Rocketbufs: a Framework for Building Efficient, In-Memory, Message-Oriented Middleware
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Robust Messaging with Rabbitmq
Spring RabbitMQ for High Load Martin Toshev Who am I Software consultant (CoffeeCupConsulting) BG JUG board member (http://jug.bg) OpenJDK and Oracle RDBMS enthusiast Twitter: @martin_fmi 2 3 Agenda • Messaging Basics • RabbitMQ Overview • Spring RabbitMQ 4 Messaging Basics 5 Messaging • Messaging provides a mechanism for loosely-coupled integration of systems • The central unit of processing in a message is a message which typically contains a body and a header 6 Use cases • Offloading long-running tasks to worker nodes • Distributing and processing high loads of data • Aggregating logs and propagating events between systems • Many others … 7 Messaging protocols • Messaging solutions implement different protocols for transferring of messages such as AMQP, XMPP, MQTT, STOMP, Kafka binary protocol and others • The variety of protocols imply vendor lock-in 8 Messaging protocols comparison AMQP MQTT XMPP STOMP Kafka goal replacement of messaging for instant messaging, message-oriented processing of large proprietary protocols resource-constrained adopted for wider middleware real-time data feeds devices use format binary binary XML-based text-based binary API divided into classes simple (5 basic different XML items ~ 10 basic commands 42 request types in (> 40 methods in operations with 2-3 with multiple types latest version (Kafka RabbitMQ) packet types for each) 2.0.0) reliability publisher/subscriber acknowledgements Acknowledgments Subscriber Acknowledgements, acknowledgements, and resumptions acknowledgements transactional transactions -

Analysis of Notification Methods with Respect to Mobile System Characteristics
Proceedings of the Federated Conference on DOI: 10.15439/2015F6 Computer Science and Information Systems pp. 1183–1189 ACSIS, Vol. 5 Analysis of notification methods with respect to mobile system characteristics Piotr Nawrocki ∗, Mikołaj Jakubowski † and Tomasz Godzik ‡ ∗AGH University of Science and Technology, al. A. Mickiewicza 30, 30-059 Krakow, Poland e-mail:[email protected] †e-mail:[email protected] ‡e-mail:[email protected] Abstract—Recently, there has been an increasing need for most promise and therefore the purpose is to discern their secure, efficient and simple notification methods for mobile usefulness in the best way possible. systems. Such systems are meant to provide users with precise In addition to the protocols and methods above, we inves- tools best suited for work or leisure environments and a lot of effort has been put into creating a multitude of mobile tigated other solutions, such as the Apple push notification applications. However, not much research has been put at the or Line application which, for various reasons, were not same time into determining which of the available protocols considered further. The Apple push notification technology is a are best suited for individual tasks. Here a number of basic good solution, but it is proprietary, i.e. limited to Apple devices notification methods are presented and tests are performed for and that is why we decided to test more universal solutions the most promising ones. An attempt is made to determine which methods have the best throughput, latency, security and other first. There are also solutions (applications) that use their own characteristics. -

Writing a Message Broker in Golang
Writing a Message Broker in GoLang George Vanburgh Supervised by Alvaro A.A. Fernandes May 3, 2016 A report submitted in part fulfilment of the degree of BSc (Hons) in Computer Science with Industrial Experience Abstract This report details an exercise in learning and evaluating the 'Go' programming language, by building a feature-rich application message broker using modern software engineering techniques and best practises. Some of the unique features of Go are presented, and the importance and relevance of these features in building simple, high-performance distributed software is explored. Discussion of the novel 'CSP-style' concurrency features in Go lead to an unorthodox design proposal for an enterprise-style messaging broker - George's Asynchronous Message Broker (gamq). The implementation of gamq is then is then described and critiqued. Finally, the process and results of the software testing are presented, and analysed. Acknowledgements Many thanks to my supervisor, Alvaro Fernandes, for his continuous support, guidance and patience - without which, this project would have been impossible. Thanks also go to my family and friends for their help and encouragement both during this project, and throughout my time at University. Contents 1 Introduction 3 1.1 Background . .3 1.2 Goals . .3 2 Background 4 2.1 Messages . .4 2.2 Message Brokers . .4 2.2.1 Pub/Sub . .6 2.2.2 Queues . .8 2.2.3 Topics . .8 2.3 Broker Requirements . .8 2.3.1 Failure Handling . 10 2.3.2 Network Bandwidth Utilisation . 10 2.3.3 Network latency . 10 2.3.4 Network packet loss . 11 2.3.5 Message power cost . -

