Laboratory for Computer Science a Scheme Shell
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Shell Scripting with Bash
Introduction to Shell Scripting with Bash Charles Jahnke Research Computing Services Information Services & Technology Topics for Today ● Introductions ● Basic Terminology ● How to get help ● Command-line vs. Scripting ● Variables ● Handling Arguments ● Standard I/O, Pipes, and Redirection ● Control Structures (loops and If statements) ● SCC Job Submission Example Research Computing Services Research Computing Services (RCS) A group within Information Services & Technology at Boston University provides computing, storage, and visualization resources and services to support research that has specialized or highly intensive computation, storage, bandwidth, or graphics requirements. Three Primary Services: ● Research Computation ● Research Visualization ● Research Consulting and Training Breadth of Research on the Shared Computing Cluster (SCC) Me ● Research Facilitator and Administrator ● Background in biomedical engineering, bioinformatics, and IT systems ● Offices on both CRC and BUMC ○ Most of our staff on the Charles River Campus, some dedicated to BUMC ● Contact: [email protected] You ● Who has experience programming? ● Using Linux? ● Using the Shared Computing Cluster (SCC)? Basic Terminology The Command-line The line on which commands are typed and passed to the shell. Username Hostname Current Directory [username@scc1 ~]$ Prompt Command Line (input) The Shell ● The interface between the user and the operating system ● Program that interprets and executes input ● Provides: ○ Built-in commands ○ Programming control structures ○ Environment -

Beginning Portable Shell Scripting from Novice to Professional
Beginning Portable Shell Scripting From Novice to Professional Peter Seebach 10436fmfinal 1 10/23/08 10:40:24 PM Beginning Portable Shell Scripting: From Novice to Professional Copyright © 2008 by Peter Seebach All rights reserved. No part of this work may be reproduced or transmitted in any form or by any means, electronic or mechanical, including photocopying, recording, or by any information storage or retrieval system, without the prior written permission of the copyright owner and the publisher. ISBN-13 (pbk): 978-1-4302-1043-6 ISBN-10 (pbk): 1-4302-1043-5 ISBN-13 (electronic): 978-1-4302-1044-3 ISBN-10 (electronic): 1-4302-1044-3 Printed and bound in the United States of America 9 8 7 6 5 4 3 2 1 Trademarked names may appear in this book. Rather than use a trademark symbol with every occurrence of a trademarked name, we use the names only in an editorial fashion and to the benefit of the trademark owner, with no intention of infringement of the trademark. Lead Editor: Frank Pohlmann Technical Reviewer: Gary V. Vaughan Editorial Board: Clay Andres, Steve Anglin, Ewan Buckingham, Tony Campbell, Gary Cornell, Jonathan Gennick, Michelle Lowman, Matthew Moodie, Jeffrey Pepper, Frank Pohlmann, Ben Renow-Clarke, Dominic Shakeshaft, Matt Wade, Tom Welsh Project Manager: Richard Dal Porto Copy Editor: Kim Benbow Associate Production Director: Kari Brooks-Copony Production Editor: Katie Stence Compositor: Linda Weidemann, Wolf Creek Press Proofreader: Dan Shaw Indexer: Broccoli Information Management Cover Designer: Kurt Krames Manufacturing Director: Tom Debolski Distributed to the book trade worldwide by Springer-Verlag New York, Inc., 233 Spring Street, 6th Floor, New York, NY 10013. -

