Shell Programming in Unix, Linux and OS X
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Institutionen För Datavetenskap Department of Computer and Information Science
Institutionen för datavetenskap Department of Computer and Information Science Final thesis NetworkPerf – A tool for the investigation of TCP/IP network performance at Saab Transpondertech by Magnus Johansson LIU-IDA/LITH-EX-A--09/039--SE 2009-08-13 Linköpings universitet Linköpings universitet SE-581 83 Linköping, Sweden 581 83 Linköping Final thesis NetworkPerf - A tool for the investigation of TCP/IP network performance at Saab Transpondertech Version 1.0.2 by Magnus Johansson LIU-IDA/LITH-EX-A09/039SE 2009-08-13 Supervisor: Hannes Persson, Attentec AB Examiner: Dr Juha Takkinen, IDA, Linköpings universitet Abstract In order to detect network changes and network troubles, Saab Transpon- dertech needs a tool that can make network measurements. The purpose of this thesis has been to nd measurable network proper- ties that best reect the status of a network, to nd methods to measure these properties and to implement these methods in one single tool. The resulting tool is called NetworkPerf and can measure the following network properties: availability, round-trip delay, delay variation, number of hops, intermediate hosts, available bandwidth, available ports, and maximum al- lowed packet size. The thesis also presents the methods used for measuring these properties in the tool: ping, traceroute, port scanning, and bandwidth measurement. iii iv Acknowledgments This master's thesis would not be half as good as it is, if I had not received help and support from several people. Many thanks to my examiner Dr Juha Takkinen, without whose countin- uous feedback this report would not have been more than a few confusing pages. -
APPENDIX a Aegis and Unix Commands
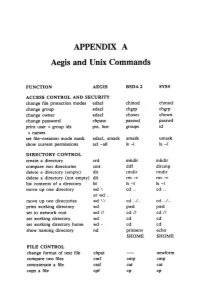
APPENDIX A Aegis and Unix Commands FUNCTION AEGIS BSD4.2 SYSS ACCESS CONTROL AND SECURITY change file protection modes edacl chmod chmod change group edacl chgrp chgrp change owner edacl chown chown change password chpass passwd passwd print user + group ids pst, lusr groups id +names set file-creation mode mask edacl, umask umask umask show current permissions acl -all Is -I Is -I DIRECTORY CONTROL create a directory crd mkdir mkdir compare two directories cmt diff dircmp delete a directory (empty) dlt rmdir rmdir delete a directory (not empty) dlt rm -r rm -r list contents of a directory ld Is -I Is -I move up one directory wd \ cd .. cd .. or wd .. move up two directories wd \\ cd . ./ .. cd . ./ .. print working directory wd pwd pwd set to network root wd II cd II cd II set working directory wd cd cd set working directory home wd- cd cd show naming directory nd printenv echo $HOME $HOME FILE CONTROL change format of text file chpat newform compare two files emf cmp cmp concatenate a file catf cat cat copy a file cpf cp cp Using and Administering an Apollo Network 265 copy std input to std output tee tee tee + files create a (symbolic) link crl In -s In -s delete a file dlf rm rm maintain an archive a ref ar ar move a file mvf mv mv dump a file dmpf od od print checksum and block- salvol -a sum sum -count of file rename a file chn mv mv search a file for a pattern fpat grep grep search or reject lines cmsrf comm comm common to 2 sorted files translate characters tic tr tr SHELL SCRIPT TOOLS condition evaluation tools existf test test -

Lecture 17 the Shell and Shell Scripting Simple Shell Scripts
Lecture 17 The Shell and Shell Scripting In this lecture • The UNIX shell • Simple Shell Scripts • Shell variables • File System commands, IO commands, IO redirection • Command Line Arguments • Evaluating Expr in Shell • Predicates, operators for testing strings, ints and files • If-then-else in Shell • The for, while and do loop in Shell • Writing Shell scripts • Exercises In this course, we need to be familiar with the "UNIX shell". We use it, whether bash, csh, tcsh, zsh, or other variants, to start and stop processes, control the terminal, and to otherwise interact with the system. Many of you have heard of, or made use of "shell scripting", that is the process of providing instructions to shell in a simple, interpreted programming language . To see what shell we are working on, first SSH into unix.andrew.cmu.edu and type echo $SHELL ---- to see the working shell in SSH We will be writing our shell scripts for this particular shell (csh). The shell scripting language does not fit the classic definition of a useful language. It does not have many of the features such as portability, facilities for resource intensive tasks such as recursion or hashing or sorting. It does not have data structures like arrays and hash tables. It does not have facilities for direct access to hardware or good security features. But in many other ways the language of the shell is very powerful -- it has functions, conditionals, loops. It does not support strong data typing -- it is completely untyped (everything is a string). But, the real power of shell program doesn't come from the language itself, but from the diverse library that it can call upon -- any program. -