Extending IBM Websphere MQ and Websphere Message Broker to The
Extending IBM WebSphere MQ and WebSphere Message Broker to the Clouds Session 14238 Ralph Bateman ( [email protected] ) STSM, Messaging and Integration Customer Support IBM Hursley Lab Private Community Deploy to a Cloud. Application Public Public Private 2 Don’t worry it’s in the cloud….. Thanks for listening. Questions? 3 Topics Cloud Concepts Introduction to PureApplication System, IWD, and SCAS Patterns and Messaging Virtual System Pattern – WebSphere MQ Hypervisor Edition Virtual Application Pattern – Messaging Extension Virtual System Pattern – Message Broker Reference – Current Versions and Links 4 Cloud Deployment Models Private Private –Used solely by the owning organisation –Benefits include in-house storage of critical data Community –Owned by several organisations but supporting a specific Community community –Some of the benefits of public cloud whilst in a closed community Public –The consumer and provider of cloud services are separate enterprises Public –Benefits include low-cost and scalability Hybrid Public –Seamlessly combines services from public and private cloud Private –Combination of benefits, but requires careful placement of secure/regulated data and apps 5 Cloud Service Models Reflect the traditional computing layers Software as a Service (SaaS) –Provides access to hosted applications or services, which Client Devices/Browsers may themselves use PaaS and IaaS services – Usage based charging , per hour or per ‘transaction’ Client Platform as a Service (PaaS) –Application Centric view - consumer’s application deployed -

A Survey of Distributed Message Broker Queues
A Survey of Distributed Message Broker Queues Vineet John Xia Liu University of Waterloo University of Waterloo [email protected] [email protected] ABSTRACT This paper surveys the message brokers that are in vogue today for distributed communication. Their primary goal is to facilitate the construction of decentralized topolo- gies without single points of failure, enabling fault tol- erance and high availability. These characteristics make them optimal for usage within distributed architectures. However, there are multiple protocols built to achieve this, and it would be beneficial to have a empirical comparison between their features and performance to determine their real-world applicability. Figure 1: Kafka Architecture This paper focuses on two popular protocols (Kafka and AMQP) and explores the divergence in their fea- RQ0 What are the message broker implementations tures as well as their performance under varied testing commonly in use today? workloads. RQ1 What are the common requirements for the im- plementation of message queues? KEYWORDS RQ2 What are the divergent functionalities in the distributed message broker, message queue, kafka, amqp, current message queue offerings? rabbitmq RQ3 How do each of the implementations offer relia- bility, partitioning and fault tolerance? 1 INTRODUCTION 3 KAFKA Kafka was developed at LinkedIn and primarily used Distributed Message Brokers are typically used to decou- for log processing. This worked well for Kafka’s user en- ple separate stages of a software architecture. They per- gagement metrics collection use-case. The fundamental mit communication between these stages asynchronously, features behind Kafka are performance over reliability by using the publish-subscribe paradigm.[1]. These mes- and it offers high throughput, low latency message queu- sage brokers are also finding new applications in the ing. -

