Authors' Pre-Publication Copy Dated March 7, 2021 This Article Has Been
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Unified Communications Comparison Guide
Unified Communications Comparison Guide Ziff Davis February 2014 Unified Communications (UC) is a useful solution for busy people to collaborate more effectively both within and outside their organizations. This guide provides a side-by-side comparison of the top 10 Unified Communications platforms based on the most common features and functions. Ziff Davis ©2014 Business UC Criteria Directory Mobile Contact Vendor/Product Product Focus Price IM/Presence eDiscovery Multi-party Cloud On-premesis Integration Support Groups SOHO, Lync SMB, $$$ Enterprise SMB, Jabber n/a Enterprise SMB, MiCollab n/a Enterprise SOHO, Open Touch n/a SMB SOHO, Aura SMB, n/a Enterprise SOHO, UC SMB, n/a Enterprise SOHO, Univerge 3C SMB, n/a Enterprise SMB, Sametime $ Enterprise SOHO, SMB, n/a Enterprise SOHO, Sky SMB, $$$$ Communicator Enterprise $ = $1-10/user $$ = $11-20/user $$$ =$21-30/user $$$ =$31-39/user Ziff Davis / Comparison Guide / Unified Communications Ziff Davis ©2014 2 Footnotes About VoIP-News.com VoIP News is a long-running news and information publication covering all aspects of the VoIP and Internet Telephony marketplaces. It is owned by Ziff Davis, Inc and is the premier source worldwide for business VoIP information. The site provides original content covering news, events and background information in the VoIP market. It has strong relationships with members of the VoIP community and is rapidly building a unique, high-quality community of VoIP users and vendors. About Ziff Davis Ziff Davis, Inc. is the leading digital media company specializing in the technology, gaming and men’s lifestyle categories, reaching over 117 million unique visitors per month. -

Report 2021, No. 6
News Agency on Conservative Europe Report 2021, No. 6. Report on conservative and right wing Europe 20th March, 2021 GERMANY 1. jungefreiheit.de (translated, original by jungefreiheit.de, 18.03.2021) "New German media makers" Migrant organization calls for more “diversity” among journalists media BERLIN. The migrant organization “New German Media Makers” (NdM) has reiterated its demand that editorial offices should become “more diverse”. To this end, the association presented a “Diversity Guide” on Wednesday under the title “How German Media Create More Diversity”. According to excerpts on the NdM website, it says, among other things: “German society has changed, it has become more colorful. That should be reflected in the reporting. ”The manual explains which terms journalists should and should not use in which context. 2 When reporting on criminal offenses, “the prejudice still prevails that refugees or people with an international history are more likely to commit criminal offenses than biographically Germans and that their origin is causally related to it”. Collect "diversity data" and introduce "soft quotas" Especially now, when the media are losing sales, there is a crisis of confidence and more competition, “diversity” is important. "More diversity brings new target groups, new customers and, above all, better, more successful journalism." The more “diverse” editorial offices are, the more it is possible “to take up issues of society without prejudice”, the published excerpts continue to say. “And just as we can no longer imagine a purely male editorial office today, we should also no longer be able to imagine white editorial offices. Precisely because of the special constitutional mandate of the media, the question of fair access and the representation of all population groups in journalism is also a question of democracy. -

So Many People Are Perplexed with the Covid-19 Lockdowns, Mask Requirements, Social Distancing, Loss of Jobs, Homes, and Their Very Sanity
So many people are perplexed with the Covid-19 lockdowns, mask requirements, social distancing, loss of jobs, homes, and their very sanity. What lies behind all of this? There have been so many conflicting reports that one has to ask the question, Is there even a pandemic at all? Was there ever one? Let’s have a look. ======================== Strange advance hints (predictive programming) – A 1993 Simpsons episode called “Marge in Chains” actually accurately predicted the coronavirus outbreak. One scene depicted a boardroom meeting between government officials and major media moguls. The chairman opened with these words: “I’d like to call to order this secret conclave of America’s media empires. We are here to come up with the next phony baloney crisis to put Americans back where they belong…” Suddenly a delegate from NBC chimed in: “Well I think…” Then the chairman interrupted him, saying: “NBC, you are here to listen and not speak!” He then said: “I think we should go with a good old fashioned health scare.” Everyone then nodded in approval. Next, a female delegate remarked: “A new disease–no one’s immune–it’s like The Summer of the Shark, except instead of the shark, it’s an epidemic.” – Another Simpsons episode called “A Totally Fun Thing that Bart will Never Do Again,” first aired on April 29, 2012, featured an emergency broadcast announcing the outbreak of the deadly “Pandora Virus,” and how it was “spreading rapidly.” The announcer then said: “This unprecedented threat requires a world-wide quarantine. All ships must remain at sea until further notice. -

