Machine-Learning Identification of Asteroid Groups
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Photometry of Asteroids: Lightcurves of 24 Asteroids Obtained in 1993–2005
ARTICLE IN PRESS Planetary and Space Science 55 (2007) 986–997 www.elsevier.com/locate/pss Photometry of asteroids: Lightcurves of 24 asteroids obtained in 1993–2005 V.G. Chiornya,b,Ã, V.G. Shevchenkoa, Yu.N. Kruglya,b, F.P. Velichkoa, N.M. Gaftonyukc aInstitute of Astronomy of Kharkiv National University, Sumska str. 35, 61022 Kharkiv, Ukraine bMain Astronomical Observatory, NASU, Zabolotny str. 27, Kyiv 03680, Ukraine cCrimean Astrophysical Observatory, Crimea, 98680 Simeiz, Ukraine Received 19 May 2006; received in revised form 23 December 2006; accepted 10 January 2007 Available online 21 January 2007 Abstract The results of 1993–2005 photometric observations for 24 main-belt asteroids: 24 Themis, 51 Nemausa, 89 Julia, 205 Martha, 225 Henrietta, 387 Aquitania, 423 Diotima, 505 Cava, 522 Helga, 543 Charlotte, 663 Gerlinde, 670 Ottegebe, 693 Zerbinetta, 694 Ekard, 713 Luscinia, 800 Kressmania, 1251 Hedera, 1369 Ostanina, 1427 Ruvuma, 1796 Riga, 2771 Polzunov, 4908 Ward, 6587 Brassens and 16541 1991 PW18 are presented. The rotation periods of nine of these asteroids have been determined for the first time and others have been improved. r 2007 Elsevier Ltd. All rights reserved. Keywords: Asteroids; Photometry; Lightcurve; Rotational period; Amplitude 1. Introduction telescope of the Crimean Astrophysics Observatory in Simeiz. Ground-based observations are the main source of knowledge about the physical properties of the asteroid 2. Observations and their reduction population. The photometric lightcurves are used to determine rotation periods, pole coordinates, sizes and Photometric observations of the asteroids were carried shapes of asteroids, as well as to study the magnitude-phase out in 1993–1994 using one-channel photoelectric photo- relation of different type asteroids. -
The Minor Planet Bulletin
THE MINOR PLANET BULLETIN OF THE MINOR PLANETS SECTION OF THE BULLETIN ASSOCIATION OF LUNAR AND PLANETARY OBSERVERS VOLUME 36, NUMBER 3, A.D. 2009 JULY-SEPTEMBER 77. PHOTOMETRIC MEASUREMENTS OF 343 OSTARA Our data can be obtained from http://www.uwec.edu/physics/ AND OTHER ASTEROIDS AT HOBBS OBSERVATORY asteroid/. Lyle Ford, George Stecher, Kayla Lorenzen, and Cole Cook Acknowledgements Department of Physics and Astronomy University of Wisconsin-Eau Claire We thank the Theodore Dunham Fund for Astrophysics, the Eau Claire, WI 54702-4004 National Science Foundation (award number 0519006), the [email protected] University of Wisconsin-Eau Claire Office of Research and Sponsored Programs, and the University of Wisconsin-Eau Claire (Received: 2009 Feb 11) Blugold Fellow and McNair programs for financial support. References We observed 343 Ostara on 2008 October 4 and obtained R and V standard magnitudes. The period was Binzel, R.P. (1987). “A Photoelectric Survey of 130 Asteroids”, found to be significantly greater than the previously Icarus 72, 135-208. reported value of 6.42 hours. Measurements of 2660 Wasserman and (17010) 1999 CQ72 made on 2008 Stecher, G.J., Ford, L.A., and Elbert, J.D. (1999). “Equipping a March 25 are also reported. 0.6 Meter Alt-Azimuth Telescope for Photometry”, IAPPP Comm, 76, 68-74. We made R band and V band photometric measurements of 343 Warner, B.D. (2006). A Practical Guide to Lightcurve Photometry Ostara on 2008 October 4 using the 0.6 m “Air Force” Telescope and Analysis. Springer, New York, NY. located at Hobbs Observatory (MPC code 750) near Fall Creek, Wisconsin. -