Message-Oriented Middleware As a Queue Management Solution to Improve Job Handling Within an E- Commerce System
DEGREE PROJECT IN INFORMATION AND COMMUNICATION TECHNOLOGY, SECOND CYCLE, 30 CREDITS STOCKHOLM, SWEDEN 2018 Message-Oriented Middleware as a Queue Management Solution to Improve Job Handling within an E- Commerce System TOBIAS JOHANSSON KTH ROYAL INSTITUTE OF TECHNOLOGY SCHOOL OF ELECTRICAL ENGINEERING AND COMPUTER SCIENCE CONTENTS 1 Abstract Today’s applications are required to continuously adapt and adjust, to be able to meet a constant change in demand. As result of an in- creasing amount of data, choosing the right communication method becomes a vital step. A solution that have been functional for a long time, may at any point in time be unable to reach the level it requires and instead turns into bottlenecks and inefficient solutions. Using a database as a communication method between system enti- ties, does not have to be a bad solution. A database has it perks with being a simple solution and efficient query operations. However, us- ing it as a queue management system, requires entities to continuously poll new table entries. This solution may not be the most suitable nor best available option. There exists communication system developed for the specific purpose of efficiently distributing messages to avail- able parties. Implementing a message-oriented middleware enables for asynchronous communication which promotes applications to be more loosely cou- pled. As a result, available resources could be better utilised and im- prove the system performance. This degree project investigates the development and integration of two message-oriented middlewares, RabbitMQ and AcviteMQ, within an e-commerce system. The pur- pose is to explore the potentials of changing queue management sys- tem from a database to a message broker. -

A Comparison Between Rabbitmq and REST Ful API for Communication Between Micro-Services Web Application
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 07 Issue: 05 | May 2020 www.irjet.net p-ISSN: 2395-0072 A Comparison between RabbitMQ and REST ful API for Communication between Micro-Services Web Application Akshay Kamath B1, Chaitra B H2 1B.E Student, Department of Computer Science and Engineering, RV College of Engineering, Bangalore 2Professor, Department of Computer Science and Engineering, RV College of Engineering, Bangalore ---------------------------------------------------------------------***--------------------------------------------------------------------- Abstract - As Micro-Service architecture is being used as trend technology, it becomes important to discuss what should be the communication medium between multiple micro- services making it efficient and scalable. This paper discusses about why AMQP (Advanced Message Queuing Protocol) technology is better at handling load than traditional REST (Representational State Transfer) communication. AMQP seems to be promising technology specially when there is massive data that is communicated between micro-services. Fig -1: RESTful API operations This paper discusses about RabbitMQ as the AMQP Message broker. 1.2 Advanced Message Queuing Protocol Key Words: AMQP, REST, RabbitMQ AMQP is advanced Message Queuing protocol, which is quite different compared to RESTful API. This messaging 1. INTRODUCTION middleware service helps in sending and receiving messages. Message broker is hosted seperately and runs independent RESTful (Representational State Transfer) is a architecture of Client or Server Micro-service [4]. This paper discuss style used to send and receive resource between two piece of about RabbitMQ as the message broker. There are three software usually they are called as client and server or main components while considering any AMQP messaging publisher and subscriber [1][2]. -
Sheet1 Page 1 Name Client License History Message Transport Jeromq
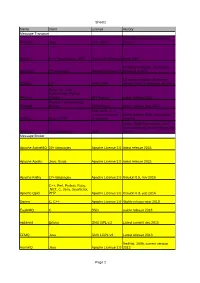
Sheet1 Name client License History Message Transport Java implementation of zeromq JeroMQ Java GNU LGPL library MSMQ C++, Visual Basic, .NET, Part of OS Windows since 1997 Currently only beta, version 0.6. Nanomsg 23 languages Apache License 2.0 released ul 2015 C# implementation of zeromq, NetMQ C# GNU LGPL version 3.3.2.1. released sep 2015 Ruby, Go, Java, CoffeeScript, Python, Resque Clojure MIT license stable release 2013 Python, Cyclone, Ruby, RestMQ Erlang BSD license stable release may 2015 GNU LGPL v3, or commercial license stable release 2015, community Sidekiq Ruby, HTTP for business growing IMatix, 2008, first version; 2011 mass produced, latest release aug ZeroMQ 30+ languages LGPL 2015 Message Broker Apache ActiveMQ 20+ languages Apache License 2.0 latest release 2015 Apache Apollo Java, Scala Apache License 2.0 latest release 2015 Apache Kafka 17+ languages Apache License 2.0 Version 0.9, nov 2015 C++, Perl, Python, Ruby, .NET, C, Java, JavaScript, Apache Qpid PHP Apache License 2.0 Version 0.3, sep 2014 Darner C, C++ Apache License 2.0 Stable release mar 2013 EagleMQ C BSD stable release 2013 ejabberd Erlang GNU GPL v.2 Latest commit dec 2015 FFMQ Java GNU LGPL v3 Latest release 2013 RedHat, 2009, current version HornetQ Java Apache License 2.0 2013 Page 1 Sheet1 IBM Websphere C, Visual Basic, .NET, C++, Various IBM IBM, 1990's, latest MQ V8 released in MQ Java, JMS, ActiveX licences 2014 OW2, 1999, latest release may JORAM Java, XML, 13+ others LGPL 2015 Kestrel ASP.NET, Java Apache License 2.0 2.4.1 released nov 2012 MemcacheQ Perl, Python, C, BSD license ~2009, version 0.2.0. -

