A Skew Laplace Distribution on Integers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supplementary Materials
Int. J. Environ. Res. Public Health 2018, 15, 2042 1 of 4 Supplementary Materials S1) Re-parametrization of log-Laplace distribution The three-parameter log-Laplace distribution, LL(δ ,,ab) of relative risk, μ , is given by the probability density function b−1 μ ,0<<μ δ 1 ab δ f ()μ = . δ ab+ a+1 δ , μ ≥ δ μ 1−τ τ Let b = and a = . Hence, the probability density function of LL( μ ,,τσ) can be re- σ σ τ written as b μ ,0<<=μ δ exp(μ ) 1 ab δ f ()μ = ya+ b δ a μδ≥= μ ,exp() μ 1 ab exp(b (log(μμ )−< )), log( μμ ) = μ ab+ exp(a (μμ−≥ log( ))), log( μμ ) 1 ab exp(−−b| log(μμ ) |), log( μμ ) < = μ ab+ exp(−−a|μμ log( ) |), log( μμ ) ≥ μμ− −−τ | log( )τ | μμ < exp (1 ) , log( ) τ 1(1)ττ− σ = μσ μμ− −≥τμμ| log( )τ | exp , log( )τ . σ S2) Bayesian quantile estimation Let Yi be the continuous response variable i and Xi be the corresponding vector of covariates with the first element equals one. At a given quantile levelτ ∈(0,1) , the τ th conditional quantile T i i = β τ QY(|X ) τ of y given X is then QYτ (|iiXX ) ii ()where τ iiis the th conditional quantile and β τ i ()is a vector of quantile coefficients. Contrary to the mean regression generally aiming to minimize the squared loss function, the quantile regression links to a special class of check or loss τ βˆ τ function. The th conditional quantile can be estimated by any solution, i (), such that ββˆ τ =−ρ T τ ρ =−<τ iiii() argmini τ (Y X ()) where τ ()zz ( Iz ( 0))is the quantile loss function given in (1) and I(.) is the indicator function. -

Discrete Probability Distributions Uniform Distribution Bernoulli
Discrete Probability Distributions Uniform Distribution Experiment obeys: all outcomes equally probable Random variable: outcome Probability distribution: if k is the number of possible outcomes, 1 if x is a possible outcome p(x)= k ( 0 otherwise Example: tossing a fair die (k = 6) Bernoulli Distribution Experiment obeys: (1) a single trial with two possible outcomes (success and failure) (2) P trial is successful = p Random variable: number of successful trials (zero or one) Probability distribution: p(x)= px(1 − p)n−x Mean and variance: µ = p, σ2 = p(1 − p) Example: tossing a fair coin once Binomial Distribution Experiment obeys: (1) n repeated trials (2) each trial has two possible outcomes (success and failure) (3) P ith trial is successful = p for all i (4) the trials are independent Random variable: number of successful trials n x n−x Probability distribution: b(x; n,p)= x p (1 − p) Mean and variance: µ = np, σ2 = np(1 − p) Example: tossing a fair coin n times Approximations: (1) b(x; n,p) ≈ p(x; λ = pn) if p ≪ 1, x ≪ n (Poisson approximation) (2) b(x; n,p) ≈ n(x; µ = pn,σ = np(1 − p) ) if np ≫ 1, n(1 − p) ≫ 1 (Normal approximation) p Geometric Distribution Experiment obeys: (1) indeterminate number of repeated trials (2) each trial has two possible outcomes (success and failure) (3) P ith trial is successful = p for all i (4) the trials are independent Random variable: trial number of first successful trial Probability distribution: p(x)= p(1 − p)x−1 1 2 1−p Mean and variance: µ = p , σ = p2 Example: repeated attempts to start -

