Clone Detection Using Abstract Syntax Trees Ira D
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UNIX Version 7 Volume 1
UNIXTM TIME-SHARING SYSTEM: UNIX PROGRAMMER'S MANUAL Seventh Edition, Volume 1 January, 1979 Bell Telephone Laboratories, Incorporated Murray Hill, New Jersey PREFACE Although this Seventh Edition no longer bears their byline, Ken Thompson and Dennis Ritchie remain the fathers and preceptors of the UNIX² time-sharing system. Many of the improvements here described bear their mark. Among many, many other people who have contributed to the further ¯owering of UNIX, we wish especially to acknowledge the contributions of A. V. Aho, S. R. Bourne, L. L. Cherry, G. L. Chesson, S. I. Feldman, C. B. Haley, R. C. Haight, S. C. Johnson, M. E. Lesk, T. L. Lyon, L. E. McMahon, R. Morris, R. Muha, D. A. Nowitz, L. Wehr, and P. J. Weinberger. We appreciate also the effective advice and criticism of T. A. Dolotta, A. G. Fraser, J. F. Maranzano, and J. R. Mashey; and we remember the important work of the late Joseph F. Ossanna. B. W. Kernighan M. D. McIlroy __________________ ²UNIX is a Trademark of Bell Laboratories. INTRODUCTION TO VOLUME 1 This volume gives descriptions of the publicly available features of the UNIX² system. It does not attempt to provide perspective or tutorial information upon the UNIX operating system, its facilities, or its implementation. Various documents on those topics are contained in Volume 2. In particular, for an overview see `The UNIX Time-Sharing System' by Ritchie and Thompson; for a tutorial see `UNIX for Beginners' by Kernighan. Within the area it surveys, this volume attempts to be timely, complete and concise. Where the latter two objectives con¯ict, the obvious is often left unsaid in favor of brevity. -

Rve P.Vp:Corelventura
® M-8400RVe Thermal Transfer Printer Operator and Technical Reference Manual PN 9001075A SATO America, Inc. 10350-A Nations Ford Rd. Charlotte, NC 28273 Main Phone: (704) 644-1650 Fax: (704) 644-1661 Technical Support Hotline: (704) 644-1660 E-Mail:[email protected] © Copyright 2000 SATO America, Inc. Warning: This equipment complies with the requirements in Part 15 of FCC rules for a Class A computing device. Operation of this equipment in a residential area may cause unacceptable interference to radio and TV reception requiring the operator to take whatever steps are necessary to correct the interference. All rights reserved. No part of this document may be reproduced or issued to third parties in any form whatsoever without the express permission of SATO America, Inc. The materials in this document is provided for general information and is subject to change without notice. SATO America, Inc. assumes no responibilities for any errors that may appear. SATOM8400RVe PREFACE M-8400RVe PRINTER OPERATOR’S MANUAL The M-8400RVe Printer Operator’s Manual contains basic information about the printer such as setup, installation, cleaning and maintenance. It also contains complete instructions on how to use the operator panel to configure the printer. The following is a brief description of each section in this manual. SECTION 1. PRINTER OVERVIEW This section contains a discussion of the printer specifications and optional features. SECTION 2. INSTALLATION This section contains instructions on how to unpack and set up the printer, load the labels and ribbon. SECTION 3. CONFIGURATION This section contains instructions on how to configure the printer using the DIP switches and the LCD/Menu/Control panel. -
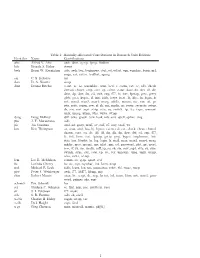
Manually-Allocated Contributions in Research Unix Editions Identifier Name Contributions Aho Alfred V
Table 1: Manually-Allocated Contributions in Research Unix Editions Identifier Name Contributions aho Alfred V. Aho awk, dbm, egrep, fgrep, libdbm bsb Brenda S. Baker struct bwk Brian W. Kernighan adv, awk, beg, beginners, ctut, ed, edtut, eqn, eqnchar, learn, m4, neqn, rat, ratfor, trofftut, uprog csr C. S. Roberts tss dan D. A. Nowitz uucp dmr Dennis Ritchie a.out, ar, as, assembler, atan, bcd, c, cacm, cat, cc, cdb, check, chmod, chown, cmp, core, cp, ctime, ctour, date, db, dev, df, dir, dmr, dp, dsw, du, ed, exit, exp, f77, fc, fort, fptrap, getc, getty, glob, goto, hypot, if, init, iolib, iosys, istat, ld, libc, ln, login, ls, m4, man2, man3, man4, mesg, mkdir, mount, mv, nm, od, pr, ptx, putc, regen, rew, rf, rk, rm, rmdir, rp, secur, security, setup, sh, sin, sort, sqrt, strip, stty, su, switch, tp, tty, type, umount, unix, uprog, utmp, who, write, wtmp doug Doug McIlroy diff, echo, graph, join, look, m6, sort, spell, spline, tmg jfm J. F. Maranzano adb jfo Joe Ossanna azel, ed, getty, nroff, ov, roff, s7, stty, troff, wc ken Ken Thompson ar, atan, atof, bas, bj, bproc, cacm, cal, cat, check, chess, chmod, chown, core, cp, dc, dd, df, dir, dli, dp, dsw, dtf, ed, exp, f77, fc, fed, form, fort, fptrap, getty, grep, hypot, implement, init, itoa, ken, libplot, ln, log, login, ls, mail, man, man2, man4, mesg, mkdir, moo, mount, mv, nlist, nm, od, password, plot, pr, qsort, rew, rf, rk, rm, rmdir, roff, rp, sa, sh, sin, sort, sqrt, stty, su, sum, switch, sync, sys, tabs, tp, ttt, tty, umount, uniq, unix, utmp, who, write, wtmp lem Lee E. -