An Introduction to Messaging Technology
AN INTRODUCTION TO MESSAGING TECHNOLOGY MARK E HR POLARSOFT LIMITED 2465 CENTRAL AVENUE S UITE 205 BOULDER, COLORADO 80301 [email protected] ABSTRACT The world of messaging technology can be a complex and confusing one. Many people travel a difficult road in trying to understand just what messaging is, how (and if) it should be applied to a given business need, and which messaging vendor to choose. This white paper provides a technical introduction to messaging technologies, describes major messaging products, and defines advantages and disadvantages of messaging technology. AN INTRODUCTION TO MESSAGING TECHNOLOGY Table of Contents SECTION 1. A HISTORY OF MESSAGING.................................................................................................1 EARLY MESSAGING SYSTEMS.................................................................................................................................... 1 Characteristics of an E-mail System......................................................................................................................... 1 Late 1980’s to Mid 1990’s: The Client/Server Revolution ................................................................................... 3 Mid to Late 1990’s: Web/Internet, Thin Clients and “Rarely Connected” Users............................................... 4 Late 1990’s and Early 2000’s: Application Servers, Corporate Web Portals, and Business-To-Business Applications .............................................................................................................................................................. -

Websphere Business Integration for SAP
Front cover WebSphere Businesssiness Integration for SAPAP WebSphere and SAP integration using WBI Adapters Business connectivity using WBI brokers WBI and SAP XI interoperability scenario Saida Davies Khirallah Birkler Niall Cargill Tino Friedemann Reinhard Heite Tony Shan Sudha Chandra Veerni Torsten Wilms ibm.com/redbooks International Technical Support Organization WebSphere Business Integration for SAP December 2004 SG24-6354-00 Note: Before using this information and the product it supports, read the information in “Notices” on page xxix. First Edition (December 2004) This edition applies to: Version 8, Release 1, Modification 5.473 of IBM DB2 Version 5, Release 3, Modification 0 of WebSphere MQ + CSD05 Version 5, Release 0, Modification 3 of WebSphere Business Integration Message Broker Version 5, Release 1, Modification 0 of WebSphere Business Integration Server Foundation Version 5, Release 1, Modification 1 of WebSphere Studio Application Developer Integration Edition Version 4, Release 2, Modification 2.2 of WebSphere Business Integration ICS Version 2, Release 4, Modification 0 of WebSphere Business Integration Adapter Framework Version 5, Release 5, Modification 0 of WebSphere Business Integration Adapter for mySAP.com Version 5, Release 5, Modification 2 of WebSphere Business Integration Adapter for mySAP.com Version 2, Release 4, Modification 0 of, WebSphere Business Integration Adapter for JDBC Version 1, Release 1, Modification 0 of WebSphere Business Integration Adapter for Lotus Domino Version 6, Release 0, Modification 0 of Lotus Domino Version 1, Release 0, Modification 0 of WebSphere Business Integration Adapter for SAP XI Version 3, Release 0, Modification 0 of SAP XI © Copyright International Business Machines Corporation 2004. All rights reserved. -