Chapter 5 Sections
Chapter 5 Chapter 5 sections Discrete univariate distributions: 5.2 Bernoulli and Binomial distributions Just skim 5.3 Hypergeometric distributions 5.4 Poisson distributions Just skim 5.5 Negative Binomial distributions Continuous univariate distributions: 5.6 Normal distributions 5.7 Gamma distributions Just skim 5.8 Beta distributions Multivariate distributions Just skim 5.9 Multinomial distributions 5.10 Bivariate normal distributions 1 / 43 Chapter 5 5.1 Introduction Families of distributions How: Parameter and Parameter space pf /pdf and cdf - new notation: f (xj parameters ) Mean, variance and the m.g.f. (t) Features, connections to other distributions, approximation Reasoning behind a distribution Why: Natural justification for certain experiments A model for the uncertainty in an experiment All models are wrong, but some are useful – George Box 2 / 43 Chapter 5 5.2 Bernoulli and Binomial distributions Bernoulli distributions Def: Bernoulli distributions – Bernoulli(p) A r.v. X has the Bernoulli distribution with parameter p if P(X = 1) = p and P(X = 0) = 1 − p. The pf of X is px (1 − p)1−x for x = 0; 1 f (xjp) = 0 otherwise Parameter space: p 2 [0; 1] In an experiment with only two possible outcomes, “success” and “failure”, let X = number successes. Then X ∼ Bernoulli(p) where p is the probability of success. E(X) = p, Var(X) = p(1 − p) and (t) = E(etX ) = pet + (1 − p) 8 < 0 for x < 0 The cdf is F(xjp) = 1 − p for 0 ≤ x < 1 : 1 for x ≥ 1 3 / 43 Chapter 5 5.2 Bernoulli and Binomial distributions Binomial distributions Def: Binomial distributions – Binomial(n; p) A r.v. -

Some Properties of the Log-Laplace Distribution* V
SOME PROPERTIES OF THE LOG-LAPLACE DISTRIBUTION* V, R. R. Uppuluri Mathematics and Statistics Research Department Computer Sciences Division Union Carbide Corporation, Nuclear Division Oak Ridge, Tennessee 37830 B? accSpBficS of iMS artlclS* W8 tfcHteHef of Recipient acKnowta*g«9 th« U.S. Government's right to retain a non - excluslva, royalty - frw Jlcqns* In JMWl JS SOX 50j.yrt«ltt BfiXSflng IM -DISCLAIMER . This book w« prtMtM n in nonim nl mrk moniond by m vncy of At UnllM Sum WM»> ih« UWIrt SUM Oow.n™»i nor an, qprcy IMrw, w «v ol Ifmf mptovMi. mkn «iy w»ti«y, nptoi Of ImolM. « »u~i •ny U»l liability or tBpomlbllliy lof Ihe nary, ramoloweB. nr unhtlm at mi Womwlon, appmlui, product, or pram dliclowl. or rwromti that lu u« acuU r»i MMngt prhiltly ownad rljM<- flihmot Mi to any malic lomnwclal product. HOCOI. 0. »tvlc by ttada naw. tradtimr», mareittciunr. or otktmte, taa not rucaaainy coralltun or Imply In anoonamnt, nKommendailon. o» Iworlnj by a, Unilid SUM Oowrnment or m atncy limml. Th, Amnd ooMora ol «iihon ncrtwd fmtin dn not tauaaruv iu» or nlfcn thoaot tt» Unltad Sum GiMmrmt or any agmv trmot. •Research sponsored by the Applied Mathematical Sciences Research Program, Office of Energy Research, U.S. Department of Energy, under contract W-74Q5-eng-26 with the Union Carbide Corporation. DISTRIBii.il i yf T!it3 OGCUHEiU IS UHLIKITEOr SOME PROPERTIES OF THE LOS-LAPLACE DISTRIBUTION V. R. R. Uppuluri ABSTRACT A random variable Y is said to have the Laplace distribution or the double exponential distribution whenever its probability density function is given by X exp(-A|y|), where -» < y < ~ and X > 0. -

(Introduction to Probability at an Advanced Level) - All Lecture Notes
Fall 2018 Statistics 201A (Introduction to Probability at an advanced level) - All Lecture Notes Aditya Guntuboyina August 15, 2020 Contents 0.1 Sample spaces, Events, Probability.................................5 0.2 Conditional Probability and Independence.............................6 0.3 Random Variables..........................................7 1 Random Variables, Expectation and Variance8 1.1 Expectations of Random Variables.................................9 1.2 Variance................................................ 10 2 Independence of Random Variables 11 3 Common Distributions 11 3.1 Ber(p) Distribution......................................... 11 3.2 Bin(n; p) Distribution........................................ 11 3.3 Poisson Distribution......................................... 12 4 Covariance, Correlation and Regression 14 5 Correlation and Regression 16 6 Back to Common Distributions 16 6.1 Geometric Distribution........................................ 16 6.2 Negative Binomial Distribution................................... 17 7 Continuous Distributions 17 7.1 Normal or Gaussian Distribution.................................. 17 1 7.2 Uniform Distribution......................................... 18 7.3 The Exponential Density...................................... 18 7.4 The Gamma Density......................................... 18 8 Variable Transformations 19 9 Distribution Functions and the Quantile Transform 20 10 Joint Densities 22 11 Joint Densities under Transformations 23 11.1 Detour to Convolutions...................................... -