Dynamical Evolution of the Cybele Asteroids
MNRAS 451, 244–256 (2015) doi:10.1093/mnras/stv997 Dynamical evolution of the Cybele asteroids Downloaded from https://academic.oup.com/mnras/article-abstract/451/1/244/1381346 by Universidade Estadual Paulista J�lio de Mesquita Filho user on 22 April 2019 V. Carruba,1‹ D. Nesvorny,´ 2 S. Aljbaae1 andM.E.Huaman1 1UNESP, Univ. Estadual Paulista, Grupo de dinamicaˆ Orbital e Planetologia, 12516-410 Guaratingueta,´ SP, Brazil 2Department of Space Studies, Southwest Research Institute, Boulder, CO 80302, USA Accepted 2015 May 1. Received 2015 May 1; in original form 2015 April 1 ABSTRACT The Cybele region, located between the 2J:-1A and 5J:-3A mean-motion resonances, is ad- jacent and exterior to the asteroid main belt. An increasing density of three-body resonances makes the region between the Cybele and Hilda populations dynamically unstable, so that the Cybele zone could be considered the last outpost of an extended main belt. The presence of binary asteroids with large primaries and small secondaries suggested that asteroid families should be found in this region, but only relatively recently the first dynamical groups were identified in this area. Among these, the Sylvia group has been proposed to be one of the oldest families in the extended main belt. In this work we identify families in the Cybele region in the context of the local dynamics and non-gravitational forces such as the Yarkovsky and stochastic Yarkovsky–O’Keefe–Radzievskii–Paddack (YORP) effects. We confirm the detec- tion of the new Helga group at 3.65 au, which could extend the outer boundary of the Cybele region up to the 5J:-3A mean-motion resonance. -

Aqueous Alteration on Main Belt Primitive Asteroids: Results from Visible Spectroscopy1
Aqueous alteration on main belt primitive asteroids: results from visible spectroscopy1 S. Fornasier1,2, C. Lantz1,2, M.A. Barucci1, M. Lazzarin3 1 LESIA, Observatoire de Paris, CNRS, UPMC Univ Paris 06, Univ. Paris Diderot, 5 Place J. Janssen, 92195 Meudon Pricipal Cedex, France 2 Univ. Paris Diderot, Sorbonne Paris Cit´e, 4 rue Elsa Morante, 75205 Paris Cedex 13 3 Department of Physics and Astronomy of the University of Padova, Via Marzolo 8 35131 Padova, Italy Submitted to Icarus: November 2013, accepted on 28 January 2014 e-mail: [email protected]; fax: +33145077144; phone: +33145077746 Manuscript pages: 38; Figures: 13 ; Tables: 5 Running head: Aqueous alteration on primitive asteroids Send correspondence to: Sonia Fornasier LESIA-Observatoire de Paris arXiv:1402.0175v1 [astro-ph.EP] 2 Feb 2014 Batiment 17 5, Place Jules Janssen 92195 Meudon Cedex France e-mail: [email protected] 1Based on observations carried out at the European Southern Observatory (ESO), La Silla, Chile, ESO proposals 062.S-0173 and 064.S-0205 (PI M. Lazzarin) Preprint submitted to Elsevier September 27, 2018 fax: +33145077144 phone: +33145077746 2 Aqueous alteration on main belt primitive asteroids: results from visible spectroscopy1 S. Fornasier1,2, C. Lantz1,2, M.A. Barucci1, M. Lazzarin3 Abstract This work focuses on the study of the aqueous alteration process which acted in the main belt and produced hydrated minerals on the altered asteroids. Hydrated minerals have been found mainly on Mars surface, on main belt primitive asteroids and possibly also on few TNOs. These materials have been produced by hydration of pristine anhydrous silicates during the aqueous alteration process, that, to be active, needed the presence of liquid water under low temperature conditions (below 320 K) to chemically alter the minerals. -
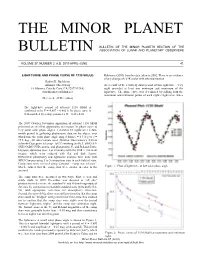
The Minor Planet Bulletin 37 (2010) 45 Classification for 244 Sita
THE MINOR PLANET BULLETIN OF THE MINOR PLANETS SECTION OF THE BULLETIN ASSOCIATION OF LUNAR AND PLANETARY OBSERVERS VOLUME 37, NUMBER 2, A.D. 2010 APRIL-JUNE 41. LIGHTCURVE AND PHASE CURVE OF 1130 SKULD Robinson (2009) from his data taken in 2002. There is no evidence of any change of (V-R) color with asteroid rotation. Robert K. Buchheim Altimira Observatory As a result of the relatively short period of this lightcurve, every 18 Altimira, Coto de Caza, CA 92679 (USA) night provided at least one minimum and maximum of the [email protected] lightcurve. The phase curve was determined by polling both the maximum and minimum points of each night’s lightcurve. Since (Received: 29 December) The lightcurve period of asteroid 1130 Skuld is confirmed to be P = 4.807 ± 0.002 h. Its phase curve is well-matched by a slope parameter G = 0.25 ±0.01 The 2009 October-November apparition of asteroid 1130 Skuld presented an excellent opportunity to measure its phase curve to very small solar phase angles. I devoted 13 nights over a two- month period to gathering photometric data on the object, over which time the solar phase angle ranged from α = 0.3 deg to α = 17.6 deg. All observations used Altimira Observatory’s 0.28-m Schmidt-Cassegrain telescope (SCT) working at f/6.3, SBIG ST- 8XE NABG CCD camera, and photometric V- and R-band filters. Exposure durations were 3 or 4 minutes with the SNR > 100 in all images, which were reduced with flat and dark frames. -