Www . Electricalpartmanuals . Com' Com .·�
. -� GEH-764AB SupiJf'sedes GEH-764AA com . Polyphase Switc.hboard ) :., ltatt... our Meters -.:-.. / ii' . _/ •, TYPES DS-19, DSW-19, DSM�19, DS-20, DSW-20 DSM-20, DS-341 DSW-341. DSM-341 DS-35 c DSW-351 DSM-35, DS-381 DSW-381 DSM-38 DS-39 I . DSW·-39:· DSM-39 I DS-40 I DSM-40 DSW-4 W-41, DSM-411 DS-43 DSW-441 DSM-44 ElectricalPartManuals . GENERAL . ELECTRIC www . ElectricalPartManuals . com' com .·� . TYPES COVERED • TWO-ELEMENT CONSTRUCTION THREE-ELEMENT CONSTRUCTION DS-19, DSW-19, DSM-19 (Surface Mount DS-20, DSW-20, DSM-20 (Surface Mount ing) ing) DS-34, DSW-34, DSM-34 (Semiflush Mount DS-35, DSW-35, DSM-35 (Semiflush Mount ing) ing) DS-38, DSW-38, DSM-38 (Drawout, Semi DS-39, DSW-39, DSM-39 (Drawout, Semi flush Mounting) flush Mounting) DS-40, DSW-40, DSM-40 (Drawout, Surface DS-41, DSW-41, DSM-41 (Drawout, Surface Mounting) Mounting) DS-43, DSW-43, DSM-43 (Drawout, Semi DS-44, DSW-44, DSM-44 (Drawout, Semi flush or Surface Mounting) flush or Surface Mounting) ElectricalPartManuals . These instructions do not purport to cover all details or variations in equipment nor to provide for every possible contingency to be met in connection with installation, operation or maintenance. Should further information be desired or should particular problems arise which are not covered sufficiently for the purchaser's purposes, the matter should be referred to the General Electric Company. 0 2 www . ElectricalPartManuals . com c POLYPHASE com SWITCHBOARD WATTHOUR METERS . The Types DS-19, DS-34, DS-38, DS-40, and DS-43 next inserted completing the electric circuits through meters are back-connected, switchboard, two-stator, the meter and locking the latch on the cradle. -