UNIX Version 7 Volume 1
UNIXTM TIME-SHARING SYSTEM: UNIX PROGRAMMER'S MANUAL Seventh Edition, Volume 1 January, 1979 Bell Telephone Laboratories, Incorporated Murray Hill, New Jersey PREFACE Although this Seventh Edition no longer bears their byline, Ken Thompson and Dennis Ritchie remain the fathers and preceptors of the UNIX² time-sharing system. Many of the improvements here described bear their mark. Among many, many other people who have contributed to the further ¯owering of UNIX, we wish especially to acknowledge the contributions of A. V. Aho, S. R. Bourne, L. L. Cherry, G. L. Chesson, S. I. Feldman, C. B. Haley, R. C. Haight, S. C. Johnson, M. E. Lesk, T. L. Lyon, L. E. McMahon, R. Morris, R. Muha, D. A. Nowitz, L. Wehr, and P. J. Weinberger. We appreciate also the effective advice and criticism of T. A. Dolotta, A. G. Fraser, J. F. Maranzano, and J. R. Mashey; and we remember the important work of the late Joseph F. Ossanna. B. W. Kernighan M. D. McIlroy __________________ ²UNIX is a Trademark of Bell Laboratories. INTRODUCTION TO VOLUME 1 This volume gives descriptions of the publicly available features of the UNIX² system. It does not attempt to provide perspective or tutorial information upon the UNIX operating system, its facilities, or its implementation. Various documents on those topics are contained in Volume 2. In particular, for an overview see `The UNIX Time-Sharing System' by Ritchie and Thompson; for a tutorial see `UNIX for Beginners' by Kernighan. Within the area it surveys, this volume attempts to be timely, complete and concise. Where the latter two objectives con¯ict, the obvious is often left unsaid in favor of brevity. -

C Shell Scripts File Permissions a Simple Spelling Checker Command
Cshell scripts Asimple spelling checker mylatex1.csh #!/bin/csh #!/bin/csh tr -cs "[:alpha:]" "[\n*]" < $1 \ latex file.tex |tr"[:upper:]" "[:lower:]" \ dvips -f file.dvi > file.ps |sort -u > tempfile rm file.aux file.dvi file.log comm -23 tempfile /usr/share/dict/words rm tempfile mylatex2.csh #!/bin/csh Put one word per line \ |convert everything to lowercase \ latex $1.tex |sor t the words,remove duplicates and write the result to ’tempfile’. dvips -f $1.dvi > $1.ps rm $1.aux $1.dvi $1.log Pr int those words in ’tempfile’ that are not in the dictionary. Remove the temporar y file. Graham Kemp,Chalmers University of Technology Graham Kemp,Chalmers University of Technology File permissions Command substitution in a script ls -l To include the output from one command within the command line for another command, enclose the command whose output is to be included rwxrwx rwx within ‘backquotes‘. For example: rwxr -xr -x #!/bin/csh 111101101 echo Date and time is: date echo 1111 011 012 = 7558 echo "Your username is:" ‘whoami‘ echo "Your current directory is:" ‘pwd‘ chmod 755 file.sh chmod u+x file.sh chmod -R a+rX . Graham Kemp,Chalmers University of Technology Graham Kemp,Chalmers University of Technology Editing several files at once (1) sed scripts Suppose wewant to change ‘‘cie’’to‘‘cei’’inall files in the current grep href publications.html \ director y whose name ends with ‘‘.tex’’. |sed ’s/[ˆ"]*"//’ \ |sed ’s/".*//’ #!/bin/csh Instead of giving a single editing command on the command line,wecan ls *.tex | sed ’s/.*/sed s\/cie\/cei\/g & > &tmp/’ > s1 create a script file containing a sequence of editing commands. -

Shell Script & Advance Features of Shell Programming
Kirti Kaushik et al, International Journal of Computer Science and Mobile Computing, Vol.4 Issue.4, April- 2015, pg. 458-462 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology ISSN 2320–088X IJCSMC, Vol. 4, Issue. 4, April 2015, pg.458 – 462 RESEARCH ARTICLE Shell Script & Advance Features of Shell Programming Kirti Kaushik* Roll No.15903, CS, Department of Computer science, Dronacharya College of Engineering, Gurgaon-123506, India Email: [email protected] Jyoti Yadav Roll No. 15040, CS, Department of Applied Computer science, Dronacharya College of Engineering, Gurgaon-123506, India Email: [email protected] Kriti Bhatia Roll No. 15048, CS, Department of Applied Computer science, Dronacharya College of Engineering, Gurgaon-123506, India Email: [email protected] Abstract-- In this research paper, the idea of shell scripting and writing computer programs is examined and different parts of shell programming are likewise contemplated. A shell script is a PC system intended to be controlled by the UNIX shell which is a charge line translator. The different tongues of shell scripts are thought to be scripting dialects. Regular operations performed by shell scripts incorporate document control, program execution, and printing content. A shell script can give an advantageous variety ofa framework order where unique environment settings, charge alternatives, or post-transforming apply naturally, yet in a manner that permits the new script to still go about as a completely typical UNIX summon. The real ideas like Programming in the Borne and C-shell, in which it would be clarified that how shell programming could be possible in Borne and C-shell. -

