Florida International University and University of Miami TRECVID 2010 - Semantic Indexing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

BARRY UNIVERSITY for the Southeast Florida Regional Partnership
PROJECT IDEA FROM BARRY UNIVERSITY for the Southeast Florida Regional Partnership Partnership Member General Information Partnership Member: Barry University, Inc. Membership Status: General Partner Address: 11300 NE Second Avenue, Miami Shores, Florida 33161 Main Contact Name: Patrick Lynch, Director, Office of Grant Programs Telephone: (305) 899-3072 Email / Website: [email protected] / www.barry.edu Are you part of the proposed Consultant Team respond to the SOQ? No Name of Directors / Officers: Barry University is governed by an independent, self- perpetuating Board of Trustees and is sponsored by the Sisters of St. Dominic of Adrian, Michigan. The Board is made up of 31 community leaders, higher education professionals and philanthropic patrons whose responsibility, according to the Articles of Incorporation, is to manage the business affairs of the University. Mr. William J. Heffernan, Chairman Eduardo A. Otero, MD Nelson L. Adams III, MD, Vice Chairman Mr. John Primeau Mr. Alejandro Aguirre Ms. Patricia M. Rosello Sister Linda Bevilacqua, OP, PhD, University President Donald S. Rosenberg, Esquire Mr. John M. Bussel Luigi Salvaneschi, PhD Patricia L. Clements, PhD Sister Corinne Sanders, OP, EdD Mr. Edward Feenane Joel H. Sharp, Jr., Esquire Sister Rosemary T. Finnegan, OP James Stelnicki, DPM Robert B. Galt III, Esquire Sister Sharon Weber, OP, PhD Mr. Gregory F. Greene Ms. Shirley McVay Wiseman Mr. Jorge A. Gross Christopher J. Gruchacz, CPA Reverend Charnel Jeanty Keith B. Kashuk, DPM Joseph P. Klock, Jr., Esquire Dr. Neta Kolasa Mrs. Olga Melin Charles R. Modica, JD Gerald W. Moore, Esquire Mr. Michael O. O’Neil, Jr. Ms. Maura Owens Barry University, Page 1 of 5 Number of Years in Business: 71 Overview and Form of Organization: A general overview of the Partnership and Consortium member and its staff, including form of organization. -

Authorizatino for 3Rd Party Disclosures
Completion Date: UNIVERSITY OF MIAMI Attachment 46 MILLER SCHOOL rd lJHealth Authorization for 3 Party Disclosures lHVERSITY Of MIAMI t£ALJH SYSTEM of MEDICINE I authorize the use or disclosure of health information about me as described below. 1. Person(s) or class of persons authorized to use or disclose the information (e.g., UHealth medical records, physician): _______________________________________________________________________________________________________ 2. Person(s) or class of persons authorized to receive the information (e.g., name & relationship: family, attorney, employer, etc.): ___________________________________________________________________________________________________________ If you would like your records to be sent to a third party, please provide an address or fax where you would like us to send the information. Please attach additional pages if more than one third party. Name: ____________________________________________ Address: __________________________________________ City: _____________________________________________ State: ______________________ Zip: _________________ Phone: _____________________________________________ Fax: _____________________________________________ 3. Description of information that may be used or disclosed (e.g., all information related to a specific type of treatment): ___________________________________________________________________________________________________________ ___________________________________________________________________________________________________________ -