08-1448 Brown V. Entertainment Merchants Assn. (06/27/2011)
(Slip Opinion) OCTOBER TERM, 2010 1 Syllabus NOTE: Where it is feasible, a syllabus (headnote) will be released, as is being done in connection with this case, at the time the opinion is issued. The syllabus constitutes no part of the opinion of the Court but has been prepared by the Reporter of Decisions for the convenience of the reader. See United States v. Detroit Timber & Lumber Co., 200 U. S. 321, 337. SUPREME COURT OF THE UNITED STATES Syllabus BROWN, GOVERNOR OF CALIFORNIA, ET AL. v. ENTERTAINMENT MERCHANTS ASSOCIATION ET AL. CERTIORARI TO THE UNITED STATES COURT OF APPEALS FOR THE NINTH CIRCUIT No. 08–1448. Argued November 2, 2010—Decided June 27, 2011 Respondents, representing the video-game and software industries, filed a preenforcement challenge to a California law that restricts the sale or rental of violent video games to minors. The Federal District Court concluded that the Act violated the First Amendment and permanently enjoined its enforcement. The Ninth Circuit affirmed. Held: The Act does not comport with the First Amendment. Pp. 2–18. (a) Video games qualify for First Amendment protection. Like pro- tected books, plays, and movies, they communicate ideas through fa- miliar literary devices and features distinctive to the medium. And “the basic principles of freedom of speech . do not vary” with a new and different communication medium. Joseph Burstyn, Inc. v. Wil- son, 343 U. S. 495, 503. The most basic principle—that government lacks the power to restrict expression because of its message, ideas, subject matter, or content, Ashcroft v. American Civil Liberties Un- ion, 535 U. -

Clash of Narratives: the US-China Propaganda War Amid the Global Pandemic
C lash of Narratives: The US-China Propaganda War Amid the Global Pandemic Preksha Shree Chhetri Research Scholar, Jawaharlal Nehru University, Delhi [email protected] Abstract In addition to traditional spheres of competition such as military and economic rivalry, the US-China rivalry is shifting into new areas. The outbreak of Covid-19 seems to have provided yet another domain for competition to both the US and China. Aside from news related to Covid-19, propaganda around Covid-19 have dominated global discussions in the last few months. Propaganda, in the most neutral sense, means to disseminate or promote particular ideas. During the ongoing pandemic, China and the US have been involved in very intense war of words in order to influence the global narrative on Covid-19. Considering the number of narratives presented by two of the world’s strongest actors, the period since the outbreak of the pandemic can be truly regarded as the age of clashing narratives. This analysis attempts to take a close look at the narratives presented by the US and China during the pandemic, consider the impact of disinformation on the day to day lives of people around the world and discuss the criticism against China and the US during the.Pandemic.. Keywords China, US, Covid-19, Propaganda, Disinformation Harold D Lasswell (1927) defines Propaganda time in the US with the creation of Committee on Public Information (CPI). A similar body as ‘management of collective attitudes by called the Office of War Information (OWI) manipulation of significant symbols’. In simple was formed during World War II. -