SOAP / REST and IBM I
1/11/18 SOPA / REST and IBM i Tim Rowe- [email protected] Business Architect Application Development © 2017 International Business Machines Corporation Using a REST API with Watson https://ibm-i-watson-test.mybluemix.net/ 2 © 2017 International Business Machines Corporation 1 1/11/18 ™ What is an API - Agenda •What is an API •What is a Web Service •SOAP vs REST – What is SOAP – What is REST – Benefits – Drawbacks 3 © 2017 International Business Machines Corporation ™ Connections Devices There Here Applications 4 © 2017 International Business Machines Corporation 2 1/11/18 ™ 5 © 2017 International Business Machines Corporation ™ 6 © 2017 International Business Machines Corporation 3 1/11/18 ™ 7 © 2017 International Business Machines Corporation ™ 8 © 2017 International Business Machines Corporation 4 1/11/18 ™ API Definition Application Programming Interface 9 © 2017 International Business Machines Corporation ™ API Definition 10 © 2017 International Business Machines Corporation 5 1/11/18 ™ APIs - Simple Simple way to connect endpoints. Send a request and receive a response. 11 © 2017 International Business Machines Corporation ™ Example Kitchen 12 © 2017 International Business Machines Corporation 6 1/11/18 ™ 13 © 2017 International Business Machines Corporation ™ Not just a buzz-word, but rather the evolution of services- oriented IT. Allows users, businesses & partners the ability to interact in new and different ways resulting in the growth (in some cases the revolution) of business. 14 © 2017 International Business Machines Corporation -

The /Proc File System
09 0430 CH07 5/22/01 10:30 AM Page 147 7 The /proc File System TRY INVOKING THE mount COMMAND WITHOUT ARGUMENTS—this displays the file systems currently mounted on your GNU/Linux computer.You’ll see one line that looks like this: none on /proc type proc (rw) This is the special /proc file system. Notice that the first field, none, indicates that this file system isn’t associated with a hardware device such as a disk drive. Instead, /proc is a window into the running Linux kernel. Files in the /proc file system don’t corre- spond to actual files on a physical device. Instead, they are magic objects that behave like files but provide access to parameters, data structures, and statistics in the kernel. The “contents” of these files are not always fixed blocks of data, as ordinary file con- tents are. Instead, they are generated on the fly by the Linux kernel when you read from the file.You can also change the configuration of the running kernel by writing to certain files in the /proc file system. Let’s look at an example: % ls -l /proc/version -r--r--r-- 1 root root 0 Jan 17 18:09 /proc/version Note that the file size is zero; because the file’s contents are generated by the kernel, the concept of file size is not applicable.Also, if you try this command yourself, you’ll notice that the modification time on the file is the current time. 09 0430 CH07 5/22/01 10:30 AM Page 148 148 Chapter 7 The /proc File System What’s in this file? The contents of /proc/version consist of a string describing the Linux kernel version number. -