Resume-January. 2020
Phone: 305.628.6635 Email: [email protected] Dr. Hagai Gringarten Selected Achievements • Founder, Publisher and Editor-in-Chief of the Journal of Multidisciplinary Research (JMR), an academic peer reviewed research journal, indexed by premier international partners such as ProQuest, Cabells, EBSCO, and Gale- Cengage. Improved brand recognition, increased exposure, created additional Web traffic, and increased the quality of published academic research. • Board member-The Florida Undergraduate Research Consortium (FURC). A consortium of 24 Florida universities and one of the nation's largest multi- disciplinary research conferences. • Co-chair of the Branding Committee Task Force for proposed St. Thomas University-Barry University merger • Co-author Ethical Branding and Marketing: Cases and Lessons. New York. Rutledge Publishing. Published in Japan, UK & USA • Co-authored Over a Cup of Coffee, a bestselling book about coffee as a consumer product, and the importance of coffee in today’s world. • As President of the American Marketing Association of South Florida, took a non-performing chapter and turned it around. Established fundamental goals and infrastructure and created a vibrant, viable chapter. • Co-founder and faculty advisor- Journal of Student Research (JSR) Education Ph.D. Lynn University, Graduate School of Business, Boca Raton, Florida. Major: Corporate and Organizational Management Doctoral Dissertation: Price and Store Image as Mitigating Factors in the Perception and Evaluation of Retailers’ Customer-Based Brand Equity. Committee Members: Senior Associate Dean, Ralph Norcio (Dissertation Chair), Dean Thomas Kruczek , and Adam Kosnitzky. 1 Post Graduate Certificate, Branding Northwestern University, Kellogg School of Management, Evanston, Illinois Post Graduate Certificate, Case Studies Harvard Graduate School of Business, Cambridge, Massachusetts M.B.A. -

Eddy A. López Solo Exhibitions Selected Group Exhibitions
UPDATED 08/21/2021 EDDY A. LÓPEZ Assistant Professor of Art l Bucknell University l Department of Art + Art History address: 310 Art Building, Bucknell University, Lewisburg, PA 17837 phone: 570.577.1619 l email: [email protected] l web: eddyalopez.com SOLO EXHIBITIONS 2022 TBD, Galeria Codice, Managua, Nicaragua. July, 2022. Postponed from 2020 due to COVID-19. Decrees, Executive Orders, Laws and Other Absurdities, Haas Gallery, Bloomsburg, University, Bloomsburg, PA. 2021 Beautiful War, Marshall University, Huntington, WV. October, 2021, Postponed from 2020 due to COVID-19. 2018 Remixes, Lycoming College Art Gallery, Lycoming College, Williamsport, PA. Beautiful War, Downtown Gallery, Samek Art Museum, Bucknell University, Lewisburg, PA. 2017 Remixes, Vandiver Gallery, South Carolina School of the Arts, Anderson University, Anderson, SC. Composites, Mattie Kelly Arts Center Gallery, Northwest Florida College, Niceville, FL. 2014 Amalgam, University of Miami Gallery at Wynwood, Miami, FL 2000 An Artist’s Quest, Power International Art Gallery, Coral Gables, FL SELECTED GROUP EXHIBITIONS 2021 International Academic Printmaking Alliance 3rd Printmaking Biennale, Central Academy of Fine Arts Art Museum, Beijing, CH. October 2020-October 2021. 41st National Print Exhibition, Artlink Contemporary Gallery, Fort Wayne, IN. Juried by Ruth Lingen. Refuge-Refugee, Northern Illinois University Art Museum, DeKalb, Il. August-November. Re-Emergence! Explorations in Photography and Printmaking, Remarque/New Grounds Print Gallery, Albuquerque, NM. July-August. Cimarron National Works on Paper Exhibition, Gardiner Gallery of Art, Oklahoma State University, Stillwater, OK. Juried by Larissa Goldston. Recollections, Bend Gallery, online exhibition. Curated by Thuong Tran & Maddie May. School of the Art Institute of Chicago, Chicago, IL. -

Project Experience
Project Experience Commercial First Bank of Miami, Kendall Branch Healthcare Historic First Bank of Miami, Coral Gables, FL United Home Care Assisted Living Facilities, Miami, FL Miami News/ Freedom Tower 355 Alhambra Plaza, Coral Gables, FL Florida Atlantic University Health Services, Boca Raton, FL Old Dillard Museum, Miami, FL 255 Aragon Avenue, Coral Gables, FL Camillus Health Concern Clinic, Miami, FL Miami Dade County School Board Ponce de Leon Middle School Westside Plaza I, Miami, FL Broward College Health Sciences Center, Boca Raton, FL Security Building, Miami, FL Westside Plaza II, Miami, FL Miami Bridge Youth Shelter Emergency Care Weiland Clinic, Coral Gables FL General Bank Hialeah Branch Residential Plaza Blue Lagoon Assisted Living Facility, Miami, FL Koubeck House, Miami, FL Republic National Bank, Miami, FL Pan American Community Health Services, Miami, FL Ingraham Building, Miami, FL Miami Dade College Medical Center Campus Charles Deering Estate, Miami, FL Education University of Miami, Batchelor Children’s Research Institute San Carlos Institute, Key West, FL Miami Dade County Public Schools Miami Central Senior High School Florida State University, College of Law, Tallahassee, FL Miami Dade County Public Schools Ponce de Leon Middle School Interiors Granada House, Coral Gables, FL Miami Dade College Aquatic Center Del Monte Fresh Produce Food Lab, Miami, FL Alhambra Circle House, Coral Gables, FL Miami Dade College Inter American Campus John S. and James L. Knight Foundation, Chinese Village House, Coral Gables, FL -