Social Networking for Educators — by Marina Leight and Cathilea Robinett Classroom Resources and Professional Development Are Reasons to Log On
inside: Let Them Have Tech | Save School Budgets with Thin Client | New School Models | The Charter Challenge Fall 2007 » STRATEGY AND LEADERSHIP FOR TECHNOLOGY IN EDUCATION A publication of e.Republic ADynamic DuoThe leading ladies of West Virginia. Issue 4 | Vol.2 CCON10_01.inddON10_01.indd 1100 110/4/070/4/07 11:57:17:57:17 PPMM 100 Blue Ravine Road Folsom, CA. 95630 _______ Designer _______ Creative Dir. 916-932-1300 Pg Cyan Magenta Yellow Black ® _______ Editorial _______ Prepress 5 25 50 75 95 100 5 25 50 75 95 100 5 25 50 75 95 100 5 25 50 75 95 100 _________ Production _______ OK to go Students not quite spellbound in class? A projector from CDW•G can liven up the room a bit. Epson PowerLite® S5 • 2000 ANSI lumens SVGA projector $ 99 • Lightweight, travel-friendly design — weighs only 5.8 lbs. 599 • Energy-efficient E-TORL lamp lasts up to 4000 hours CDWG 1225649 • Two-year limited parts and labor, 90-day lamp warranty with Epson Road Service Program that includes overnight exchange Epson Duet Ultra Portable Projector Screen • 80" projection screen • Offers standard (4:3) and widescreen (16:9) formats • Includes floor stand, and bracket for wall-mounting $249 CDWG 1100660 1Express Replacement Assistance with 24-hour replacement. Offer subject to CDW•G’s standard terms and conditions of sale, available at CDWG.com. ©2007 CDW Government, Inc. CCon_OctFall_Temp.inddon_OctFall_Temp.indd 1 99/26/07/26/07 111:45:271:45:27 AAMM 4510_cdwg_Converge_sel_sp_10-1.i1 1 9/10/07 1:13:49 PM 100 Blue Ravine Road Folsom, CA. -

Future Bright for Home Media, Analysts Say Page 1 of 3
In searching the publicly accessible web, we found a webpage of interest and provide a snapshot of it below. Please be advised that this page, and any images or links in it, may have changed since we created this snapshot. For your convenience, we provide a hyperlink to the current webpage as part of our service. Future Bright For Home Media, Analysts Say Page 1 of 3 Product Bulletin Special Reports Show Reports PC Magazine My Account | Sign In Not a member? Join now Home > News and Analysis > Future Bright For Home Media, Analysts Say Future Bright For Home Media, Analysts Say 07.07.06 Total posts: 1 By PC Magazine Staff Two separate analyst reports released Thursday paint a rosy future for home media servers and the networks that they will use to pipe content around the home. ABI Research predicted that by 2011, the home media server market will top $44 billion in value, up from $3.7 billion in 2006. In a separate report, Parks Associates forecast that 20 million people would own a "connected entertainment network," of interconnected consumer-electronics devices, or a PC-to-CE network, by 2010. ADVERTISEMENT The PE-CE convergence began in about 2000 when companies like TiVo and ReplayTV began offering personal video recorders that recorded video to a hard drive, like a PC. After failing to capitalize on either its WebTV box or UltimateTV interactive service, Microsoft then introduced its Windows XP Media Center Edition in 2002, which allowed PC owners to connect their breaking news cable feed to the PC and perform the same PVR functions. -
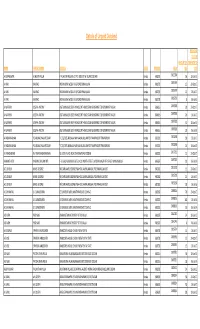
Details of Unpaid Dividend
Details of Unpaid Dividend PROPOSED DATE OF AMOUNT (IN TRANSFER TO NAME FATHER'S NAME ADDRESS STATE PINCODE FOLIO RS.) IEPF A GOPAKUMAR ACHUTAN PILLAI P. ACHUTAN PILLAI & CO P.O. BOX 507 W. ISLANO COCHIN Kerala 682003 0021306 56 18‐Jun‐15 A HARI KAK RAO INDIAN BANK WESDA. M G ROAD ERNAKULAM Kerala 682035 0039759 15 20‐Oct‐17 A HARI KAK RAO INDIAN BANK WESDA. M G ROAD ERNAKULAM Kerala 682035 0039759 15 16‐Jul‐17 A HARI KAK RAO INDIAN BANK WESDA. M G ROAD ERNAKULAM Kerala 682035 0039759 806‐Jul‐14 A MATHEW JOSEPH ANTONY ASST.MANAGER (EDP) FINANCE DPT HINDUSTAN NEWSPRINT LTD NEWSPRINT NAGAR Kerala 686616 0007828 20 20‐Oct‐17 A MATHEW JOSEPH ANTONY ASST.MANAGER (EDP) FINANCE DPT HINDUSTAN NEWSPRINT LTD NEWSPRINT NAGAR Kerala 686616 0007828 20 16‐Jul‐17 A MATHEW JOSEPH ANTONY ASST.MANAGER (EDP) FINANCE DPT HINDUSTAN NEWSPRINT LTD NEWSPRINT NAGAR Kerala 686616 0007828 32 18‐Jun‐15 A MATHEW JOSEPH ANTONY ASST.MANAGER (EDP) FINANCE DPT HINDUSTAN NEWSPRINT LTD NEWSPRINT NAGAR Kerala 686616 0007828 10 06‐Jul‐14 A PADMANABHAN P S ARUNACHALA REDDIAR T C 25/1695 ARUNALAYAM MANJALIKULAM RD THAMPANOOR TRIVANDRUM Kerala 695001 0018268 30 16‐Jul‐17 A PADMANABHAN P S ARUNACHALA REDDIAR T C 25/1695 ARUNALAYAM MANJALIKULAM RD THAMPANOOR TRIVANDRUM Kerala 695001 0018268 24 18‐Jun‐15 A VARADARAJAN R V ANANTHANARAYANAN V1/1673 PALACE ROAD THEKKAMADAM COCHIN Kerala 682002 0017215 15 20‐Oct‐17 A ANANTH IYER K ARUNA CHALAM IYER F‐3 GURU VAISHNAV FLATS 1‐A/10 NORTH STREET LAKSHMI NAGAR 4TH STAGE NANGANALLUR Kerala 695607 0007320 10 06‐Jul‐14 A C LOVELIN JAMES GEORGE -

