Arxiv:2101.05744V4 [Stat.OT] 17 Jun 2021 a Comparative Study Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

VODAFONE Mclaren MERCEDES TEAM UNVEILED in VALENCIA
VODAFONE McLAREN MERCEDES TEAM UNVEILED IN VALENCIA Monday 15th January 2007, Ciudad de las Artes y de las Ciencias, Valencia, Spain: Vodafone McLaren Mercedes race drivers Fernando Alonso and Lewis Hamilton will drive through the streets of Valencia in their Formula 1 cars later today to mark the start of an exciting new era for the team. The event heralds the launch of the Vodafone McLaren Mercedes team, which Vodafone is joining as Title Sponsor and Official Mobile Partner. Fernando and Lewis, who form one of the youngest driver line-ups in the history of the sport, will unveil the new livery to an expected crowd of more than 150,000 on a bespoke circuit around the Ciudad de las Artes y de las Ciencias in two MP4-21 race cars. This will be followed by the unveiling of the 2007 car, the MP4-22, which Fernando and Lewis will use to contest this year's Formula 1 World Championship. The 2007 challengers will conduct a shakedown test at the Circuit Ricardo Tormo, Valencia, on Wednesday 17th January. The intensive pre-season testing programme will then commence on Wednesday 24th January at the same track. Pedro de la Rosa and Gary Paffett join Fernando and Lewis to complete the driver line-up. Pedro and Gary, who are starting their fifth and second years with the team respectively, will continue to support the ongoing technical development of the MP4-22 package during the course of the year alongside Fernando and Lewis. “This is a fantastic day for me - I am really proud to be introducing myself as a Vodafone McLaren Mercedes driver in my home country, and of course to help present my new team to the Spanish fans,” said double World Champion Fernando. -

2018 BAHRAIN GRAND PRIX 06 – 08 April 2018
2018 BAHRAIN GRAND PRIX 06 – 08 April 2018 ormula One continues its early season long-haul programme BAHRAIN INTERNATIONAL CIRCUIT Fthis weekend with a visit to the Bahrain International Circuit, Length of lap: home of Bahrain Grand Prix, round two of the 2018 FIA Formula 5.412km One World Championship Lap record: 1:31.447 (Pedro de la Rosa, McLaren, Australia was a relatively gentle introduction to the season for 2005) 2018’s cars but Bahrain provides a stiffer challenge. Heat and dust Start line/finish line offset: are both notorious engine breakers, while the stop-start nature 0.246km of the track provides a harsh test for both brakes and tyres. Total number of race laps: 57 While the conversion of the Bahrain Grand Prix to a night race Total race distance: has improved the spectacle for fans, it brings with it challenges 308.238km for both teams and drivers. The rapidly cooling track affects the Pitlane speed limits: balance of the car in ways that are inconsistent with a standard, 80km/h in practice, qualifying, and mid-afternoon event. the race The other consequence of racing at night is that it makes FP2, conducted in the early evening, the only practice session from CIRCUIT NOTES which meaningful set-up data is gathered. FP1 and FP3, both ► Other than routine maintenance of which take place in the mid-afternoon, are not expected to no changes of significance have been made. be fruitful in the search for a good race balance, with the circuit tending to move from oversteer on the hot track, towards understeer as the asphalt cools. -

Avaliação Do Campeonato Mundial De Fórmula 1 Com Análise Envoltória De Dados
AVALIAÇÃO DO CAMPEONATO MUNDIAL DE FÓRMULA 1 COM ANÁLISE ENVOLTÓRIA DE DADOS Silvio Figueiredo Gomes Júnior Mestrado em Engenharia de Produção – Universidade Federal do Rio de Janeiro Rua Passo da Pátria 156, 24210-240, Niterói, RJ [email protected] João Carlos Correia Baptista Soares de Mello Departamento de Engenharia de Produção – Universidade Federal Fluminense Rua Passo da Pátria 156, 24210-240, Niterói, RJ [email protected] Resumo Este trabalho analisa os resultados obtidos pelos pilotos no ano de 2005 no Campeonato Mundial de Fórmula 1 segundo a metodologia multicritério Data Envelopment Analysis – DEA, que é uma técnica de programação matemática para avaliação de eficiência produtiva entre diversas unidades, denominadas unidades tomadoras de decisão (DMU), segundo os recursos utilizados na obtenção de seus produtos, diferentemente dos métodos multicritério adotados atualmente para estabelecer a classificação da competição, que permite manipulações e distorções nos resultados. Palavras-chave: DEA, Restrições aos Pesos, Fórmula 1 1. INTRODUÇÃO Em geral, o objetivo da metodologia DEA é medir a eficiência comparada entre unidades de produção que desenvolvam a mesma atividade quanto à utilização de seus recursos e classificá-las em eficientes ou não-eficientes e dar uma medida relativa da eficiência para as não-eficientes. Além disso, outros objetivos da metodologia DEA consistem em estabelecer um ou mais benchmarks e posicionar as outras unidades em relação a eles ou ordená-las segundo as eficiências calculadas. O modelo é -