Lecture Notes #17: Some Important Distributions and Coupon Collecting
EECS 70 Discrete Mathematics and Probability Theory Spring 2014 Anant Sahai Note 17 Some Important Distributions In this note we will introduce three important probability distributions that are widely used to model real- world phenomena. The first of these which we already learned about in the last Lecture Note is the binomial distribution Bin(n; p). This is the distribution of the number of Heads, Sn, in n tosses of a biased coin with n k n−k probability p to be Heads. As we saw, P[Sn = k] = k p (1 − p) . E[Sn] = np, Var[Sn] = np(1 − p) and p s(Sn) = np(1 − p). Geometric Distribution Question: A biased coin with Heads probability p is tossed repeatedly until the first Head appears. What is the distribution and the expected number of tosses? As always, our first step in answering the question must be to define the sample space W. A moment’s thought tells us that W = fH;TH;TTH;TTTH;:::g; i.e., W consists of all sequences over the alphabet fH;Tg that end with H and contain no other H’s. This is our first example of an infinite sample space (though it is still discrete). What is the probability of a sample point, say w = TTH? Since successive coin tosses are independent (this is implicit in the statement of the problem), we have Pr[TTH] = (1 − p) × (1 − p) × p = (1 − p)2 p: And generally, for any sequence w 2 W of length i, we have Pr[w] = (1 − p)i−1 p. -

Lecture 8: Geometric and Binomial Distributions
Recap Dangling thread from last time From OpenIntro quiz 2: Lecture 8: Geometric and Binomial distributions Statistics 101 Mine C¸etinkaya-Rundel P(took j not valuable) September 22, 2011 P(took and not valuable) = P(not valuable) 0:1403 = 0:1403 + 0:5621 = 0:1997 Statistics 101 (Mine C¸etinkaya-Rundel) L8: Geometric and Binomial September 22, 2011 1 / 27 Recap Geometric distribution Bernoulli distribution Milgram experiment Clicker question (graded) Stanley Milgram, a Yale University psychologist, conducted a series of Which of the following is false? experiments on obedience to authority starting in 1963. Experimenter (E) orders the teacher (a) The Z score for the mean of a distribution of any shape is 0. (T), the subject of the experiment, to (b) Half the observations in a distribution of any shape have positive give severe electric shocks to a Z scores. learner (L) each time the learner (c) The median of a right skewed distribution has a negative Z score. answers a question incorrectly. (d) Majority of the values in a left skewed distribution have positive Z The learner is actually an actor, and scores. the electric shocks are not real, but a prerecorded sound is played each time the teacher administers an electric shock. Statistics 101 (Mine C¸etinkaya-Rundel) L8: Geometric and Binomial September 22, 2011 2 / 27 Statistics 101 (Mine C¸etinkaya-Rundel) L8: Geometric and Binomial September 22, 2011 3 / 27 Geometric distribution Bernoulli distribution Geometric distribution Bernoulli distribution Milgram experiment (cont.) Bernouilli random variables These experiments measured the willingness of study Each person in Milgram’s experiment can be thought of as a trial. -