Miami DDA Master Plan
DOWNTOWN MIAMI DWNTWN MIAMI... Epicenter of the Americas 2025 Downtown Miami Master Plan 9 200 ber Octo TABLE OF CONTENTS: INTRODUCTION 05 About the Downtown Development Authority 06 Master Plan Overview 06 Foundation 06 Districts 08 Principles 09 Considerations 09 Acknowledgements 10 How to Use this Document 12 VISION 13 Vision Statement 14 GOALS 15 1. Enhance our Position as the Business and 19 Cultural Epicenter of the Americas 2. Leverage our Beautiful and Iconic Tropical Waterfront 27 3. Elevate our Grand Boulevards to Prominence 37 4. Create Great Streets and Community Spaces 45 5. Promote Transit and Regional Connectivity 53 IMPLEMENTATION 61 Process 62 Matrix 63 CONCLUSION 69 APPENDIX 71 Burle Marx Streetscape Miami DDA DOWNTOWN MIAMI MASTER PLAN 2025 2025 DOWNTOWN MIAMI... EPICENTER OF THE AMERICAS 2 3 INTRODUCTION About the DDA Master Plan Overview Foundation Districts Principles Considerations Acknowledgements How to Use the Document DOWNTOWN MIAMI MASTER PLAN 2025 4 Introduction Introduction ABOUT THE DDA FOUNDATION “Roadmap to Success” Downtown Master Plan Study Miami 21 (Duany Plater-Zyberk): 2009 A Greenprint for Our Future: The Miami-Dade Street CRA Master Plans (Dover Kohl / Zyscovich): (Greater Miami Chamber of Commerce (GMCoC), Tree Master Plan (Miami-Dade County Community 2004 / 2006 Miami 21’s mission is to overhaul the City of Miami’s The Miami Downtown Development Authority (DDA) is The Master Plan stands on a foundation of various New World Center (NWC) Committee): 2009 Image Advisory Board): 2007 a quasi-independent -

Career Advancement Miami Survival Guide: How to Prepare for a Successful Summer in Miami the Resources in This Guide Are for Informational Purposes Only
Career Advancement Miami Survival Guide: How to Prepare for a Successful Summer in Miami The resources in this guide are for informational purposes only. Career Advancement does not endorse or guarantee any of the services described in this document. Students should exercise their own discretion when planning for their summer internship. If you would like more information or have questions about this document, feel free to speak with a Career Advancement adviser. You can make an appointment on UChicago Handshake. 3. Location is everything. It is vital that your housing Welcome to Miami! situation is near your work and/or near transportation that Miami is a city like no other. Known for its beautiful beaches, will get you to work quickly. warm weather, diversity, culture, and distinct arts scene. 4. Decide what is important to you. Once you’ve decided on Miami is an exciting metropolitan city with a Latin Flair. what neighborhoods or borough would be convenient for Downtown Miami is also home to the largest concentration of you, it’s always helpful to explore what attractions they international banks in America, and houses many other large have to offer. Whether you love trying new restaurants, firms and businesses. This city also offers a variety of shopping, or visiting museums and other cultural opportunities for UChicago students who are seeking institutions, try to find a place that will give you the most internships and full-time jobs. time to explore your favorite things. The type of housing you’re looking for, your budget, and your 5. Politely ask your employer about housing resources. -
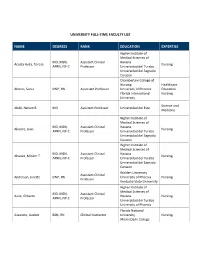
University Full-Time Faculty List
UNIVERSITY FULL-TIME FACULTY LIST NAME DEGREES RANK EDUCATION EXPERTISE Higher Institute of Medical Sciences of MD, MSN, Assistant Clinical Havana Acosta Avila, Teresa Nursing APRN, NP-C Professor Universidad del Turabo Universidad del Sagrado Corazon Chamberlain College of Nursing Healthcare Alonso, Sonia DNP, RN Associate Professor University of Phoenix Education Florida International Nursing University Science and Alubi, Nelson B. MD Assistant Professor Universidad del Este Medicine Higher Institute of Medical Sciences of MD, MSN, Assistant Clinical Havana Alvarez, Juan Nursing APRN, NP-C Professor Universidad del Turabo Universidad del Sagrado Corazon Higher Institute of Medical Sciences of MD, MSN, Assistant Clinical Havana Alvarez, Miriam T. Nursing APRN, NP-C Professor Universidad del Turabo Universidad del Sagrado Corazon Walden University Assistant Clinical Anderson, Julette DNP, RN University of Phoenix Nursing Professor Kentucky State University Higher Institute of Medical Sciences of MD, MSN, Assistant Clinical Avila, Gilberto Havana Nursing APRN, NP-C Professor Universidad del Turabo University of Phoenix Florida National Azzareto, Lizabet BSN, RN Clinical Instructor University Nursing Miami Dade College Higher Institute of Medical Sciences of Villa MD, MSN, Assistant Clinical Clara Bembibre, Ruben Nursing APRN, NP-C Professor Universidad del Turabo Universidad del Sagrado Corazon California Coast Education University Brown, Santarvis PhD(c), MBA Professor Business Columbia Southern Administration University University of -