Spectroscopic Survey of X-Type Asteroids S
Spectroscopic Survey of X-type Asteroids S. Fornasier, B.E. Clark, E. Dotto To cite this version: S. Fornasier, B.E. Clark, E. Dotto. Spectroscopic Survey of X-type Asteroids. Icarus, Elsevier, 2011, 10.1016/j.icarus.2011.04.022. hal-00768793 HAL Id: hal-00768793 https://hal.archives-ouvertes.fr/hal-00768793 Submitted on 24 Dec 2012 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Accepted Manuscript Spectroscopic Survey of X-type Asteroids S. Fornasier, B.E. Clark, E. Dotto PII: S0019-1035(11)00157-6 DOI: 10.1016/j.icarus.2011.04.022 Reference: YICAR 9799 To appear in: Icarus Received Date: 26 December 2010 Revised Date: 22 April 2011 Accepted Date: 26 April 2011 Please cite this article as: Fornasier, S., Clark, B.E., Dotto, E., Spectroscopic Survey of X-type Asteroids, Icarus (2011), doi: 10.1016/j.icarus.2011.04.022 This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. -

“Deep Impact: Your First Look Inside a Comet” -.:: GEOCITIES.Ws
Journal of the South Bay Astronomical Society – January 2006 on line at www.geocities.com/sbas_elcamino Monthly General Meeting: Friday, January, 6th, 7:30 PM Guest Speaker: Kenneth P. Klaasen “Deep Impact: Your First Look Inside a Comet” The December 2 Meeting It was a dark and stormy night. Well, it was, but that didn¹t keep 32 people from attending a lecture by Kara Knack, giving us an “Update on the Griffith Observatory Renovations”. Before she spoke, we heard some reports from various members, who had observed from Kitt Peak, toured the Deep Space Network at Canberra, Australia, and seen some bright bolides of the Leonid meteor shower while visiting New Mexico. We also held elections for the four executive positions in the SBAS. The four candidates were elected unanimously. Dr. Dave Pierce then introduced he evening¹s speaker, who began by reviewing the history of the Griffith Observatory. This was the third planetarium in the United States, when it opened in 1935, and operated until 2002 when it was closed for much-needed renovations and expansion. To preserve the building’s appearance, most of the expansion is below ground. The new Zeiss projector is unlike any other projector in the world, and is expected to create the best artificial sky anywhere. The murals are being cleaned of 70 years of airborne dirt, and the 18 bullet holes (!) in the telescope domes have been filled in. For those of you who are worried that some much-beloved displays will disappear, fear not; the Foucault pendulum, Tesla coil and solar telescope remain. -