Formule 1 Seats
2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 2021 Mercedes Mercedes Mercedes Mercedes Mercedes Mercedes Mercedes Mercedes Mercedes Mercedes Mercedes Mercedes Michael Schumacher Michael Schumacher Michael Schumacher Nico Rosberg Lewis Hamilton Lewis Hamilton Lewis Hamilton Lewis Hamilton Lewis Hamilton Lewis Hamilton Lewis Hamilton Lewis Hamilton Nico Rosberg Nico Rosberg Nico Rosberg Lewis Hamilton Nico Rosberg Nico Rosberg Nico Rosberg Valtteri Bottas Valtteri Bottas Valtteri Bottas Valtteri Bottas Valtteri Bottas Ferrari Ferrari Ferrari Ferrari Ferrari Ferrari Ferrari Ferrari Ferrari Ferrari Ferrari Ferrari Felipe Massa Fernando Alonso Fernando Alonso Fernando Alonso Fernando Alonso Sebastian Vettel Sebastian Vettel Sebastian Vettel Sebastian Vettel Sebastian Vettel Sebastian Vettel Charles Leclerc Fernando Alonso Felipe Massa Felipe Massa Felipe Massa Kimi Raïkkönen Kimi Raïkkönen Kimi Raïkkönen Kimi Raïkkönen Kimi Raïkkönen Charles Leclerc Charles Leclerc Carlos Sainz Red Bull Red Bull Red Bull Red Bull Red Bull Red Bull Red Bull Red Bull Red Bull Red Bull Red Bull Red Bull Sebastian Vettel Sebastian Vettel Sebastian Vettel Sebastian Vettel Sebastian Vettel Daniel Ricciardo Daniel Ricciardo Daniel Ricciardo Max Verstappen Max Verstappen Max Verstappen Max Verstappen Mark Webber Mark Webber Mark Webber Mark Webber Daniel Ricciardo Daniil Kvyat Daniil Kvyat Max Verstappen Daniel Ricciardo Pierre Gasly Alexander Albon Sergio Perez McLaren McLaren McLaren McLaren McLaren McLaren McLaren McLaren McLaren McLaren McLaren McLaren -

Media Information
PR Document 2016 Japanese SUPER FORMULA Championship Series MEDIA INFORMATION March 13, 2016 About SUPER FORMULA In the 1950s, the Fédération Internationale de I’Automobile (FIA) launched the Drivers’Championship to find the world’s fastest driver in formula cars – the purest form of racing machine. That ethos was passed on to all FIA national member organizations. Top-level formula motor racing has been held in Japan in various forms since 1973, when Formula 2000 was launched. The competition morphed into Formula Two in 1978 and then Formula 3000 in 1987. Japan Race Promotion Inc. (JRP) was established in 1995 and relaunched the competition as Formula Nippon the following year. Hiroshi Shirai, previously project leader on Honda’s Formula One race team, became JRP president in 2010. In 2013, the name of the competition was changed again to Japanese Championship SUPER FORMULA and a bold plan was implemented to upgrade the race cars and lift the profile of the competition, with the clear aim of spreading the appeal of SUPER FORMULA from Japan to other parts of Asia and transforming it into a third great open-wheel racing competition after Formula One and Indy Car. (The competition’s name will change to the Japanese SUPER FORMULA Championship from the 2016 series). In the early days, formula racing in Japan was led by top drivers such as Kunimitsu Takahashi, Kazuyoshi Hoshino and Satoru Nakajima, who later competed on the global stage in Formula One. In the Formula 3000 era, Michael Schumacher and Heinz-Harald Frentzen competed in Japan, as did Ralf Schumacher, Pedro de la Rosa, Eddie Irvine and Toranosuke Takagi in the mid 1990s, all tenacious drivers aiming to make it into Formula One. -