File Management Tools
File Management Tools ● gzip and gunzip ● tar ● find ● df and du ● od ● nm and strip ● sftp and scp Gzip and Gunzip ● The gzip utility compresses a specified list of files. After compressing each specified file, it renames it to have a “.gz” extension. ● General form. gzip [filename]* ● The gunzip utility uncompresses a specified list of files that had been previously compressed with gzip. ● General form. gunzip [filename]* Tar (38.2) ● Tar is a utility for creating and extracting archives. It was originally setup for archives on tape, but it now is mostly used for archives on disk. It is very useful for sending a set of files to someone over the network. Tar is also useful for making backups. ● General form. tar options filenames Commonly Used Tar Options c # insert files into a tar file f # use the name of the tar file that is specified v # output the name of each file as it is inserted into or # extracted from a tar file x # extract the files from a tar file Creating an Archive with Tar ● Below is the typical tar command used to create an archive from a set of files. Note that each specified filename can also be a directory. Tar will insert all files in that directory and any subdirectories. tar cvf tarfilename filenames ● Examples: tar cvf proj.tar proj # insert proj directory # files into proj.tar tar cvf code.tar *.c *.h # insert *.c and *.h files # into code.tar Extracting Files from a Tar Archive ● Below is the typical tar command used to extract the files from a tar archive. -

Lecture 1 Introduction to Unix and C
Lecture 1 Introduction to Unix and C In this lecture • Operating System • Unix system shell • Why learn C • Program Development Process • Compilation, Linking and Preprocessing • ANSI-C • The C compiler – gcc • Jobs and Processes • Killing a Process • Moving from Java to C • Additional Readings • Exercises Operating System Each machine needs an Operating System (OS). An operating system is a software program that manages coordination between application programs and underlying hardware. OS manages devices such as printers, disks, monitors and manage multiple tasks such as processes. UNIX is an operating system. The following figure demonstrates the high level view of the layers of a computer system. It demonstrates that the end users interface with the computer at the application level, while programmers deal with utilities and operating system level. On the other hand, an OS designed must understand how to interface with the underlying hardware architecture. Copyright @ 2009 Ananda Gunawardena End user Programmer Application programs OS Designer Utilities Operating System Computer Hardware Unix is an operating system developed by AT&T in the late 60’s. BSD (Berkeley Unix) and Linux, are unix-like operating systems that are widely used in servers and many other platforms such as portable devices. Linux, an open source version of Unix-like operating system was first developed by Linus Torvalds . Linux has become a popular operating system used by many devices. Many volunteer developers have contributed to the development of many linux based resources. Linux is free, open source, and have very low hardware requirements. This makes linux a popular operating system for devices with limited hardware capabilities as well as running low cost personal computers. -

User's Manual
USER’S MANUAL USER’S > UniQTM UniQTM User’s Manual Ed.: 821003146 rev.H © 2016 Datalogic S.p.A. and its Group companies • All rights reserved. • Protected to the fullest extent under U.S. and international laws. • Copying or altering of this document is prohibited without express written consent from Datalogic S.p.A. • Datalogic and the Datalogic logo are registered trademarks of Datalogic S.p.A. in many countries, including the U.S. and the E.U. All other brand and product names mentioned herein are for identification purposes only and may be trademarks or registered trademarks of their respective owners. Datalogic shall not be liable for technical or editorial errors or omissions contained herein, nor for incidental or consequential damages resulting from the use of this material. Printed in Donnas (AO), Italy. ii SYMBOLS Symbols used in this manual along with their meaning are shown below. Symbols and signs are repeated within the chapters and/or sections and have the following meaning: Generic Warning: This symbol indicates the need to read the manual carefully or the necessity of an important maneuver or maintenance operation. Electricity Warning: This symbol indicates dangerous voltage associated with the laser product, or powerful enough to constitute an electrical risk. This symbol may also appear on the marking system at the risk area. Laser Warning: This symbol indicates the danger of exposure to visible or invisible laser radiation. This symbol may also appear on the marking system at the risk area. Fire Warning: This symbol indicates the danger of a fire when processing flammable materials. -