Interface and Hardware Component Configuration Guide, Cisco IOS Release 15S
Interface and Hardware Component Configuration Guide, Cisco IOS Release 15S Americas Headquarters Cisco Systems, Inc. 170 West Tasman Drive San Jose, CA 95134-1706 USA http://www.cisco.com Tel: 408 526-4000 800 553-NETS (6387) Fax: 408 527-0883 THE SPECIFICATIONS AND INFORMATION REGARDING THE PRODUCTS IN THIS MANUAL ARE SUBJECT TO CHANGE WITHOUT NOTICE. ALL STATEMENTS, INFORMATION, AND RECOMMENDATIONS IN THIS MANUAL ARE BELIEVED TO BE ACCURATE BUT ARE PRESENTED WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED. USERS MUST TAKE FULL RESPONSIBILITY FOR THEIR APPLICATION OF ANY PRODUCTS. THE SOFTWARE LICENSE AND LIMITED WARRANTY FOR THE ACCOMPANYING PRODUCT ARE SET FORTH IN THE INFORMATION PACKET THAT SHIPPED WITH THE PRODUCT AND ARE INCORPORATED HEREIN BY THIS REFERENCE. IF YOU ARE UNABLE TO LOCATE THE SOFTWARE LICENSE OR LIMITED WARRANTY, CONTACT YOUR CISCO REPRESENTATIVE FOR A COPY. The Cisco implementation of TCP header compression is an adaptation of a program developed by the University of California, Berkeley (UCB) as part of UCB's public domain version of the UNIX operating system. All rights reserved. Copyright © 1981, Regents of the University of California. NOTWITHSTANDING ANY OTHER WARRANTY HEREIN, ALL DOCUMENT FILES AND SOFTWARE OF THESE SUPPLIERS ARE PROVIDED “AS IS" WITH ALL FAULTS. CISCO AND THE ABOVE-NAMED SUPPLIERS DISCLAIM ALL WARRANTIES, EXPRESSED OR IMPLIED, INCLUDING, WITHOUT LIMITATION, THOSE OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT OR ARISING FROM A COURSE OF DEALING, USAGE, OR TRADE PRACTICE. IN NO EVENT SHALL CISCO OR ITS SUPPLIERS BE LIABLE FOR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, OR INCIDENTAL DAMAGES, INCLUDING, WITHOUT LIMITATION, LOST PROFITS OR LOSS OR DAMAGE TO DATA ARISING OUT OF THE USE OR INABILITY TO USE THIS MANUAL, EVEN IF CISCO OR ITS SUPPLIERS HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. -

10/01/2020 10:08 AM 1/13 Email
10/01/2020 BUSINESS LISTING REPORT - DETAIL FOR CITY OF DOUGLASVILLE Page: 1/13 10:08 AM ALL RECORDS DB: Douglasville ======================================================================================================================== BUS ID: 11215 BUS NAME: ACARPENTERSONS.COM TOTAL LICENSES: 1 ======================================================================================================================== BUS ADD'L: BUS TYPE: RESIDENTIAL -- RESIDENTIAL BUSINESS BUS STATUS: Active BUSINESS INFORMATION -------------------------------------------------------------------------------------------------------------- Business Address: Billing/Mailing Address: ------------------- ------------------------- ACARPENTERSONSCOM LLC ACARPENTERSONSCOM LLC 7506 STONEHENGE WAY 7506 STONEHENGE WAY ATTN: BUSINESS OWNER DOUGLASVILLE, GA 30134 DOUGLASVILLE, GA 30134 Ph: (678) 907-4013 Ph: Fax: Fax: Car-Rt: Car-Rt: Business Contact: ------------------- Name: PERNELL HENRY Name 2:TRINITY HENRY Ph: (678) 907-4013 Email: [email protected] ======================================================================================================================== BUS ID: 11204 BUS NAME: ACCESSORY LADY TOTAL LICENSES: 1 ======================================================================================================================== BUS ADD'L: BUS TYPE: COMMERCIAL -- COMMERCIAL BUSINESS BUS STATUS: Active BUSINESS INFORMATION -------------------------------------------------------------------------------------------------------------- Business -