Fake News in India
Countering ( Misinformation ( Fake News In India Solutions & Strategies Authors Tejeswi Pratima Dodda & Rakesh Dubbudu Factly Media & Research Research, Design & Editing Team Preeti Raghunath Bharath Guniganti Premila Manvi Mady Mantha Uday Kumar Erothu Jyothi Jeeru Shashi Kiran Deshetti Surya Kandukuri Questions or feedback on this report: [email protected] About this report is report is a collaborative eort by Factly Media & Research (Factly) and e Internet and Mobile Association of India (IAMAI). Factly works towards making public data & information more accessible to people through a variety of methods. IAMAI is a young and vibrant association with ambitions of representing the entire gamut of digital businesses in India. Factly IAMAI Rakesh Dubbudu, [email protected] Nilotpal Chakravarti, [email protected] Bharath Guniganti, [email protected] Dr Amitayu Sengupta, [email protected] ACKNOWLEDGEMENT We are grateful to all those with whom we had the pleasure of working for this report. To each member of our team who tirelessly worked to make this report possible. Our gratitude to all our interviewees and respondents who made time to participate, interact and share their opinions, thoughts and concerns about misinformation in India. Special thanks to Claire Wardle of First Dra News for her support, valuable suggestions and penning a foreword for this report. is report would not have seen the light of the day without the insights by the team at Google. We are also thankful to the Government of Telangana for inviting us to the round-table on ‘Fake News’ where we had the opportunity to interact with a variety of stakeholders. We would also like to thank Internet & Mobile Association of India (IAMAI) for being great partners and for all the support extended in the process. -