Perbandingan Kinerja Redis, Mosquitto, Dan Mongodb Sebagai Message Broker Pada Iot Middleware Fitri Febriyani1, Eko Sakti Pramukantoro2, Fariz Andri Bakhtiar3
Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer e-ISSN: 2548-964X Vol. 3, No. 7, Juli 2019, hlm. 6816-6823 http://j-ptiik.ub.ac.id Perbandingan Kinerja Redis, Mosquitto, dan MongoDB sebagai Message Broker pada IoT Middleware Fitri Febriyani1, Eko Sakti Pramukantoro2, Fariz Andri Bakhtiar3 Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: [email protected], [email protected], [email protected] Abstrak IoT middleware memiliki service unit yang menerapkan Redis message broker untuk menerima berbagai tipe data. Selain menerima data, message broker perlu scalable untuk menangani banyak data dan untuk terus beroperasi walaupun terjadi kegagalan. Penelitian ini melakukan perbandingan kinerja Redis, Mosquitto, dan MongoDB sebagai message broker pada IoT middleware secara bergantian. MongoDB dipilih karena karakteristik skalabilitasnya dan Mosquitto karena kinerjanya yang stabil. Hasil pengujian kinerja, penggunaan CPU terbaik saat read data adalah Mosquitto dengan rentang 8%-62%. Penggunaan CPU saat write data, penggunaan memori, dan runtime, hasil terbaik dimiliki Redis dengan nilai berkisar 13%-41%, 53MB-64MB, dan 54MB-59MB. Kemudian runtime saat write dan read data sebesar 2,37 detik dan 0,05 detik. Pada disk i/o, MongoDB memiliki kinerja yang terbaik saat write dan read data sebesar 111 megabit dan 689 megabit. Dalam hal skalabilitas, concurrent publish terbaik adalah Mosquitto sebesar 18 pesan per detik melalui CoAP dan 15 pesan per detik melalui MQTT. Kesimpulan yang dapat ditarik adalah Redis memiliki kinerja yang baik pada penggunaan CPU saat write data, penggunaan memori, runtime, dan kecepatan menangani data yang masuk. Dari segi disk i/o dan kecepatan membaca data, MongoDB memiliki kinerja yang terbaik. -

Title Goes Here and Here and Here
Event Brokering Using SAP Cloud Platform Enterprise Messaging Karsten Strothmann, SAP SE December 5th, 2019 PUBLIC Disclaimer ▪ The information in this presentation is confidential and proprietary to SAP and may not be disclosed without the permission of SAP. Except for your obligation to protect confidential information, this presentation is not subject to your license agreement or any other service or subscription agreement with SAP. SAP has no obligation to pursue any course of business outlined in this presentation or any related document, or to develop or release any functionality mentioned therein. ▪ This presentation, or any related document and SAP's strategy and possible future developments, products and or platforms directions and functionality are all subject to change and may be changed by SAP at any time for any reason without notice. The information in this presentation is not a commitment, promise or legal obligation to deliver any material, code or functionality. This presentation is provided without a warranty of any kind, either express or implied, including but not limited to, the implied warranties of merchantability, fitness for a particular purpose, or non-infringement. This presentation is for informational purposes and may not be incorporated into a contract. SAP assumes no responsibility for errors or omissions in this presentation, except if such damages were caused by SAP’s intentional or gross negligence. ▪ All forward-looking statements are subject to various risks and uncertainties that could cause actual results to differ materially from expectations. Readers are cautioned not to place undue reliance on these forward-looking statements, which speak only as of their dates, and they should not be relied upon in making purchasing decisions.