HPSS Management Guide
HPSS Management Guide High Performance Storage System, version 9.2.0.0.0, 10 May 2021 HPSS Management Guide High Performance Storage System, version 9.2.0.0.0, 10 May 2021 Table of Contents ............................................................................................................................................................. xiii 1. HPSS configuration overview ........................................................................................................... 1 1.1. Introduction ............................................................................................................................. 1 1.2. Starting the SSM GUI for the first time ................................................................................ 1 1.3. HPSS configuration roadmap (new HPSS sites) ................................................................... 2 1.4. Initial HPSS startup roadmap (all sites) ................................................................................. 3 1.5. Additional configuration roadmap (all sites) ......................................................................... 4 1.6. Verification checklists (all sites) ............................................................................................ 4 1.6.1. Configuration checklists .............................................................................................. 4 1.6.2. Operational checklists .................................................................................................. 6 1.6.3. Performance checklist -

What Do They Mean for Social Work Practice, Research and Education
SWPI-RPT-22014.DSW-Report_Layout 1 1/8/14 2:31 PM Page 2 ed in 2009 and is a is: policy deliberations. tion and dissemination uture issues in ation DC 20002-4241 ADVANCED PRACTICE DOCTORATES: 202.336.8393 WHAT DO THEY MEAN FOR SOCIAL WORK PRACTICE, RESEARCH, AND EDUCATION SEPTEMBER 2013 > REPORT FROM AN INVITATIONAL THINK TANK > Convened by NASW, in collaboration with CSWE, BPD, ASWB, GADE, NADD, SSWR and SLG SWPI-RPT-22014.DSW-Report_Layout 1 1/8/14 2:31 PM Page 3 ADVANCED PRACTICE DOCTORATES: WHAT DO THEY MEAN FOR SOCIAL WORK PRACTICE, RESEARCH, AND EDUCATION l-being of America’s Veterans and Their by the NASW Foundation’s Social Work ersity of Southern California School Veterans and Military Families, on TABLE OF CONTENTS ern California School of Social Work Overview ..................................................................................................................................1 ial Work Policy Institute’s website, so be viewed at that site. Practice Doctorates in Social Work: How Do They Fit with Our Practice and What Can We Learn From Other Disciplines That Have Launched Practice D FOR MORE INFORMATION CONTACT Joan Levy Zlotnik, PhD, ACSW ded Citation – Social Work Policy Institute (2012). Director, Social Work Policy Institute What Can We Learn From Current DSW Programs ....................................................................1 Risk: Optimizing Health in an Era of Reform. 750 First Street NE, Suite 700 n, DC: National Association of Social Workers. Washington, DC 20002 What Does the Marketplace Want -

Unix Programmer's Manual
There is no warranty of merchantability nor any warranty of fitness for a particu!ar purpose nor any other warranty, either expressed or imp!ied, a’s to the accuracy of the enclosed m~=:crials or a~ Io ~helr ,~.ui~::~::.j!it’/ for ~ny p~rficu~ar pur~.~o~e. ~".-~--, ....-.re: " n~ I T~ ~hone Laaorator es 8ssumg$ no rO, p::::nS,-,,.:~:y ~or their use by the recipient. Furln=,, [: ’ La:::.c:,:e?o:,os ~:’urnes no ob~ja~tjon ~o furnish 6ny a~o,~,,..n~e at ~ny k:nd v,,hetsoever, or to furnish any additional jnformstjcn or documenta’tjon. UNIX PROGRAMMER’S MANUAL F~ifth ~ K. Thompson D. M. Ritchie June, 1974 Copyright:.©d972, 1973, 1974 Bell Telephone:Laboratories, Incorporated Copyright © 1972, 1973, 1974 Bell Telephone Laboratories, Incorporated This manual was set by a Graphic Systems photo- typesetter driven by the troff formatting program operating under the UNIX system. The text of the manual was prepared using the ed text editor. PREFACE to the Fifth Edition . The number of UNIX installations is now above 50, and many more are expected. None of these has exactly the same complement of hardware or software. Therefore, at any particular installa- tion, it is quite possible that this manual will give inappropriate information. The authors are grateful to L. L. Cherry, L. A. Dimino, R. C. Haight, S. C. Johnson, B. W. Ker- nighan, M. E. Lesk, and E. N. Pinson for their contributions to the system software, and to L. E. McMahon for software and for his contributions to this manual. -