Discrete Probability Distributions Geometric and Negative Binomial Illustrated by Mitochondrial Eve and Cancer Driv
Discrete Probability Distributions Geometric and Negative Binomial illustrated by Mitochondrial Eve and Cancer Driver/Passenger Genes Binomial Distribution • Number of successes in n independent Bernoulli trials • The probability mass function is: nx nx PX x Cpx 1 p for x 0,1,... n (3-7) Sec 3=6 Binomial Distribution 2 Geometric Distribution • A series of Bernoulli trials with probability of success =p. continued until the first success. X is the number of trials. • Compare to: Binomial distribution has: – Fixed number of trials =n. nx nx PX x Cpx 1 p – Random number of successes = x. • Geometric distribution has reversed roles: – Random number of trials, x – Fixed number of successes, in this case 1. n – Success always comes in the end: so no combinatorial factor Cx – P(X=x) = p(1‐p)x‐1 where: x‐1 = 0, 1, 2, … , the number of failures until the 1st success. • NOTE OF CAUTION: Matlab, Mathematica, and many other sources use x to denote the number of failures until the first success. We stick with Montgomery‐Runger notation 3 Geometric Mean & Variance • If X is a geometric random variable (according to Montgomery‐Bulmer) with parameter p, 1 1 p EX and 2 VX (3-10) pp2 • For small p the standard deviation ~= mean • Very different from Poisson, where it is variance = mean and standard deviation = mean1/2 Sec 3‐7 Geometric & Negative Binomial 4 Distributions Geometric distribution in biology • Each of our cells has mitochondria with 16.5kb of mtDNA inherited only from our mother • Human mtDNA has 37 genes encoding 13 proteins, 22+2 tRNA & rRNA • Mitochondria appeared 1.5‐2 billion years ago as a symbiosis between an alpha‐proteobacterium (1000s of genes) and an archaeaon (of UIUC’s Carl R. -
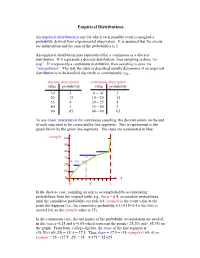
Discrete Distributions: Empirical, Bernoulli, Binomial, Poisson
Empirical Distributions An empirical distribution is one for which each possible event is assigned a probability derived from experimental observation. It is assumed that the events are independent and the sum of the probabilities is 1. An empirical distribution may represent either a continuous or a discrete distribution. If it represents a discrete distribution, then sampling is done “on step”. If it represents a continuous distribution, then sampling is done via “interpolation”. The way the table is described usually determines if an empirical distribution is to be handled discretely or continuously; e.g., discrete description continuous description value probability value probability 10 .1 0 – 10- .1 20 .15 10 – 20- .15 35 .4 20 – 35- .4 40 .3 35 – 40- .3 60 .05 40 – 60- .05 To use linear interpolation for continuous sampling, the discrete points on the end of each step need to be connected by line segments. This is represented in the graph below by the green line segments. The steps are represented in blue: rsample 60 50 40 30 20 10 0 x 0 .5 1 In the discrete case, sampling on step is accomplished by accumulating probabilities from the original table; e.g., for x = 0.4, accumulate probabilities until the cumulative probability exceeds 0.4; rsample is the event value at the point this happens (i.e., the cumulative probability 0.1+0.15+0.4 is the first to exceed 0.4, so the rsample value is 35). In the continuous case, the end points of the probability accumulation are needed, in this case x=0.25 and x=0.65 which represent the points (.25,20) and (.65,35) on the graph. -

Machine Learning - HT 2016 3
Machine learning - HT 2016 3. Maximum Likelihood Varun Kanade University of Oxford January 27, 2016 Outline Probabilistic Framework � Formulate linear regression in the language of probability � Introduce the maximum likelihood estimate � Relation to least squares estimate Basics of Probability � Univariate and multivariate normal distribution � Laplace distribution � Likelihood, Entropy and its relation to learning 1 Univariate Gaussian (Normal) Distribution The univariate normal distribution is defined by the following density function (x µ)2 1 − 2 p(x) = e− 2σ2 X (µ,σ ) √2πσ ∼N Hereµ is the mean andσ 2 is the variance. 2 Sampling from a Gaussian distribution Sampling fromX (µ,σ 2) ∼N X µ By settingY= − , sample fromY (0, 1) σ ∼N Cumulative distribution function x 1 t2 Φ(x) = e− 2 dt √2π �−∞ 3 Covariance and Correlation For random variableX andY the covariance measures how the random variable change jointly. cov(X, Y)=E[(X E[X])(Y E[Y ])] − − Covariance depends on the scale of the random variable. The (Pearson) correlation coefficient normalizes the covariance to give a value between 1 and +1. − cov(X, Y) corr(X, Y)= , σX σY 2 2 2 2 whereσ X =E[(X E[X]) ] andσ Y =E[(Y E[Y]) ]. − − 4 Multivariate Gaussian Distribution Supposex is an-dimensional random vector. The covariance matrix consists of all pariwise covariances. var(X ) cov(X ,X ) cov(X ,X ) 1 1 2 ··· 1 n cov(X2,X1) var(X2) cov(X 2,Xn) T ··· cov(x) =E (x E[x])(x E[x]) = . . − − . � � . cov(Xn,X1) cov(Xn,X2) var(X n,Xn) ··· Ifµ=E[x] andΣ = cov[x], the multivariate normal is defined by the density 1 1 T 1 (µ,Σ) = exp (x µ) Σ− (x µ) N (2π)n/2 Σ 1/2 − 2 − − | | � � 5 Bivariate Gaussian Distribution 2 2 SupposeX 1 (µ 1,σ ) andX 2 (µ 2,σ ) ∼N 1 ∼N 2 What is the joint probability distributionp(x 1, x2)? 6 Suppose you are given three independent samples: x1 = 1, x2 = 2.7, x3 = 3. -