Rotation Periods for Small Main-Belt Asteroids?,??
A&A 415, 403–406 (2004) Astronomy DOI: 10.1051/0004-6361:20034585 & c ESO 2004 Astrophysics Rotation periods for small main-belt asteroids?;?? R. Almeida, C. A. Angeli, R. Duffard, and D. Lazzaro Observat´orio Nacional/MCT, Coordenac¸˜ao de Astronomia e Astrof´ısica – CAA, 20921-400 Rio de Janeiro, Brazil Received 29 November 2002 / Accepted 9 October 2003 Abstract. The results of new CCD observations are presented as part of the campaign we are performing in Brazil to measure rotational periods for small asteroids. The observations presented here have been acquired at the Pico dos Dias Observatory between 1997 and 2002 and result in 48 single night lightcurves for 20 asteroids, most of them Main-Belt objects with D < 40 km. We present the rotation periods – ranging from about 3 to 18 hr – along with the composite lightcurve obtained for each observed object. Key words. minor planets, asteroids – solar system: general 1. Introduction the picture of this population. The final aim is the analysis of all these periods, along with the ones available in the literature, in From the lightcurves of asteroids we can determine the distri- view of the diameters of those asteroids, to better understand bution of their rotation rates and put important constraints on their rotational evolution. Our rotation periods are based on the evolution of the asteroid population as a whole. Special at- 48 single-night lightcurves from data collected from April 1997 tention has been paid lately to small objects (D < 40 km), be- through April 2002. cause in this range of diameters the fast and the slow rotators of the population are concentrated. -

Chirikov Diffusion in the Asteroidal Three-Body Resonance (5,-2,-2)
Celest Mech Dyn Astron manuscript No. (will be inserted by the editor) Chirikov Diffusion in the Asteroidal Three-Body Resonance (5, −2, −2) F. Cachucho · P. M. Cincotta · S. Ferraz-Mello Received: date / Accepted: date Abstract The theory of diffusion in many-dimensional Hamiltonian system is ap- plied to asteroidal dynamics. The general formulations developed by Chirikov is ap- plied to the Nesvorn´y-Morbidelli analytic model of three-body (three-orbit) mean- motion resonances (Jupiter-Saturn-asteroid system). In particular, we investigate the diffusion along and across the separatrices of the (5, 2, 2) resonance of the − − (490) Veritas asteroidal family and their relationship to diffusion in semi-major axis and eccentricity. The estimations of diffusion were obtained using the Mel- nikov integral, a Hadjidemetriou-type sympletic map and numerical integrations for times up to 108 years. Keywords Chaotic motion, Chirikov theory, asteroid belt, Nesvorn´y-Morbidelli model, three-body resonances 1 Introduction The application of chaotic dynamics concepts to asteroidal dynamics led to the un- derstanding of the main structural characteristics of asteroids distribution within the solar system. It was verified that chaotic region are generally devoid of larger asteroids while, in contrast, regular regions exhibit a great number of them (see for instance, Berry 1978, Wisdom 1982, Dermott and Murray 1983, Hadjidemetriou and Ichtiaroglou 1984, Ferraz-Mello et al. 1997, Tsiganis et al. 2002b, Kneˇzevi´c 2004, Varvoglis 2004) It was soon accepted that chaos was related inevitably to F. Cachucho E-mail: [email protected] P.M. Cincotta Facultad de Ciencias Astron´omicas y Geof´ısicas Universitas National de La Plata, La Plata, Argentina E-mail: [email protected] arXiv:1009.3558v1 [astro-ph.EP] 18 Sep 2010 S. -

The Minor Planet Bulletin, It Is a Pleasure to Announce the Appointment of Brian D
THE MINOR PLANET BULLETIN OF THE MINOR PLANETS SECTION OF THE BULLETIN ASSOCIATION OF LUNAR AND PLANETARY OBSERVERS VOLUME 33, NUMBER 1, A.D. 2006 JANUARY-MARCH 1. LIGHTCURVE AND ROTATION PERIOD Observatory (Observatory code 926) near Nogales, Arizona. The DETERMINATION FOR MINOR PLANET 4006 SANDLER observatory is located at an altitude of 1312 meters and features a 0.81 m F7 Ritchey-Chrétien telescope and a SITe 1024 x 1024 x Matthew T. Vonk 24 micron CCD. Observations were conducted on (UT dates) Daniel J. Kopchinski January 29, February 7, 8, 2005. A total of 37 unfiltered images Amanda R. Pittman with exposure times of 120 seconds were analyzed using Canopus. Stephen Taubel The lightcurve, shown in the figure below, indicates a period of Department of Physics 3.40 ± 0.01 hours and an amplitude of 0.16 magnitude. University of Wisconsin – River Falls 410 South Third Street Acknowledgements River Falls, WI 54022 [email protected] Thanks to Michael Schwartz and Paulo Halvorcem for their great work at Tenagra Observatory. (Received: 25 July) References Minor planet 4006 Sandler was observed during January Schmadel, L. D. (1999). Dictionary of Minor Planet Names. and February of 2005. The synodic period was Springer: Berlin, Germany. 4th Edition. measured and determined to be 3.40 ± 0.01 hours with an amplitude of 0.16 magnitude. Warner, B. D. and Alan Harris, A. (2004) “Potential Lightcurve Targets 2005 January – March”, www.minorplanetobserver.com/ astlc/targets_1q_2005.htm Minor planet 4006 Sandler was discovered by the Russian astronomer Tamara Mikhailovna Smirnova in 1972. (Schmadel, 1999) It orbits the sun with an orbit that varies between 2.058 AU and 2.975 AU which locates it in the heart of the main asteroid belt. -

