.com /ISSN:1936-2625/IJCEP0085911 Original Article Expression and prognostic significance of MCM-3 and MCM-7 in salivary adenoid cystic carcinoma Qing-Liang Wen1,2,3*, Sen-Miao Zhu5*, Lie-Hao Jiang2,3*, Fang-Yue Xiang6, Wen-Juan Yin4, Yang-Yang Qian1,2,3, Yu-Qing Huang3,7, Ke-Xin Yin7, Xin Zhu8, Ming-Hua Ge1,2,3 1The First Affiliated Hospital of Wenzhou Medical University, Ouhai District, Wenzhou, China; 2Department of Thyroid and Breast Surgery, Zhejiang Provincial People’s Hospital, Gongshu District, Hangzhou, China; Depart- ments of 3Head and Neck Surgery, 4Pathology, Zhejiang Cancer Hospital, Gongshu District, Hangzhou, China; 5The Second Affiliated Hospital of Wenzhou Medical University, Lucheng District, Wenzhou, China; 6Stomatology Col- lege, 7Second Clinical Medical College, Zhejiang Chinese Medical University, Binjiang District, Hangzhou, China; 8Zhejiang Cancer Research Institute, Zhejiang Province Cancer Hospital, Gongshu District, Hangzhou, China. *Equal contributors. Received September 24, 2018; Accepted October 25, 2018; Epub November 1, 2018; Published November 15, 2018 Abstract: This study sought to investigate minichromosome maintenance protein 3 (MCM3) and minichromosome maintenance protein 7 (MCM7) expression in salivary adenoid cystic carcinoma (SACC) samples, and to evaluate the relationship between clinicopathological characteristics and prognosis. The expressions of MCM3 and MCM7 were evaluated using immunohistochemistry of tissue sections from SACC patients, and statistical analyses were performed to evaluate the associations between MCM expression and clinicopathological variables and to analyze the disease-free survival (DFS) and prognostic factors. The positive expression rates of MCM3 and MCM7 in SACC were 98.8% and 96.6%, respectively.