2020 Suite Menu Index
> UNIVERSITY OF MIAMI HURRICANES 2020 SUITE MENU INDEX Making It Better To Be There Since 1929.™ 2 WELCOME! Welcome to the 2020 season. INDEX It’s going to be a fantastic year for entertaining at Hard Rock Stadium! We are thrilled to welcome you, delight your guests, and Here’s to the Miami Hurricanes, and to great times at thank you for your support of the University of Miami Hurricanes. Hard Rock Stadium. Welcome and thanks for joining us! Undoubtedly, there will be many special moments throughout the year, and we are dedicated to ensuring Centerplate’s Cheers! hospitality services add to your unforgettable memories of this Hurricanes season enjoyed together with family, friends, and colleagues. Ryan Cellucci From traditional fan-favorite foods, to on-trend locally sourced Ryan Cellucci, Suites Manager regional specialties, everything we prepare is meant to create Centerplate Catering at Hard Rock Stadium and enrich the time you spend together with your guests. We believe in the power of hospitality to help people connect in meaningful ways, and our mission is simple: Making It Better to Be There®. In keeping with our commitment to your satisfaction, we are honored to host your event and we welcome special requests. Please let me know how we may help create special dishes that O 305.623.6425 are perfect for your celebration. My contact information is listed [email protected] here for your convenience. Please call! 3 INDEX PAGE Service Directory 5 From the Grill 16 EZPlanit Ordering Instructions 6 Sandwiches 17 INDEX Commitment to Quality & Safety 7 Hand-Carved Action Cart 18 Personalized Hospitality Package 9 Very Vegan 19 Make it Local 10 Bake It Local 20 Guacamole & Taco Cart 11 Sweet Selections 21 Snacks 12 Beverages 23 Appetizers 13 Order Timing 24 Salad-Sides-Fruit-Veggies 14 Fine Print 25-26 Hard Rock Stadium Flatbreads 15 Click on any of the INDEX items to jump immediately to that page. -