New CCD Photometry of Asteroid (1028) Lydina ∗
Research in Astron. Astrophys. 2012 Vol. 12 No. 12, 1714–1722 Research in http://www.raa-journal.org http://www.iop.org/journals/raa Astronomy and Astrophysics New CCD photometry of asteroid (1028) Lydina ¤ Yi-Bo Wang1;2;3 and Xiao-Bin Wang1;2 1 National Astronomical Observatories / Yunnan Observatory, Chinese Academy of Sciences, Kunming 650011, China; [email protected] 2 Key Laboratory for the Structure and Evolution of Celestial Objects, Chinese Academy of Sciences, Kunming 650011, China 3 Graduate University of Chinese Academy of Sciences, Beijing 100049, China Received 2012 April 24; accepted 2012 May 30 Abstract New CCD photometric observations for asteroid (1028) Lydina, carried out with the 1-m and 2.4-m telescopes at Yunnan Observatory from 2011 December 19 to 2012 February 3, are presented. Using the new light curves, the rotation period of 11.680§0.001 hours is derived with the Phase Dispersion Minimization (PDM) method. In addition, using the Amplitude-Aspect method, the elementary results of the ± ± ±+4 ±+4 pole orientation of asteroid (1028) Lydina are obtained: ¸ = 111 ± , ¯ = 31 ± . p ¡4 p ¡5 +0:10 Meanwhile, the axial ratios of the tri-axial ellipsoid are estimated: a=b = 1:77¡0:08 +0:07 and b=c = 1:17¡0:09. Key words: asteroids: photometric — observation: rotation period — pole orienta- tion: tri-axial ellipsoid 1 INTRODUCTION Ground-based photometric observation is one of the most important methods to obtain light curves, from which the rotation parameters and shape of an asteroid can be inferred. These parameters may provide a clue for understanding the scenarios in planetary formation and collision evolution of asteroids. -

Occultation Newsletter Volume 8, Number 4
Volume 12, Number 1 January 2005 $5.00 North Am./$6.25 Other International Occultation Timing Association, Inc. (IOTA) In this Issue Article Page The Largest Members Of Our Solar System – 2005 . 4 Resources Page What to Send to Whom . 3 Membership and Subscription Information . 3 IOTA Publications. 3 The Offices and Officers of IOTA . .11 IOTA European Section (IOTA/ES) . .11 IOTA on the World Wide Web. Back Cover ON THE COVER: Steve Preston posted a prediction for the occultation of a 10.8-magnitude star in Orion, about 3° from Betelgeuse, by the asteroid (238) Hypatia, which had an expected diameter of 148 km. The predicted path passed over the San Francisco Bay area, and that turned out to be quite accurate, with only a small shift towards the north, enough to leave Richard Nolthenius, observing visually from the coast northwest of Santa Cruz, to have a miss. But farther north, three other observers video recorded the occultation from their homes, and they were fortuitously located to define three well- spaced chords across the asteroid to accurately measure its shape and location relative to the star, as shown in the figure. The dashed lines show the axes of the fitted ellipse, produced by Dave Herald’s WinOccult program. This demonstrates the good results that can be obtained by a few dedicated observers with a relatively faint star; a bright star and/or many observers are not always necessary to obtain solid useful observations. – David Dunham Publication Date for this issue: July 2005 Please note: The date shown on the cover is for subscription purposes only and does not reflect the actual publication date.