Media Information
PR Document 2017 Japanese SUPER FORMULA Championship Series MEDIA INFORMATION March 4, 2017 ABOUT SUPER FORMULA In the 1950s, the Fédération Internationale de I’Automobile (FIA) launched the Drivers’ Championship to find the world’s fastest driver in formula cars – the purest form of racing machine. That ethos was passed on to all FIA national member organizations. Top-level formula motor racing has been held in Japan in various forms since 1973, when Formula 2000 was launched. The competition morphed into Formula Two in 1978 and then Formula 3000 in 1987. Japan Race Promotion Inc. (JRP) was established in 1995 and relaunched the competition as Formula Nippon the following year. Hiroshi Shirai, previously project leader on Honda’s Formula One race team, became JRP president in 2010. In 2013, the name of the competition was changed again to Japanese Championship SUPER FORMULA and a bold plan was implemented to upgrade the race cars and lift the profile of the competition with the clear aim of spreading the appeal of SUPER FORMULA from Japan to other parts of Asia and transforming it into a third great open-wheel racing competition after Formula One and Indy Car. (The competition’s name was changed to Japanese SUPER FORMULA Championship from the 2016 season). In the early days, formula racing in Japan was led by top drivers such as Kunimitsu Takahashi, Kazuyoshi Hoshino and Satoru Nakajima, who later competed on the global stage in Formula One. In the Formula 3000 era, Michael Schumacher and Heinz-Harald Frentzen competed in Japan, as did Ralf Schumacher, Pedro de la Rosa, Eddie Irvine and Toranosuke Takagi in the mid 1990s, all tenacious drivers aiming to make it into Formula One. -

2019 BAHRAIN GRAND PRIX 29 – 31 March 2019
2019 BAHRAIN GRAND PRIX 29 – 31 March 2019 he Bahrain International Circuit this weekend hosts Round Two BAHRAIN INTERNATIONAL CIRCUIT Tof the 2019 FIA Formula One World Championship, with teams Length of lap: 5.412km and drivers arriving in the island kingdom to tackle the first night Lap record: race of the season. 1:31.447 (Pedro de la Rosa, McLaren, 2005) After the close confines of the season-opening race at the Start line/finish line offset: Melbourne Grand Prix Circuit, the track at Sakhir presents a very 0.246km different set of challenges, not only because of the evening start Total number of race laps: 57 under floodlights. Total race distance: 308.238km Pitlane speed limits: High temperatures and dust from the desert landscape make the 80km/h in practice, qualifying, and weekend tough on engines, and the problem of airborne sand can the race be exacerbated if the wind gets up across a circuit that features a relatively gentle elevation change of just 16.9m. CIRCUIT NOTES ► Other than routine maintenance The start-stop nature of the track also makes the race tough on no changes of significance have both brakes and tyres. The circuit is ranked as one of the season’s been made. toughest on brakes, with Turns 1, 4 and 14 being particularly severe. DRS ZONE Tyres, meanwhile, are stressed not just by the high loads under ► The Bahrain International Circuit braking but also by the highly abrasive surface. To deal with the will feature three DRS Zones. demands, Pirelli is this weekend bringing the hardest compounds The first features a detection point 50m before Turn 1, with activation in its 2019 range. -