Intel Settles, Will Pay Intergraph $300 Million
HOME (HTTPS://WWW.EXTREMETECH.COM)Search Extremetech EXTREME (HTTPS://WWW.EXTREMETECH.COM/CATEGORY/EXTREME) INTELTOP SETTLES, ARTICLES WILL PAY1/5 INTERGRAPH $300 MILLION SEARCH Intel Settles, Will Pay Intergraph $300 Million By Mark Hachman (https://www.extremetech.com/author/mhachman) on April 15, 2002 at 2:36 pm 0 Comments (https://www.extremetech.com/extreme/50946-intel-settles-will-pay-intergraph-300-million#disqus_thread) This site may earn affiliate commissions from the links on this page. Terms of use (https://www.ziffdavis.com/terms-of-use#endorsement). Intergraph Corp. announced Monday that it has settled part of its lawsuit with Intel Corp., which paid Intergraph $300 million. The decision settles part of the litigation between the two companies, which claims Intel illegally coerced Intergraph to give up certain patents beginning in 1996. A second case, which will investigate whether Intel’s 64-bit microprocessors infringe Intergraph’s patents, remains unsettled and will go to trial in July. ADVERTISING ADVERTISING “Intergraph has been building its portfolio of intellectual property for 30 years,” said Jim Taylor, the chief executive of Intergraph, Huntsville, Ala., in a statement. “We believe that this settlement demonstrates the validity and value of our patents. Now that we have resolved the Alabama litigation, we can realize additional value for our intellectual property through open licensing agreements with others in the computer and electronics industries.” ADVERTISING The legal tangle between the two companies goes back for several years and is also partly the basis for the Federal Trade Commission’s investigation of Intel for antitrust violations. The FTC later settled with Intel, requiring that Digital (later Compaq) retain the rights to the Alpha microprocessor. -

Coronajihad: COVID-19, Misinformation, and Anti-Muslim Violence in India
#CoronaJihad COVID-19, Misinformation, and Anti-Muslim Violence in India Shweta Desai and Amarnath Amarasingam Abstract About the authors On March 25th, India imposed one of the largest Shweta Desai is an independent researcher and lockdowns in history, confining its 1.3 billion journalist based between India and France. She is citizens for over a month to contain the spread of interested in terrorism, jihadism, religious extremism the novel coronavirus (COVID-19). By the end of and armed conflicts. the first week of the lockdown, starting March 29th reports started to emerge that there was a common Amarnath Amarasingam is an Assistant Professor in link among a large number of the new cases the School of Religion at Queen’s University in Ontario, detected in different parts of the country: many had Canada. He is also a Senior Research Fellow at the attended a large religious gathering of Muslims in Institute for Strategic Dialogue, an Associate Fellow at Delhi. In no time, Hindu nationalist groups began to the International Centre for the Study of Radicalisation, see the virus not as an entity spreading organically and an Associate Fellow at the Global Network on throughout India, but as a sinister plot by Indian Extremism and Technology. His research interests Muslims to purposefully infect the population. This are in radicalization, terrorism, diaspora politics, post- report tracks anti-Muslim rhetoric and violence in war reconstruction, and the sociology of religion. He India related to COVID-19, as well as the ongoing is the author of Pain, Pride, and Politics: Sri Lankan impact on social cohesion in the country. -

AI PRINCIPLES in CONTEXT: Tensions and Opportunities for the United States and China
Written by Jessica Cussins Newman August 2020 AI PRINCIPLES IN CONTEXT: Tensions and Opportunities for the United States and China INTRODUCTION Over the past five years, awareness of the transformative impacts of artificial intelligence (AI) on societies, policies, and economies around the world has been increasing. Unique challenges posed by AI include the rise of synthetic media (text, audio, images, and video content);1 insufficient transparency in the automation of decision making in complex environments;2 the amplification of social biases from training data and design GAINING A BETTER UNDERSTANDING OF choices, causing disparate outcomes for 3 THE CULTURAL AND POLITICAL CONTEXT different races, genders, and other groups; and SURROUNDING KEY AI PRINCIPLES CAN the vulnerability of AI models to cyberattacks HELP CLARIFY WHICH PRINCIPLES PROVIDE such as data poisoning.4 Awareness of these and PRODUCTIVE OPPORTUNITIES FOR numerous other challenges has led to serious POTENTIAL COOPERATION. deliberation about the principles needed to guide AI development and use. By some counts, there are now more than 160 AI principles and guidelines globally.5 Because these principles have emerged from different stakeholders with unique histories and motivations, their style and substance vary. Some documents include recommendations or voluntary commitments, while a smaller subset includes binding agreements or enforcement mechanisms. Despite the differences, arguably a consensus has also been growing around key thematic trends, including privacy, accountability, safety and security, transparency and explainability (meaning that the results and decisions made by an AI system can be understood by humans), fairness and nondiscrimination, human control of technology, professional responsibility, and promotion of human values.6 However, in the face of complex and growing the United States and China.