COMMUNITY RESOURCE GUIDE Miami-Dade County Homeless Trust Community Resource Guide Table of Contents
MIAMI-DADE COUNTY HOMELESS TRUST COMMUNITY RESOURCE GUIDE Miami-Dade County Homeless Trust Community Resource Guide Table of Contents Adults & Families Animal Care Services 3 Dental Services 3 Food Assistance 4 Clothing 11 Counseling 14 Domestic Violence & Sexual Violence Supportive Services 17 Employment/Training 18 HIV/AIDS Supportive Services 27 Immigration Services 27 Legal Services 28 Low-Cost Housing 29 Medical Care: Hospitals, Urgent Care Centers and Clinics 32 Mental Health/Behavioral Health Care 39 Shelter 42 Social Security Services 44 Substance Abuse Supportive Services 44 Elderly Services 45 Persons with Disabilities 50 2 Adults & Families Animal Care Animal Welfare Society of South Florida 2601 SW 27th Ave. Miami, FL 33133 305-858-3501 Born Free Shelter 786-205-6865 The Cat Network 305-255-3482 Humane Society of Greater Miami 1601 West Dixie Highway North Miami Beach, FL 33160 305-696-0800 Miami-Dade County Animal Services 3599 NW 79th Ave. Doral, FL 33122 311 Paws 4 You Rescue, Inc. 786-242-7377 Dental Services Caring for Miami Project Smile 8900 SW 168th St. Palmetto Bay, FL 33157 786-430-1051 Community Smiles Dade County 750 NW 20th St., Bldg. G110 Miami, FL 33127 305-363-2222 3 Food Assistance Camillus House, Inc. (English, Spanish & Creole) 1603 NW 7th Ave. Miami, FL 33136 305-374-1065 Meals served to community homeless Mon. – Fri. 6:00 AM Showers to community homeless Mon. – Fri. 6:00 AM Emergency assistance with shelter, food, clothing, job training and placement, residential substance abuse treatment and aftercare, behavioral health and maintenance, health care access and disease prevention, transitional and permanent housing (for those who qualify), crisis intervention and legal services. -

Florida International University, Miami Studies
Narrative Section of a Successful Application The attached document contains the grant narrative and selected portions of a previously-funded grant application. It is not intended to serve as a model, but to give you a sense of how a successful application may be crafted. Every successful application is different, and each applicant is urged to prepare a proposal that reflects its unique project and aspirations. Prospective applicants should consult the current Institutes guidelines, which reflect the most recent information and instructions, at https://www.neh.gov/grants/education/humanities-initiatives-hispanic-serving- institutions Applicants are also strongly encouraged to consult with the NEH Division of Education Programs staff well before a grant deadline. Note: The attachment only contains the grant narrative and selected portions, not the entire funded application. In addition, certain portions may have been redacted to protect the privacy interests of an individual and/or to protect confidential commercial and financial information and/or to protect copyrighted materials. Project Title: Miami Studies: Building a New Interdisciplinary Public Humanities Program Institution: Florida International University Project Director: Julió Capo, Andrea Fanta Casto, and Rebecca Friedman Grant Program: Humanities Initiatives at Hispanic-Serving Institutions 1 Miami Studies: Building a New Interdisciplinary Public Humanities Program TABLE OF CONTENTS Project Summary............................................................................................................................ -

Miami, Fl 33156 Rer Reva Dadeland Parcels Development
FOR SALE RER REVA DADELAND SW 70TH AVE & SW 80TH ST PARCELS DEVELOPMENT MIAMI, FL 33156 Partnership. Performance 30-4035-000-1320 , 30-4035-000-1080 Parcel ID PRIME Development Parcels in Dadeland 30-4035-000-1170, 30-4035-000-1430 Avison Young (AY) is pleased to present RER Reva Dadeland (the “Property”), a Total Proposed Units 786 Units development opportunity comprising ± 2.83 acres in Dadeland, spread across four continuous parcels. An investor has the opportunity to acquire the site as South Building 334 Units a whole or the southern three most parcels, allowing creativity and flexibility Center Building 242 Units (adult age restricted) with future site plans. North Building 210 Units The Property’s generous DKUC-Core zoning designation will permit the Parking Garage 455 Parking Spaces construction of impressive structures that could rise to 25 stories, and Lot size (ac) 2.83 potentially include 786 or more multifamily and senior living units, as well as a Primary Zoning DKUC mix of office and retail uses. *Site plan proposed by Hamed Rodriguez Architects. Final site plan may differ than above breakdown. Michael T. Fay, Principal, Managing Dir. - Miami Brian C. de la Fé, Vice President Emily Brais, Associate 305.4 47.7842 305.476.7134 305.447.7858 [email protected] [email protected] [email protected] RER Reva Dadeland Development Parcels Property Highlights Across the street to the Dadeland North MetroRail Station, which provides commuter access to the University of Miami, Brickell, Downtown, and the Miami International Airports, among other destinations. Enjoys flexible zoning, located in the DKUC Core subdistrict.