Italy Results 2010
Grand Prix of Italy 2010 1st training session, 10 September 2010 Pos. Driver Team Time Laps 1. Jenson Button McLaren 01:23.693 28 2. Sebastian Vettel Red Bull 01:23.790 27 3. Lewis Hamilton McLaren 01:23.976 25 4. Robert Kubica Renault 01:24.120 25 5. Nico Rosberg Mercedes Grand Prix 01:24.129 30 6. Mark Webber Red Bull 01:24.446 26 7. Vitantonio Liuzzi Force India F1 01:24.512 19 8. Fernando Alonso Ferrari 01:24.543 24 9. Felipe Massa Ferrari 01:24.648 22 10. Michael Schumacher Mercedes Grand Prix 01:24.756 26 11. Nico Hulkenberg Williams 01:24.841 28 12. Paul di Resta Force India F1 01:24.923 23 13. Vitaly Petrov Renault 01:25.292 25 14. Sebastien Buemi Scuderia Toro Rosso 01:25.318 29 15. Pedro de la Rosa Sauber 01:25.320 20 16. Kamui Kobayashi Sauber 01:25.334 24 17. Jaime Alguersuari Scuderia Toro Rosso 01:25.897 19 18. Timo Glock Virgin Racing 01:26.772 19 19. Jarno Trulli Lotus F1 01:26.898 12 20. Lucas Di Grassi Virgin Racing 01:26.956 17 21. Heikki Kovalainen Lotus F1 01:27.374 14 22. Bruno Senna HRT F1 Team 01:28.256 8 23. Rubens Barrichello Williams 01:28.516 4 24. Sakon Yamamoto HRT F1 Team 01:29.870 17 2nd training session, 10 September 2010 Pos. Driver Team Time Laps 1. Sebastian Vettel Red Bull 01:22.839 27 2. Fernando Alonso Ferrari 01:22.915 32 3. -
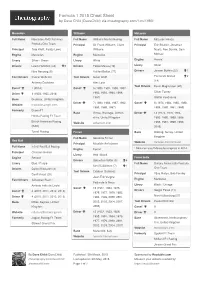
Formula 1 2015 Cheat Sheet by Davechild
Formula 1 2015 Cheat Sheet by Dave Child (DaveChild) via cheatography.com/1/cs/1983/ Mercedes Williams McLaren Full Name Mercedes AMG Petronas Full Name Williams Martini Racing Full Name McLaren Honda Formula One Team Principal Sir Frank Williams, Claire Principal Éric Boullier, Jonathan Principal Toto Wolff, Paddy Lowe Williams Neale, Ron Dennis, Sam Engine Mercedes Engine Mercedes Michael Livery Silver / Green Livery White Engine Honda¹ Drivers Lewis Hamilton (44) 2 Drivers Felipe Massa (19) Livery Silver Nico Rosberg (6) Valtteri Bottas (77) Drivers Jenson Button (22) 1 Test Drivers Pascal Wehrlein Test Drivers Susie Wolff Fernando Alonso 2 (14) Anthony Davidson Alex Lynn Test Drivers Kevin Magnussen (20) Const' 1 (2014) Const' 9 (1980, 1981, 1986, 1987, Oliver Turvey Driver 3 (1954, 1955, 2014) 1992, 1993, 1994, 1996, 1997) Stoffel Vandoorne Base Brackley, United Kingdom Driver 7 (1980, 1982, 1987, 1992, Const' 8 (1974, 1984, 1985, 1988, Website mercedesamgf1.com 1993, 1996, 1997) 1989, 1990, 1991, 1998) Formerly Brawn F1 Base Grove, Wantage, Oxford‐ Driver 12 (1974, 1976, 1984, Honda Racing F1 Team shire, United Kingdom 1985, 1986, 1988, 1989, British American Racing Website williamsf1.com 1990, 1991, 1998, 1999, (BAR) 2008) Tyrrell Racing Ferrari Base Woking, Surrey, United Kingdom Full Name Scuderia Ferrari Red Bull Website mclaren.com/formula1 Principal Maurizio Arrivabene Full Name Infiniti Red Bull Racing Engine Ferrari ¹ McLaren used Mercedes engines in 2014. Principal Christian Horner Livery Red / Black Engine Renault -

British Grand Prix 2010 - Silverstone
British Grand Prix 2010 - Silverstone 1st training session, 09 July 2010 Pos. Driver Team Time 1. Sebastian Vettel Red Bull 01:32.280 2. Lewis Hamilton McLaren 01:32.614 3. Robert Kubica Renault 01:32.725 4. Mark Webber Red Bull 01:32.747 5. Adrian Sutil Force India F1 01:32.968 6. Nico Rosberg Mercedes Grand Prix 01:33.318 7. Nico Hulkenberg Williams 01:33.377 8. Jenson Button McLaren 01:33.519 9. Michael Schumacher Mercedes Grand Prix 01:33.955 10. Rubens Barrichello Williams 01:34.016 11. Sebastien Buemi Scuderia Toro Rosso 01:34.132 12. Vitaly Petrov Renault 01:34.365 13. Fernando Alonso Ferrari 01:34.490 14. Paul di Resta Force India F1 01:34.580 15. Kamui Kobayashi Sauber 01:34.710 16. Pedro de la Rosa Sauber 01:34.901 17. Felipe Massa Ferrari 01:35.037 18. Jaime Alguersuari Scuderia Toro Rosso 01:35.318 19. Heikki Kovalainen Lotus F1 01:36.747 20. Timo Glock Virgin Racing 01:37.330 21. Lucas Di Grassi Virgin Racing 01:37.518 22. Karun Chandhok HRT F1 Team 01:38.735 23. Fairuz Fauzy Lotus F1 01:39.510 24. Sakon Yamamoto HRT F1 Team 01:39.673 2nd training session, 09 July 2010 Pos. Driver Team Time 1. Mark Webber Red Bull 01:31.234 2. Fernando Alonso Ferrari 01:31.626 3. Sebastian Vettel Red Bull 01:31.875 4. Felipe Massa Ferrari 01:32.099 5. Nico Rosberg Mercedes Grand Prix 01:32.166 6. Michael Schumacher Mercedes Grand Prix 01:32.660 7. -