Field Guide to Continuous Probability Distributions
Field Guide to Continuous Probability Distributions Gavin E. Crooks v 1.0.0 2019 G. E. Crooks – Field Guide to Probability Distributions v 1.0.0 Copyright © 2010-2019 Gavin E. Crooks ISBN: 978-1-7339381-0-5 http://threeplusone.com/fieldguide Berkeley Institute for Theoretical Sciences (BITS) typeset on 2019-04-10 with XeTeX version 0.99999 fonts: Trump Mediaeval (text), Euler (math) 271828182845904 2 G. E. Crooks – Field Guide to Probability Distributions Preface: The search for GUD A common problem is that of describing the probability distribution of a single, continuous variable. A few distributions, such as the normal and exponential, were discovered in the 1800’s or earlier. But about a century ago the great statistician, Karl Pearson, realized that the known probabil- ity distributions were not sufficient to handle all of the phenomena then under investigation, and set out to create new distributions with useful properties. During the 20th century this process continued with abandon and a vast menagerie of distinct mathematical forms were discovered and invented, investigated, analyzed, rediscovered and renamed, all for the purpose of de- scribing the probability of some interesting variable. There are hundreds of named distributions and synonyms in current usage. The apparent diver- sity is unending and disorienting. Fortunately, the situation is less confused than it might at first appear. Most common, continuous, univariate, unimodal distributions can be orga- nized into a small number of distinct families, which are all special cases of a single Grand Unified Distribution. This compendium details these hun- dred or so simple distributions, their properties and their interrelations. -

Some Continuous and Discrete Distributions Table of Contents I
Some continuous and discrete distributions Table of contents I. Continuous distributions and transformation rules. A. Standard uniform distribution U[0; 1]. B. Uniform distribution U[a; b]. C. Standard normal distribution N(0; 1). D. Normal distribution N(¹; ). E. Standard exponential distribution. F. Exponential distribution with mean ¸. G. Standard Gamma distribution ¡(r; 1). H. Gamma distribution ¡(r; ¸). II. Discrete distributions and transformation rules. A. Bernoulli random variables. B. Binomial distribution. C. Poisson distribution. D. Geometric distribution. E. Negative binomial distribution. F. Hypergeometric distribution. 1 Continuous distributions. Each continuous distribution has a \standard" version and a more general rescaled version. The transformation from one to the other is always of the form Y = aX + b, with a > 0, and the resulting identities: y b fX ¡ f (y) = a (1) Y ³a ´ y b FY (y) = FX ¡ (2) Ã a ! E(Y ) = aE(X) + b (3) V ar(Y ) = a2V ar(X) (4) bt MY (t) = e MX (at) (5) 1 1.1 Standard uniform U[0; 1] This distribution is \pick a random number between 0 and 1". 1 if 0 < x < 1 fX (x) = ½ 0 otherwise 0 if x 0 · FX (x) = x if 0 x 1 8 · · < 1 if x 1 ¸ E(X) = 1:=2 V ar(X) = 1=12 et 1 M (t) = ¡ X t 1.2 Uniform U[a; b] This distribution is \pick a random number between a and b". To get a random number between a and b, take a random number between 0 and 1, multiply it by b a, and add a. The properties of this random variable are obtained by applying¡ rules (1{5) to the previous subsection.