Using IBM Z/OS Provisioning Toolkit
1.1 Using IBM z/OS Provisioning Toolkit IBM Note Before using this information and the product it supports, read the information in “Notices” on page 223. This edition applies to the IBM® z/OS® Provisioning Toolkit, Version 1 Release 0 (product number 5655-CI1) and to all subsequent releases and modifications until otherwise indicated in new editions. © Copyright International Business Machines Corporation 2017, 2020. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this book..................................................................................................... v Chapter 1. What is z/OS PT?.................................................................................. 1 How does z/OS PT work?............................................................................................................................. 3 What documentation is available for z/OS PT?........................................................................................... 6 Chapter 2. z/OS PT change history......................................................................... 9 Chapter 3. Prerequisites for using z/OS PT........................................................... 19 Chapter 4. Installing z/OS PT............................................................................... 21 Chapter 5. Upgrading z/OS PT..............................................................................23 Chapter 6. Configuring z/OS PT........................................................................... -

Unix Programmer's Manual
- UNIX PROGRAMMER'S MANUAL Sixth Edition K. Thompson D. M. Ritchie May, 1975 - This manual was set by a Graphic Systems phototypeset- ter driven by the troff formatting program operating un- der the UNIX system. The text of the manual was pre- pared using the ed text editor. - PREFACE to the Sixth Edition We are grateful to L. L. Cherry, R. C. Haight, S. C. Johnson, B. W. Kernighan, M. E. Lesk, and E. N. Pin- son for their contributions to the system software, and to L. E. McMahon for software and for his contribu- tions to this manual. We are particularly appreciative of the invaluable technical, editorial, and administra- tive efforts of J. F. Ossanna, M. D. McIlroy, and R. Morris. They all contributed greatly to the stock of UNIX software and to this manual. Their inventiveness, thoughtful criticism, and ungrudging support in- creased immeasurably not only whatever success the UNIX system enjoys, but also our own enjoyment in its creation. i - INTRODUCTION TO THIS MANUAL This manual gives descriptions of the publicly available features of UNIX. It provides neither a general overview ߝ see ‘‘The UNIX Time-sharing System’’ (Comm. ACM 17 7, July 1974, pp. 365-375) for that ߝ nor details of the implementation of the system, which remain to be disclosed. Within the area it surveys, this manual attempts to be as complete and timely as possible. A conscious de- cision was made to describe each program in exactly the state it was in at the time its manual section was prepared. In particular, the desire to describe something as it should be, not as it is, was resisted. -

RSX - 11 M-PLUS Mini-Reference
RSX - 11 M-PLUS Mini-Reference Order No. AV-H435F-TC RSX - 11M-PLUS Mini-Reference Order Number. AV-H435F-TC RSX-ll M-PLUS Version 4.2 Digital Equipment Corporation Maynard, Massachusetts First Printing, September 1977 Revised, April 1982 Revised, April 1983 Revised, July 1985 R~vised, .September 1987 Revised, January 1989 The information in this document is subject to change without notice and should not be construed as a commitment by Digital Equipment Corporation. Digital Equipment Corporation assumes no responsibility for any errors that may appear in this document. The software described in this document is furnished under a license and may be used or copied only in accordance with the terms of such license. No responsibility is assumed for the use or reliability of software on equipment that is not supplied by Digital Equipment Corporation or its affiliated companies. © Digital Equipment Corporation 1977, 1982, 1983, 1985, 1987, 1989. All Rights Reserved. Printed in U.S.A. The postpaid Reader's Comments forms at the end of this document request your critical evaluation to assist in preparing future documentation. The following are trademarks of Digital Equipment Corporation: DEC DIBOL UNIBUS DEC/CMS EduSystem VAX DEC/MMS lAS VAXcluster DECnet MASSBUS VMS DECsystem-lO PDP VT DECSYSTEM-20 PDT DECUS RSTS DECwriter RSX ~U~UIl~DTM ZK5077 Contents Preface vii Conventions ............................................... viii Online Help Files Online Help Files ............................................. 3 Command Line Interpreters Monitor Console Routine (MCR) Commands ......................... 7 Digital Command Language (DCL) ............................... 21 utilities BAD Command Summary ...................................... 67 iii BRU Command Summary ...................................... 69 CMP Command Summary ...................................... 74 DMP Command Summary .....................................