2016 BAHRAIN GRAND PRIX 01-03 April 2016
2016 BAHRAIN GRAND PRIX 01-03 April 2016 ollowing an intriguing opening race to the season in BAHRAIN INTERNATIONAL CIRCUIT FAustralia, this weekend the action moves to Sakhir and the Length of lap: Bahrain International Circuit, home to round two of the 2016 5.412km FIA Formula One World Championship, the Bahrain Grand Prix. Lap record: 1:31.447 (Pedro de la Rosa, As is to be expected, a permanent circuit carved into desert rock McLaren, 2005) provides a very different racing experience to the park roads of Start line/finish line offset: suburban Melbourne. While not renowned as a power track, 0.246km the four straights of the Bahrain International Circuit do place Total number of race laps: greater demands on the power units than those experienced 57 two weeks ago. The short straights also contribute to the stop- Total race distance: 308.238km start nature of the layout, which places a heavy burden on Pitlane speed limits: brakes. While not quite to the level that will be seen later in the 80km/h in practice, qualifying, and year at the Canadian Grand Prix, Bahrain nevertheless requires the race performance and cooling at the heavy end of the braking spectrum. Allied to this, engineers and drivers will also have to pay particular attention to the traction demands in Bahrain. CIRCUIT NOTES Lacking the flow of other circuits, comparatively big lap time ► Other than routine maintenance gains are to be found in getting the power down early out of the no changes of significance have been made. low-speed corners. -
2013 Formula 1 Rolex Australian Grand Prix Melbourne 14-15-16-17 March
Official A4 Media Kit Cover Width 210mm x Depth 297mm (3mm bleed) © 2012 Formula One World Championship Limited, a Formula One group company. All rights reserved. The F1 FORMULA 1 logo, F1 logo, F1 FIA FORMULA 1 WORLD CHAMPIONSHIP logo, FORMULA 1, FORMULA ONE, F1, FIA FORMULA ONE WORLD CHAMPIONSHIP, GRAND PRIX and related marks are trade marks of Formula One Licensing BV, a Formula One group company. Licensed by Formula One World Championship Limited, a Formula One group company. All rights reserved. 2013 FORMULA 1 ROLEX AUSTRALIAN GRAND PRIX MELBOURNE 14-15-16-17 MARCH OFFICIAL MEDIA KIT Pantone 806 c Cutter P806c K Official F1 Media Letterhead Width 210mm x Depth 297mm FORMULA 1 ROLEX AUSTRALIAN GRAND PRIX MELBOURNE 14-15-16-17 MARCH 2013 CONTENTS WELCOME 3 KEY CONTACTS 4 OPENING HOURS 5 2013 FORMULA 1 ROLEX AUSTRALIAN GRAND PRIX – SCHEDULE 6 – 7 PRESS CONFERENCES 8 WORKING IN THE MEDIA CENTRE 9 INFORMATION FOR PHOTOGRAPHERS 10 IT AND TELECOMMUNICATIONS FACILITIES 11 2013 FIA FORMULA ONE WORLD CHAMPIONSHIP: CALENDAR 12 2013 FIA FORMULA ONE WORLD CHAMPIONSHIP: TEAMS AND DRIVERS 13 KEY REGULatiONS FOR 2013 14 2013 TEAM AND DRIVER STATISTICS 15 – 18 THE 2013 FORMULA 1 DRIVERS’ MELBOURNE RECORD 19 – 20 2012 FORMULA ONE WORLD CHAMPIONSHIP: DRIVERS’ FINAL STANDINGS 21 2012 FORMULA ONE WORLD CHAMPIONSHIP: CONSTRUCTORS’ FINAL STANDINGS 22 2012 FORMULA 1 Qantas AUSTRALIAN GRAND PRIX: QUALIFYING 23 2012 FORMULA 1 Qantas AUSTRALIAN GRAND PRIX: RACE CLASSIFICatiON 24 2012 FORMULA 1 Qantas AUSTRALIAN GRAND PRIX: RACE REPORT 25 – 26 MELBOURNE STATISTICS