GNU Coreutils Cheat Sheet (V1.00) Created by Peteris Krumins ([email protected], -- Good Coders Code, Great Coders Reuse)
GNU Coreutils Cheat Sheet (v1.00) Created by Peteris Krumins ([email protected], www.catonmat.net -- good coders code, great coders reuse) Utility Description Utility Description arch Print machine hardware name nproc Print the number of processors base64 Base64 encode/decode strings or files od Dump files in octal and other formats basename Strip directory and suffix from file names paste Merge lines of files cat Concatenate files and print on the standard output pathchk Check whether file names are valid or portable chcon Change SELinux context of file pinky Lightweight finger chgrp Change group ownership of files pr Convert text files for printing chmod Change permission modes of files printenv Print all or part of environment chown Change user and group ownership of files printf Format and print data chroot Run command or shell with special root directory ptx Permuted index for GNU, with keywords in their context cksum Print CRC checksum and byte counts pwd Print current directory comm Compare two sorted files line by line readlink Display value of a symbolic link cp Copy files realpath Print the resolved file name csplit Split a file into context-determined pieces rm Delete files cut Remove parts of lines of files rmdir Remove directories date Print or set the system date and time runcon Run command with specified security context dd Convert a file while copying it seq Print sequence of numbers to standard output df Summarize free disk space setuidgid Run a command with the UID and GID of a specified user dir Briefly list directory -

You Can Download and Print the Meeting Schedule
EVERY WEEK DAY FRIDAY 6 PM SATURDAY NIGHT LIVE 7 PM HONOMU AS YET UNNAMED Serenity House, 15-2579 Pahoa-Keaau Rd., Pahoa ZOOM 5 PM WOMEN'S 11th STEP 8 AM ATTITUDE ADJUSTMENT NEW Hilo Coast United Church of Christ, Old Mamalahoa - O, BBS (near Pahoa Fire Station) MEDITATION -CL, WO LOCATION Onekahakaha Beach Park 74 Hwy. past the gym & turn left at the first driveway, https://zoom.us/j/400348959 Onekahakaha Rd, Hilo -OD, S, H Honomu - O, H ZOOM 6PM BEGINNER STEP MEETING psswd: 443670 https://us02web.zoom.us/j/4639358103?pwd 12 PM NOONERS now located at the Hilo soccer =c0FKRnJaVmNIQUlaS3lmRFVQNzZtdz09 field on Kamehameha Ave ***from Kilauea Ave turn TUESDAY 5:30 PM VOLCANO BIG BOOK GROUP psswd 9waxu4 East on Ponahawai Street. (toward the water) Right Cooper Center in Bookstore, Wright Rd., Volcano - on Bay Front (King Kamahemeha Ave) First drive ZOOM 7 PM SERENDIPITY -OD, H and CL, BB, H on right, at pavilion Bring Own Chair! 6:30 PM KEEP IT SIMPLE NEW Additional teleconference meeting Reflections https://us04web.zoom.us/j/9609522834 6 PM AA FRIDAY NIGHT Center for Spiritual Cooper Center on Wright Road, Volcano - Telephone number: 978-990-5000 Living, corner of 31st and Paradise in Hawaiian OD, H Access code: 226622 Paradise Park- OD, H ZOOM 7 PM ELEVATAH STAY BROKE Ask member for zoom info 7 PM YOUNG PEOPLES TUNDA 7 AM NANAWALE 4th DIMENSION (week 6 PM HILO MEN'S STAG 1842 Kino'ole St., Hilo O, 12 X 12 Lanakila Center, 600 Wailoa St. (across St. -

Introduction to Unix Shell (Part I)
Introduction to Unix shell (part I) Evgeny Stambulchik Faculty of Physics, Weizmann Institute of Science, Rehovot 7610001, Israel Joint ICTP-IAEA School on Atomic Processes in Plasmas February 27 – March 3, 2017 Trieste, Italy Contrary to popular belief, Unix is user friendly. It just happens to be very selective about who it decides to make friends with. Unknown Initially used at Bell Labs, but soon licensed to academy (notably, U. of California, Berkeley) and commercial vendors (IBM, Sun, etc). There are two major products that came out of Berkeley: LSD and Unix. We don’t believe this to be a coincidence. Jeremy S. Anderson, Unix systems administrator Historical overview (kind of) Unix is a family of multiuser, multitasking operating systems stemming from the original Unix developed in the 1970’s at Bell Labs by Ken Thompson, Dennis Ritchie1, and others. Some consider Unix to be the second most important invention to come out of AT&T Bell Labs after the transistor. Dennis Ritchie 1Also famous for creating the C programming language. Historical overview (kind of) Unix is a family of multiuser, multitasking operating systems stemming from the original Unix developed in the 1970’s at Bell Labs by Ken Thompson, Dennis Ritchie1, and others. Some consider Unix to be the second most important invention to come out of AT&T Bell Labs after the transistor. Dennis Ritchie Initially used at Bell Labs, but soon licensed to academy (notably, U. of California, Berkeley) and commercial vendors (IBM, Sun, etc). There are two major products that came out of Berkeley: LSD and Unix. -