Towards a Portable and Mobile Scheme Interpreter
Towards a Portable and Mobile Scheme Interpreter Adrien Pi´erard Marc Feeley Universit´eParis 6 Universit´ede Montr´eal [email protected] [email protected] Abstract guage. Because Mobit implements R4RS Scheme [6], we must also The transfer of program data between the nodes of a distributed address the serialization of continuations. Our main contribution is system is a fundamental operation. It usually requires some form the demonstration of how this can be done while preserving the in- of data serialization. For a functional language such as Scheme it is terpreter’s maintainability and with local changes to the original in- clearly desirable to also allow the unrestricted transfer of functions terpreter’s structure, mainly through the use of unhygienic macros. between nodes. With the goal of developing a portable implemen- We start by giving an overview of the pertinent features of the tation of the Termite system we have designed the Mobit Scheme Termite dialect of Scheme. In Section 3 we explain the structure interpreter which supports unrestricted serialization of Scheme ob- of the interpreter on which Mobit is based. Object serialization is jects, including procedures and continuations. Mobit is derived discussed in Section 4. Section 5 compares Mobit’s performance from an existing Scheme in Scheme fast interpreter. We demon- with other interpreters. We conclude with related and future work. strate how macros were valuable in transforming the interpreter while preserving its structure and maintainability. Our performance 2. Termite evaluation shows that the run time speed of Mobit is comparable to Termite is a Scheme adaptation of the Erlang concurrency model. -

A.5.1. Linux Programming and the GNU Toolchain
Making the Transition to Linux A Guide to the Linux Command Line Interface for Students Joshua Glatt Making the Transition to Linux: A Guide to the Linux Command Line Interface for Students Joshua Glatt Copyright © 2008 Joshua Glatt Revision History Revision 1.31 14 Sept 2008 jg Various small but useful changes, preparing to revise section on vi Revision 1.30 10 Sept 2008 jg Revised further reading and suggestions, other revisions Revision 1.20 27 Aug 2008 jg Revised first chapter, other revisions Revision 1.10 20 Aug 2008 jg First major revision Revision 1.00 11 Aug 2008 jg First official release (w00t) Revision 0.95 06 Aug 2008 jg Second beta release Revision 0.90 01 Aug 2008 jg First beta release License This document is licensed under a Creative Commons Attribution-Noncommercial-Share Alike 3.0 United States License [http:// creativecommons.org/licenses/by-nc-sa/3.0/us/]. Legal Notice This document is distributed in the hope that it will be useful, but it is provided “as is” without express or implied warranty of any kind; without even the implied warranties of merchantability or fitness for a particular purpose. Although the author makes every effort to make this document as complete and as accurate as possible, the author assumes no responsibility for errors or omissions, nor does the author assume any liability whatsoever for incidental or consequential damages in connection with or arising out of the use of the information contained in this document. The author provides links to external websites for informational purposes only and is not responsible for the content of those websites. -

Rve P.Vp:Corelventura
® M-8400RVe Thermal Transfer Printer Operator and Technical Reference Manual PN 9001075A SATO America, Inc. 10350-A Nations Ford Rd. Charlotte, NC 28273 Main Phone: (704) 644-1650 Fax: (704) 644-1661 Technical Support Hotline: (704) 644-1660 E-Mail:[email protected] © Copyright 2000 SATO America, Inc. Warning: This equipment complies with the requirements in Part 15 of FCC rules for a Class A computing device. Operation of this equipment in a residential area may cause unacceptable interference to radio and TV reception requiring the operator to take whatever steps are necessary to correct the interference. All rights reserved. No part of this document may be reproduced or issued to third parties in any form whatsoever without the express permission of SATO America, Inc. The materials in this document is provided for general information and is subject to change without notice. SATO America, Inc. assumes no responibilities for any errors that may appear. SATOM8400RVe PREFACE M-8400RVe PRINTER OPERATOR’S MANUAL The M-8400RVe Printer Operator’s Manual contains basic information about the printer such as setup, installation, cleaning and maintenance. It also contains complete instructions on how to use the operator panel to configure the printer. The following is a brief description of each section in this manual. SECTION 1. PRINTER OVERVIEW This section contains a discussion of the printer specifications and optional features. SECTION 2. INSTALLATION This section contains instructions on how to unpack and set up the printer, load the labels and ribbon. SECTION 3. CONFIGURATION This section contains instructions on how to configure the printer using the DIP switches and the LCD/Menu/Control panel. -

Shell Variables
Shell Using the command line Orna Agmon ladypine at vipe.technion.ac.il Haifux Shell – p. 1/55 TOC Various shells Customizing the shell getting help and information Combining simple and useful commands output redirection lists of commands job control environment variables Remote shell textual editors textual clients references Shell – p. 2/55 What is the shell? The shell is the wrapper around the system: a communication means between the user and the system The shell is the manner in which the user can interact with the system through the terminal. The shell is also a script interpreter. The simplest script is a bunch of shell commands. Shell scripts are used in order to boot the system. The user can also write and execute shell scripts. Shell – p. 3/55 Shell - which shell? There are several kinds of shells. For example, bash (Bourne Again Shell), csh, tcsh, zsh, ksh (Korn Shell). The most important shell is bash, since it is available on almost every free Unix system. The Linux system scripts use bash. The default shell for the user is set in the /etc/passwd file. Here is a line out of this file for example: dana:x:500:500:Dana,,,:/home/dana:/bin/bash This line means that user dana uses bash (located on the system at /bin/bash) as her default shell. Shell – p. 4/55 Starting to work in another shell If Dana wishes to temporarily use another shell, she can simply call this shell from the command line: [dana@granada ˜]$ bash dana@granada:˜$ #In bash now dana@granada:˜$ exit [dana@granada ˜]$ bash dana@granada:˜$ #In bash now, going to hit ctrl D dana@granada:˜$ exit [dana@granada ˜]$ #In original shell now Shell – p. -
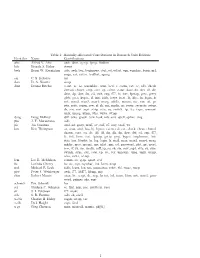
Manually-Allocated Contributions in Research Unix Editions Identifier Name Contributions Aho Alfred V
Table 1: Manually-Allocated Contributions in Research Unix Editions Identifier Name Contributions aho Alfred V. Aho awk, dbm, egrep, fgrep, libdbm bsb Brenda S. Baker struct bwk Brian W. Kernighan adv, awk, beg, beginners, ctut, ed, edtut, eqn, eqnchar, learn, m4, neqn, rat, ratfor, trofftut, uprog csr C. S. Roberts tss dan D. A. Nowitz uucp dmr Dennis Ritchie a.out, ar, as, assembler, atan, bcd, c, cacm, cat, cc, cdb, check, chmod, chown, cmp, core, cp, ctime, ctour, date, db, dev, df, dir, dmr, dp, dsw, du, ed, exit, exp, f77, fc, fort, fptrap, getc, getty, glob, goto, hypot, if, init, iolib, iosys, istat, ld, libc, ln, login, ls, m4, man2, man3, man4, mesg, mkdir, mount, mv, nm, od, pr, ptx, putc, regen, rew, rf, rk, rm, rmdir, rp, secur, security, setup, sh, sin, sort, sqrt, strip, stty, su, switch, tp, tty, type, umount, unix, uprog, utmp, who, write, wtmp doug Doug McIlroy diff, echo, graph, join, look, m6, sort, spell, spline, tmg jfm J. F. Maranzano adb jfo Joe Ossanna azel, ed, getty, nroff, ov, roff, s7, stty, troff, wc ken Ken Thompson ar, atan, atof, bas, bj, bproc, cacm, cal, cat, check, chess, chmod, chown, core, cp, dc, dd, df, dir, dli, dp, dsw, dtf, ed, exp, f77, fc, fed, form, fort, fptrap, getty, grep, hypot, implement, init, itoa, ken, libplot, ln, log, login, ls, mail, man, man2, man4, mesg, mkdir, moo, mount, mv, nlist, nm, od, password, plot, pr, qsort, rew, rf, rk, rm, rmdir, roff, rp, sa, sh, sin, sort, sqrt, stty, su, sum, switch, sync, sys, tabs, tp, ttt, tty, umount, uniq, unix, utmp, who, write, wtmp lem Lee E.