CS 388 – UNIX Systems Programming Syllabus
CS 388 – UNIX Systems Programming Syllabus Instructor: Dr. Jack Tan Office: Phillips 135 Office Hours: click here Email: [email protected] Tel: 836-2408 Course Description: In-depth coverage of the UNIX command shell, file manipulation, process control, file system utilities, mail, pipes and filters, I/O redirection, process management, UNIX editors, scripting language, and shell scripting. Credits: 3 Prerequisites: CS 245 Courses that require this course as a prerequisite: none. Learning Resources: • Your UNIX: The Ultimate Guide, Sumitabha Das, McGraw-Hill, 2012. • Learning Perl: Making Things Easy and Hard Things Possible, Randall Schwartz, O’Reilly, 2016. • SED and AWK Pocket Reference, Arnold Robbins, O’Reilly, 2000. • Classic Shell Scripting: Hidden Commands that Unlock the Power of Unix, Arnold Robbins, 2017. Evaluation Midterm & Final: 20% Lab Assignments: 80% Course Outline Topic Number of weeks • UNIX commands and Utilities 2 • File and directory operations 1 • vi/vim editor 1 • UNIX file system 1 • UNIX Shell & shell scripting 2 • Process control 1 • grep, sed, and awk 2 • Regular expressions 1 • Perl programming 2 • System administration utilities 1 Course Outcomes: • Describe and apply the basic set of commands and utilities in Linux/UNIX systems. • Describe and process command-line arguments. • Apply important Linux/UNIX library functions and system calls. • Describe the inner workings of UNIX-like operating systems. • Design software for Linux/UNIX systems. • Use Perl and sed/awk/grep scripts to design programs for users. • Design conditional statements to control the execution of shell scripts. • Write shell scripts to perform repetitive tasks using while and for loops. • Design and implement shell functions. -

Unix Programmer's Manual
There is no warranty of merchantability nor any warranty of fitness for a particu!ar purpose nor any other warranty, either expressed or imp!ied, a’s to the accuracy of the enclosed m~=:crials or a~ Io ~helr ,~.ui~::~::.j!it’/ for ~ny p~rficu~ar pur~.~o~e. ~".-~--, ....-.re: " n~ I T~ ~hone Laaorator es 8ssumg$ no rO, p::::nS,-,,.:~:y ~or their use by the recipient. Furln=,, [: ’ La:::.c:,:e?o:,os ~:’urnes no ob~ja~tjon ~o furnish 6ny a~o,~,,..n~e at ~ny k:nd v,,hetsoever, or to furnish any additional jnformstjcn or documenta’tjon. UNIX PROGRAMMER’S MANUAL F~ifth ~ K. Thompson D. M. Ritchie June, 1974 Copyright:.©d972, 1973, 1974 Bell Telephone:Laboratories, Incorporated Copyright © 1972, 1973, 1974 Bell Telephone Laboratories, Incorporated This manual was set by a Graphic Systems photo- typesetter driven by the troff formatting program operating under the UNIX system. The text of the manual was prepared using the ed text editor. PREFACE to the Fifth Edition . The number of UNIX installations is now above 50, and many more are expected. None of these has exactly the same complement of hardware or software. Therefore, at any particular installa- tion, it is quite possible that this manual will give inappropriate information. The authors are grateful to L. L. Cherry, L. A. Dimino, R. C. Haight, S. C. Johnson, B. W. Ker- nighan, M. E. Lesk, and E. N. Pinson for their contributions to the system software, and to L. E. McMahon for software and for his contributions to this manual. -

Tour of the Terminal: Using Unix Or Mac OS X Command-Line
Tour of the Terminal: Using Unix or Mac OS X Command-Line hostabc.princeton.edu% date Mon May 5 09:30:00 EDT 2014 hostabc.princeton.edu% who | wc –l 12 hostabc.princeton.edu% Dawn Koffman Office of Population Research Princeton University May 2014 Tour of the Terminal: Using Unix or Mac OS X Command Line • Introduction • Files • Directories • Commands • Shell Programs • Stream Editor: sed 2 Introduction • Operating Systems • Command-Line Interface • Shell • Unix Philosophy • Command Execution Cycle • Command History 3 Command-Line Interface user operating system computer (human ) (software) (hardware) command- programs kernel line (text (manages interface editors, computing compilers, resources: commands - memory for working - hard-drive cpu with file - time) memory system, point-and- hard-drive many other click (gui) utilites) interface 4 Comparison command-line interface point-and-click interface - may have steeper learning curve, - may be more intuitive, BUT provides constructs that can BUT can also be much more make many tasks very easy human-manual-labor intensive - scales up very well when - often does not scale up well when have lots of: have lots of: data data programs programs tasks to accomplish tasks to accomplish 5 Shell Command-line interface provided by Unix and Mac OS X is called a shell a shell: - prompts user for commands - interprets user commands - passes them onto the rest of the operating system which is hidden from the user How do you access a shell ? - if you have an account on a machine running Unix or Linux , just log in. A default shell will be running. - if you are using a Mac, run the Terminal app.